文章目錄
- 目錄
- 1.FM算法產生背景
- 2.FM算法模型
- 3.FM算法VS其他算法
- 4.推薦算法總結
目錄
1.FM算法產生背景
在傳統的線性模型如LR中,每個特征都是獨立的,如果需要考慮特征與特征直接的交互作用,可能需要人工對特征進行交叉組合;非線性SVM可以對特征進行kernel映射,但是在特征高度稀疏的情況下,并不能很好地進行學習;現在也有很多分解模型Factorization model如矩陣分解MF、SVD++等,這些模型可以學習到特征之間的交互隱藏關系,但基本上每個模型都只適用于特定的輸入和場景。為此,在高度稀疏的數據場景下如推薦系統,FM(Factorization Machine)出現了。
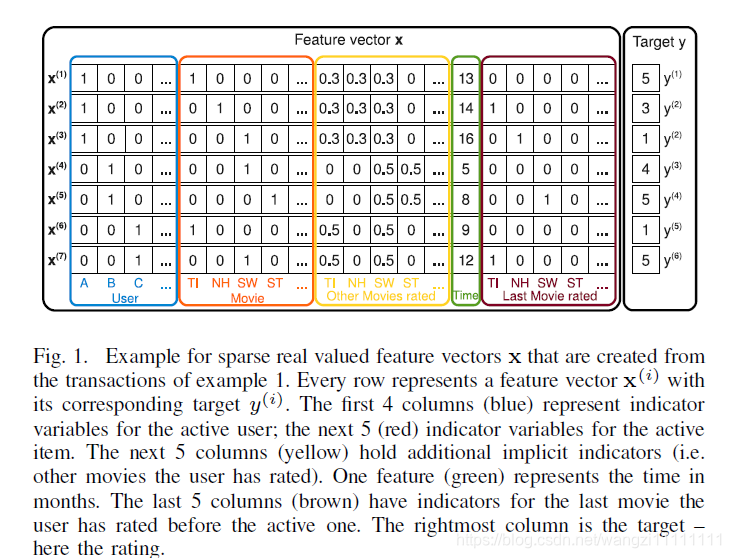
下面所有的假設都是建立在稀疏數據的基礎上,舉個例子,根據用戶的評分歷史預測用戶對某部電影的打分,這里的每一行對應一個樣本,Feature vector x表示特征,Targer y表示預測結果。從下圖可以看出,這是一個稀疏特征的例子,后面的相關內容會以此為例子進行說明。
特征中的前四列表示用戶u(one-hot編碼,稀疏),接著五列表示電影i(ont-hot編碼,稀疏),再接下去五列表示用戶u對電影i的打分(歸一化特征),緊接著一列表示時間(連續特征),最后五列表示用戶u對電影i打分前評價過的最近一部電影(one-hot編碼,稀疏)
2.FM算法模型
二、FM算法模型
1、模型目標函數
二元交叉的FM(2-way FM)目標函數如下:
其中,w是輸入特征的參數,<vi,vj>是輸入特征i,j間的交叉參數,v是k維向量。
前面兩個就是我們熟知的線性模型,后面一個就是我們需要學習的交叉組合特征,正是FM區別與線性模型的地方。

為什么要通過向量v的學習方式而不是簡單的wij參數呢?
這是因為在稀疏條件下,這樣的表示方法打破了特征的獨立性,能夠更好地挖掘特征之間的相關性。以上述電影為例,我們要估計用戶A和電影ST的關系w(A&ST)以更好地預測y,如果是簡單地考慮特征之間的共現情況來估計w(A&ST),從已有的訓練樣本來看,這兩者并沒有共現,因此學習出來的w(A&ST)=0。而實際上,A和ST應該是存在某種聯系的,從用戶角度來看,A和B都看過SW,而B還看過ST,說明A也可能喜歡ST,說明A很有可能也喜歡ST。而通過向量v來表示用戶和電影,任意兩兩之間的交互都會影響v的更新,從前面舉的例子就可以看過,A和B看過SW,這樣的交互關系就會導致v(ST)的學習更新,因此通過向量v的學習方式能夠更好的挖掘特征間的相互關系,尤其在稀疏條件下。
2、模型的計算復雜度
可能有人會問,這樣兩兩交叉的復雜度應該O(k*n^2)吧,其實,通過數學公式的巧妙轉化一下,就可以變成O(kn)了。轉化公式如下所示,其實就是利用了2xy=(x+y)2?x2?y22xy = (x+y)^2-x^2-y^22xy=(x+y)2?x2?y2的思路。
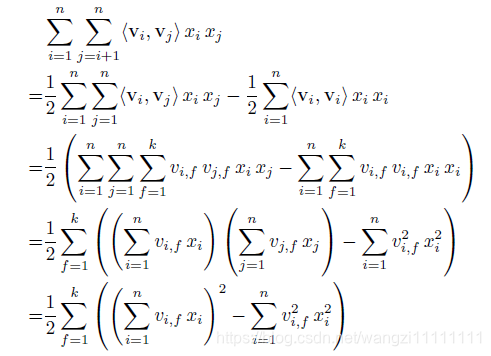
3、模型的應用
FM可以應用于很多預測任務,比如回歸、分類、排序等等。
1.回歸Regression:y^(x)直接作為預測值,損失函數可以采用least square error;2.二值分類Binary Classification:y^(x)需轉化為二值標簽,如0,1。損失函數可以采用hinge loss或logit loss;3.排序Rank:x可能需要轉化為pair-wise的形式如(X^a,X^b),損失函數可以采用pairwise loss
4、模型的學習方法
前面提到FM目標函數可以在線性時間內完成,那么對于大多數的損失函數而言,FM里面的參數w和v更新通過隨機梯度下降SGD的方法同樣可以在線性時間內完成,比如logit loss,hinge loss,square loss,模型參數的梯度計算如下:
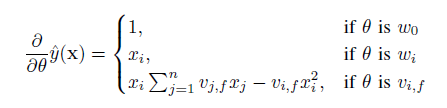
這部分求和跟樣本i是獨立的,因此可以預先計算好。
5、模型延伸:多元交叉
前面提到到都是二元交叉,其實可以延伸到多元交叉,目標函數如下:(看起來復雜度好像很高,其實也是可以在線性時間內完成的)
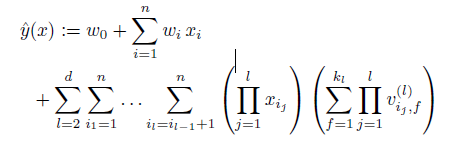
6、總結
前面簡單地介紹了FM模型,總的來說,FM通過向量交叉學習的方式來挖掘特征之間的相關性,有以下兩點好處:
1.在高度稀疏的條件下能夠更好地挖掘數據特征間的相關性,尤其是對于在訓練樣本中沒出現的交叉數據;
2.FM在計算目標函數和在隨機梯度下降做優化學習時都可以在線性時間內完成。
3.FM算法VS其他算法
1、FM 對比 SVM
1)SVM
SVM是大家熟知的支持向量機模型,其模型原理在這里就不詳述了。
SVM的線性模型函數表示為:
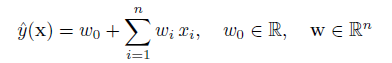
其非線性形式可以通過核映射kernel mapping的方式得到,如下所示:
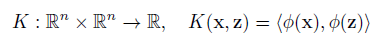
其中多項式核表示為:
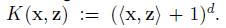
當d=2時為二次多項式,表示為:
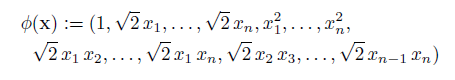
多項式核映射后的模型函數表示為:
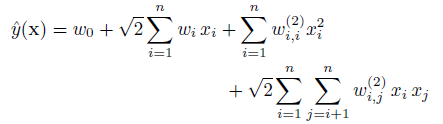
2)FM 對比 SVM
看到上面的式子,是不是覺得跟FM特別像?SVM和FM的主要區別在于,SVM的二元特征交叉參數是獨立的,如wij,而FM的二元特征交叉參數是兩個k維的向量vi、vj,這樣子的話,<vi,vj>和<vi,vk>就不是獨立的,而是相互影響的。
為什么線性SVM在和多項式SVM在稀疏條件下效果會比較差呢?線性svm只有一維特征,不能挖掘深層次的組合特征在實際預測中并沒有很好的表現;而多項式svn正如前面提到的,交叉的多個特征需要在訓練集上共現才能被學習到,否則該對應的參數就為0,這樣對于測試集上的case而言這樣的特征就失去了意義,因此在稀疏條件下,SVM表現并不能讓人滿意。而FM不一樣,通過向量化的交叉,可以學習到不同特征之間的交互,進行提取到更深層次的抽象意義。
此外,FM和SVM的區別還體現在:1)FM可以在原始形式下進行優化學習,而基于kernel的非線性SVM通常需要在對偶形式下進行;2)FM的模型預測是與訓練樣本獨立,而SVM則與部分訓練樣本有關,即支持向量。
2、FM 對比 其他分解模型Fac torization Model
這部分不詳述,其他分解模型包括Matrix factorization (MF)、SVD++、PITF for Tag Recommendation、Factorized Personalized Markov Chains (FPMC),這些模型都只在特定場景下使用,輸入形式也比較單一(比如MF只適用于categorical variables),而FM通過對輸入特征進行轉換,同樣可可以實現以上模型的功能,而且FM的輸入可以是任意實數域的數據,因此FM是一個更為泛化和通用的模型。詳細內容參考:https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf
4.推薦算法總結
目前為止,我們常推薦算法有好多種,比較常見的有協同過濾(Collaborative Filtering Recommendations)這個在Mahout里的ItemCF和UserCF比較常用,還有一種比較新的運行在Spark上的交替性最小二乘ALS也是一種協同過濾的算法,但是其它的推薦算法也有很多,在日常中也用的比較多,就做個總結吧。
1、基于內容的推薦算法(Content Based Recommendation 簡稱CB)
這種推薦是從信息檢索,和文本檢索里來的,個人理解為是搜索引擎里的搜索排行。TD-IDF計算文章的詞頻和反文檔頻率計算出關鍵詞在文檔中的權值,最后構成某篇文章的特征向量。基于該文章的特征向量和其它文章的特征向量進行余弦相似度計算,從而返回最匹配相似的文章來給予推薦。
可以簡單概括為: 抽取item的特征向量 -> 計算余弦相似度 -> 推薦
item可以是用戶過去喜歡的電影,商品,問題等等。
基于內容的過濾創建了每個商品、用戶的屬性(或是組合)用來描述其本質。比如對于電影來說,可能包括演員、票房程度等。 用戶屬性信息可能包含地理信息、問卷調查的回答等。這些屬性信息關聯用戶用戶后即可達到匹配商品的目的。 當然基于內容的策略極有可能因為信息收集的不便而導致無法實施。
CB的優點:
-
用戶之間的獨立性(User Independence):既然每個用戶的profile都是依據他本身對item的喜好獲得的,自然就與他人的行為無關。而CF剛好相反,CF需要利用很多其他人的數據。CB的這種用戶獨立性帶來的一個顯著好處是別人不管對item如何作弊(比如利用多個賬號把某個產品的排名刷上去)都不會影響到自己。
-
好的可解釋性(Transparency):如果需要向用戶解釋為什么推薦了這些產品給他,你只要告訴他這些產品有某某屬性,這些屬性跟你的品味很匹配等等。
-
新的item可以立刻得到推薦(New Item Problem):只要一個新item加進item庫,它就馬上可以被推薦,被推薦的機會和老的item是一致的。而CF對于新item就很無奈,只有當此新item被某些用戶喜歡過(或打過分),它才可能被推薦給其他用戶。所以,如果一個純CF的推薦系統,新加進來的item就永遠不會被推薦:( 。
CB的缺點:
-
item的特征抽取一般很難(Limited Content Analysis):如果系統中的item是文檔(如個性化閱讀中),那么我們現在可以比較容易地使用信息檢索里的方法來“比較精確地”抽取出item的特征。但很多情況下我們很難從item中抽取出準確刻畫item的特征,比如電影推薦中item是電影,社會化網絡推薦中item是人,這些item屬性都不好抽。其實,幾乎在所有實際情況中我們抽取的item特征都僅能代表item的一些方面,不可能代表item的所有方面。這樣帶來的一個問題就是可能從兩個item抽取出來的特征完全相同,這種情況下CB就完全無法區分這兩個item了。比如如果只能從電影里抽取出演員、導演,那么兩部有相同演員和導演的電影對于CB來說就完全不可區分了。
-
無法挖掘出用戶的潛在興趣(Over-specialization):既然CB的推薦只依賴于用戶過去對某些item的喜好,它產生的推薦也都會和用戶過去喜歡的item相似。如果一個人以前只看與推薦有關的文章,那CB只會給他推薦更多與推薦相關的文章,它不會知道用戶可能還喜歡數碼。
-
無法為新用戶產生推薦(New User Problem):新用戶沒有喜好歷史,自然無法獲得他的profile,所以也就無法為他產生推薦了。當然,這個問題CF也有。
2、基于協同過濾的推薦算法(Collaborative Filtering Recommendations)
基于協同過濾的推薦,可以理解為基于用戶行為的推薦。依賴于用戶過去的行為的協同過濾,行為可以是過往的交易行為和商品評分,這種方式不需要顯性的屬性信息。協同過濾通過分析用戶和商品的內在關系來識別新的 user-item 關系。
協同過濾領域主要的兩種方式是最近鄰(neighborhood)方法和潛在因子(latent factor)模型。最近鄰方法主要集中在 item 的關系或者是 user 的關系,是比較基礎的過濾引擎。而潛在因子模型并不是選取所有的關系,而是通過矩陣分解的技術將共現矩陣的分解,比如提取20-100個因子,來表示原始矩陣信息(可以對比上面提到的音樂基因,只不過潛在因子模型是通過計算機化的實現)。
最鄰近:
基于用戶的協同過濾算法: 基于一個這樣的假設“跟你喜好相似的人喜歡的東西你也很有可能喜歡。”所以基于用戶的協同過濾主要的任務就是找出用戶的最近鄰居,從而根據最近鄰 居的喜好做出未知項的評分預測。
item based CF 基于物品相似的協同過濾。
user based CF 基于用戶相似的協同過濾。
潛在引子模型:
SVD奇異值分解矩陣
ALS交替最小二乘
總結為: 用戶評分 -> 計算最鄰近 -> 推薦
3、算法對比
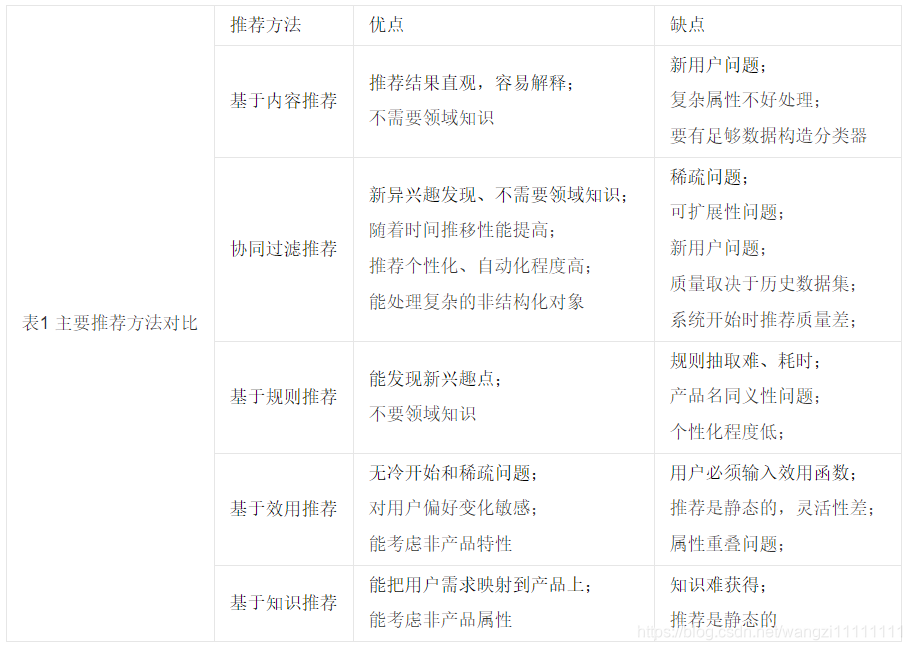
各種推薦方法都有其各自的優點和缺點,見表1。
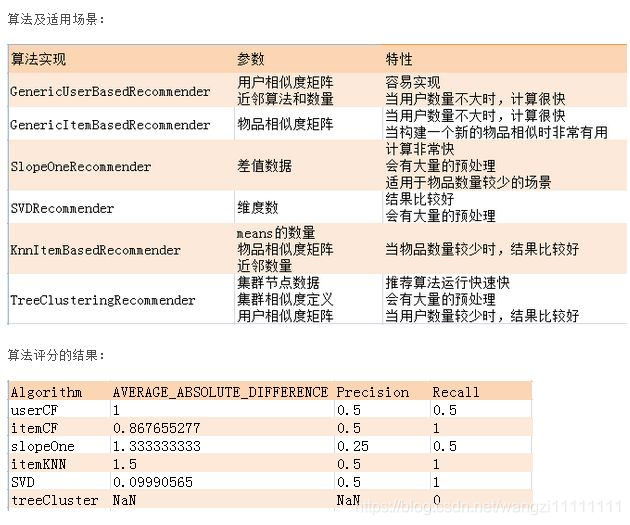
4、 Mahout里的推薦算法
5、總結
沒有最那一種算法能解決所有問題,混合算法有效結合每個算法的利弊才能達到最好的效果。
一個比較成功的內容過濾是 pandora.com 的音樂基因項目,一個訓練有素的音樂分析師會對每首歌里幾百個獨立的特征進行打分。這些得分幫助pandora推薦歌曲。還有一種基于內容的過濾是基于用戶人口統計特征的推薦,先根據人口統計學特征將用戶分成若干個先驗的類。對后來的任意一個用戶,首先找到他的聚類,然后給他推薦這個聚類里的其他用戶喜歡的物品。這種方法的雖然推薦的粒度太粗,但可以有效解決注冊用戶的冷啟動(Cold Start)的問題。

-Pycharm基本使用技巧)
)


)
組合模式)
--Pycharm安裝、使用小技巧)
)

)
-注釋)


)
)

)

-算數運算符)