文章目錄
- 目錄
- 1.什么是數據倉庫?
- 1.1數據倉庫概念
- 1.2傳統數據倉庫面臨的挑戰
- 1.3 Hive介紹
- 1.4 Hive與傳統數據庫的對比
- 1.5 Hive在企業中的部署與應用
- 2.Hive系統架構
- 3.Hive工作原理
- 3.1 SQL轉換為MapReduce作業的基本原理
- 3.2 Hive中SQL查詢轉換MapReduce作業的過程
- 4.Hive HA基本原理
- 5.Impala
- 5.1 Impala介紹
- 5.2 Impala系統架構
- 5.3 Impala查詢執行過程
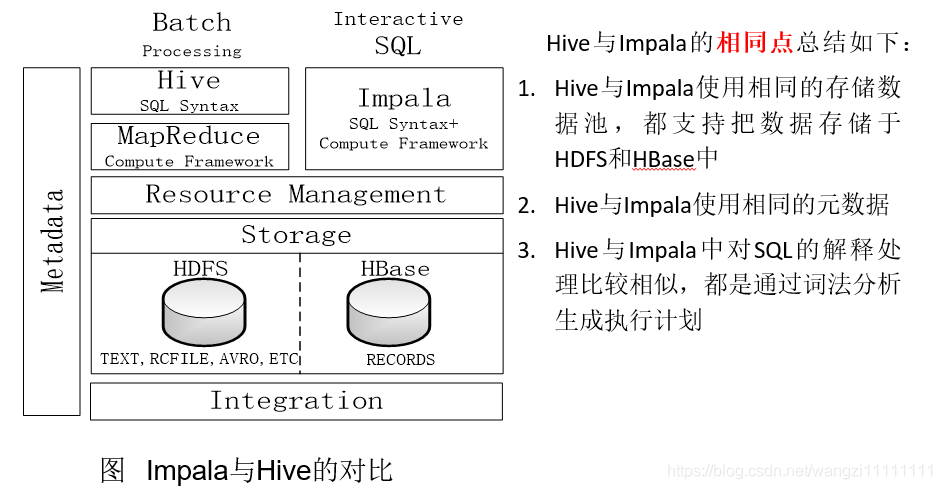
- 5.4 Impala和Hive的區別
- 6.Hive編程實踐
- 6.1 Hive的安裝和配置
- 6.2 Hive的基本數據類型
- 6.3 Hive的基本操作
- 6.4 Hive的應用實例(wordCount)
- 6.5 Hive的優勢
- 7.總結
目錄
1.什么是數據倉庫?
1.1數據倉庫概念
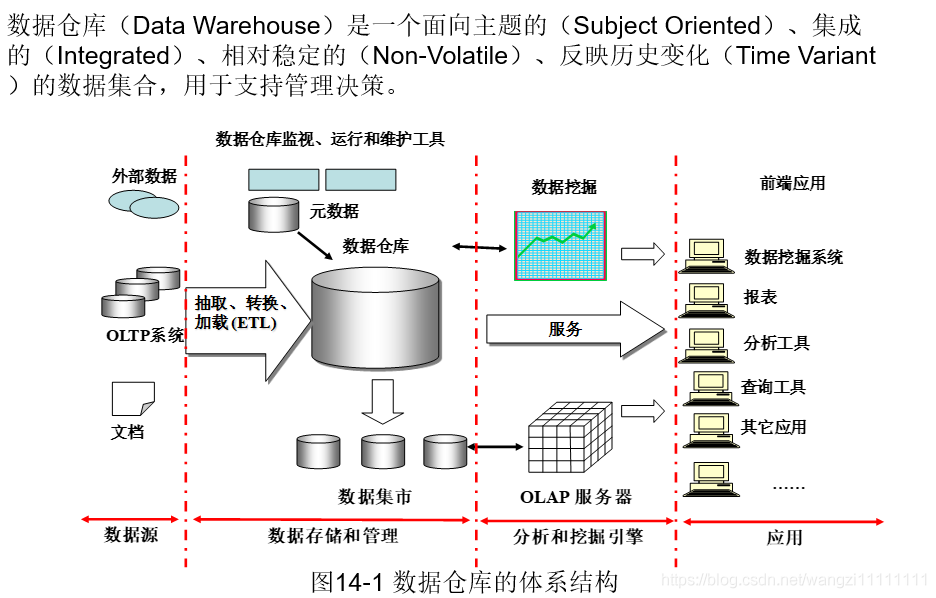
對歷史數據變化的統計,從而支撐企業的決策。比如:某個商品最近一個月的銷量,預判下個月應該銷售多少,從而補充多少貨源。
1.2傳統數據倉庫面臨的挑戰

1.3 Hive介紹


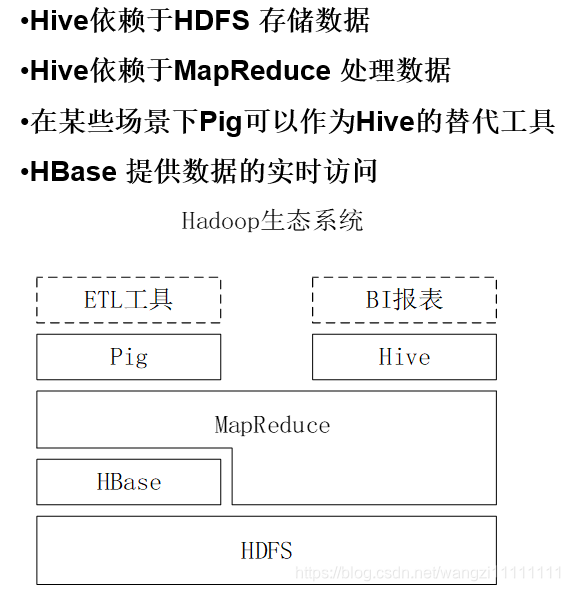
Hbase支持快速的交互式的大數據應用
pig,Hive支持批量式的數據分析業務
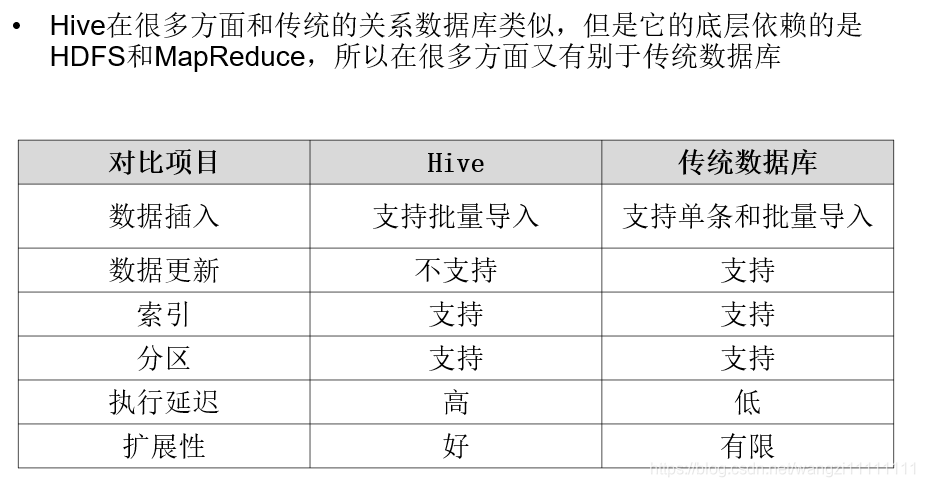
1.4 Hive與傳統數據庫的對比
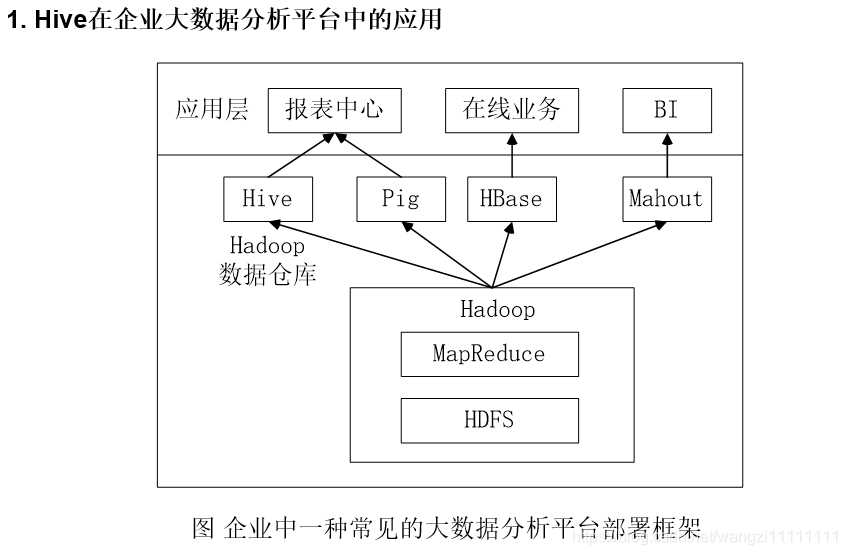
1.5 Hive在企業中的部署與應用
2.Hive系統架構
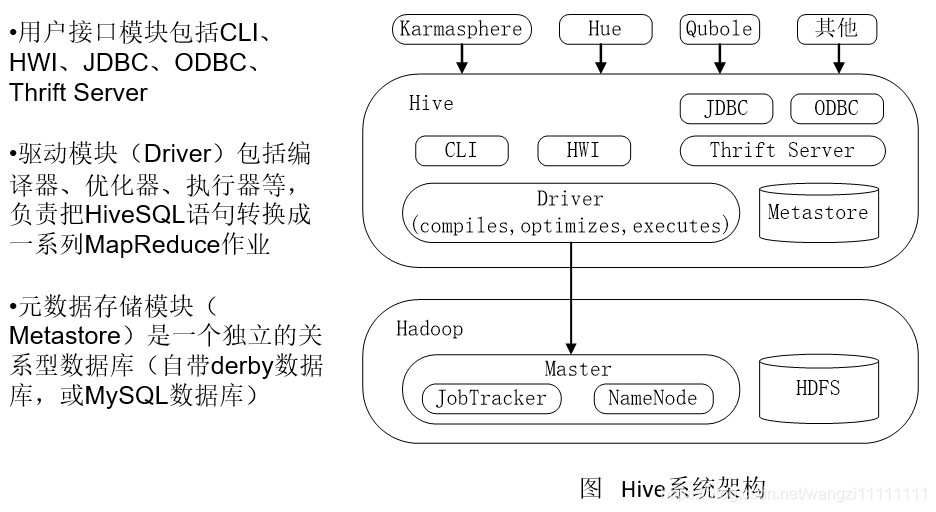
Microsoft推出的ODBC(Open Database Connectivity)技術 [1] 為異質數據庫的訪問提供了統一的接口
JDBC(Java Data Base Connectivity,java數據庫連接)是一種用于執行SQL語句的Java API,可以為多種關系數據庫提供統一訪問,它由一組用Java語言編寫的類和接口組成。
CIL (Common Intermediate Language) 公共中間語言
3.Hive工作原理
3.1 SQL轉換為MapReduce作業的基本原理
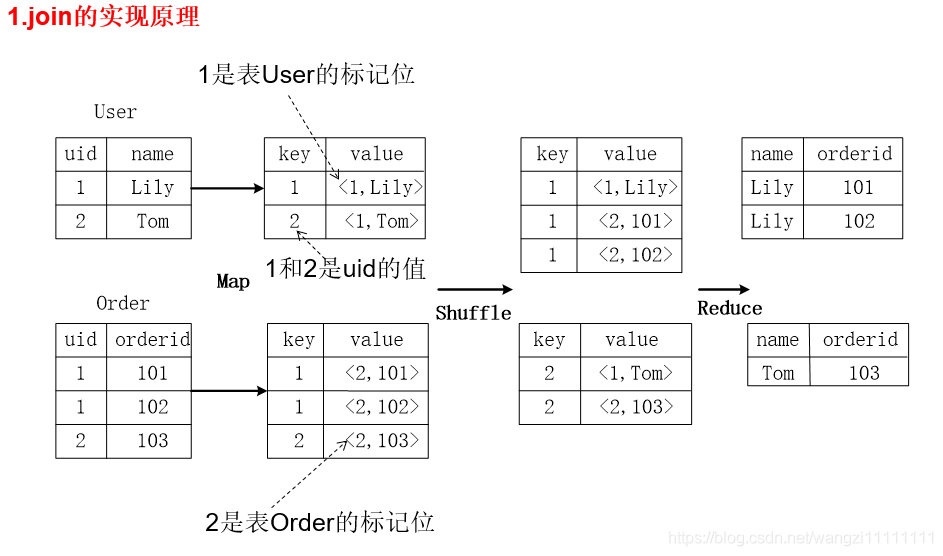
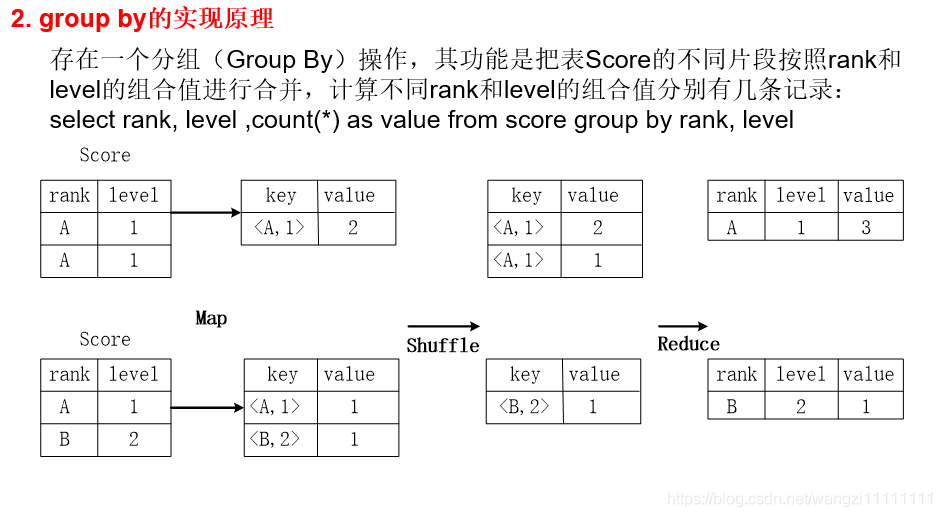
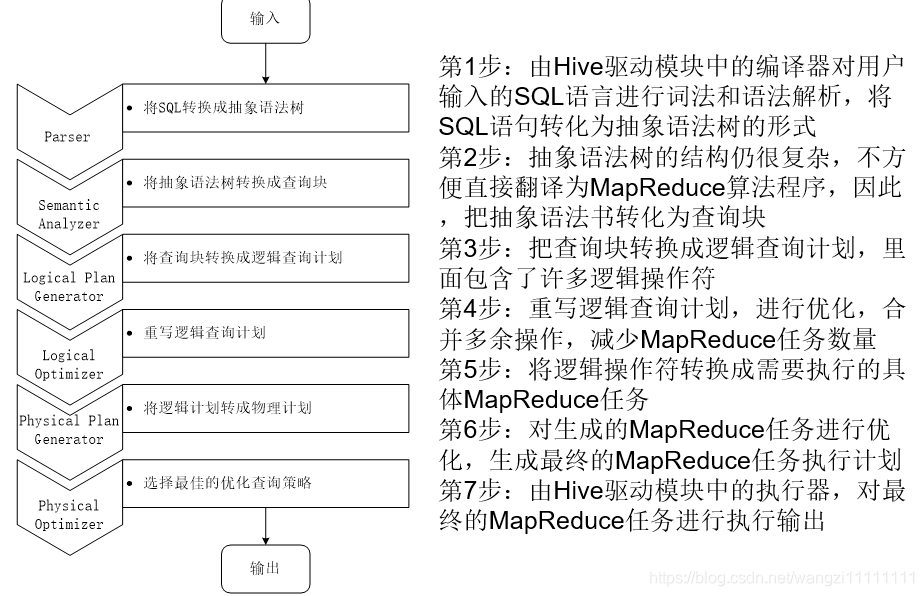
3.2 Hive中SQL查詢轉換MapReduce作業的過程


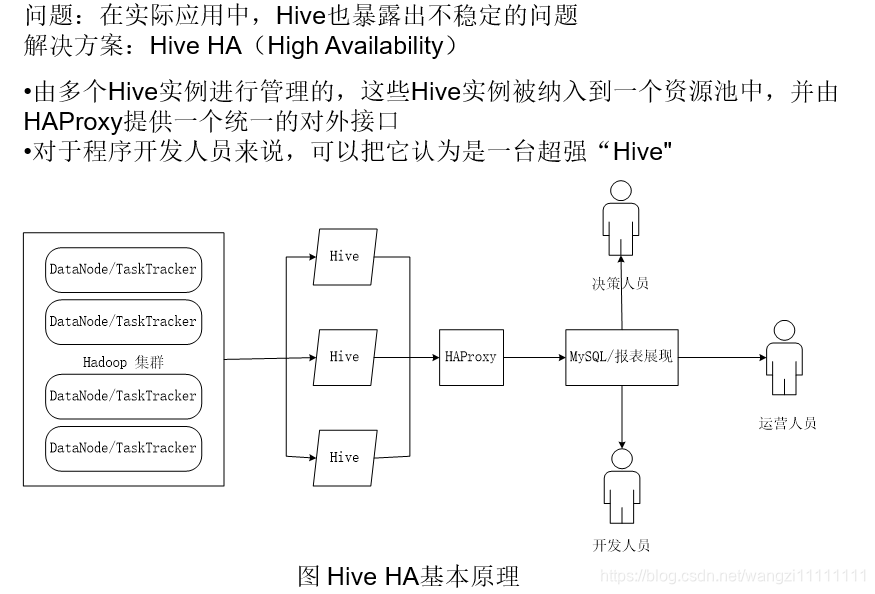
4.Hive HA基本原理
5.Impala
5.1 Impala介紹

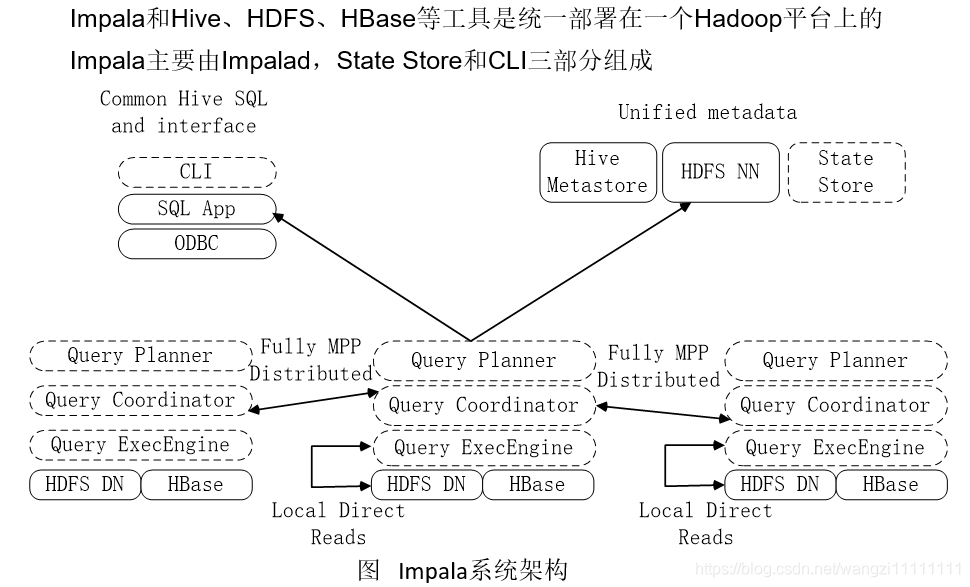
5.2 Impala系統架構

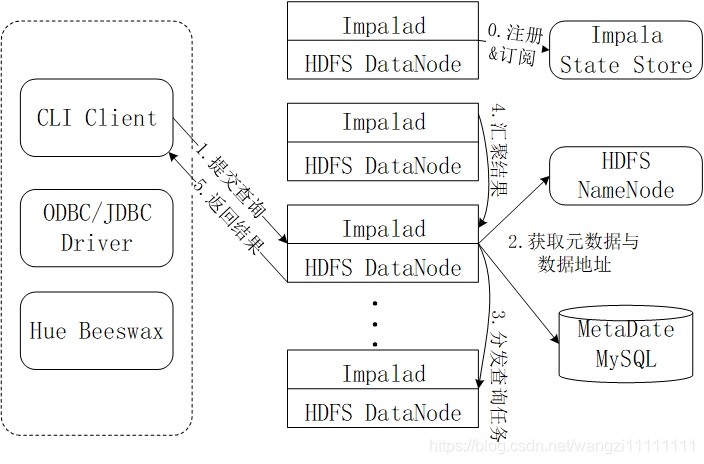
5.3 Impala查詢執行過程


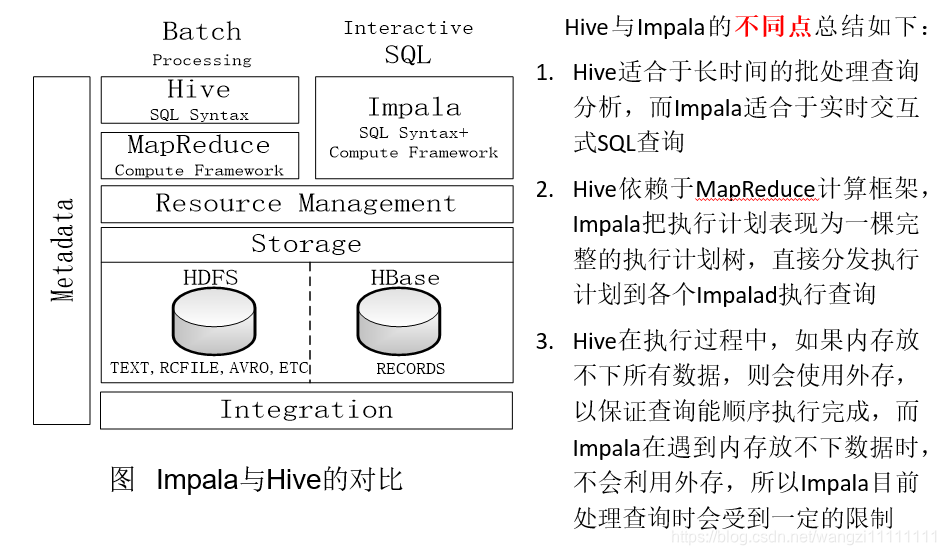
5.4 Impala和Hive的區別

6.Hive編程實踐
參考博客
6.1 Hive的安裝和配置

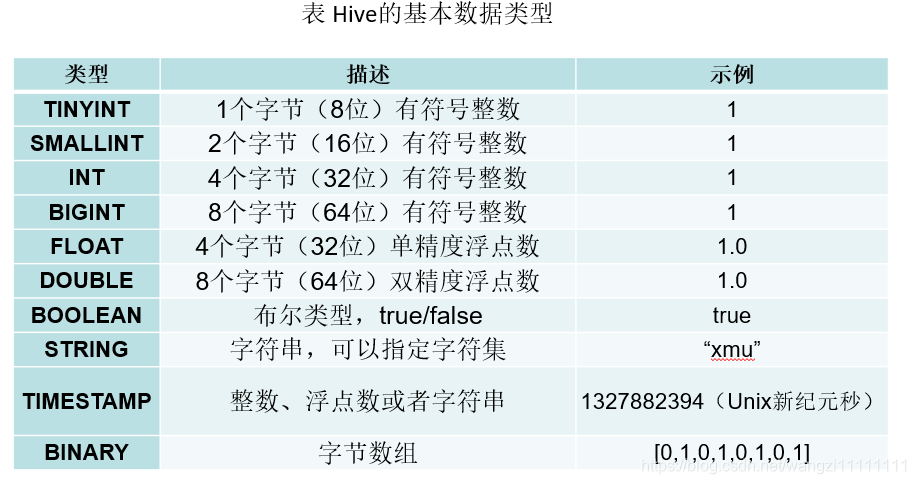
6.2 Hive的基本數據類型

6.3 Hive的基本操作






6.4 Hive的應用實例(wordCount)


6.5 Hive的優勢

7.總結



-mySQL數據庫鏈接錯誤)


-讀寫mat文件)


靜態工廠方法模式)

-for-enumerate()-zip())




--Hadoop2.0介紹)

-圖像分類常用數據集)

函數分析)