Dubbo 支持哪些協議,每種協議的應用場景,優缺點?
? dubbo: 單一長連接和 NIO 異步通訊,適合大并發小數據量的服務調用,
?以及消費者遠大于提供者。傳輸協議 TCP,異步,Hessian 序列化;
? rmi: 采用 JDK 標準的 rmi 協議實現,傳輸參數和返回參數對象需要實現
Serializable 接口,使用 java 標準序列化機制,使用阻塞式短連接,傳輸數
據包大小混合,消費者和提供者個數差不多,可傳文件,傳輸協議 TCP。
多個短連接,TCP 協議傳輸,同步傳輸,適用常規的遠程服務調用和 rmi 互
操作。在依賴低版本的 Common-Collections 包,java 序列化存在安全漏 洞;
? webservice: 基于 WebService 的遠程調用協議,集成 CXF 實現,提供和
原生 WebService 的互操作。多個短連接,基于 HTTP 傳輸,同步傳輸,適
用系統集成和跨語言調用;
? http: 基于 Http 表單提交的遠程調用協議,使用 Spring 的 HttpInvoke 實
?現。多個短連接,傳輸協議 HTTP,傳入參數大小混合,提供者個數多于消
?費者,需要給應用程序和瀏覽器 JS 調用;
? hessian: 集成 Hessian 服務,基于 HTTP 通訊,采用 Servlet 暴露服務,
Dubbo 內嵌 Jetty 作為服務器時默認實現,提供與 Hession 服務互操作。多
個短連接,同步 HTTP 傳輸,Hessian 序列化,傳入參數較大,提供者大于
消費者,提供者壓力較大,可傳文件;
? memcache: 基于 memcached 實現的 RPC 協議
? redis: 基于 redis 實現的 RPC 協議
Dubbo 超時時間怎樣設置?
Dubbo 超時時間設置有兩種方式:
? 服務提供者端設置超時時間,在 Dubbo 的用戶文檔中,推薦如果能在服務
端多配置就盡量多配置,因為服務提供者比消費者更清楚自己提供的服務特
性。
? 服務消費者端設置超時時間,如果在消費者端設置了超時時間,以消費者端
為主,即優先級更高。因為服務調用方設置超時時間控制性更靈活。如果消
費方超時,服務端線程不會定制,會產生警告。
Dubbo 有些哪些注冊中心?
? Multicast 注冊中心: Multicast 注冊中心不需要任何中心節點,只要廣播地
址,就能進行服務注冊和發現。基于網絡中組播傳輸實現;
? Zookeeper 注冊中心: 基于分布式協調系統 Zookeeper 實現,采用
?Zookeeper 的 watch 機制實現數據變更;
? redis 注冊中心: 基于 redis 實現,采用 key/Map 存儲,住 key 存儲服務名
?和類型,Map 中 key 存儲服務 URL,value 服務過期時間。基于 redis 的發
?布/訂閱模式通知數據變更;
? Simple 注冊中心
Dubbo 集群的負載均衡有哪些策略
?
?
Dubbo 提供了常見的集群策略實現,并預擴展點予以自行實現。
? Random LoadBalance: 隨機選取提供者策略,有利于動態調整提供者權
重。截面碰撞率高,調用次數越多,分布越均勻;
? RoundRobin LoadBalance: 輪循選取提供者策略,平均分布,但是存在請
求累積的問題;
? LeastActive LoadBalance: 最少活躍調用策略,解決慢提供者接收更少的
請求;
? ConstantHash LoadBalance: 一致性 Hash 策略,使相同參數請求總是發
到同一提供者,一臺機器宕機,可以基于虛擬節點,分攤至其他提供者,避
免引起提供者的劇烈變動;
Dubbo 是什么?
? Dubbo 是一個分布式、高性能、透明化的 RPC 服務框架,提
供服務自動注冊、自動發現等高效服務治理方案, 可以和
Spring 框架無縫集成。
? Dubbo 的主要應用場景?
? 透明化的遠程方法調用,就像調用本地方法一樣調用遠程方法,
只需簡單配置,沒有任何 API 侵入。
? 軟負載均衡及容錯機制,可在內網替代 F5 等硬件負載均衡器,
降低成本,減少單點。
? 服務自動注冊與發現,不再需要寫死服務提供方地址,注冊中心
基于接口名查詢服務提供者的 IP 地址,并且能夠平滑添加或刪
除服務提供者。
Dubbo 的核心功能?
?
?
. Remoting:網絡通信框架,提供對多種 NIO 框架抽象封裝,包括
“同步轉異步”和“請求-響應”模式的信息交換方式。
. Cluster:服務框架,提供基于接口方法的透明遠程過程調用,包括多
協議支持,以及軟負載均衡,失敗容錯,地址路由,動態配置等集群
支持。
. Registry:服務注冊,基于注冊中心目錄服務,使服務消費方能動態
的查找服務提供方,使地址透明,使服務提供方可以平滑增加或減少
機器。
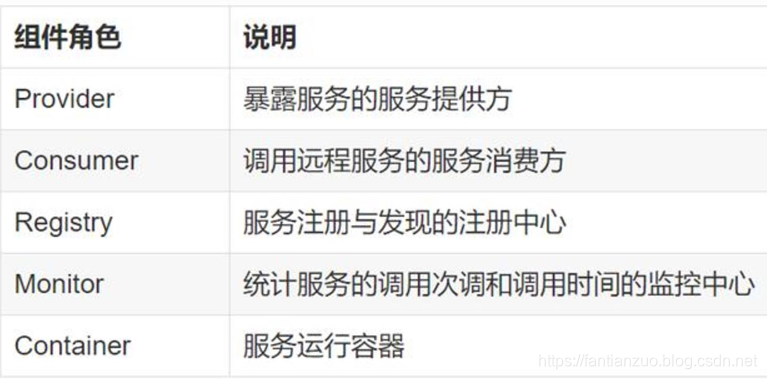
. Dubbo 的核心組件?
.
Dubbo 服務注冊與發現的流程?
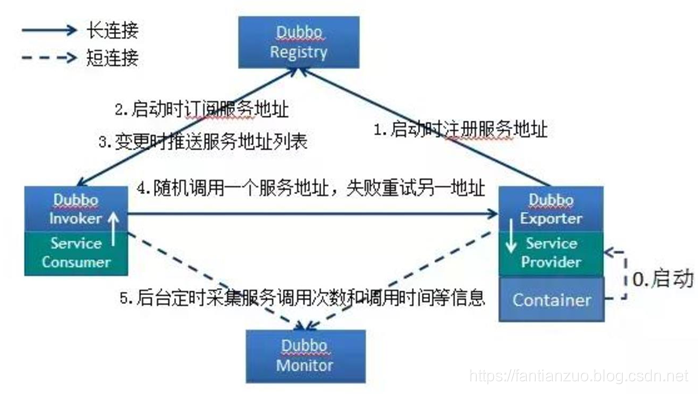
?
流程說明:
. Provider(提供者)綁定指定端口并啟動服務
. 指供者連接注冊中心,并發本機 IP、端口、應用信息和提供服務信息
發送至注冊中心存儲
. Consumer(消費者),連接注冊中心 ,并發送應用信息、所求服務信
息至注冊中心
. 注冊中心根據 消費 者所求服務信息匹配對應的提供者列表發送至
Consumer 應用緩存。
. Consumer 在發起遠程調用時基于緩存的消費者列表擇其一發起調
用。
. Provider 狀態變更會實時通知注冊中心、在由注冊中心實時推送至
Consumer
?
?
設計的原因:
. Consumer 與 Provider 解偶,雙方都可以橫向增減節點數。
. 注冊中心對本身可做對等集群,可動態增減節點,并且任意一臺宕掉
后,將自動切換到另一臺
. 去中心化,雙方不直接依懶注冊中心,即使注冊中心全部宕機短時間
內也不會影響服務的調用
. 服務提供者無狀態,任意一臺宕掉后,不影響使用
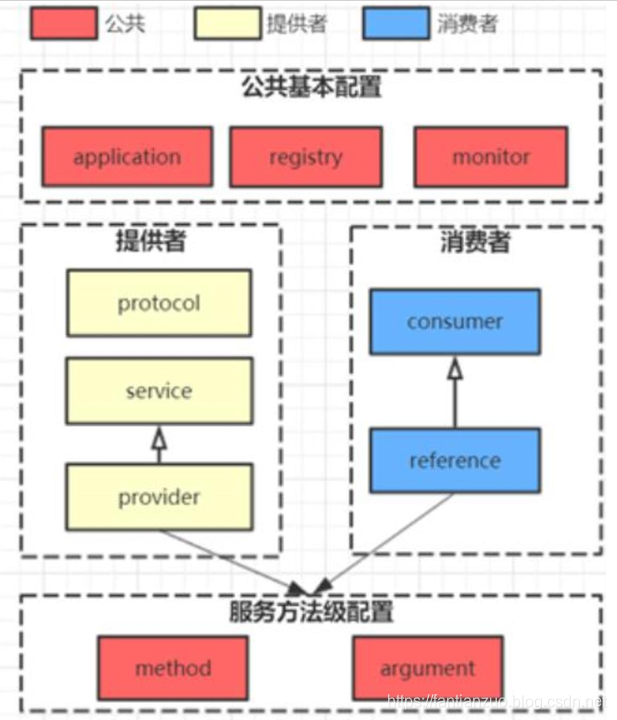
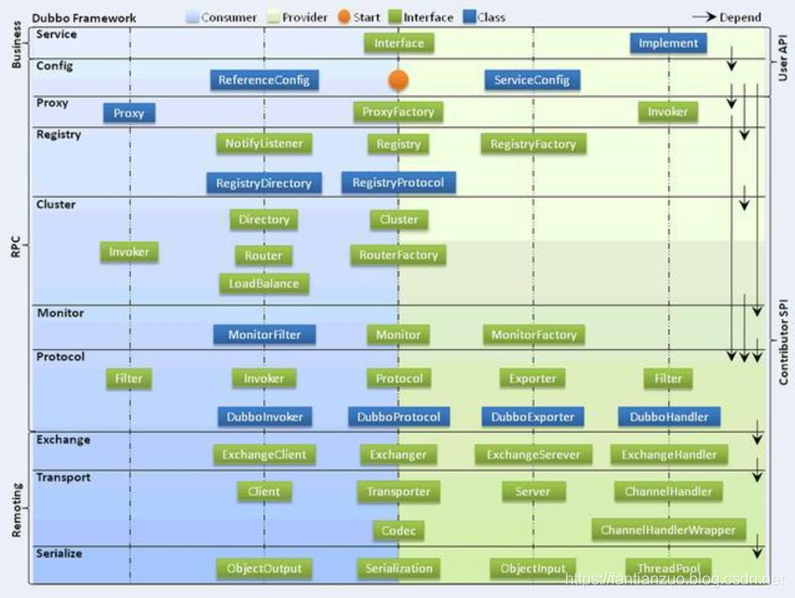
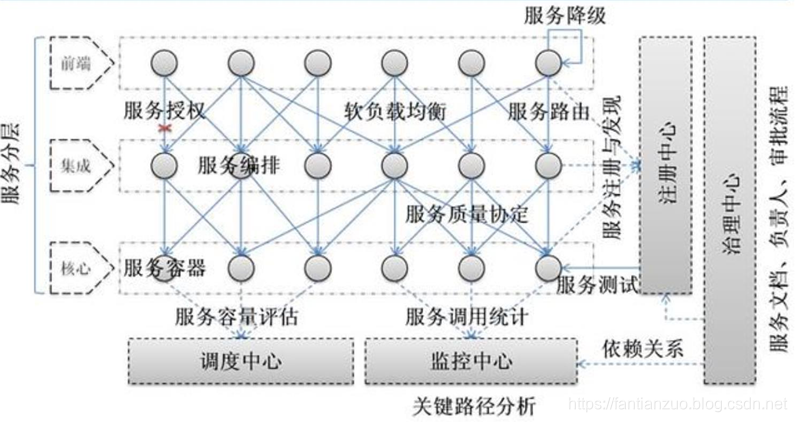
Dubbo 的架構設計?
?
Dubbo 框架設計一共劃分了 10 個層:
. 服務接口層(Service):該層是與實際業務邏輯相關的,根據服務提供方和服務消費方的業務設計對應的接口和實現。
. 配置層(Config):對外配置接口,以 ServiceConfig 和ReferenceConfig 為中心。
. 服務代理層(Proxy):服務接口透明代理,生成服務的客戶端 Stub和服務器端 Skeleton。
?服務注冊層(Registry):封裝服務地址的注冊與發現,以服務 URL為中心。
?
. 集群層(Cluster):封裝多個提供者的路由及負載均衡,并橋接注冊中心,以 Invoker 為中心。
. 監控層(Monitor):RPC 調用次數和調用時間監控。
. 遠程調用層(Protocol):封將 RPC 調用,以 Invocation 和 Result為中心,擴展接口為 Protocol、Invoker 和 Exporter。
. 信息交換層(Exchange):封裝請求響應模式,同步轉異步,以Request 和 Response 為中心。
. 網絡傳輸層(Transport):抽象 mina 和 netty 為統一接口,以Message 為中心。
?
?
Dubbo 支持哪些協議,每種協議的應用場景,優缺點?
. dubbo: 單一長連接和 NIO 異步通訊,適合大并發小數據量的服務
調用,以及消費者遠大于提供者。傳輸協議 TCP,異步,Hessian 序
列化;
. rmi: 采用 JDK 標準的 rmi 協議實現,傳輸參數和返回參數對象需要
實現 Serializable 接口,使用 java 標準序列化機制,使用阻塞式短連
接,傳輸數據包大小混合,消費者和提供者個數差不多,可傳文件,
?
傳輸協議 TCP。 多個短連接,TCP 協議傳輸,同步傳輸,適用常規的
遠程服務調用和 rmi 互操作。在依賴低版本的 Common-Collections
包,java 序列化存在安全漏洞;
. webservice: 基于 WebService 的遠程調用協議,集成 CXF 實現,
提供和原生 WebService 的互操作。多個短連接,基于 HTTP 傳輸,
同步傳輸,適用系統集成和跨語言調用;
. http: 基于 Http 表單提交的遠程調用協議,使用 Spring 的
HttpInvoke 實現。多個短連接,傳輸協議 HTTP,傳入參數大小混
合,提供者個數多于消費者,需要給應用程序和瀏覽器 JS 調用;
. hessian: 集成 Hessian 服務,基于 HTTP 通訊,采用 Servlet 暴露
服務,Dubbo 內嵌 Jetty 作為服務器時默認實現,提供與 Hession 服
務互操作。多個短連接,同步 HTTP 傳輸,Hessian 序列化,傳入參
數較大,提供者大于消費者,提供者壓力較大,可傳文件;
. memcache: 基于 memcached 實現的 RPC 協議
. redis: 基于 redis 實現的 RPC 協議
dubbo 推薦用什么協議?
默認使用 dubbo 協議
Dubbo 有些哪些注冊中心?
. Multicast 注冊中心: Multicast 注冊中心不需要任何中心節點,只
要廣播地址,就能進行服務注冊和發現。基于網絡中組播傳輸實現;
?
. Zookeeper 注冊中心: 基于分布式協調系統 Zookeeper 實現,采用
?
Zookeeper 的 watch 機制實現數據變更;
. redis 注冊中心: 基于 redis 實現,采用 key/Map 存儲,住 key 存儲
服務名和類型,Map 中 key 存儲服務 URL,value 服務過期時間。基
于 redis 的發布/訂閱模式通知數據變更;
. Simple 注冊中心
Dubbo 默認采用注冊中心?
采用 Zookeeper
為什么需要服務治理?
. 過多的服務 URL 配置困難
. 負載均衡分配節點壓力過大的情況下也需要部署集群
?
. 過多服務導致性能指標分析難度較大,需要監控
Dubbo 的注冊中心集群掛掉,發布者和訂閱者之間還能通信么?
可以的,啟動 dubbo 時,消費者會從 zookeeper 拉取注冊的生產者
的地址接口等數據,緩存在本地。
每次調用時,按照本地存儲的地址進行調用。
Dubbo 與 Spring 的關系?
Dubbo 采用全 Spring 配置方式,透明化接入應用,對應用沒有任何
API 侵入,只需用 Spring 加載 Dubbo 的配置即可,Dubbo 基于
Spring 的 Schema 擴展進行加載。
Dubbo 使用的是什么通信框架?
默認使用 NIO Netty 框架
Dubbo 集群提供了哪些負載均衡策略?
Random LoadBalance: 隨機選取提供者策略,有利于動態調整提供者權重。截面碰撞率高,調用次數越多,分布越均勻;
RoundRobin LoadBalance: 輪循選取提供者策略,平均分布,但是存在請求累積的問題;
LeastActive LoadBalance: 最少活躍調用策略,解決慢提供者接收更少的請求;
ConstantHash LoadBalance: 一致性 Hash 策略,使相同參數請求
?
總是發到同一提供者,一臺機器宕機,可以基于虛擬節點,分攤至其
他提供者,避免引起提供者的劇烈變動;
缺省時為 Random 隨機調用
Dubbo 的集群容錯方案有哪些?
. Failover Cluster
. 失敗自動切換,當出現失敗,重試其它服務器。通常用于讀操作,但重試會帶來更長延遲。
. Failfast Cluster
. 快速失敗,只發起一次調用,失敗立即報錯。通常用于非冪等性的寫操作,比如新增記錄。
. Failsafe Cluster
. 失敗安全,出現異常時,直接忽略。通常用于寫入審計日志等操作。
. Failback Cluster
. 失敗自動恢復,后臺記錄失敗請求,定時重發。通常用于消息通知操作。
. Forking Cluster
并行調用多個服務器,只要一個成功即返回。通常用于實時性要求較高的讀操作,但需要浪費更多服務資源。可通過 forks="2" 來設置最大并行數。
?
. Broadcast Cluster
. 廣播調用所有提供者,逐個調用,任意一臺報錯則報錯 。通常用于通知所有提供者更新緩存或日志等本地資源信息。
Dubbo 的默認集群容錯方案?
Failover Cluster
Dubbo 支持哪些序列化方式?
默認使用 Hessian 序列化,還有 Duddo、FastJson、Java 自帶序列
化。
Dubbo 超時時間怎樣設置?
Dubbo 超時時間設置有兩種方式:
. 服務提供者端設置超時時間,在 Dubbo 的用戶文檔中,推薦如果能
在服務端多配置就盡量多配置,因為服務提供者比消費者更清楚自己
提供的服務特性。
. 服務消費者端設置超時時間,如果在消費者端設置了超時時間,以消
費者端為主,即優先級更高。因為服務調用方設置超時時間控制性更
靈活。如果消費方超時,服務端線程不會定制,會產生警告。
?
服務調用超時問題怎么解決?
dubbo 在調用服務不成功時,默認是會重試兩次的。
Dubbo 在安全機制方面是如何解決?
Dubbo 通過 Token 令牌防止用戶繞過注冊中心直連,然后在注冊中
心上管理授權。Dubbo 還提供服務黑白名單,來控制服務所允許的調
用方。
Dubbo 和 Dubbox 之間的區別?
dubbox 基于 dubbo 上做了一些擴展,如加了服務可 restful 調
用,更新了開源組件等。
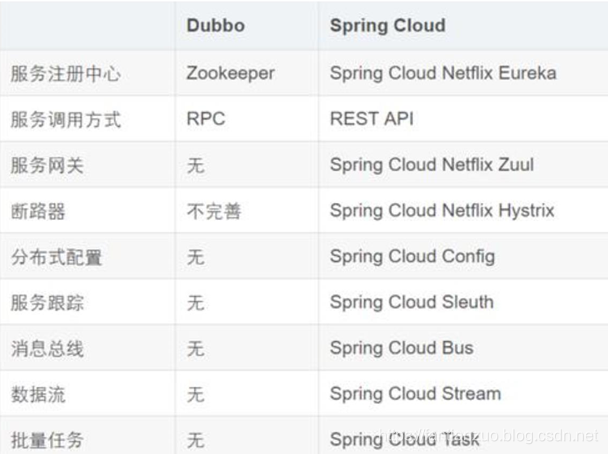
Dubbo 和 Spring Cloud 的關系?
Dubbo 是 SOA 時代的產物,它的關注點主要在于服務的調用,流
量分發、流量監控和熔斷。而 Spring Cloud 誕生于微服務架構時
代,考慮的是微服務治理的方方面面,另外由于依托了 Spirng、
Spirng Boot 的優勢之上,兩個框架在開始目標就不一致,Dubbo
定位服務治理、Spirng Cloud 是一個生態。
Dubbo 和 Spring Cloud 的區別?
最大的區別:Dubbo 底層是使用 Netty 這樣的 NIO 框架,是基于
?
TCP 協議傳輸的,配合以 Hession 序列化完成 RPC 通信。
而 SpringCloud 是基于 Http 協議+Rest 接口調用遠程過程的通信,
相對來說,Http 請求會有更大的報文,占的帶寬也會更多。但是
REST 相比 RPC 更為靈活,服務提供方和調用方的依賴只依靠一紙契
約,不存在代碼級別的強依賴。
?Dubbo 中 zookeeper 做注冊中心,如果注冊中心集群都掛掉,發布者和訂閱者之間還能通信么?
可以通信的,啟動 dubbo 時,消費者會從 zk 拉取注冊的生產者的地址接口等數據,緩存在本地。每次調用時,按照本
地存儲的地址進行調用;
注冊中心對等集群,任意一臺宕機后,將會切換到另一臺;注冊中心全部宕機后,服務的提供者和消費者仍能通過本
地緩存通訊。服務提供者無狀態,任一臺 宕機后,不影響使用;服務提供者全部宕機,服務消費者會無法使用,并無
限次重連等待服務者恢復;
掛掉是不要緊的,但前提是你沒有增加新的服務,如果你要調用新的服務,則是不能辦到的。
附文檔截圖:
dubbo 服務負載均衡策略?
l Random LoadBalance
隨機,按權重設置隨機概率。在一個截面上碰撞的概率高,但調用量越大分布越均勻,而且按概率使用權重后也比
較均勻,有利于動態調整提供者權重。(權重可以在 dubbo 管控臺配置)
l RoundRobin LoadBalance
輪循,按公約后的權重設置輪循比率。存在慢的提供者累積請求問題,比如:第二臺機器很慢,但沒掛,當請求調
到第二臺時就卡在那,久而久之,所有請求都卡在調到第二臺上。
l LeastActive LoadBalance
最少活躍調用數,相同活躍數的隨機,活躍數指調用前后計數差。使慢的提供者收到更少請求,因為越慢的提供者的
調用前后計數差會越大。
l ConsistentHash LoadBalance
一致性 Hash,相同參數的請求總是發到同一提供者。當某一臺提供者掛時,原本發往該提供者的請求,基于虛擬節
點,平攤到其它提供者,不會引起劇烈變動。缺省只對第一個參數 Hash
Dubbo 在安全機制方面是如何解決的
Dubbo 通過 Token 令牌防止用戶繞過注冊中心直連,然后在注冊中心上管理授權。Dubbo 還提供服務黑白名單,來控
制服務所允許的調用方。
dubbo 連接注冊中心和直連的區別
在開發及測試環境下,經常需要繞過注冊中心,只測試指定服務提供者,這時候可能需要點對點直連,
點對點直聯方式,將以服務接口為單位,忽略注冊中心的提供者列表,
服務注冊中心,動態的注冊和發現服務,使服務的位置透明,并通過在消費方獲取服務提供方地址列表,實現軟負載
均衡和 Failover, 注冊中心返回服務提供者地址列表給消費者,如果有變更,注冊中心將基于長連接推送變更數據給
消費者。
服務消費者,從提供者地址列表中,基于軟負載均衡算法,選一臺提供者進行調用,如果調用失敗,再選另一臺調
用。注冊中心負責服務地址的注冊與查找,相當于目錄服務,服務提供者和消費者只在啟動時與注冊中心交互,注冊
中心不轉發請求,服務消費者向注冊中心獲取服務提供者地址列表,并根據負載算法直接調用提供者,注冊中心,服
務提供者,服務消費者三者之間均為長連接,監控中心除外,注冊中心通過長連接感知服務提供者的存在,服務提供
者宕機,注冊中心將立即推送事件通知消費者
注冊中心和監控中心全部宕機,不影響已運行的提供者和消費者,消費者在本地緩存了提供者列表
注冊中心和監控中心都是可選的,服務消費者可以直連服務提供者。
?
?
dubbo 通信協議 dubbo 協議為什么要消費者比提供者個數多:
因 dubbo 協議采用單一長連接,假設網絡為千兆網卡(1024Mbit=128MByte),
根據測試經驗數據每條連接最多只能壓滿 7MByte(不同的環境可能不一樣,供參考),理論上 1 個服務提供者需要 20
個服務消費者才能壓滿網卡。
dubbo 通信協議 dubbo 協議為什么不能傳大包:
因 dubbo 協議采用單一長連接,
如果每次請求的數據包大小為 500KByte,假設網絡為千兆網卡(1024Mbit=128MByte),每條連接最大 7MByte(不同的
環境可能不一樣,供參考),
單個服務提供者的 TPS(每秒處理事務數)最大為:128MByte / 500KByte = 262。
單個消費者調用單個服務提供者的 TPS(每秒處理事務數)最大為:7MByte / 500KByte = 14。
?
dubbo 通信協議 dubbo 協議為什么采用異步單一長連接:
因為服務的現狀大都是服務提供者少,通常只有幾臺機器,
而服務的消費者多,可能整個網站都在訪問該服務,
比如 Morgan 的提供者只有 6 臺提供者,卻有上百臺消費者,每天有 1.5 億次調用,
如果采用常規的 hessian 服務,服務提供者很容易就被壓跨,
通過單一連接,保證單一消費者不會壓死提供者,
長連接,減少連接握手驗證等,
并使用異步 IO,復用線程池,防止 C10K 問題。
dubbo 通信協議 dubbo 協議適用范圍和適用場景
適用范圍:傳入傳出參數數據包較小(建議小于 100K),消費者比提供者個數
多,單一消費者無法壓滿提供者,盡量不要用 dubbo協議傳輸大文件或超大字 符串。 適用場景:常規遠程服務方法調用
dubbo協議補充:
連接個數:單連接
連接方式:長連接
傳輸協議:TCP
傳輸方式:NIO 異步傳輸
序列化:Hessian 二進制序列化
RMI 協議
RMI協議采用 JDK標準的 java.rmi.*實現,采用阻塞式短連接和 JDK標準序列
化方式,Java標準的遠程調用協議。
連接個數:多連接
連接方式:短連接
傳輸協議:TCP
傳輸方式:同步傳輸
序列化:Java標準二進制序列化 適用范圍:傳入傳出參數數據包大小混合,消費者與提供者個數差不多,可傳
文件。 適用場景:常規遠程服務方法調用,與原生 RMI服務互操作
Hessian 協議
Hessian協議用于集成 Hessian的服務,Hessian底層采用 Http通訊,采用
Servlet暴露服務,Dubbo缺省內嵌 Jetty作為服務器實現
基于 Hessian的遠程調用協議。 連接個數:多連接
連接方式:短連接
傳輸協議:HTTP 傳輸方式:同步傳輸 序列化:Hessian二進制序列化
適用范圍:傳入傳出參數數據包較大,提供者比消費者個數多,提供者壓力較
大,可傳文件。
適用場景:頁面傳輸,文件傳輸,或與原生 hessian服務互操作
http
采用 Spring的 HttpInvoker實現
基于 http表單的遠程調用協議。
連接個數:多連接
連接方式:短連接
傳輸協議:HTTP
傳輸方式:同步傳輸
序列化:表單序列化(JSON)
適用范圍:傳入傳出參數數據包大小混合,提供者比消費者個數多,可用瀏覽
器查看,可用表單或 URL傳入參數,暫不支持傳文件。
適用場景:需同時給應用程序和瀏覽器 JS使用的服務。
Webservice
基于 CXF的 frontend-simple和 transports-http實現
基于 WebService的遠程調用協議。 連接個數:多連接 連接方式:短連接 傳輸協議:HTTP 傳輸方式:同步傳輸 序列化:SOAP文本序列化 適用場景:系統集成,跨語言調用。
Thrif
Thrift是 Facebook捐給 Apache的一個 RPC框架,當前 dubbo 支持的 thrift
協議是對 thrift 原生協議的擴展,在原生協議的基礎上添加了一些額外的頭信 息,比如 service name,magic number等

-mySQL數據庫鏈接錯誤)


-讀寫mat文件)


靜態工廠方法模式)

-for-enumerate()-zip())




--Hadoop2.0介紹)

-圖像分類常用數據集)

函數分析)
