文章目錄
- 1.摘要和背景
- 1.1 摘要
- 1.2 背景
- 2.方法和貢獻
- 2.1 方法
- 2.2 貢獻
- 3.實驗和結果
- 3.1 實驗
- 3.2 結果
- 4.總結和展望
- 4.1 總結
- 4.2 展望
本系列是在閱讀深度神經網絡模型小型化方面論文時的筆記!內容大部分從論文中摘取,也會有部分自己理解,有錯誤的地方還望大家批評指出!
論文鏈接:BlockSwap: Fisher-guided Block Substitution for Network Compression
代碼鏈接:github代碼
1.摘要和背景
1.1 摘要
原文摘要:
The desire to run neural networks on low-capacity edge devices has led to the development of a wealth of compression techniques. Moonshine (Crowley et al., 2018a) is a simple and powerful example of this: one takes a large pre-trained network and substitutes each of its convolutional blocks with a selected cheap alternative block, then distills the resultant network with the original. However, not all blocks are created equally; for a required parameter budget there may exist a potent combination of many different cheap blocks. In this work, we find these by developing BlockSwap: an algorithm for choosing networks with interleaved block types by passing a single minibatch of training data through randomly initialised networks and gauging their Fisher potential. We show that block-wise cheapening yields more accurate networks than single block-type networks across a spectrum of parameter budgets.
在資源受限的設備(手機等終端設備)上使用深度神經網絡使得模型壓縮成為研究的熱門。2018年Crowley等人提出的Moonshine方法將原始網絡中的basicBlock用計算量更加少的block進行替代,從而達到了對模型裁剪的目的。但是,該方法對原始網絡中的每一個block都使用相同的block進行替換,即:在篩選出最佳的block后,將原始模型的中所有block都是搜索得到的最佳的block進行替換。本文在moonshine方法基礎上,對不同的basicBlock用不同的最佳的block進行替換,從而得到裁剪后的模型,然后使用網絡蒸餾的方法對裁剪后的模型進行retrain,從而提高裁剪后模型的精度。本文提出的方法首先隨機生成一批滿足資源限定要求的網絡,然后使用一個minibatch的數據對所有產生的網絡進行前向傳播,并計算出每個網絡的Fisher potential,然后推選出Fisher potential最大的那個網絡作為裁剪后的模型,然后對該模型進行微調(使用網絡蒸餾方法),提高裁剪后模型的精度。
1.2 背景
-
2018年Crowley等人提出的方法:Moonshine主要分為以下兩步:
- 將原始網絡中的每個block替換成計算資源更加少的block
- 將替換后的網絡作為學生網絡,原始網絡作為老師網絡,使用網絡蒸餾的方法,訓練學生網絡,得到的學生網絡便是壓縮后的網絡。
-
2018年Crowley等人提出的方法:Moonshine,存在的問題是對所有的block使用相同的替換block,這個假設太強了。我們知道,即使在resnet中,不同的block之間的通道數還不一樣,所以文章中使用同一個block對原始模型的所有的block進行替換是不合適的。
-
使用分組卷積,深度可分離卷積,瓶頸卷積等特殊的卷積替換普通卷積,可以大大的降低模型的計算量。如:mobilenet就是使用深度可分離卷積替換原始的普通卷積,使得在和vgg相同的精度表現下可以擁有更少的參數。
2.方法和貢獻
2.1 方法
- 本文方法的過程:
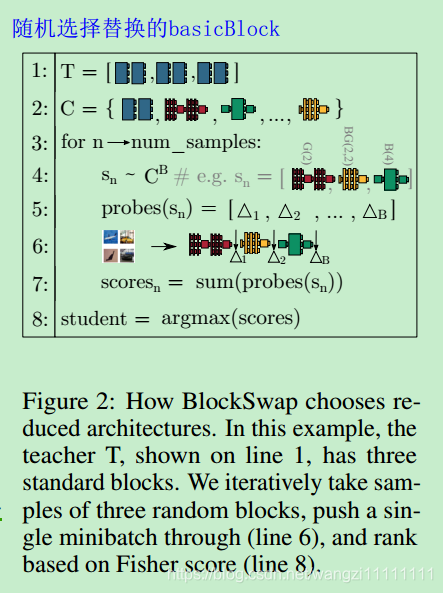
- 從候選的可替換卷積模塊中隨機選取block替換原始網絡中的block,并使得構造出來的網絡滿足資源限制的條件。
- 從數據集中隨機選取一個minibatch的數據集,然后使用生成的所有滿足要求的網絡計算得到 Fisher potential,并選出 Fisher potential最大的那個網絡
- 將選出的網絡作為學生網絡,初始網絡作為老師網絡,使用網絡蒸餾的方法對學生網絡進行訓練,得到的學生網絡就是我們壓縮后的網絡。
- 使用網絡蒸餾的方法可以將一個大而復雜的網絡的知識遷移到一個小而簡單的網絡中,是比fine_turn更好的方法。但是使用網絡蒸餾方法的前提是得知道小網絡(裁剪后的網絡)的結構。
- 分組卷積,深度可分離卷積和瓶頸卷積或者它們的組合,替換普通的卷積可以大大的降低模型的計算量。

- 網絡自動架構搜索(automating neural architecture search (NAS))技術常常包括如下方法:1)基于空間查找方法的(使用隨機和非隨機方法),即對候選的網絡的參數空間進行搜索,從而得出滿足要求的結構。2)基于優化算法(遺傳算法),對網絡的參數進行搜索;3)基于強化學習的架構搜索,即使用強化學習方法對參數進行搜索 ;4)one-shot方法:訓練一個大而全的混合模型,然后根據要求選出合適的子模型等等。按時NAS方法被證明常常會找到一個次優解。
2.2 貢獻
- 提出了blockswap方法,通過該方法得出比刪減網絡的深度或者寬度或者moonshine方法結果要好。
- 我們概述了一種通過Fisher信息快速比較候選模型的簡單方法。 我們通過消融研究證實了我們的度量與最終訓練誤差高度相關,并表明它可以用來選擇性能架構
- 實驗證明,本文的方法比moonshine和隨機組合的方法都要好。
3.實驗和結果
3.1 實驗
- 數據集:cofar10和ImageNet
- 模型:WRN-40-2 , ResNet-34
- 通過對比人為簡單的刪減網絡的深度和寬度,moonshin取不同block的時候和blockswap方法的對比,驗證本文方法的有效性。
- blockswap方法在候選的block集合中搜索滿足資源限制的搜索步驟為1000步,是隨機的。然后使用一個minibatch的訓練集根據生成的網絡算出他們的firsh分數,然后選擇分數最高的那個網絡作為裁剪后的網絡。
- Networks are trained for 200 epochs using SGD with momentum 0.9. The initial learning rate of 0.1 is reduced by a factor of 5 every 60 epochs. Minibatches of size 128 are used with standard crop + flip data augmentation. The weight decay factor is set to 0.0005. For attention transfer β is set to 1000 using the output of each of the three sections of the network.
3.2 結果


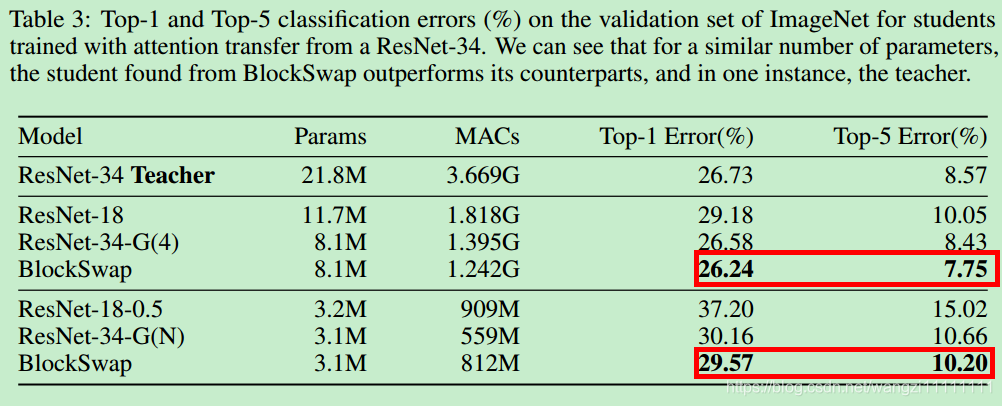
- BlockSwap chooses a student that is better than the teacher, despite using 3.5× fewer parameters and 3× fewer MACs.
- Fisher potential metric is an effective means for choosing optimal block structures
- Specifically, it beats the teacher by 0.49% in top-1 error and 0.82% in top-5 error despite using almost 3× fewer parameters
4.總結和展望
4.1 總結
- 提出了一種算法,可以對復雜的模型進行壓縮以適用于計算資源受限的設備。
- 通過給定一個block候選集合,然后隨機的對原始網絡中的block使用候選的block進行替換,并且滿足資源受限的條件。然后,使用一個minibatch的訓練集對生成的網絡計算firsher分數,并將分數最高的那個網絡作為裁剪后的網絡,然后利用網絡蒸餾的方法對得到的裁剪后的網絡進行訓練。
4.2 展望
- 文章中給出的候選的block集合中的block數目有限,是否可以發現更好的可替換的block?
- 文章中對于網絡的替換是基于隨機生成的,是否可以使用基于優化算法或者網絡生成呢?
-知識圖譜、信息抽取)


- Meta Filter Pruning to Accelerate Deep Convolutional Neural Networks)

-自己設計神經網絡會遇到的問題)

- Be Your Own Teacher: Improve the Performance of Convolutional Neural Networks via Self)

-模塊)



-核函數與再生核希爾伯特空間)




-特征函數)
