文章目錄
- 1.摘要和介紹
- 1.1摘要部分
- 2.背景和方法
- 2.1 背景
- 2.2 貢獻
- 2.3 方法
- 3.實驗和結果
- 3.1 實驗
- 3.2 結果
- 4.總結和展望
- 4.1 總結
- 4.2 展望
本系列是在閱讀深度神經網絡模型小型化方面論文時的筆記!內容大部分從論文中摘取,也會有部分自己理解,有錯誤的地方還望大家批評指出!
論文鏈接:Meta Filter Pruning to Accelerate Deep Convolutional Neural Networks
1.摘要和介紹
1.1摘要部分
原文摘要:
Existing methods usually utilize pre-defined criterions, such as ‘ p-norm, to prune unimportant filters. There are
two major limitations in these methods. First, the relations of the filters are largely ignored. The filters usually work
jointly to make an accurate prediction in a collaborative way. Similar filters will have equivalent effects on the network prediction, and the redundant filters can be further pruned. Second, the pruning criterion remains unchanged during training. As the network updated at each iteration, the filter distribution also changes continuously. The pruning criterions should also be adaptively switched.
傳統的通道裁剪方法都是需要預先定義通道的裁剪準則,然后使用該一成不變的準則對網絡進行裁剪,而其中使用的是裁剪準則是不考慮通道之間的相關性,如:lp_norm。該方法存在下面兩個問題:1)沒有考慮網絡中不同通道之間的相關性。一般而言,相關性大的兩個通道就可以裁剪掉其中的一個。2)沒有考慮網絡更新過程中狀態的改變。應該使用自適應的通道裁剪準則。
In this paper, we propose Meta Filter Pruning (MFP) to solve the above problems. First, as a complement to the existing ‘p-norm criterion, we introduce a new pruning criterion considering the filter relation via filter distance.
Additionally, we build a meta pruning framework for filter pruning, so that our method could adaptively select the most appropriate pruning criterion as the filter distribution changes. Experiments validate our approach on two image classification benchmarks. Notably, on ILSVRC-2012, our MFP reduces more than 50% FLOPs on ResNet-50 withonly 0.44% top-5 accuracy loss.
文章提出了一種基于元學習的通道刪除方法。主要是改進了上面提出的另個問題。其中為了解決第一個問題,提出了兩種用于度量兩個不同通道之間的相關性的方法,并將其作為新的通道裁剪準則,與常用lp_norm準則一起構成裁剪準則候選集合;為了解決第二個問題,提出了一種基于元學習的自動選擇合適的通道裁剪準則框架,其在每一個epoch中會根據當前網絡的狀態,自動從通道裁剪集合中選擇合適的裁剪準則。最終,本文實現了在ILSVRC-2012數據集上,對模型resnet50裁剪50%的flops,得到0.44%的top_5的精度。
2.背景和方法
2.1 背景
- 為了在計算資源有限的平臺上(手機等終端設備)上使用深度神經網絡模型,對模型的裁剪是必須的。其中對模型的裁剪分為:權重的裁剪(weight pruning)和卷積通道( filter pruning)的裁剪。其中前者是對神經元進行裁剪,而后者是將整個通道都刪除了。前者因為得到的是非結構化稀疏(unstructured sparsity)無發很好的利用基本線性代數子程序庫(BLAS)進行加速,所以意義不是很大,所以大家基本上都是研究通道級別的裁剪,因為其得到的是結構化的稀疏( structured sparsity)。
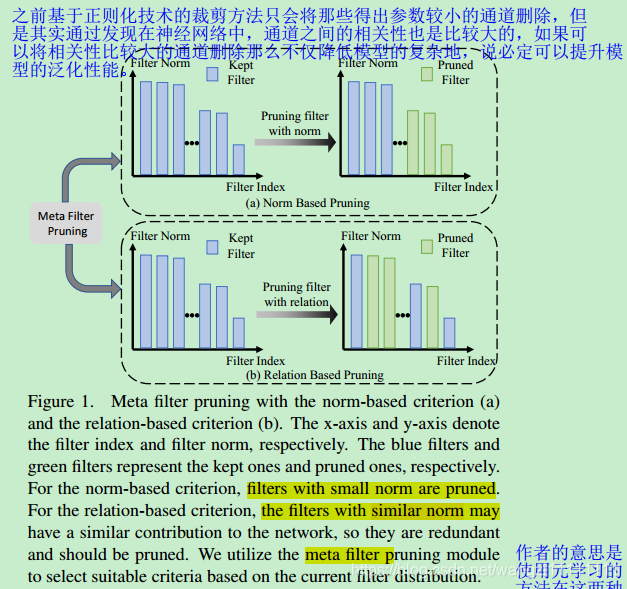
- 在過去的工作中,裁剪的準則主要分為兩種:1)系數值越小則越不重要(smaller-norm-less-important),即:如果某個通道的卷積系數或者BN層的稀疏比較小,那么該通道對于結果貢獻就不大,可以刪除。所以,該類方法大多采用正則化的方法使得模型的系數稀疏化,從而達到裁剪通道的目的。但是該方法沒有考慮到通道之間的相關性。2)基于通道之間的相關性(Relational Criterion),相關性越大的兩個通道,則必定有一個是冗余的。采用的方法是使用幾何均值篩選中模型中最不重要的通道,因為越是接近集合均值的通道這說明和剩下的通道相關性越大,則可以被刪除。
- 傳統的通道裁剪存在以下兩個問題:1)通道之間的相關性度量方法嘗試太少;2)由于通道的裁剪,模型中卷積核的參數分布是動態變換的,所以固定不變的通道裁剪準則是不是不太合適。
2.2 貢獻
- 提出了兩種新的通道相關性度量的方法
- 提出了基于元學習的通道裁剪準則自適應變換框架,從而盡可能的降低裁剪前后模型之前的loss差異
- 在常用的數據集:cifar10和ImageNet上對常用的模型(resnet , vggnet等)進行試驗,得到的實驗記過非常好。
2.3 方法

- 在每一個epoch過程中,分別會根據lp_norm準則和distace_norm準則,對網絡中所有的通道進行排序,然后通過元學習的方法篩選出適合當前狀態的通道裁剪準則,并按照該準則的分數對模型進行裁剪。
- 其中距離準則下使用了Minkowski Distance和Cosine Distance,并通過計算當前通道與剩下所有通道之間距離之和然后再求平均得到的值表示該通道的相關性分數,分數越大則表示通道越重要。
- lp_norm準則下,使用的是l1和l2正則化來產生稀疏性,然后計算當前通道參數的1范數或者2范數作為通道重要性的分數,分數越大,則通道越重要。
- 文章的優化目標是降低模型裁剪前后元屬性,其中元屬性可以為:sparsity level κ, the mean value of weights,
top-5 loss, top-1 loss等。
3.實驗和結果
3.1 實驗
- 數據集:CIFAR-10 , ILSVRC-2012
- 模型: ResNet , VGGNet
- 每個實驗重復三次,并對結果取均值和方差
- Minkowski distance with p = 1; 2 cosine distance
3.2 結果
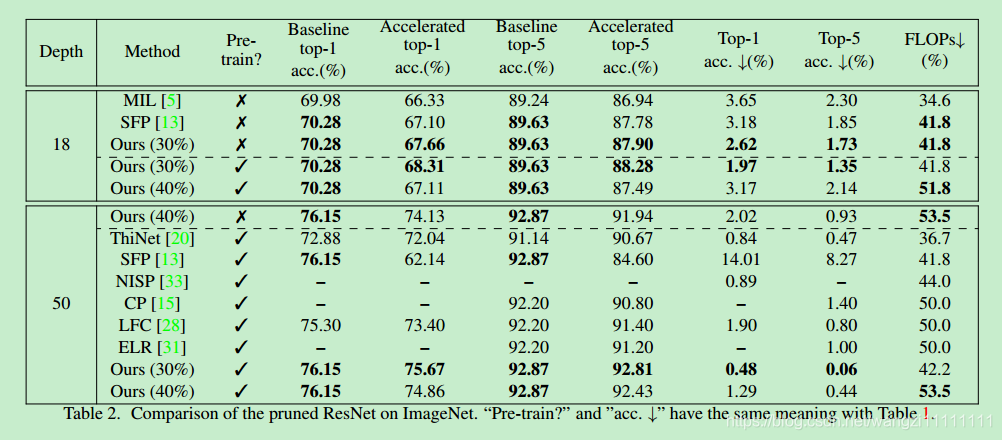


- 通過上面的實驗結果可以看出,無論是在resnet模型還是vggnet模型,在數據集cifar10和imgnet上的結果都比其他方法要好,即:更大的裁剪量可以得到更好的模型
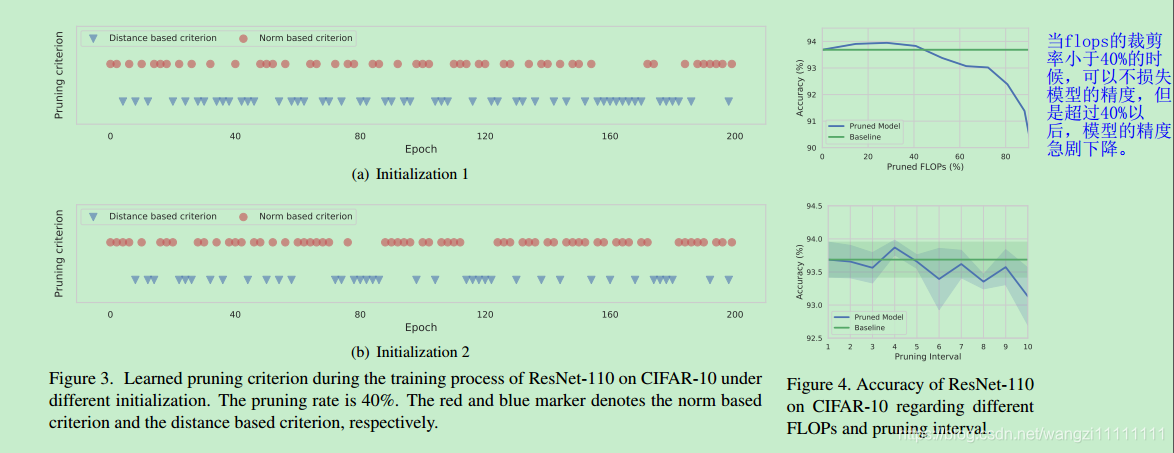
- 在裁剪量小于40%的時候,在resnet-100,數據集cifar10上,得到的裁剪后的模型精度比未裁剪的要好。
- This means the performance of our framework is not sensitive to the pruning interval
- we find that during the early training process, the distance-based criteria are adopted less than norm-based criteria
4.總結和展望
4.1 總結
- 本文的方法不僅使用基于系數大小的裁剪準則,還使用了基于相關性的裁剪準則,使得結果更好
- 本文提出了一種基于元學習的自適應選取裁剪準則的框架,可以在每個epoch下,更根據模型的狀態選擇合適的裁剪專責。
- MFP achieves comparable performance with state-of-theart methods in several benchmarks.
4.2 展望
- 目前裁剪準則的查找是在epoch級別上,未來可以考慮將其做在層上。
- 可以嘗試更多的元屬性。

-自己設計神經網絡會遇到的問題)

- Be Your Own Teacher: Improve the Performance of Convolutional Neural Networks via Self)

-模塊)



-核函數與再生核希爾伯特空間)




-特征函數)


)

-文件,os模塊)