目錄
- 1. 初見LeNet原始模型
- 2. Caffe LeNet的網絡結構
- 3. 逐層理解Caffe LeNet
- 3.1 Data Layer
- 3.2 Conv1 Layer
- 3.3 Pool1 Layer
- 3.4 Conv2 Layer
- 3.5 Pool2 Layer
- 3.6 Ip1 Layer
- 3.7 Relu1 Layer
- 3.8 Ip2 Layer
- 3.9 Loss Layer
1. 初見LeNet原始模型
?
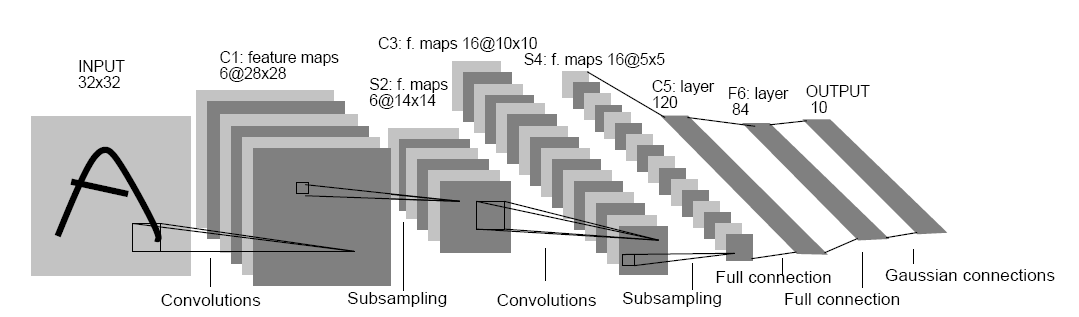
Fig.1. Architecture of original LeNet-5.
圖片來源: Lecun, et al., Gradient-based learning applied to document recognition,?P IEEE, vol. 86, no. 11, 1998, pp. 2278-2324.
在這篇圖片的論文中,詳細描述了LeNet-5的結構。
這里不對LeNet-5原始模型進行討論。可以參考這些資料:
http://blog.csdn.net/qiaofangjie/article/details/16826849
http://blog.csdn.net/xuanyuansen/article/details/41800721
2. Caffe LeNet的網絡結構
他山之石,可以攻玉。本來是準備畫出Caffe LeNet的圖的,但發現已經有人做了,并且畫的很好,就直接拿過來輔助理解了。
第3部分圖片來源:http://www.2cto.com/kf/201606/518254.html
先從整體上感知Caffe LeNet的拓撲圖,由于Caffe中定義網絡的結構采用的是bottom&top這種上下結構,所以這里的圖也采用這種方式展現出來,更加方便理解。
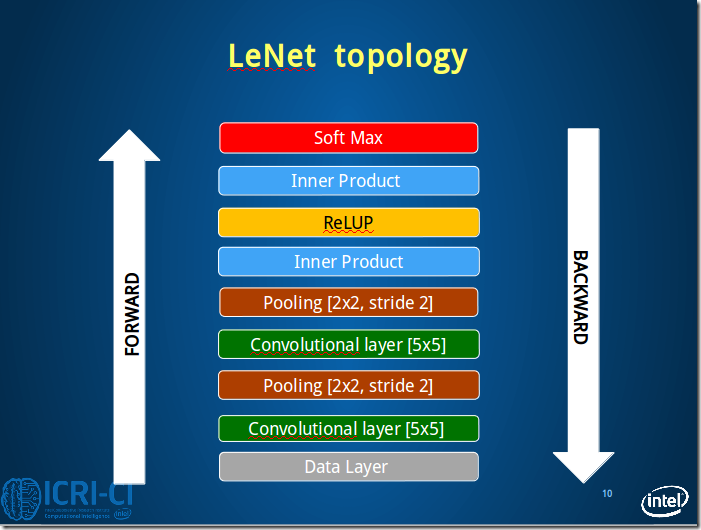
Fig.2. Architecture of caffe LeNet.
From bottom to top: Data Layer, conv1, pool1, conv2, pool2, ip1, relu1, ip2, [accuracy]loss.
本節接下來將按照這個順序依次理解Caffe LeNet的網絡結構。
3. 逐層理解Caffe LeNet
本節將采用定義與圖解想結合的方式逐層理解Caffe LeNet的結構。3.1 Data Layer
#==============定義TRAIN的數據層============================================
layer { name: "mnist" #定義該層的名字type: "Data" #該層的類型是數據top: "data" #該層生成一個data blobtop: "label" #該層生成一個label blobinclude {phase: TRAIN #說明該層只在TRAIN階段使用}transform_param {scale: 0.00390625 #數據歸一化系數,1/256,歸一到[0,1)}data_param {source: "E:/MyCode/DL/caffe-master/examples/mnist/mnist_train_lmdb" #訓練數據的路徑batch_size: 64 #批量處理的大小backend: LMDB}
}
#==============定義TEST的數據層============================================
layer { name: "mnist"type: "Data"top: "data"top: "label"include {phase: TEST #說明該層只在TEST階段使用}transform_param {scale: 0.00390625}data_param {source: "E:/MyCode/DL/caffe-master/examples/mnist/mnist_test_lmdb" #測試數據的路徑batch_size: 100backend: LMDB}
}
2Fig.3. Architecture of data layer.Fig.3 是train情況下,數據層讀取lmdb數據,每次讀取64條數據,即N=64。Caffe中采用4D表示,N*C*H*W(Num*Channels*Height*Width)。3.2 Conv1 Layer
#==============定義卷積層1=============================
layer {name: "conv1" #該層的名字conv1,即卷積層1type: "Convolution" #該層的類型是卷積層bottom: "data" #該層使用的數據是由數據層提供的data blobtop: "conv1" #該層生成的數據是conv1param {lr_mult: 1 #weight learning rate(簡寫為lr)權值的學習率,1表示該值是lenet_solver.prototxt中base_lr: 0.01的1倍}param {lr_mult: 2 #bias learning rate偏移值的學習率,2表示該值是lenet_solver.prototxt中base_lr: 0.01的2倍}convolution_param {num_output: 20 #產生20個輸出通道kernel_size: 5 #卷積核的大小為5*5stride: 1 #卷積核移動的步幅為1weight_filler {type: "xavier" #xavier算法,根據輸入和輸出的神經元的個數自動初始化權值比例}bias_filler {type: "constant" #將偏移值初始化為“穩定”狀態,即設為默認值0}}
}
3Fig.4. Architecture of conv1 layer.conv1的數據變化的情況:batch_size*1*28*28->batch_size*20*24*243.3 Pool1 Layer
#==============定義池化層1=============================
layer {name: "pool1"type: "Pooling"bottom: "conv1" #該層使用的數據是由conv1層提供的conv1top: "pool1" #該層生成的數據是pool1pooling_param {pool: MAX #采用最大值池化kernel_size: 2 #池化核大小為2*2stride: 2 #池化核移動的步幅為2,即非重疊移動}
}
4Fig.5. Architecture of pool1 layer.池化層1過程數據變化:batch_size*20*24*24->batch_size*20*12*123.4 Conv2 Layer
#==============定義卷積層2=============================
layer {name: "conv2"type: "Convolution"bottom: "pool1"top: "conv2"param {lr_mult: 1}param {lr_mult: 2}convolution_param {num_output: 50kernel_size: 5stride: 1weight_filler {type: "xavier"}bias_filler {type: "constant"}}
}
conv2層的圖與Fig.4 類似,卷積層2過程數據變化:batch_size*20*12*12->batch_size*50*8*8。3.5 Pool2 Layer
#==============定義池化層2=============================
layer {name: "pool2"type: "Pooling"bottom: "conv2"top: "pool2"pooling_param {pool: MAXkernel_size: 2stride: 2}
}
pool2層圖與Fig.5類似,池化層2過程數據變化:batch_size*50*8*8->batch_size*50*4*4。3.6 Ip1 Layer
#==============定義全連接層1=============================
layer {name: "ip1"type: "InnerProduct" #該層的類型為全連接層bottom: "pool2"top: "ip1"param {lr_mult: 1}param {lr_mult: 2}inner_product_param {num_output: 500 #有500個輸出通道weight_filler {type: "xavier"}bias_filler {type: "constant"}}
}
5Fig.6. Architecture of ip11 layer.ip1過程數據變化:batch_size*50*4*4->batch_size*500*1*1。此處的全連接是將C*H*W轉換成1D feature vector,即800->500.3.7 Relu1 Layer
#==============定義ReLU1層=============================
layer {name: "relu1"type: "ReLU"bottom: "ip1"top: "ip1"
}
6
Fig.7. Architecture of relu1 layer.
ReLU1層過程數據變化:batch_size*500*1*1->batch_size*500*1*13.8 Ip2 Layer
#==============定義全連接層2============================
layer {name: "ip2"type: "InnerProduct"bottom: "ip1"top: "ip2"param {lr_mult: 1}param {lr_mult: 2}inner_product_param {num_output: 10 #10個輸出數據,對應0-9十個數字weight_filler {type: "xavier"}bias_filler {type: "constant"}}
}
ip2過程數據變化:batch_size*500*1*1->batch_size*10*1*13.9 Loss Layer
#==============定義損失函數層============================
layer {name: "loss"type: "SoftmaxWithLoss"bottom: "ip2"bottom: "label"top: "loss"
}
7Fig.8. Architecture of loss layer.損失層過程數據變化:batch_size*10*1*1->batch_size*10*1*1note:注意到caffe LeNet中有一個accuracy layer的定義,這是輸出測試結果的層。回到頂部(go to top)
4. Caffe LeNet的完整定義
name: "LeNet" #定義網絡的名字
#==============定義TRAIN的數據層============================================
layer { name: "mnist" #定義該層的名字type: "Data" #該層的類型是數據top: "data" #該層生成一個data blobtop: "label" #該層生成一個label blobinclude {phase: TRAIN #說明該層只在TRAIN階段使用}transform_param {scale: 0.00390625 #數據歸一化系數,1/256,歸一到[0,1)}data_param {source: "E:/MyCode/DL/caffe-master/examples/mnist/mnist_train_lmdb" #訓練數據的路徑batch_size: 64 #批量處理的大小backend: LMDB}
}
#==============定義TEST的數據層============================================
layer { name: "mnist"type: "Data"top: "data"top: "label"include {phase: TEST #說明該層只在TEST階段使用}transform_param {scale: 0.00390625}data_param {source: "E:/MyCode/DL/caffe-master/examples/mnist/mnist_test_lmdb" #測試數據的路徑batch_size: 100backend: LMDB}
}
#==============定義卷積層1=============================
layer {name: "conv1" #該層的名字conv1,即卷積層1type: "Convolution" #該層的類型是卷積層bottom: "data" #該層使用的數據是由數據層提供的data blobtop: "conv1" #該層生成的數據是conv1param {lr_mult: 1 #weight learning rate(簡寫為lr)權值的學習率,1表示該值是lenet_solver.prototxt中base_lr: 0.01的1倍}param {lr_mult: 2 #bias learning rate偏移值的學習率,2表示該值是lenet_solver.prototxt中base_lr: 0.01的2倍}convolution_param {num_output: 20 #產生20個輸出通道kernel_size: 5 #卷積核的大小為5*5stride: 1 #卷積核移動的步幅為1weight_filler {type: "xavier" #xavier算法,根據輸入和輸出的神經元的個數自動初始化權值比例}bias_filler {type: "constant" #將偏移值初始化為“穩定”狀態,即設為默認值0}}
}#卷積過程數據變化:batch_size*1*28*28->batch_size*20*24*24
#==============定義池化層1=============================
layer {name: "pool1"type: "Pooling"bottom: "conv1" #該層使用的數據是由conv1層提供的conv1top: "pool1" #該層生成的數據是pool1pooling_param {pool: MAX #采用最大值池化kernel_size: 2 #池化核大小為2*2stride: 2 #池化核移動的步幅為2,即非重疊移動}
}#池化層1過程數據變化:batch_size*20*24*24->batch_size*20*12*12
#==============定義卷積層2=============================
layer {name: "conv2"type: "Convolution"bottom: "pool1"top: "conv2"param {lr_mult: 1}param {lr_mult: 2}convolution_param {num_output: 50kernel_size: 5stride: 1weight_filler {type: "xavier"}bias_filler {type: "constant"}}
}#卷積層2過程數據變化:batch_size*20*12*12->batch_size*50*8*8
#==============定義池化層2=============================
layer {name: "pool2"type: "Pooling"bottom: "conv2"top: "pool2"pooling_param {pool: MAXkernel_size: 2stride: 2}
}#池化層2過程數據變化:batch_size*50*8*8->batch_size*50*4*4
#==============定義全連接層1=============================
layer {name: "ip1"type: "InnerProduct" #該層的類型為全連接層bottom: "pool2"top: "ip1"param {lr_mult: 1}param {lr_mult: 2}inner_product_param {num_output: 500 #有500個輸出通道weight_filler {type: "xavier"}bias_filler {type: "constant"}}
}#全連接層1過程數據變化:batch_size*50*4*4->batch_size*500*1*1
#==============定義ReLU1層=============================
layer {name: "relu1"type: "ReLU"bottom: "ip1"top: "ip1"
}#ReLU1層過程數據變化:batch_size*500*1*1->batch_size*500*1*1
#==============定義全連接層2============================
layer {name: "ip2"type: "InnerProduct"bottom: "ip1"top: "ip2"param {lr_mult: 1}param {lr_mult: 2}inner_product_param {num_output: 10 #10個輸出數據,對應0-9十個數字weight_filler {type: "xavier"}bias_filler {type: "constant"}}
}#全連接層2過程數據變化:batch_size*500*1*1->batch_size*10*1*1
#==============定義顯示準確率結果層============================
layer {name: "accuracy"type: "Accuracy"bottom: "ip2"bottom: "label"top: "accuracy"include {phase: TEST}
}
#==============定義損失函數層============================
layer {name: "loss"type: "SoftmaxWithLoss"bottom: "ip2"bottom: "label"top: "loss"
}#損失層過程數據變化:batch_size*10*1*1->batch_size*10*1*1?
-分支)
)

-diff)
:柱面投影+模板匹配+漸入漸出融合)
:OpenCV同時打開兩個攝像頭捕獲視頻)
-merge)



-cherry-pick、reset、rebase)


-stash, reflog)


的創建及CV_8UC1,CV_8UC2等參數詳解)
-模型相關基礎概念)

