Tensorboard
- 1.tensorboard in tensorflow
- 1.1 tensorboard的啟動過程
- 1.2 tf.summary 可視化類型
- 1.3 tf.summary 使用demo
- 2.tensorboard in pytorch
- 2.1 SummaryWriter 使用demo1
- 2.2 tSummaryWriter 使用demo2
- 2.3 tensorboard 數據再讀取
tensorboard in tensorflow :tensorboard 是一套用于tensorflow訓練過程可視化工具,能夠可視化模型的結構,參數,損失函數等。最常用于記錄訓練過程中參數和損失函數值的變化,用來反饋模型性能指標的變化。
TensorBoard github readme–基礎概念、操作,tf.summary.xxx
Get started with TensorBoard–圖像、網絡圖、網絡參數的可視化
tensorboard in pytorch: 有多種方式來使用tensorboard。本文想推薦的是通過 TensorboardX [第三方庫] 來使用tensorboard。底層實際還是tensorflow的tensorboard. 在pytorch 代碼框架下想要使用tensorboard 的話,需安裝以下兩個包。 pip install tensorboardX、pip install tensorflow # cpu 版本即可。
PyTorch 自帶 TensorBoard 使用教程 – from torch.utils.tensorboard import SummaryWriter
PyTorch 使用 TensorboardX 進行網絡可視化–from tensorboardX import SummaryWriter
(pytorch 和 tensorflow 使用tensorboard 之間的差別后續在整理。本文先著重于整理tensor low中tensor board的使用。)
從標黃的三個地方可以看出,Summary這個對象蠻重要的。
1.tensorboard in tensorflow
1.1 tensorboard的啟動過程
# 1.創建writer,用于寫日志文件
writer=tf.summary.FileWriter('/path/to/logs', tf.get_default_graph())
# 2.保存日志文件
writer.close()
# 3.運行可視化命令,啟動服務
tensorboard –logdir /path/to/logs
# 4.打開可視化界面
通過瀏覽器打開服務器訪問端口http://xxx.xxx.xxx.xxx:6006
參考文檔–Tensorboard 詳解(上篇)
1.2 tf.summary 可視化類型
Tensorboard 需要將可視化的數據存盤,這些數據來自 summary操作[summary ops]。 summary操作和tensorflow的其他ops性質是一致的,它能夠產生序列化的protobufs數據,然后使用summary.FileWriter寫入磁盤。
tensorboard支持以下操作,也就是tensor board能夠可視化的對象類型。
tf.summary.FileWriter() # 指定一個文件用來保存圖,可以調用其add_summary()方法將訓練過程數據保存在filewriter指定的文件中,詳見使用demo
tf.summary.scalar # 用于追蹤模型的loss,
tf.summary.image
tf.summary.audio
tf.summary.text
tf.summary.histogram
tf.summary.merge_all # 可以將所有summary全部保存到磁盤tf.summary.scalar、tf.summary.histogram
建議給每類數據賦予一個tag, scalar 和 histogram 的標簽里如果有/, 這些數據在存儲的時候會存入對應的目錄文件中。
1.3 tf.summary 使用demo
自動管理: tf.summary.merge_all(),猜測是直接將訓練輸出到tensor board中
summary_writer = tf.summary.FileWriter(dir, flush_secs=60)
summary_writer.add_graph(sess.graph) #添加graph圖
tf.summary.scalar('loss', loss)
tf.summary.scalar('accuracy', accuracy)
sum_ops = tf.summary.merge_all() #自動管理,就是說要算loss 和 accuracy 唄
metall = sess.run(sum_ops, feed_dict={X: batch_x_test, Y: batch_y_test, keep_prob: 1.})
summary_writer.add_summary(metall, global_step=step) # 寫入文件
手動管理:
summary_writer = tf.summary.FileWriter(dir', flush_secs=60)
summary_writer.add_graph(sess.graph) #添加graph圖
loss_scalar = tf.summary.scalar('loss', loss)
accuracy_scalar = tf.summary.scalar('accuracy', accuracy)
loss_metall, accuracy_metall, = sess.run([loss_scalar, accuracy_scalar], feed_dict={X: batch_x_test, Y: batch_y_test, keep_prob: 1.})
summary_writer.add_summary(loss_metall, global_step=step) # 寫入文件
summary_writer.add_summary(accuracy_metall, global_step=step) # 寫入文件
參考文檔:
Tensorflow學習筆記——Summary用法
tf.summary.merge_all()
構建更復雜的圖的代碼demo
2.tensorboard in pytorch
2.1 SummaryWriter 使用demo1
from tensorboardX import SummaryWriter
writer1 = SummaryWriter('runs/exp') # 日志保存在‘runs/exp’路徑下
writer2 = SummaryWriter() # 默認將使用‘runs/日期時間’路徑來保存日志
writer3 = SummaryWriter(comment='resnet') # 使用 runs/日期時間-comment 路徑來保存日志# 調用 SummaryWriter 實例的各種 add_something 方法向日志中寫入不同類型的數據# 標量
writer1.add_scalar(tag, scalar_value, global_step=None, walltime=None)
# tag 子圖標識。相同tag的saclar被放在了同一張圖表中,方便對比觀察
# scalar_value 要求float類型。如果是tensor,則需要調用.item() 方法獲取其數值。# 圖像
writer1.add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')
# img_tensor (torch.Tensor / numpy.array): 圖像數據
# dataformats (string, optional): 圖像數據的格式# 直方圖
writer1.add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)
# values (torch.Tensor, numpy.array, or string/blobname): 用來構建直方圖的數據# 網絡結構
writer1.add_graph(model, input_to_model=None, verbose=False, **kwargs)
# model (torch.nn.Module): 待可視化的網絡模型
# input_to_model (torch.Tensor or list of torch.Tensor, optional): 待輸入神經網絡的變量或一組變量# 嵌入向量 (embedding),作用:高維特征使用PCA、t-SNE等方法降維至二維平面或三維空間顯示,還可觀察每一個數據點在降維前的特征空間的K近鄰情況。
writer1.add_embedding(mat, metadata=None, label_img=None, global_step=None, tag='default', metadata_header=None)
# 可以運行一下參考論文中的demo 加深印象參考論文:
詳解PyTorch項目使用TensorboardX進行訓練可視化
2.2 tSummaryWriter 使用demo2
1.記錄數據
from tensorboardX import SummaryWriter
# 設置路徑
# 數據將存在代碼運行文件目錄下的./run/xxxyyy/下的文件中,其中run文件目錄,xxx附加名稱是自動生成的
path = “yyy”
selfwriter = SummaryWriter(comment=os.path.split(path)
# 添加要觀察數據add_scalar方法保證實時觀察
# global_step 數據步長
selfwriter.add_scalar("Grad/gradD", d_grad_mean, global_step=dis_iter# ations)
....
selfwriter.add_scalar("Loss/lossD", loss_D, global_step=dis_iterations)
....
2.顯示數據:切換至./run/xxxpath/下,運行以下命令,在輸出信息中打開對應的網頁鏈接
tensorboard --logdir .
2.3 tensorboard 數據再讀取
使用tensorboard 記錄實驗數據,可以啟動服務后,在網頁上實時看到被記錄指標的變換情況。有時需操作記錄下來的數據,那么就涉及到tensorboar 數據再讀取問題。
參考博文:https://blog.csdn.net/nima1994/article/details/82844988#commentBox
讀取的接口的github 庫:https://github.com/tensorflow/tensorboard/blob/master/tensorboard/backend/event_processing/event_accumulator.py
from tensorboard.backend.event_processing import event_accumulator
import matplotlib.pyplot as plt
# 加載日志數據
path = "./runs/xxxyyy/events.out.tfevents.1609854743.pp-System-Product-Name"
ea = event_accumulator.EventAccumulator(path)
# 數據再載入
ea.Reload()
# 輸出所有圖對應的keys,之后會依據這個keys取出對應的數據
print(ea.scalars.Keys())grad_d = ea.scalars.Items('Grad/gradD')
grad_g = ea.scalars.Items('Grad/gradG')
nd, ng = len(grad_d), len(grad_g)
# 數據長度,event_accumulator默認的數據載入壓縮比為500:1,最多載入10000個點
# 所以數據很多的話。最多也就是載入10000個點,我是有后續的點被舍棄掉了么?兩個都是10000,但是數據量明明不一樣?
print(nd,ng)
# 數據后加工,這里就是展示了繪制
# 數據是[(.step, .value),(),()] 的形式存的
figure = plt.figure()
axes1 = figure.add_subplot(2,1,1)
axes2 = figure.add_subplot(2,1,2)
axes1.plot([i.step for i in grad_d], [i.value for i in grad_d])
axes2.plot([i.step for i in grad_g], [i.value for i in grad_g])
axes1.set_title("grad d")
axes2.set_title("grad g")
plt.savefig("grad_any.png")
下圖中上下兩子圖都包含1萬個點,那只能說明采樣率不同?(60萬個點采1萬個Vs 12萬個點采1萬個)
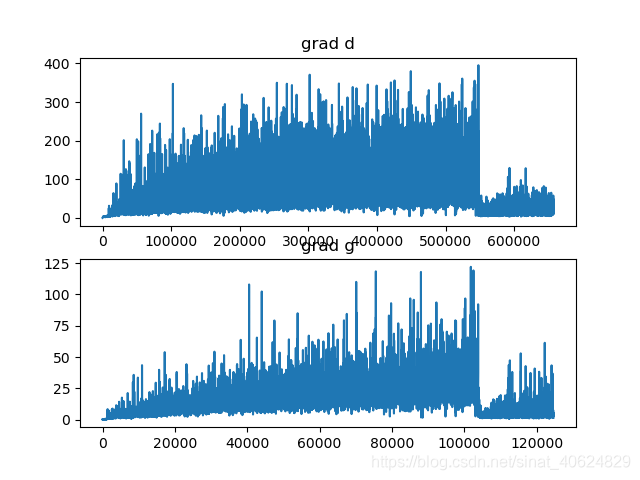
如何實現的自動采樣率?修改總的采樣點數,還需要查看官網接口。(具體效果沒有驗證過)
初步查看應該修改event_accumulator.EventAccumulator(path)類實例話時的參數size_guidance,不傳入時默認為:
DEFAULT_SIZE_GUIDANCE = {COMPRESSED_HISTOGRAMS: 500,IMAGES: 4,AUDIO: 4,SCALARS: 10000,HISTOGRAMS: 1,TENSORS: 10,
}
tf.summary.merge_all 可以將所有summary全部保存到磁盤,以便tensorboard顯示。
這個tensorbord 可以顯示模型結構?
再看一看這個玩意
summary.merge_all() 的用法

-訓練數據載入)



-與訓練相關的操作)

)


-TFRecord)
如何調用PlayFab接口)
如何通過Demo應用來進一步熟悉Playfab)

-TGAN-DeliGAN)
)

)
- RNN-LSTM-tf.nn.rnn_cell)
