目錄
?專欄導讀?
1網絡爬蟲概述
1.1?工作原理
1.2 應用場景
1.3 爬蟲策略
1.4 爬蟲的挑戰
2 網絡爬蟲開發
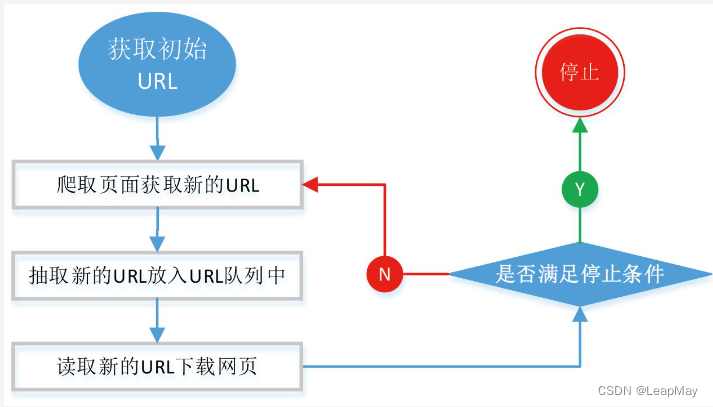
2.1 通用的網絡爬蟲基本流程
2.2 網絡爬蟲的常用技術
2.3 網絡爬蟲常用的第三方庫
3 簡單爬蟲示例
?專欄導讀?

專欄訂閱地址:https://blog.csdn.net/qq_35831906/category_12375510.html

1網絡爬蟲概述
????????網絡爬蟲(Web Crawler),也稱為網絡蜘蛛、網絡機器人,是一種自動化程序,用于在互聯網上瀏覽和抓取信息。爬蟲可以遍歷網頁,收集數據,提取信息,以便于進一步處理和分析。網絡爬蟲在搜索引擎、數據采集、信息監測等領域發揮著重要作用。
1.1?工作原理
初始URL選擇: 爬蟲從一個或多個初始URL開始,這些URL通常是你希望開始爬取的網站的主頁或其他頁面。
發送HTTP請求: 對于每個初始URL,爬蟲會發送HTTP請求以獲取網頁內容。請求可以包括GET、POST等不同的HTTP方法,也可以設置請求頭、參數和Cookies等。
接收HTTP響應: 服務器將返回一個HTTP響應,其中包含網頁的HTML代碼和其他資源,如圖片、CSS、JavaScript等。
解析網頁內容: 爬蟲使用HTML解析庫(如Beautiful Soup或lxml)解析接收到的HTML代碼,將其轉換為文檔對象模型(DOM)結構。
數據提取和處理: 通過DOM結構,爬蟲從網頁中提取所需的信息,如標題、正文、鏈接、圖片等。這可以通過CSS選擇器、XPath等方法實現。
存儲數據: 爬蟲將提取的數據存儲到本地文件、數據庫或其他存儲系統中,以供后續分析和使用。
發現新鏈接: 在解析網頁時,爬蟲會找到新的鏈接,并將其加入待爬取的URL隊列中,以便繼續爬取更多頁面。
重復流程: 爬蟲循環執行上述步驟,從初始URL隊列中取出URL,發送請求,接收響應,解析網頁,提取信息,處理和存儲數據,發現新鏈接,直到完成爬取任務。
控制和維護: 爬蟲需要設置適當的請求頻率和延時,以避免對服務器造成過大負擔。還需要監控爬蟲的運行情況,處理錯誤和異常。
1.2 應用場景
搜索引擎:搜索引擎使用爬蟲來抓取網頁內容,建立索引,以便用戶搜索時能夠快速找到相關信息。
數據采集:企業、研究機構等可以使用爬蟲從互聯網上采集數據,用于市場分析、輿情監測等。
新聞聚合:爬蟲可以從各個新聞網站抓取新聞標題、摘要等,用于新聞聚合平臺。
價格比較:電商網站可以使用爬蟲抓取競爭對手的產品價格和信息,用于價格比較分析。
科研分析:研究人員可以使用爬蟲來獲取科學文獻、學術論文等信息。
1.3 爬蟲策略
????????通用爬蟲(General Crawler)和聚焦爬蟲(Focused Crawler)是兩種不同的網絡爬蟲策略,用于在互聯網上獲取信息。它們的工作方式和應用場景有所不同。
通用爬蟲(General Crawler): 通用爬蟲是一種廣泛用途的爬蟲,它的目標是盡可能地遍歷互聯網上的大量網頁,以收集和索引盡可能多的信息。通用爬蟲會從一個起始URL開始,然后通過鏈接跟蹤、遞歸爬取等方式探索更多的網頁,構建一個廣泛的網頁索引。
通用爬蟲的特點:
- 目標是收集盡可能多的信息。
- 開始于一個或多個起始URL,然后通過鏈接跟蹤擴展。
- 適用于搜索引擎和大型數據索引項目。
- 需要考慮網站的robots.txt文件和反爬蟲機制。
聚焦爬蟲(Focused Crawler): 聚焦爬蟲是一種專注于特定領域或主題的爬蟲,它選擇性地爬取與特定主題相關的網頁。與通用爬蟲不同,聚焦爬蟲只關注某些特定的網頁,以滿足特定需求,如輿情分析、新聞聚合等。
聚焦爬蟲的特點:
- 專注于特定主題或領域。
- 根據特定的關鍵詞、內容規則等選擇性地爬取網頁。
- 適用于定制化需求,如輿情監控、新聞聚合等。
- 可以更精準地獲取特定領域的信息。
在實際應用中,通用爬蟲和聚焦爬蟲有各自的優勢和用途。通用爬蟲適合用于構建全面的搜索引擎索引,以及進行大規模數據分析和挖掘。聚焦爬蟲則更適合于定制化需求,能夠針對特定領域或主題獲取精準的信息。
1.4 爬蟲的挑戰
網站結構變化:網站結構和內容可能隨時變化,需要對爬蟲進行調整和更新。
反爬蟲機制:一些網站采取了反爬蟲措施,如限制請求頻率、使用驗證碼等。
數據清洗:從網頁中提取的數據可能包含噪音,需要進行清洗和整理。
法律和道德問題:爬蟲需要遵守法律法規,尊重網站規則,不要濫用和侵犯他人權益。
????????總結: 網絡爬蟲是一種自動化程序,用于從互聯網上獲取信息。它通過發送請求、解析網頁、提取信息等步驟,實現數據的采集和整理。在不同的應用場景中,爬蟲發揮著重要的作用,但也需要面對各種挑戰和合規性問題。
2 網絡爬蟲開發
2.1 通用的網絡爬蟲基本流程
2.2 網絡爬蟲的常用技術
?????網絡爬蟲是一種自動化的程序,用于從互聯網上收集數據。常用的網絡爬蟲技術和第三方庫包括以下內容:
1. 請求和響應處理:
- Requests: 用于發送HTTP請求和處理響應的庫,方便爬蟲獲取網頁內容。
- httpx: 類似于
requests,支持同步和異步請求,適用于高性能爬蟲。2. 解析和提取數據:
- Beautiful Soup: 用于解析HTML和XML文檔,并提供簡單的方法來提取所需數據。
- lxml: 高性能的HTML和XML解析庫,支持XPath和CSS選擇器。
- PyQuery: 基于jQuery的解析庫,支持CSS選擇器。
3. 動態渲染網頁:
- Selenium: 自動化瀏覽器庫,用于處理動態渲染的網頁,如JavaScript加載內容。
4. 異步處理:
- asyncio和aiohttp: 用于異步處理請求,提高爬蟲的效率。
5. 數據存儲:
- SQLite、MySQL、MongoDB: 數據庫用于存儲和管理爬取的數據。
- CSV、JSON: 簡單格式用于導出和導入數據。
6. 反爬蟲和IP代理:
- User-Agent設置: 設置請求的User-Agent頭部來模擬不同瀏覽器和操作系統。
- 代理服務器: 使用代理IP來隱藏真實IP地址,避免IP封禁。
- 驗證碼處理: 使用驗證碼識別技術來處理需要驗證碼的網站。
7. Robots.txt和網站政策遵守:
- robots.txt: 檢查網站的
robots.txt文件,遵循網站的規則。- 爬蟲延遲: 設置爬蟲請求的延遲,避免對服務器造成過大負擔。
8. 爬蟲框架:
- Scrapy: 一個強大的爬蟲框架,提供了許多功能來組織爬取過程。
- Splash: 一個JavaScript渲染服務,適用于處理動態網頁。
2.3 網絡爬蟲常用的第三方庫
????????網絡爬蟲使用多種技術和第三方庫來實現對網頁的數據獲取、解析和處理。以下是網絡爬蟲常用的技術和第三方庫:
1. 請求庫: 網絡爬蟲的核心是發送HTTP請求和處理響應。以下是一些常用的請求庫:
- Requests: 簡單易用的HTTP庫,用于發送HTTP請求和處理響應。
- httpx: 現代化的HTTP客戶端,支持異步和同步請求。
2. 解析庫: 解析庫用于從HTML或XML文檔中提取所需的數據。
- Beautiful Soup: 用于從HTML和XML文檔中提取數據的庫,支持靈活的查詢和解析。
- lxml: 高性能的XML和HTML解析庫,同時支持XPath和CSS選擇器。
3. 數據存儲庫: 存儲爬取到的數據是爬蟲的重要環節之一。
- SQLAlchemy: 強大的SQL工具包,用于在Python中操作關系數據庫。
- Pandas: 數據分析庫,可用于數據清洗和分析。
- MongoDB: 非關系型數據庫,適合存儲和處理大量的非結構化數據。
- SQLite: 輕量級的嵌入式關系數據庫。
4. 異步庫: 使用異步請求可以提高爬蟲的效率。
- asyncio: Python的異步IO庫,用于編寫異步代碼。
- aiohttp: 異步HTTP客戶端,支持異步請求。
5. 動態渲染處理: 有些網頁使用JavaScript進行動態渲染,需要使用瀏覽器引擎進行處理。
- Selenium: 自動化瀏覽器操作庫,用于處理JavaScript渲染的頁面。
6. 反爬蟲技術應對: 一些網站采取反爬蟲措施,需要一些技術來繞過。
- 代理池: 使用代理IP來避免頻繁訪問同一IP被封禁。
- User-Agent隨機化: 更改User-Agent以模擬不同的瀏覽器和操作系統。
這只是網絡爬蟲常用的一些技術和第三方庫。根據實際項目需求,您可以選擇合適的技術和工具來實現高效、穩定和有用的網絡爬蟲。
3 簡單爬蟲示例
?創建一個簡單的爬蟲,例如爬取一個靜態網頁上的文本信息,并將其輸出。
import requests
from bs4 import BeautifulSoup# 發送GET請求獲取網頁內容
url = 'https://www.baidu.com'
response = requests.get(url)
response.encoding = 'utf-8' # 指定編碼為UTF-8
html_content = response.text# 使用Beautiful Soup解析HTML內容
soup = BeautifulSoup(html_content, 'html.parser')# 提取網頁標題
title = soup.title.text# 提取段落內容
paragraphs = soup.find_all('p')
paragraph_texts = [p.text for p in paragraphs]# 輸出結果
print("Title:", title)
print("Paragraphs:")
for idx, paragraph in enumerate(paragraph_texts, start=1):print(f"{idx}. {paragraph}")




)

--樹與二叉查找樹)



)








