整理并翻譯自DeepLearning.AI×LangChain的官方課程:Question Answer(源代碼可見)
本節介紹使用LangChian構建文檔上的問答系統,可以實現給定一個PDF文檔,詢問關于文檔上出現過的某個信息點,LLM可以給出關于該信息點的詳情信息。這種使用方式比較靈活,因為并沒有使用PDF上的文本對模型進行訓練就可以實現文檔上的信息點問答。本節介紹的Chain也比較常用,它涉及到了嵌入(embedding)和向量存儲(vector store)。
(筆者注:embedding指的是將一個實體映射到高維空間,以高維向量的形式存儲,以最大限度地capture其信息,自然語言處理使用embedding方式表示單詞,即詞向量。自然語言處理語境下,embedding都指的是word embedding詞嵌入)
首先是一個簡單的例子:

下面解釋了一下底層原理:
LLM‘s on Documents 文檔上的大語言模型

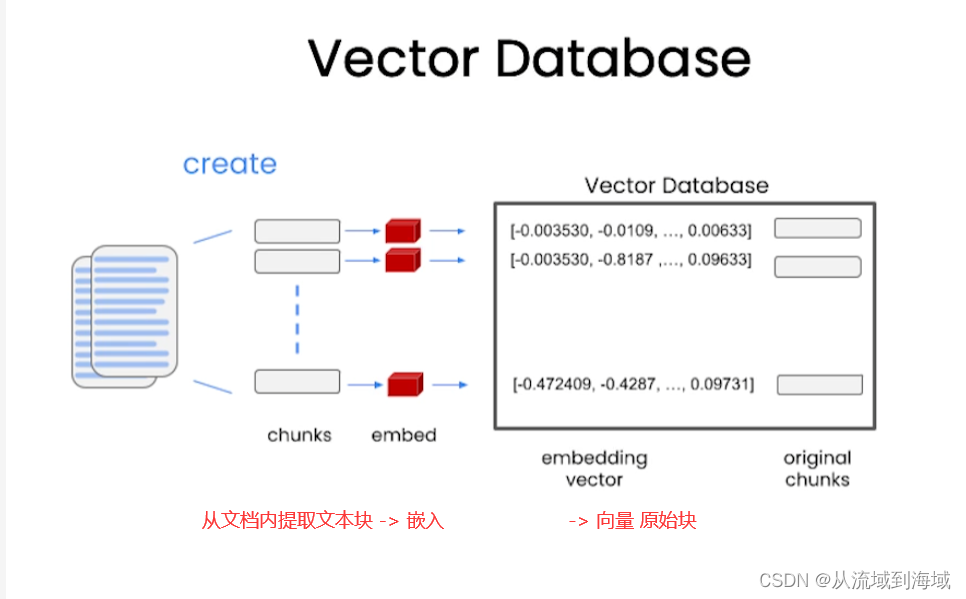
由于最大token數限制,LLM最多只能一次性處理幾千個token。因而如果有一個文檔級別的信息(遠大于幾千token),LLM沒辦法直接處理,因而引入詞嵌入(embedding)和向量存儲(vector store)來解決這個問題
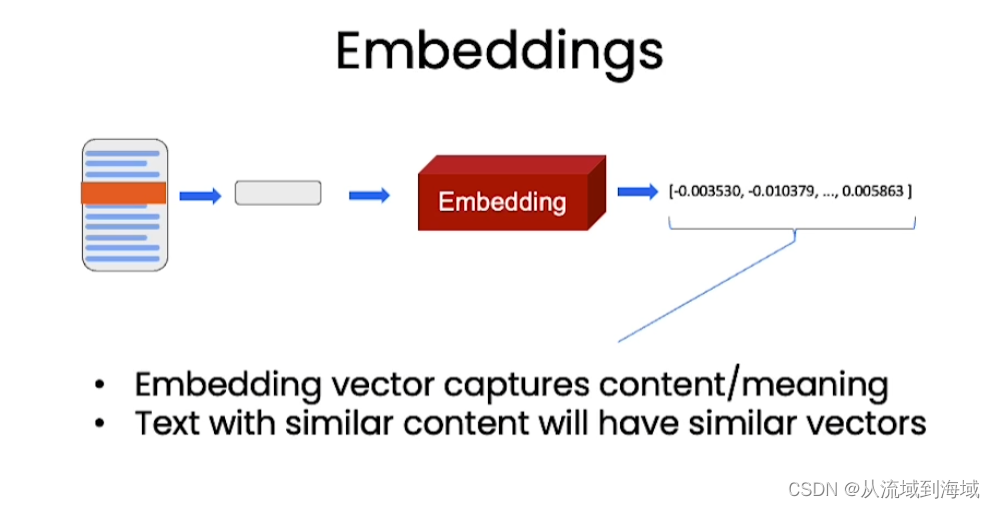
Embedding 詞嵌入
- 嵌入向量捕捉上下文/含義
- 相似(指語義相似)內容地文本對應相似的向量
如下圖:句子1)和2)語義相似,因而它們的表示向量也相似。

因而我們可以使用表示向量的相似程度來判定兩句話的相似程度,在回答文檔上的問題時,先找出和提問相似的信息,作為輸入喂給LLM,期望LLM能根據相似信息做出解答。
(筆者注:事實上,LLM內部就是將文本轉化為詞向量(tokenizer)來處理的,直接以向量形式存儲節省了文本到向量的轉化步驟。)
Vecotor Database 向量數據庫
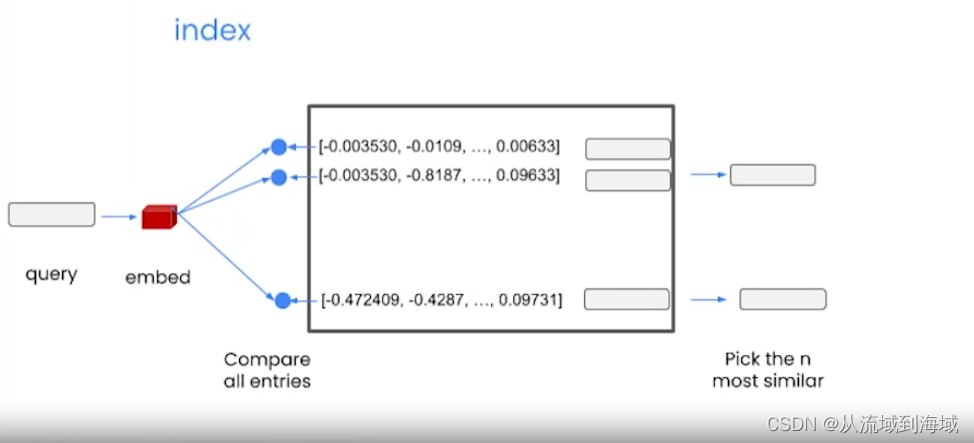
當一個查詢輸入時,先將其向量化,然后跟向量數據庫里面的所有項對比,找出最相似的n項。
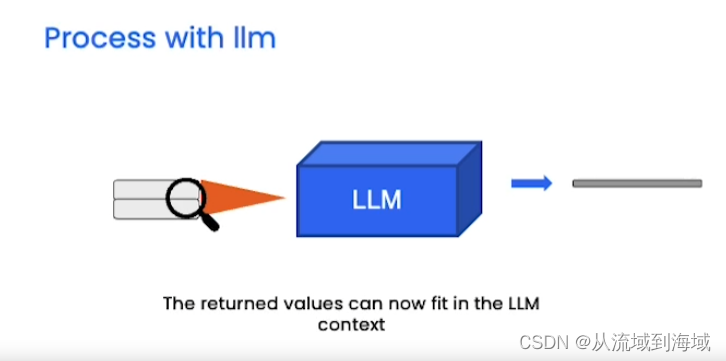
查詢結果放入輸入的上下文中喂給LLM,得到回復。
下面分步解釋過程:

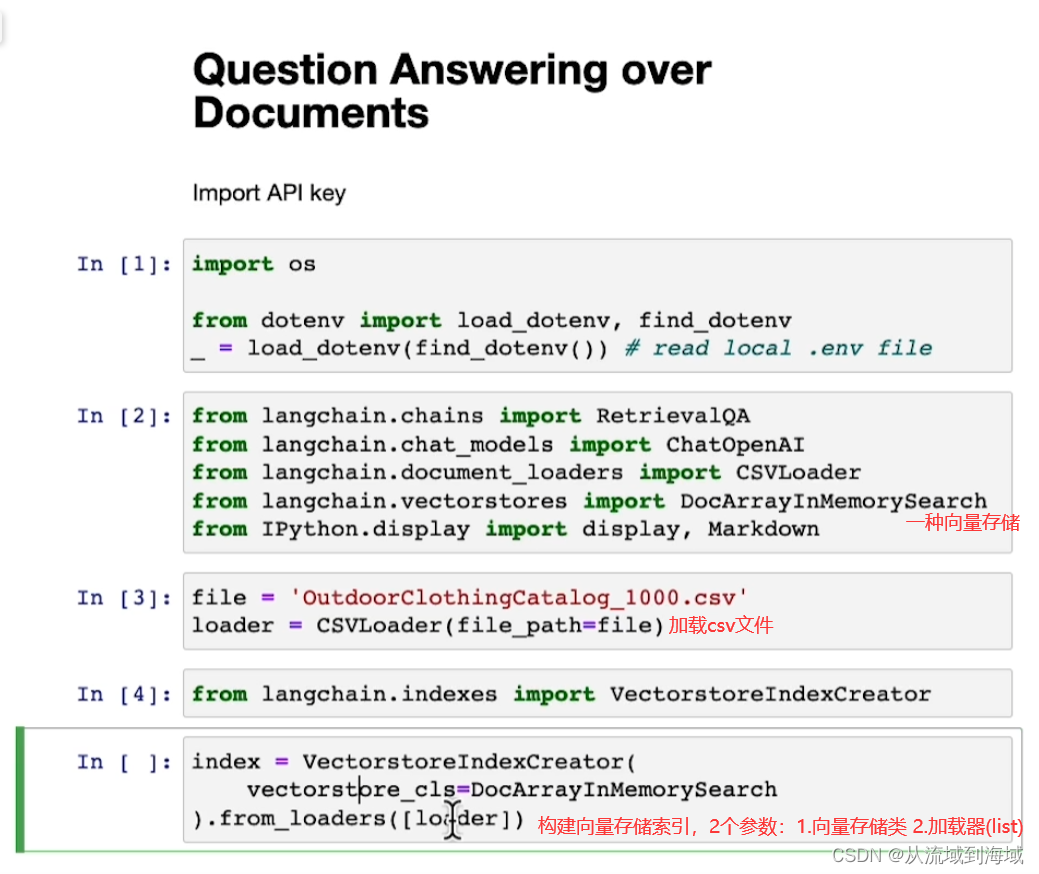
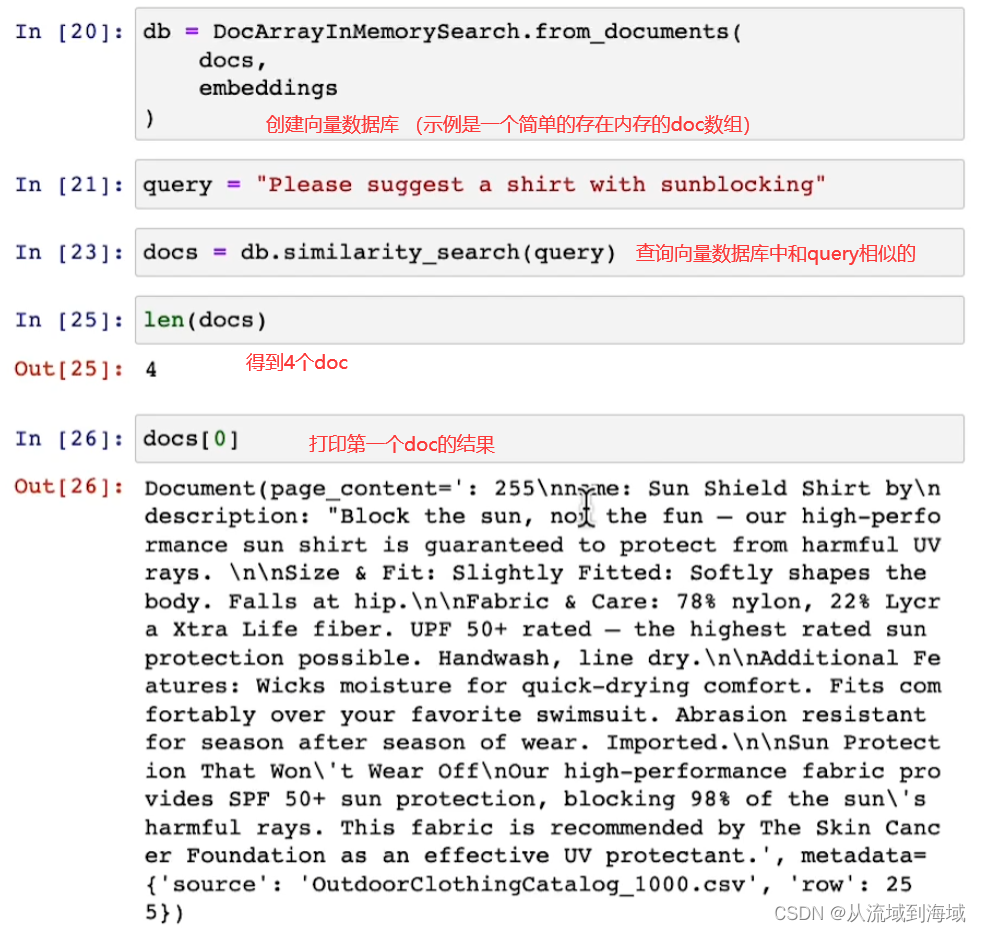
使用CSVLoader對象loader加載一個csv文件,里面存放了戶外服裝相關信息,打印第一行信息如上圖。
因為文本量比較少,不需要分塊,因而可以直接創建embedding,查看一個embedding(其實是一組詞向量):

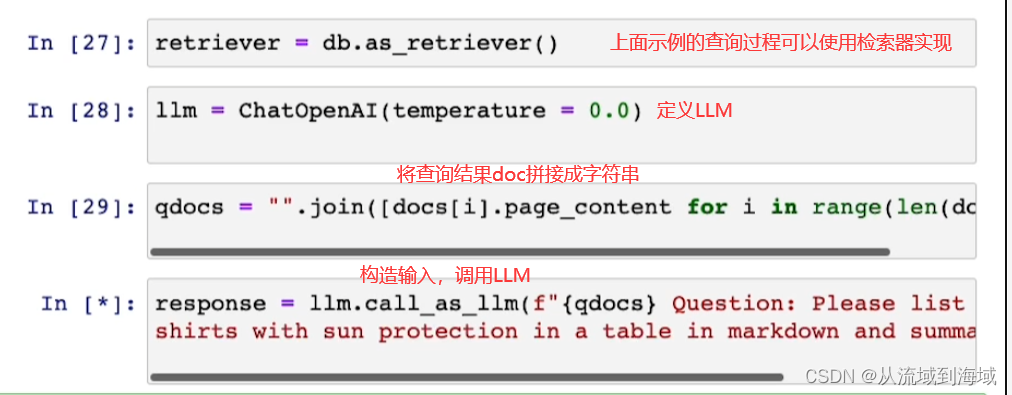

上述過程可以使用RetrievalQA chain輕松實現:


Stuff method 原材料方法

原材料是最簡單的方法,只需要將所有的原始數據放到prompt中作為上下文喂給語言模型。
優點:只需調用一次LLM。LLM可以一次性訪問所有數據。
缺點:LLM有上下文長度,對于大型文檔或者多個文檔超過上下文長度時無法生效。
additional methods 額外方法
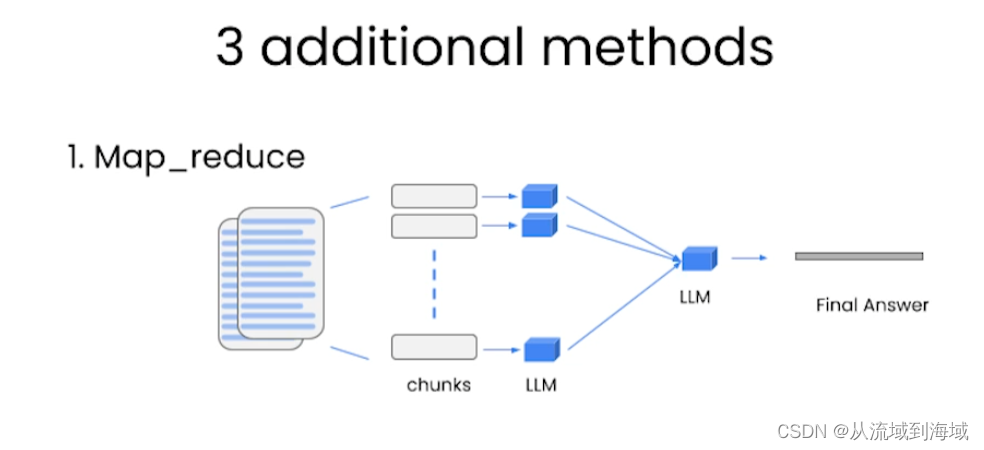
Map_reduce:將文檔每一個塊和提問一起輸入一個LLM中,匯總所有LLM結果,再使用一個LLM處理拿到最終答案。
(很有效,可以處理任意數量的文檔,還可以并行,但很貴,且獨立對待每一個文檔,即忽略了文檔之間的關聯性)

Refine:從一個塊和LLM中得到回復之后,再把結果作為下一輪的輸出,不斷優化到最后一個塊,得到最終結果。
(好處時考慮了文檔之間的關聯性,和map_reduce代價相同)
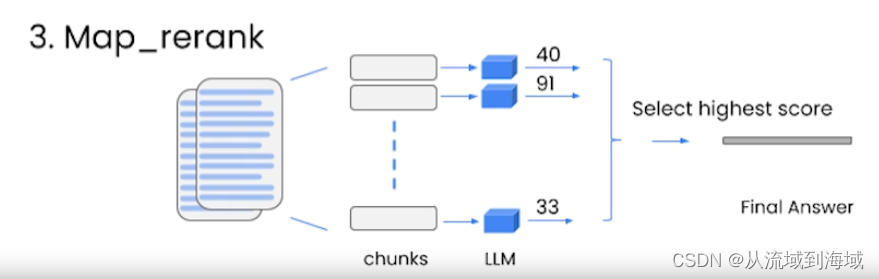
Map_rank:處理所有塊,給每一個塊和LLM的結果打分,選一個分最高的作為最終結果。
(需要LLM有能力給結果打分,和map_reduce代價相同,也沒有考慮文檔之間的關聯性)

)
 condition_variable、wait、notify_one、notify_all)

![[Machine Learning] decision tree 決策樹](http://pic.xiahunao.cn/[Machine Learning] decision tree 決策樹)


 創建UDR外部函數)
)
)



?為什么它在JavaScript中很有用?)





-JS句柄)