文獻分享
1. Multitask Learning for Super-Resolution
原題目:Multitask Learning for Super-Resolution of Seismic Velocity Model
全波形反演(FWI)是估算地下速度模型的強大工具。與傳統反演策略相比,FWI充分利用了地震波的運動學和動力特性,具有更高的精度和分辨率。近年來,低頻和中頻波數的FWI發展迅速,而高頻FWI由于其計算成本巨大,亟待解決。由于深度學習技術在各種地球物理問題中取得了顯著的性能,作者建議使用深度學習方法來提高FWI的效率和準確性。
Core parts:
1.super-resolution:目標是從給定的低分辨率圖像中獲得視覺上令人愉悅的高分辨率圖像。作者專注于使用SR技術來執行FWI任務,即使用SR作為后處理操作來提高FWI的質量。
2.multitask learning:把多個相關(related)的任務放在一起學習,同時學習多個任務。通過在一定程度上提高輔助任務的性能和共享參數,可以更好地泛化原始任務。
1.1 方法
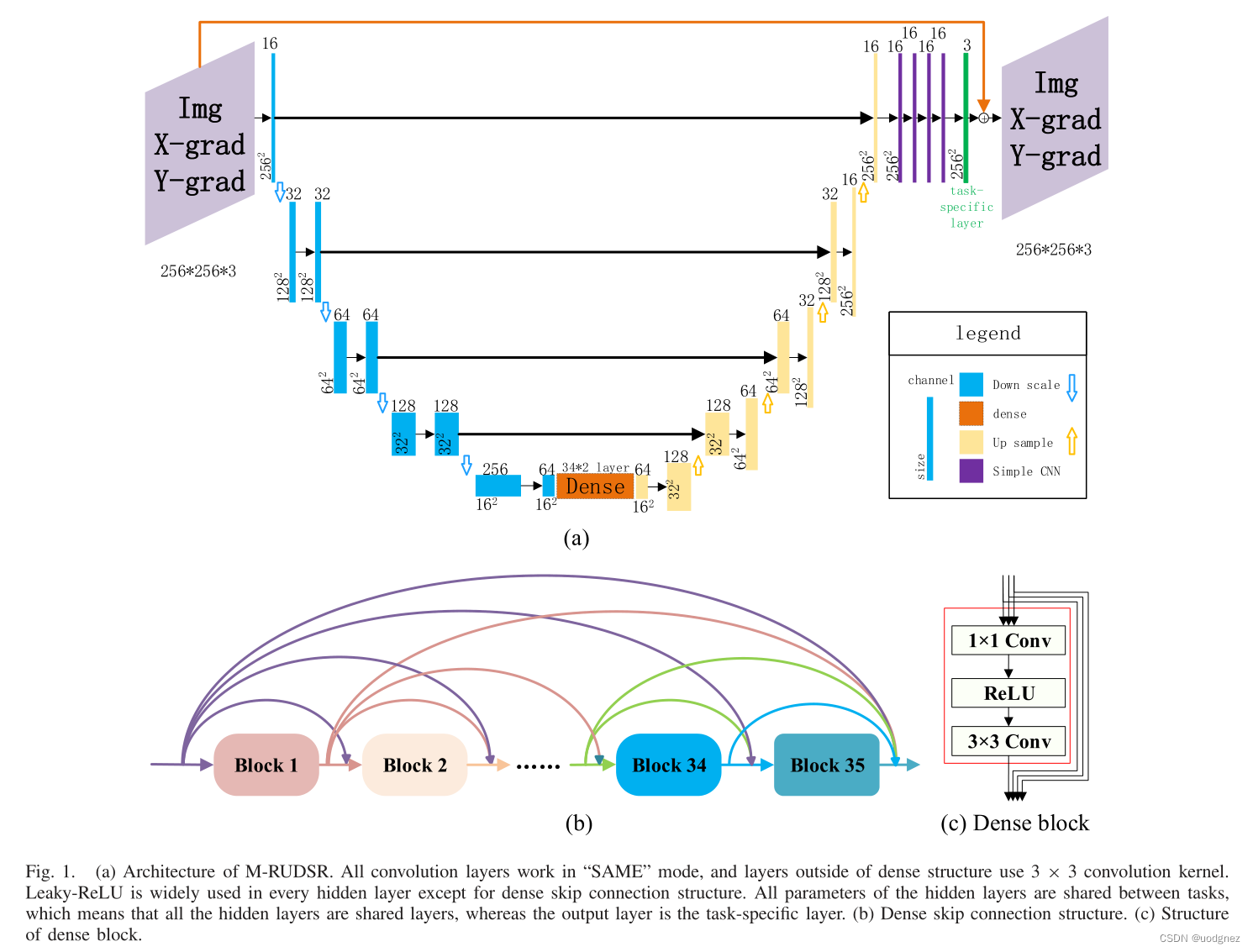
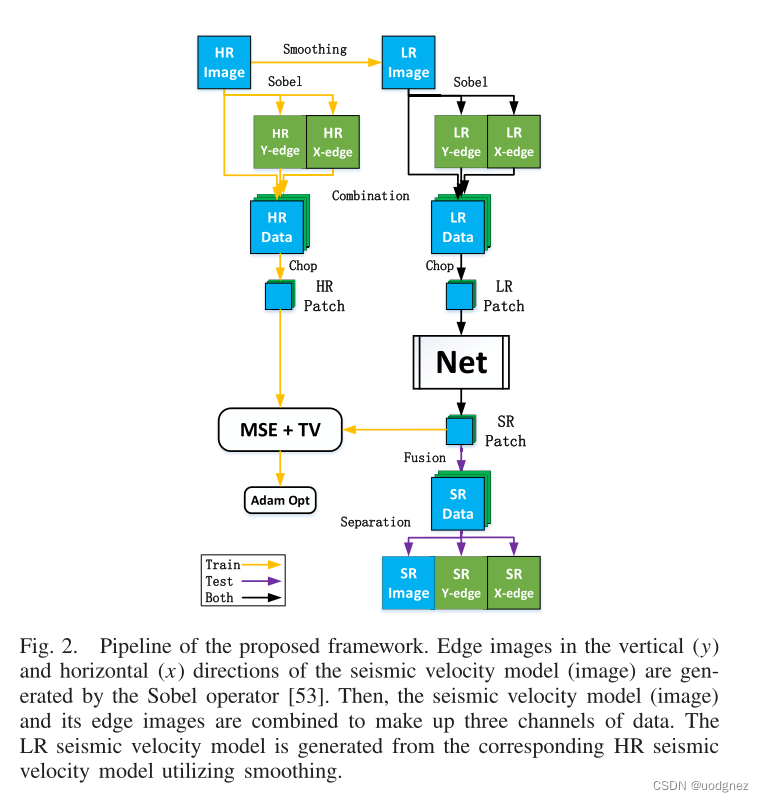
具有硬參數共享的MTL:邊界恢復是當前SR處理的難點,并且這在地震速度模型的SR中尤為突出。在地球物理學中,地震速度模型的邊緣信息是地質模型的重要組成部分,這證明了使用邊緣圖像重建作為輔助任務的相關性。并且由于地震速度模型與其邊緣圖像高度相關,因此采用硬參數共享策略更加高效。文章得到的邊緣圖像是原始圖像經過sobel算子卷積的結果。
邊緣圖像:是對原始圖像進行邊緣提取后得到的圖像。邊緣是圖像性區域和另一個屬性區域的交接處,是區域屬性發生突變的地方,是圖像中不確定性最大的地方,也是圖像信息最集中的地方,圖像的邊緣包含著豐富的信息。
混合損失函數:由MSE和TV組成,表達式如下:
loss ( Φ ) = mse ( Φ ) + TV ( Φ ) \text{loss}(\Phi)= \text{mse}(\Phi) +\text{TV}(\Phi) loss(Φ)=mse(Φ)+TV(Φ)
mse ( Φ ) = 1 N M ∑ k = 1 3 α k ∑ i = 1 N ∑ j = 1 M ( f ( I L , Φ ) i , j , k , ? I H i , j , k ) 2 , \text{mse}(\Phi) =\frac{1}{NM}\sum^{3}_{k=1}\alpha_k\sum^{N}_{i=1}\sum^{M}_{j=1}(f(I_L,\Phi)^{i,j,k},-I_H^{i,j,k})^2, mse(Φ)=NM1?k=1∑3?αk?i=1∑N?j=1∑M?(f(IL?,Φ)i,j,k,?IHi,j,k?)2, where ∑ k = 1 3 α k = 1 \sum^{3}_{k=1}\alpha_k=1 ∑k=13?αk?=1 and a k l 1 ( I H ? I L ) ∣ c = k ≡ C , k = 1 , 2 , 3 a_k l_1(I_H-I_L)|_{c=k}\equiv C, k=1,2,3 ak?l1?(IH??IL?)∣c=k?≡C,k=1,2,3
TV ( Φ ) = β 1 1 K 1 ∑ i = 1 N ∑ j = 2 M ∣ f ( I L , Φ ) i , j , 1 ? f ( I L , Φ ) i , j ? 1 , 1 ∣ + β 2 1 K 2 ∑ i = 1 N ∑ j = 2 M ∣ f ( I L , Φ ) i , j , 1 ? f ( I L , Φ ) i ? 1 , j , 1 ∣ , \text{TV}(\Phi)=\beta_1\frac {1}{K_1}\sum^{N}_{i=1}\sum^{M}_{j=2}\lvert f(I_L,\Phi)^{i,j,1}-f(I_L,\Phi)^{i,j-1,1}\rvert+ \ \beta_2\frac {1}{K_2}\sum^{N}_{i=1}\sum^{M}_{j=2}\lvert f(I_L,\Phi)^{i,j,1}-f(I_L,\Phi)^{i-1,j,1}\rvert, TV(Φ)=β1?K1?1?i=1∑N?j=2∑M?∣f(IL?,Φ)i,j,1?f(IL?,Φ)i,j?1,1∣+?β2?K2?1?i=1∑N?j=2∑M?∣f(IL?,Φ)i,j,1?f(IL?,Φ)i?1,j,1∣,
where K 1 = N ( M ? 1 ) , K 2 = ( N ? 1 ) M K_1 = N(M-1), K_2=(N-1)M K1?=N(M?1),K2?=(N?1)M.
同時,在訓練過程中,采用了學習率衰減方法。實際學習率表示為
η i = a i η 0 \eta_i = a^i\eta_0 ηi?=aiη0?
η 0 \eta_0 η0?為初始學習率, a a a為衰減率。
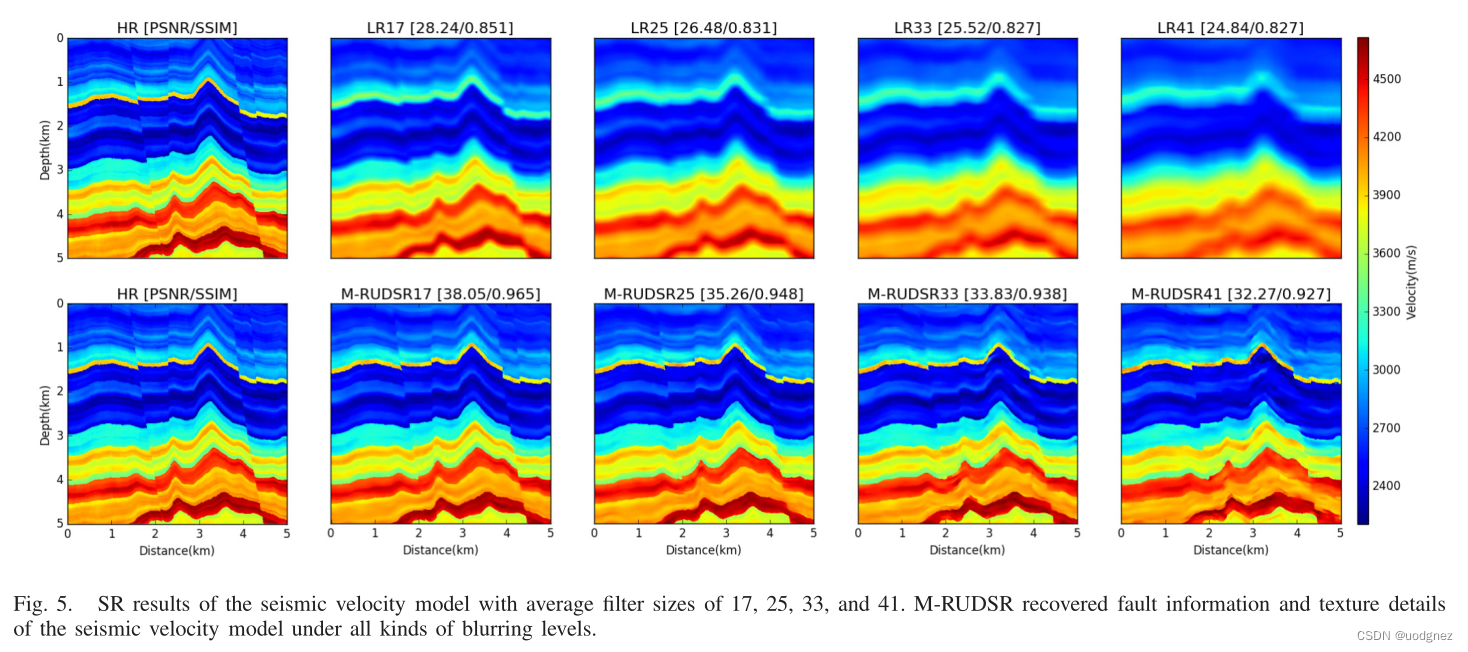
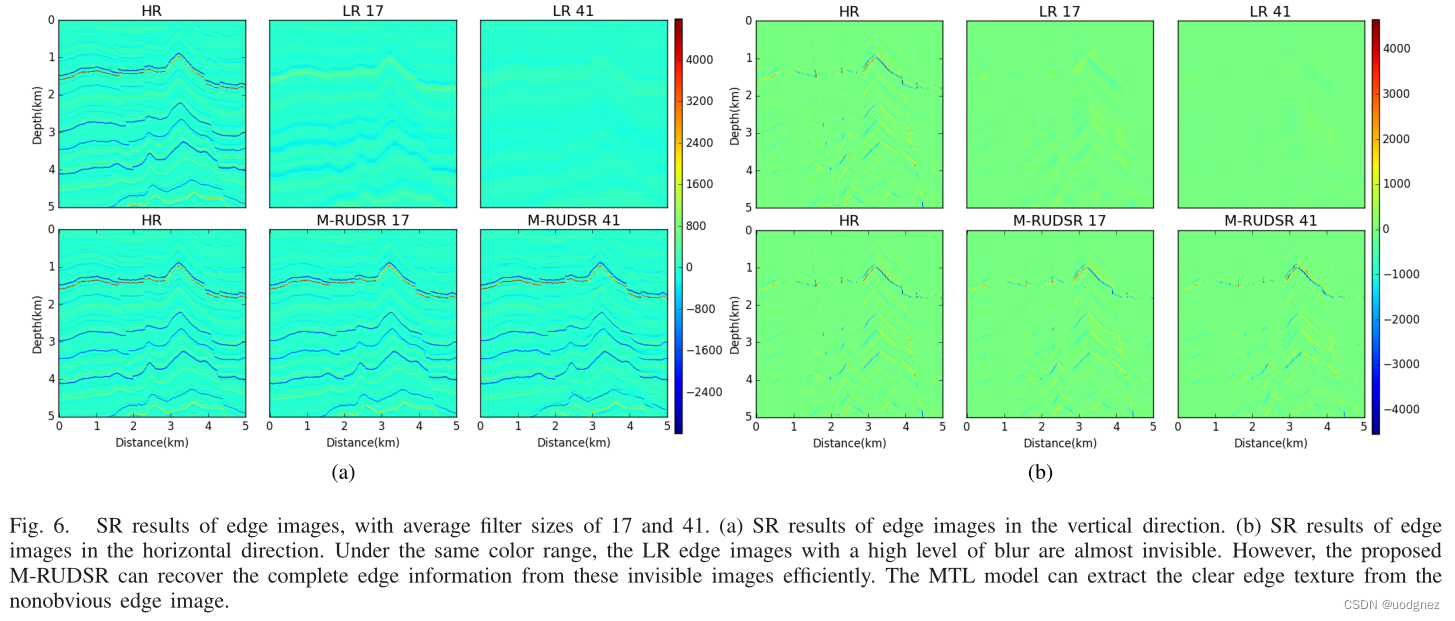
1.2 實驗結果
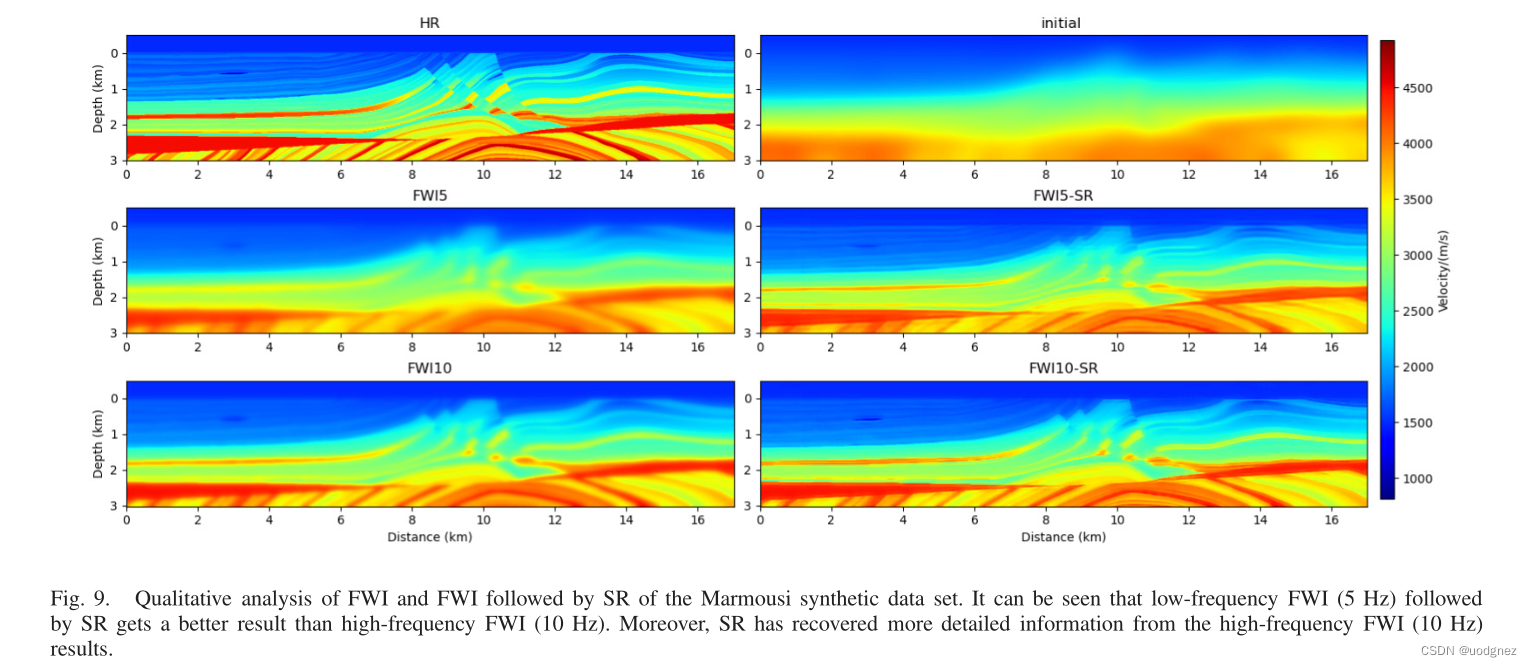
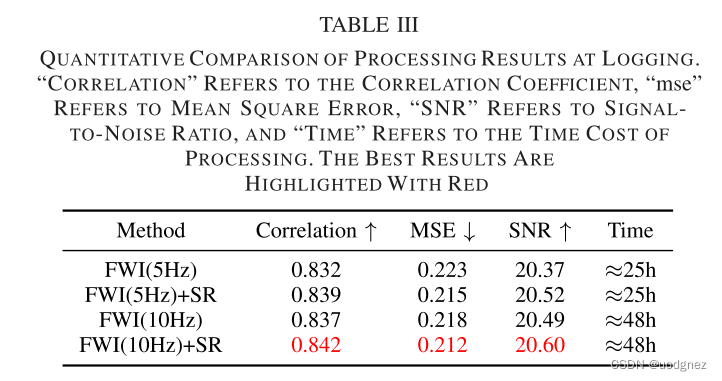
2. Super-resolution guided by seismic data
原題目:Super-Resolution of Seismic Velocity ModelGuided by Seismic Data
前面的提到的,M-RUDSR的多任務學習框架已經成功通過提高地震速度模型的分辨率,來提高FWI結果的精度。
然而,作者認為它并沒有充分利用地震數據。但由于地震速度模型和地震數據處于不同的頻段,單純增加模型輸入輸出通道來實現地震數據的利用效果有限。在M-RUSDR的基礎上,提出了M-RUSDRv2。
不同的是,M-RUSDR是僅將地震速度模型邊緣圖像的SR作為輔助任務以增強地震速度模型的分辨率,而M-RUSDRv2不僅考慮地震速度模型及其邊緣圖像,還考慮了地震數據及其邊緣圖像。并且M-RUSDRv2通過在特定數據的訓練,海量數據上的微調,實現了較強的泛化能力。
2.1 方法
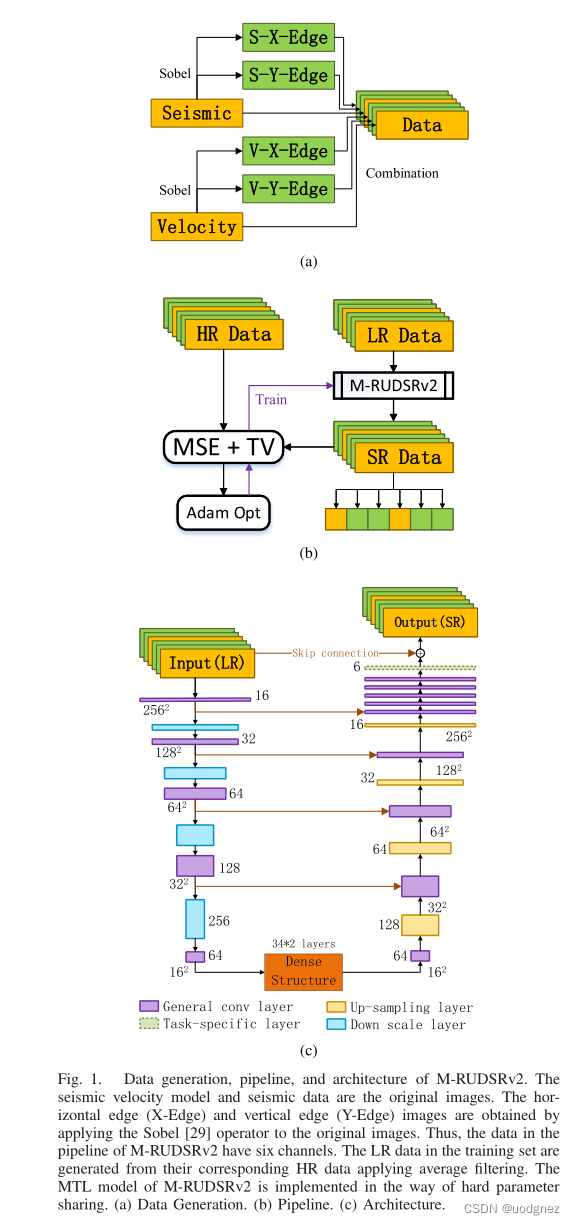
損失函數:與上文僅僅有一處不同,即 a k a_k ak?
∑ k = 1 K a k = 1 , K = 6 \sum_{k=1}^K a_k=1,K=6 ∑k=1K?ak?=1,K=6 and a k = m a k + 3 , m > 0 , k ∈ [ 1 , 3 ] a_k=ma_{k+3},m>0,k \in[1,3] ak?=mak+3?,m>0,k∈[1,3] and a k 1 ∥ I H k 1 ? I L k 2 ∥ 1 = a k 2 ∥ I H k 2 ? I L k 2 ∥ 1 , k 1 , k 2 ∈ [ 1 , 3 ] a_{k_1}\lVert I_H^{k_1}-I_{L}^{k_2}\rVert_1=a_{k_2}\lVert I_H^{k_2}-I_{L}^{k_2}\rVert_1, k_1,k_2 \in[1,3] ak1??∥IHk1???ILk2??∥1?=ak2??∥IHk2???ILk2??∥1?,k1?,k2?∈[1,3]
訓練過程分為三個步驟:
1.對具有相同模糊級別的地震速度模型和地震數據進行訓練,包括四種類型的訓練數據(與上文類似)。上式參數 m m m設置為1。此時模型僅針對特定數據進行初步學習,泛化能力較差。
2.對地震速度模型和各種模糊級別的地震數據進行訓練,包括16種訓練數據。因此,該模型廣泛學習各種數據,具有很強的泛化能力。 m m m值設置同上。
3.對地震速度模型和各種模糊級別的地震數據的訓練與步驟2中的訓練數據類似(圖3中的所有部分)。此外,將參數 m m m調整為 m > 1 m > 1 m>1,這使得損失函數對地震速度模型更加敏感。
2.2 實驗結果
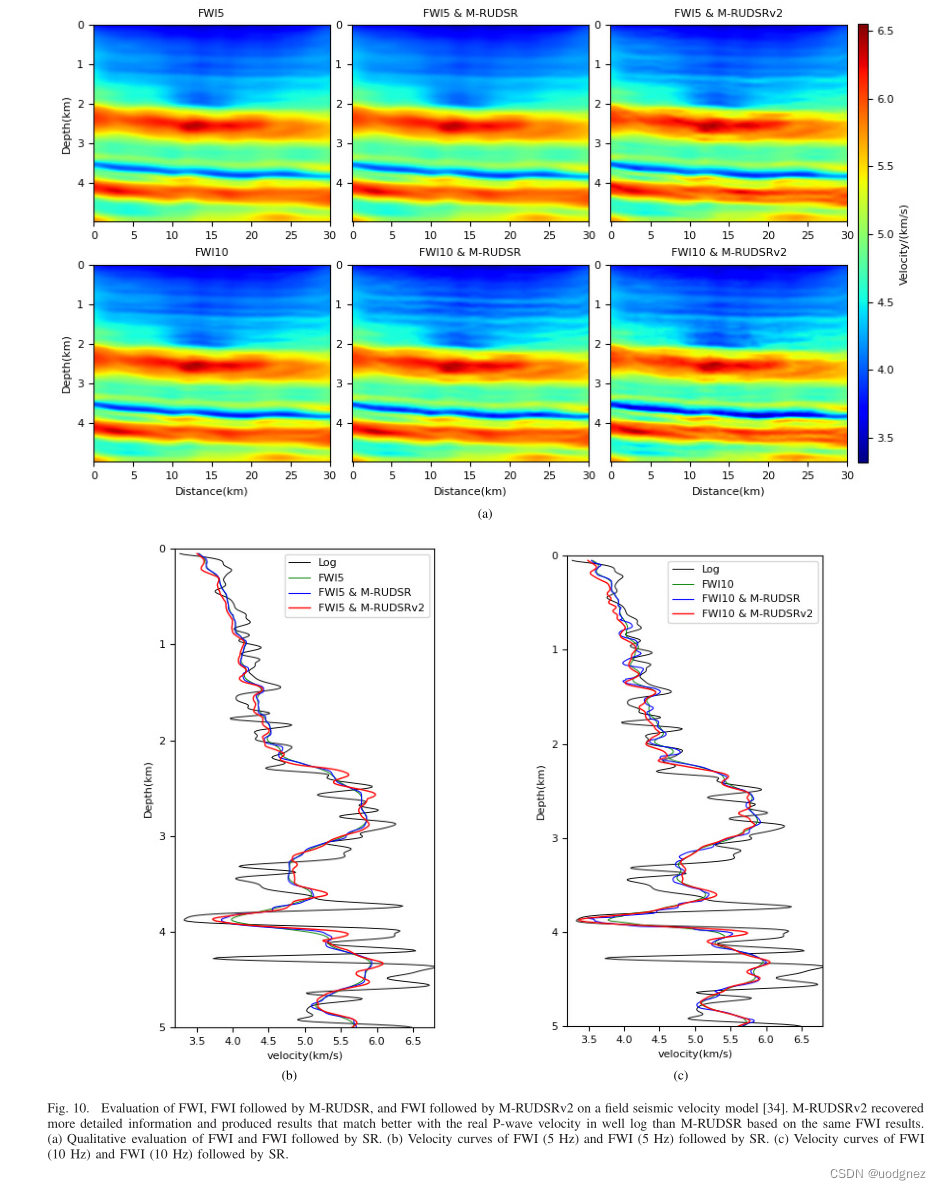










3.3 BSW的通信功能)





)


