一、python 之基礎語法、基礎數據類型、復合數據類型及基本操作
- 基礎語法規則
- 基礎數據類型
- 數字類型(Numbers)
- 字符串類型(String)
- 布爾類型(Boolean)
- 復合數據類型
- List(列表)
- Tuple(元組)
- Dictionary(字典)
- 補充知識
- 索引概念
- 切片
基礎語法規則
- 縮進規則
Python 以縮進來區分代碼塊,不同的縮進來區分代碼塊/代碼層級。同一代碼塊必須有相同的縮進,同時縮進不推薦空格和 Tab 字符混用。
# 行前面加入#為行注釋
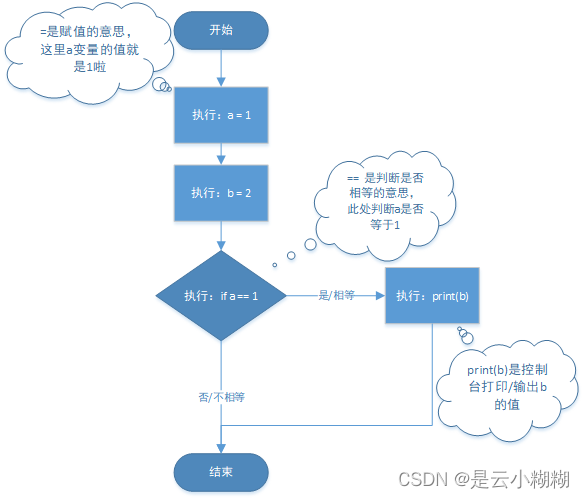
a = 1
b = 2
以上代碼為同一個層級代碼,具有相同的縮進,我愿稱之為一級代碼塊
由一級代碼塊進入二級,必須以冒號(:)開始且需要時定義方法、對象或判斷、循環條件等
# 一級代碼塊
a = 1
b = 2
#判斷條件,:號收尾
if a == 1 :#二級代碼塊print(b)
- 執行規則
基礎部分,認識python從上到下依次執行就可以了
上面代碼執行順序:
基礎數據類型
python的變量定義不需要聲名數據類型,但是變量內部存在類型區分。其中基礎數據類型分為
- 數字類型(Numbers)
- 字符串類型(String)
- 爾類型(Boolean)
數字類型(Numbers)
數字類型:整數(int)、長整型(long) 、浮點數(float)、復數(complex)
入門級知道:整數(int)、浮點數(float)即可,不需要記那么多,用到了再說嘍
# 整數
a = 1# 浮點數理解成小數即可
b = 1.1
字符串類型(String)
字符串類型用來表示文本信息,在Python中使用一對單引號 ’ ’ 或雙引號 " " 來創建字符串。
# 單引號
a= 'shiyuncode.com'# 雙引號
b= "Hello, world!"# 獲取第一個字符 "H"
b1 = b[0] # 字符串切片,獲取索引2到3的子字符串 "ll"
b23 = b[2:4]
布爾類型(Boolean)
布爾類型,布爾類型意思真/假,python對應的真就是 True 表示,假就是False表示。布爾類型通常用于條件判斷和邏輯運算。
# 布爾類型
a = Trueb = False
復合數據類型
Python的符合數據類型,我愿理解為一個變量可以存儲多個基礎數據,其中包括
- 列表(List)
- 元組(Tuple)
- 字典(Dictionary)
List(列表)
列表是一種有序的集合,可以存儲多個元素,每個元素可以是不同的數據類型。列表用方括號 [ ] 表示,元素之間用逗號分隔。
# 定義一個水果列表
fruits = ['apple', 'banana', 'orange', 'grape']# 訪問列表元素
first_fruit = fruits[0] # 獲取第一個元素 "apple"# 列表的切片
some_fruits = fruits[1:3] # 獲取索引1到2的子列表 ['banana', 'orange']# 列表的修改和添加
fruits[2] = 'kiwi' # 修改列表中的元素
fruits.append('pear') # 添加元素到列表末尾
Tuple(元組)
元組和列表類似,也是一種有序的集合,但與列表不同的是,元組的元素一旦創建就不能被修改,相當于不可變的列表。元組用圓括號 ( ) 表示。
# 元組的創建
tp = (1, 2)# 訪問元組元素
x = tp[0] # 獲取第一個元素 1
Dictionary(字典)
字典是一種無序的鍵-值對集合,用花括號 { } 表示。每個鍵對應一個值,鍵和值之間用冒號分隔。這里數據結構和Json的格式一致誒。
# 字典的創建
person = {'name': 'shiyuncode.com','age': 30
}# 訪問字典元素
person_name = person['name'] # 獲取鍵'name'對應的值 "shiyuncode.com"# 字典的修改
person['age'] = 31 # 修改鍵'age'對應的值# 字典的添加
person['gender'] = 'female' # 添加新的鍵值對
補充知識
索引概念
索引的起點是0,也就是第1個,對應的索引是0,第2個對應的索引是1,以此類推。
- 字符串索引圖示
 - 列表索引圖示
- 列表索引圖示
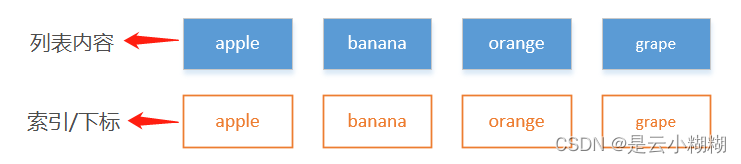 其它帶有索引的類型類似
其它帶有索引的類型類似
切片
切片從序列(如列表、元組、字符串等)中獲取子序列的操作。通過指定起始索引和結束索引來獲取序列的一部分,返回一個新的序列。切片在Python中非常常用,可以用于提取、復制和操作序列中的一段數據。
my_str = '012345'
my_list = [0, 1, 2, 3, 4, 5]# 獲取索引1到3的子數據'123'/[1, 2, 3]
sub_str = my_str[1:4]
sub_list = my_list[1:4]# 獲取索引0到2的子數據'01'/[0, 1]
sub_str2 = my_str[:3]
sub_list2 = my_list[:3]# 獲取索引3到末尾的子數據'345'/[3, 4, 5]
sub_str3 = my_str[3:]
sub_list3 = my_list[3:]# 獲取完整的副本'0123456'/[0, 1, 2, 3, 4, 5]
full_copy_str = my_str[:]
full_copy_list = my_list[:]
這里我們可以看到,如果 : 前面不寫則表示從頭開始,如果后面不寫則表示一直到最后。






)



)








