批量發送消息
Kafka 采用了批量發送消息的方式,通過將多條消息按照分區進行分組,然后每次發送一個消息集合,看似很平常的一個手段,其實它大大提升了 Kafka 的吞吐量。
消息壓縮
消息壓縮的目的是為了進一步減少網絡傳輸帶寬。而對于壓縮算法來說,通常是數據量越大,壓縮效果才會越好。
因為有了批量發送這個前期,從而使得 Kafka 的消息壓縮機制能真正發揮出它的威力。對比壓縮單條消息,同時對多條消息進行壓縮,能大幅減少數據量,從而更大程度提高網絡傳輸率。
多分區
Kafka 使用的是多分區策略,消息被組織成一個一個的主題(topic),而主題可以劃分為多個分區(partition)。每個分區都是一個有序、持久化的日志,而 Kafka 通過分區來實現消息的水平擴展和負載均衡。
每個分區內的消息有一個唯一的偏移量(offset),消費者可以根據偏移量讀取消息。一個主題可以有多個分區,而消費者可以并行地消費不同分區的消息。
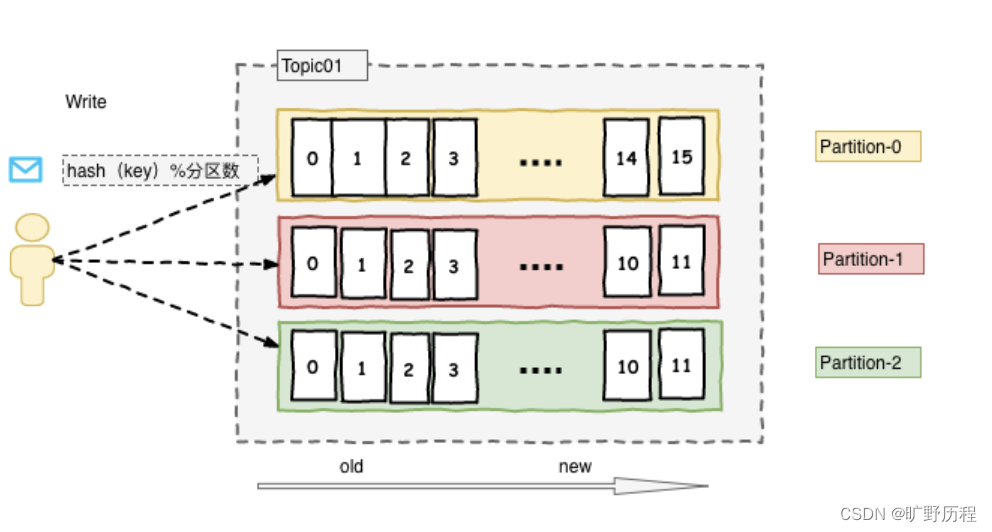
Kafka 使用分區的副本機制來實現數據的冗余備份,而每個主題的分區可以配置多個副本,其中一個副本為 leader(領導者),其他副本為 follower(跟隨者)。所有寫入操作都由 leader 處理,而 follower 會定期從 leader 同步數據,保持與 leader 數據的一致性。
當 leader 節點故障時,Kafka 會自動從剩余的 follower 中選舉新的 leader,確保數據的可用性。
?
順序寫入
Kafka 的特性之一就是高吞吐率,但是 Kafka 的消息是保存在磁盤上的,一般認為在磁盤上讀寫數據是會降低性能的,但是 Kafka 即使是普通的服務器,Kafka 也可以輕松支持每秒百萬級的寫入請求,超過了大部分的消息中間件,這種特性也使得 Kafka 在日志處理等海量數據場景廣泛應用。
Kafka 為防止丟失數據,會把收到的消息都寫入到硬盤中。為了優化寫入速度 Kafka 采用了兩個技術:順序寫入和 MMFile。
因為硬盤是機械結構,每次讀寫都會尋址->寫入,其中尋址是一個“機械動作”,它是最耗時的。所以硬盤最討厭隨機I/O,最喜歡順序I/O。為了提高讀寫硬盤的速度,Kafka就是使用順序I/O。這樣省去了大量的內存開銷以及節省了IO尋址的時間。
即便是順序寫入硬盤,硬盤的訪問速度還是不可能追上內存。所以 Kafka 的寫入性能也不可能和內存進行對比,因此 Kafka 的數據并不是實時的寫入硬盤中,它充分利用了現代操作系統分頁存儲(Page Cache)來利用內存提高 I/O 效率。
Memory Mapped Files
Memory Mapped Files(MMAP或MMFile)也稱內存映射文件,在64位操作系統中一般可以表示20G的數據文件,它的工作原理是直接利用操作系統的 Page 實現文件到物理內存的直接映射。完成 MMAP 映射后,用戶對內存的所有操作會被操作系統自動的刷新到磁盤上,極大地降低了 IO 使用率。

?常規的文件操作為了提高讀寫性能,使用了 Page Cache 機制,但是由于頁緩存處在內核空間中,不能被用戶進程直接尋址,所以讀文件時還需要通過系統調用,將頁緩存中的數據再次拷貝到用戶空間中。而采用 mmap 后,它將磁盤文件與進程虛擬地址做了映射,并不會招致系統調用,以及額外的內存 copy 開銷,從而提高了文件讀取效率。
Page Cache
雖然磁盤順序寫已經很快了,但是對比內存順序寫仍然慢了幾個數量級。Kafka 用到了 Page Cache 技術,利用了操作系統本身的緩存技術,在讀寫磁盤日志文件時,其實操作的都是內存,然后由操作系統決定什么時候將 Page Cache 里的數據真正刷入磁盤。

?如果在極端的情況下會存在丟失數據的風險。
零拷貝
傳統模式下,當需要對一個文件進行傳輸的時候,其具體流程細節如下:
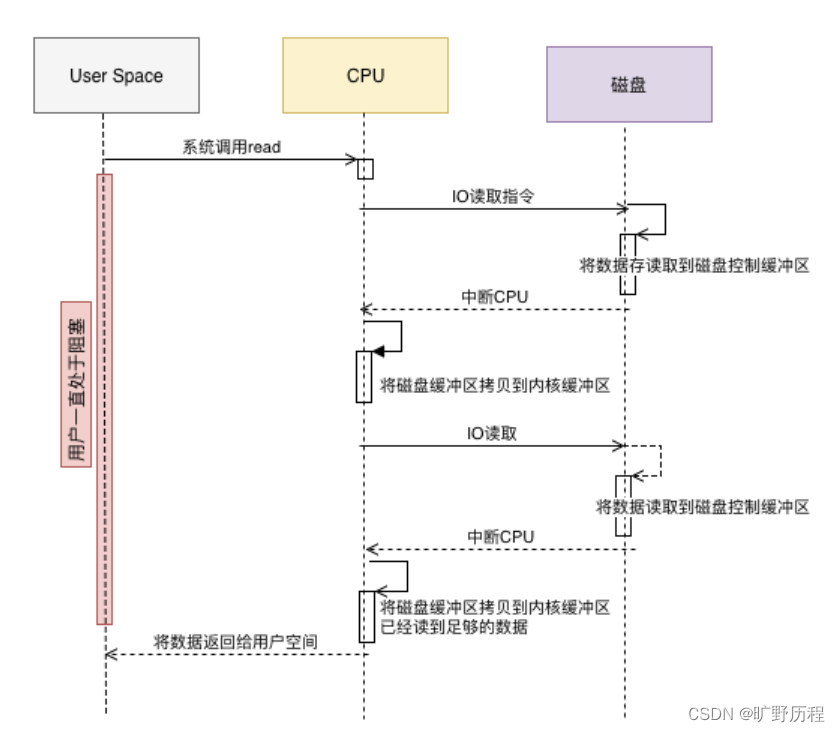

- 用戶進程調用 read ,系統調用向操作系統發出IO請求,請求讀取數據到自己的內存緩沖區中。自己進入阻塞狀態。
- 操作系統收到請求后,進一步將IO請求發送磁盤。
- 磁盤驅動器收到內核的IO請求,把數據從磁盤讀取到驅動器的緩沖中。此時不占用CPU。當驅動器的緩沖區被讀滿后,向內核發起中斷信號告知自己緩沖區已滿。
- 內核收到中斷,使用CPU時間將磁盤驅動器的緩存中的數據拷貝到內核緩沖區中。
- 如果內核緩沖區的數據少于用戶申請的讀的數據,重復步驟3跟步驟4,直到內核緩沖區的數據足夠多為止。
- 將數據從內核緩沖區拷貝到用戶緩沖區,同時從系統調用中返回,完成任務。
???????
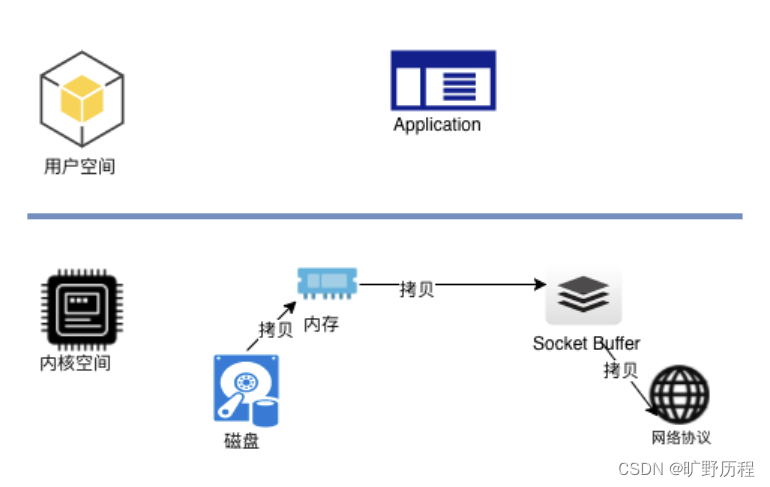
?Kafka服務器在響應客戶端讀取的時候,底層使用 ZeroCopy 技術,直接將磁盤無需拷貝到用戶空間,而是直接將數據通過內核空間傳遞輸出,數據并沒有抵達用戶空間。




)



)









)
低功耗模式)