1 前言
🔥學長分享優質競賽項目,今天要分享的是
🚩 GRU的 電影評論情感分析 - python 深度學習 情感分類
🥇學長這里給一個題目綜合評分(每項滿分5分)
- 難度系數:3分
- 工作量:3分
- 創新點:4分
這是一個較為新穎的競賽課題方向,學長非常推薦!
🧿 更多資料, 項目分享:
https://gitee.com/dancheng-senior/postgraduate
1 項目介紹
其實,很明顯這個項目和微博謠言檢測是一樣的,也是個二分類的問題,因此,我們可以用到學長之前提到的各種方法,即:
樸素貝葉斯或者邏輯回歸以及支持向量機都可以解決這個問題。
另外在深度學習中,我們可以用CNN-Text或者RNN以及LSTM等模型最好。
當然在構建網絡中也相對簡單,相對而言,LSTM就比較復雜了,為了讓不同層次的同學們可以接受,學長就用了相對簡單的GRU模型。
如果大家想了解LSTM。以后,學長會給大家詳細介紹。
2 情感分類介紹
其實情感分析在自然語言處理中,情感分析一般指判斷一段文本所表達的情緒狀態,屬于文本分類問題。一般而言:情緒類別:正面/負面。當然,這就是為什么本人在前面提到情感分析實際上也是二分類問題的原因。
3 數據集
學長本次使用的是非常典型的IMDB數據集。
該數據集包含來自互聯網的50000條嚴重兩極分化的評論,該數據被分為用于訓練的25000條評論和用于測試的25000條評論,訓練集和測試集都包含50%的正面評價和50%的負面評價。該數據集已經經過預處理:評論(單詞序列)已經被轉換為整數序列,其中每個整數代表字典中的某個單詞。
查看其數據集的文件夾:這是train和test文件夾。
接下來就是以train文件夾介紹里面的內容
然后就是以neg文件夾介紹里面的內容,里面會有若干的text文件:
4 實現
4.1 數據預處理
#導入必要的包
? import zipfile
? import os
? import io
? import random
? import json
? import matplotlib.pyplot as plt
? import numpy as np
? import paddle
? import paddle.fluid as fluid
? from paddle.fluid.dygraph.nn import Conv2D, Pool2D, Linear, Embedding
? from paddle.fluid.dygraph.base import to_variable
? from paddle.fluid.dygraph import GRUUnit
? import paddle.dataset.imdb as imdb?
?
? #加載字典
? def load_vocab():
? vocab = imdb.word_dict()
? return vocab
? #定義數據生成器
? class SentaProcessor(object):
? def __init__(self):
? self.vocab = load_vocab()def data_generator(self, batch_size, phase='train'):if phase == "train":return paddle.batch(paddle.reader.shuffle(imdb.train(self.vocab),25000), batch_size, drop_last=True)elif phase == "eval":return paddle.batch(imdb.test(self.vocab), batch_size,drop_last=True)else:raise ValueError("Unknown phase, which should be in ['train', 'eval']")
步驟
-
首先導入必要的第三方庫
-
接下來就是數據預處理,需要注意的是:數據是以數據標簽的方式表示一個句子,因此,每個句子都是以一串整數來表示的,每個數字都是對應一個單詞。當然,數據集就會有一個數據集字典,這個字典是訓練數據中出現單詞對應的數字標簽。
4.2 構建網絡
這次的GRU模型分為以下的幾個步驟
- 定義網絡
- 定義損失函數
- 定義優化算法
具體實現如下
?
#定義動態GRUclass DynamicGRU(fluid.dygraph.Layer):def __init__(self,size,param_attr=None,bias_attr=None,is_reverse=False,gate_activation='sigmoid',candidate_activation='relu',h_0=None,origin_mode=False,):super(DynamicGRU, self).__init__()self.gru_unit = GRUUnit(size * 3,param_attr=param_attr,bias_attr=bias_attr,activation=candidate_activation,gate_activation=gate_activation,origin_mode=origin_mode)self.size = sizeself.h_0 = h_0self.is_reverse = is_reversedef forward(self, inputs):hidden = self.h_0res = []for i in range(inputs.shape[1]):if self.is_reverse:i = inputs.shape[1] - 1 - iinput_ = inputs[ :, i:i+1, :]input_ = fluid.layers.reshape(input_, [-1, input_.shape[2]], inplace=False)hidden, reset, gate = self.gru_unit(input_, hidden)hidden_ = fluid.layers.reshape(hidden, [-1, 1, hidden.shape[1]], inplace=False)res.append(hidden_)if self.is_reverse:res = res[::-1]res = fluid.layers.concat(res, axis=1)return res
?
class GRU(fluid.dygraph.Layer):
def init(self):
super(GRU, self).init()
self.dict_dim = train_parameters[“vocab_size”]
self.emb_dim = 128
self.hid_dim = 128
self.fc_hid_dim = 96
self.class_dim = 2
self.batch_size = train_parameters[“batch_size”]
self.seq_len = train_parameters[“padding_size”]
self.embedding = Embedding(
size=[self.dict_dim + 1, self.emb_dim],
dtype=‘float32’,
param_attr=fluid.ParamAttr(learning_rate=30),
is_sparse=False)
h_0 = np.zeros((self.batch_size, self.hid_dim), dtype=“float32”)
h_0 = to_variable(h_0)
self._fc1 = Linear(input_dim=self.hid_dim, output_dim=self.hid_dim*3)self._fc2 = Linear(input_dim=self.hid_dim, output_dim=self.fc_hid_dim, act="relu")self._fc_prediction = Linear(input_dim=self.fc_hid_dim,output_dim=self.class_dim,act="softmax")self._gru = DynamicGRU(size=self.hid_dim, h_0=h_0)def forward(self, inputs, label=None):emb = self.embedding(inputs)o_np_mask =to_variable(inputs.numpy().reshape(-1,1) != self.dict_dim).astype('float32')mask_emb = fluid.layers.expand(to_variable(o_np_mask), [1, self.hid_dim])emb = emb * mask_embemb = fluid.layers.reshape(emb, shape=[self.batch_size, -1, self.hid_dim])fc_1 = self._fc1(emb)gru_hidden = self._gru(fc_1)gru_hidden = fluid.layers.reduce_max(gru_hidden, dim=1)tanh_1 = fluid.layers.tanh(gru_hidden)fc_2 = self._fc2(tanh_1)prediction = self._fc_prediction(fc_2)if label is not None:acc = fluid.layers.accuracy(prediction, label=label)return prediction, accelse:return prediction
4.3 訓練模型
?
def train():with fluid.dygraph.guard(place = fluid.CUDAPlace(0)): # # 因為要進行很大規模的訓練,因此我們用的是GPU,如果沒有安裝GPU的可以使用下面一句,把這句代碼注釋掉即可# with fluid.dygraph.guard(place = fluid.CPUPlace()):
?
processor = SentaProcessor()
train_data_generator = processor.data_generator(batch_size=train_parameters[“batch_size”], phase=‘train’)
model = GRU()sgd_optimizer = fluid.optimizer.Adagrad(learning_rate=train_parameters["lr"],parameter_list=model.parameters())steps = 0Iters, total_loss, total_acc = [], [], []for eop in range(train_parameters["epoch"]):for batch_id, data in enumerate(train_data_generator()):steps += 1doc = to_variable(np.array([np.pad(x[0][0:train_parameters["padding_size"]], (0, train_parameters["padding_size"] - len(x[0][0:train_parameters["padding_size"]])),'constant',constant_values=(train_parameters["vocab_size"]))for x in data]).astype('int64').reshape(-1))label = to_variable(np.array([x[1] for x in data]).astype('int64').reshape(train_parameters["batch_size"], 1))model.train()prediction, acc = model(doc, label)loss = fluid.layers.cross_entropy(prediction, label)avg_loss = fluid.layers.mean(loss)avg_loss.backward()sgd_optimizer.minimize(avg_loss)model.clear_gradients()if steps % train_parameters["skip_steps"] == 0:Iters.append(steps)total_loss.append(avg_loss.numpy()[0])total_acc.append(acc.numpy()[0])print("step: %d, ave loss: %f, ave acc: %f" %(steps,avg_loss.numpy(),acc.numpy()))if steps % train_parameters["save_steps"] == 0:save_path = train_parameters["checkpoints"]+"/"+"save_dir_" + str(steps)print('save model to: ' + save_path)fluid.dygraph.save_dygraph(model.state_dict(),save_path)draw_train_process(Iters, total_loss, total_acc)

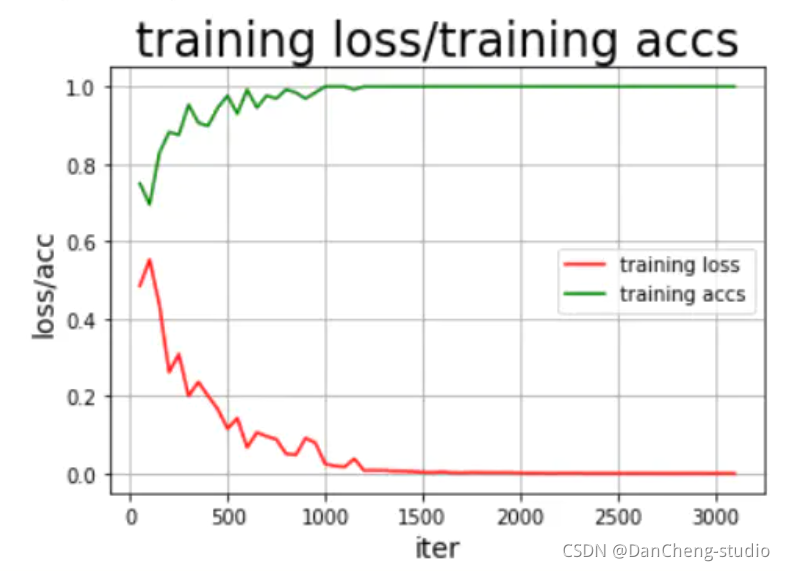
4.4 模型評估

結果還可以,這里說明的是,剛開始的模型訓練評估不可能這么好,很明顯是過擬合的問題,這就需要我們調整我們的epoch、batchsize、激活函數的選擇以及優化器、學習率等各種參數,通過不斷的調試、訓練最好可以得到不錯的結果,但是,如果還要更好的模型效果,其實可以將GRU模型換為更為合適的RNN中的LSTM以及bi-
LSTM模型會好很多。
4.5 模型預測
train_parameters["batch_size"] = 1
with fluid.dygraph.guard(place = fluid.CUDAPlace(0)):sentences = 'this is a great movie'data = load_data(sentences)print(sentences)print(data)data_np = np.array(data)data_np = np.array(np.pad(data_np,(0,150-len(data_np)),"constant",constant_values =train_parameters["vocab_size"])).astype('int64').reshape(-1)infer_np_doc = to_variable(data_np)model_infer = GRU()model, _ = fluid.load_dygraph("data/save_dir_750.pdparams")model_infer.load_dict(model)model_infer.eval()result = model_infer(infer_np_doc)print('預測結果為:正面概率為:%0.5f,負面概率為:%0.5f' % (result.numpy()[0][0],result.numpy()[0][1]))

訓練的結果還是挺滿意的,到此為止,我們的本次項目實驗到此結束。
5 最后
🧿 更多資料, 項目分享:
https://gitee.com/dancheng-senior/postgraduate


)









》ISBN978-7-111-63687-8 第11章 11.1.3 樹的性質 節 第664頁的例9說明)



)


