
文章目錄
- 命名空間概念
- 命名空間的定義
- 1、正常的命名空間定義
- 2、命名空間可以嵌套
- 3、同一個工程中允許存在多個相同名稱的命名空間,編譯器最后會合成同一個命名空間中
- 命名空間的使用
- 1、加命名空間名稱及作用域限定符
- 2、使用using將命名空間中某個成員引入
- 3、使用using namespace 命名空間名稱 引入
- 4、使用using namespace std C++標準庫命名空間 引入

命名空間概念
在C/C++中,變量、函數和后面要學到的類都是大量存在的,這些變量、函數和類的名稱將都存 在于全局作用域中,可能會導致很多沖突。使用命名空間的目的是對標識符的名稱進行本地化, 以避免命名沖突或名字污染,namespace關鍵字的出現就是針對這種問題的。
很多人在開始接觸C++的時候,知道打印一行 hello world 都是這樣寫的:
#include
using namespace std;
int main()
{
cout << “hello world” << endl;
}
但是要問你iostream 和 namespace std 是什么,在這行代碼中起到什么作用,很多初學者基本上是回答不上來的,就知道怎么寫,不知道其中的意義。
那么現在就開始認識命名空間這個概念
大家都知道C++是在c語言基礎上建立的,c語言很多地方存在很多缺陷的,C++就創建了一個命名空間的概念來彌補這一缺陷
這一缺陷是什么呢?創建一個全局變量 int rand = 0 ,你只引入了頭文件 <stdio.h> ,利用printf打印出rand,不會產生任何問題。可當你再引用了 <stdlib.h> ,再次運行程序就會出現問題

這里報錯,顯示rand重定義,這里的問題叫做命名沖突,因為 stdlib.h 這個庫里面已經定義了rand,且定義成的一個函數,而我們這個全局變量rand是int類型的元素,系統在識別這個rand的時候就會找到兩個rand,它不知道去打印哪一個,當然這里剛好rand在庫里面是個函數 且與%d發生沖突,顯示兩個錯誤
在c語言中,解決這一問題,最簡單粗暴的方法,就是改變量名稱,防止與庫里面的同名變量命名沖突,這樣當然可以解決問題,但如果你在一個團隊中需要分組完成一個項目,每個組的個別變量都一樣,這時候怎么辦,總不能組與組直接吵一架吧,這會大大降低工作效率不說,也影響團隊氛圍嘛,所以顯然這種方法不可取。
既然c語言不能解決這個問題,那么C++就提出了命名空間來解決
這里就要引入一個關鍵字 namespace ,它的作用是創建一個域把創建的rand變量保護起來,下面是代碼實現
namespace Yuan
{int rand = 0;
}
int main()
{printf("%d\n", rand);
}
namespace 后面的名字隨便取什么都行,只要自己記得住
這樣就不會產生命名沖突的問題,main里面打印的是庫函數里面的rand(準確來說是訪問全局的域來找到rand),并不是Yuan里面的rand
要想打印Yuan里面的rand需要在rand前面加Yuan::
namespace Yuan
{int rand = 0;
}
int main()
{printf("%d\n", Yuan::rand);
}
namespace創建的是一個命名為Yuan的局部域,這里需要回顧一下C語言里面的全局變量和局部變量
int i = 0;
int main()
{int i = 1;printf("%d", i);
}
現在問大家一個問題,這里打印的i是0還是1?
答案是1,這里滿足一個
就近原則,打印結果是1,這里是直接訪問的局部域里面的局部變量i
但是如果你想在局部域里面訪問全局變量i,怎么辦?
需要在i前面加
::
int i = 0;
int main()
{int i = 1;printf("%d\n", ::i);printf("%d\n", i);
}
::叫做域作用符,作用是指定在哪個域里面去找這個i,這里::左邊是空白,就代表在全局域里面去找
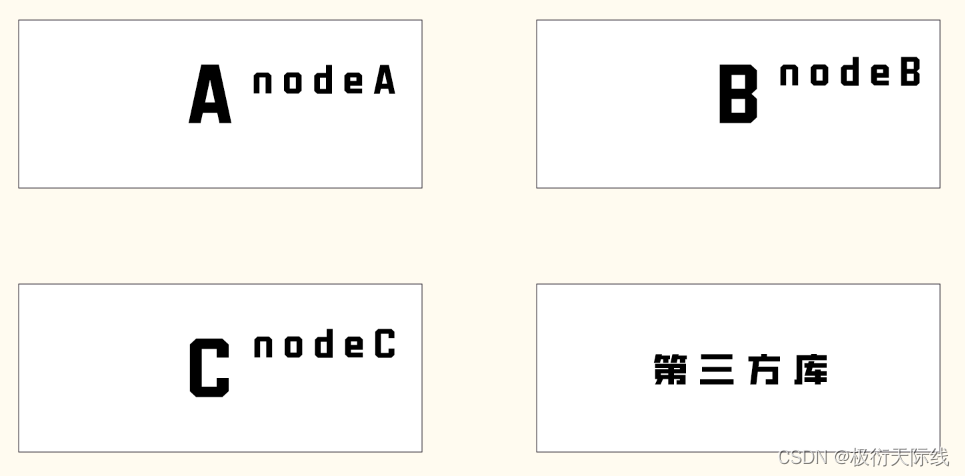
所以命名沖突問題有了命名空間這個概念,就迎刃而解了。A B C三個小組,每個小組寫的所有的變量全都保存在他們自己所定義的命名空間里面,且命名空間分別交nodeA nodeB nodeC,即使各自的命名空間里面有相同的變量,也不會收到任何影響
命名空間的定義
1、正常的命名空間定義
命名空間里面可以定義變量,函數,類型等
namespace Yuan
{int rand = 0;void func(){printf("func()\n");}struct TreeNode{struct TreeNode* left;struct TreeNode* right;int val;};
}int main()
{printf("%p\n", rand);printf("%p\n", Yuan::rand);Yuan::func();struct Yuan::TreeNode node;return 0;
}
2、命名空間可以嵌套
命名空間可以嵌套,就想循環語句一樣
namespace sql
{int a = 0;namespace Yuan{int rand = 0;void func(){printf("func()\n");}struct TreeNode{struct TreeNode* left;struct TreeNode* right;int val;};}
}int main()
{printf("%p\n", rand);printf("%p\n", sql::Yuan::rand);sql::Yuan::func();struct sql::Yuan::TreeNode node;return 0;
}
3、同一個工程中允許存在多個相同名稱的命名空間,編譯器最后會合成同一個命名空間中
這一點怎么來理解呢,比如說在一個項目中我們添加了Stack.h(棧),Stack.cpp(棧),Queue.h(隊列),Queue.cpp(隊列),里面有很多變量,類型,函數等,現在要把它們放到一個命名空間里面,我們會擔心發生命名沖突的問題,怎么處理呢?
這四個文件中分別定義一個 每次為 Yuan 的命名空間,并把文件中所有東西放到命名空間中,這四個命名空間名字相同,但不在一個文件中,編譯器會自動把它們合并到一個命名空間中,不用擔心命名沖突的問題
namespace Yuan
{typedef int STDataType;typedef struct Stack{STDataType* a;int top; // 棧頂的位置int capacity; // 容量}ST;
}#include "Stack.h"//棧
#include "Queue.h"//隊列int main()
{Yuan::ST st;Yuan::StackInit(&st);Yuan::Queue q;Yuan::QueueInit(&q);
}
命名空間的使用
1、加命名空間名稱及作用域限定符
int main()
{printf("%d\n", Yuan::a);return 0;
}
前面已經介紹了通過域作用符來進行命名空間的使用,這也是最基本最簡單的一種命名空間使用方式,可這個方式如果在命名空間使用比較多的時候就顯得有些繁瑣了,可能這里沒有加域作用符,那里又沒有加,導致一堆bug,所以就有了以下三種方式
2、使用using將命名空間中某個成員引入
using Yuan::b;
int main()
{printf("%d\n", Yuan::a);printf("%d\n", b);return 0;
}
3、使用using namespace 命名空間名稱 引入
using namespce N;
int main()
{printf("%d\n", Yuan::a);printf("%d\n", b);Add(10, 20);return 0;
}
4、使用using namespace std C++標準庫命名空間 引入
前面兩種相對就比較保守,這個就是很大膽的直接展開C++全部標準庫,雖然是很大程度上避免了一定的沖突,但是這樣全部展開,就可能存在沖突的風險,所以直接全部展開不推薦使用,如果要用應該是這樣寫
#include<iostream>
//using namespace std
int main()
{std::cout << "hello world" << std::endl;return 0;
}




》ISBN978-7-111-63687-8 第11章 11.1.3 樹的性質 節 第664頁的例9說明)



)





)


![[Flutter]有的時候調用setState(() {})報錯?](http://pic.xiahunao.cn/[Flutter]有的時候調用setState(() {})報錯?)


