💓博主個人主頁:不是笨小孩👀
?專欄分類:數據結構與算法👀 C++👀 刷題專欄👀 C語言👀
🚚代碼倉庫:笨小孩的代碼庫👀
?社區:不是笨小孩👀
🌹歡迎大家三連關注,一起學習,一起進步!!💓

C++
- 什么是C++
- C++的關鍵字
- 命名空間
- 命名空間的定義
- 命名空間的使用
- C++的輸入和輸出
- 缺省參數
- 函數重載
- 引用
- 引用特性
- 常引用
- 使用場景
- 引用和指針的區別
- 內聯函數
- 特性
- auto關鍵字
- 基于范圍的for循環
- 指針空值nullptr
什么是C++
C語言是結構化和模塊化的語言,適合處理較小規模的程序。對于復雜的問題,規模較大的程序,需要高度的抽象和建模時,C語言則不合適。為了解決軟件危機, 20世紀80年代, 計算機界提出了OOP(object oriented programming:面向對象)思想,支持面向對象的程序設計語言應運而生。
1982年,Bjarne Stroustrup博士在C語言的基礎上引入并擴充了面向對象的概念,發明了一種新的程序語言。為了表達該語言與C語言的淵源關系,命名為C++。因此:C++是基于C語言而產生的,它既可以進行C語言的過程化程序設計,又可以進行以抽象數據類型為特點的基于對象的程序設計,還可以進行面向對象的程序設計。
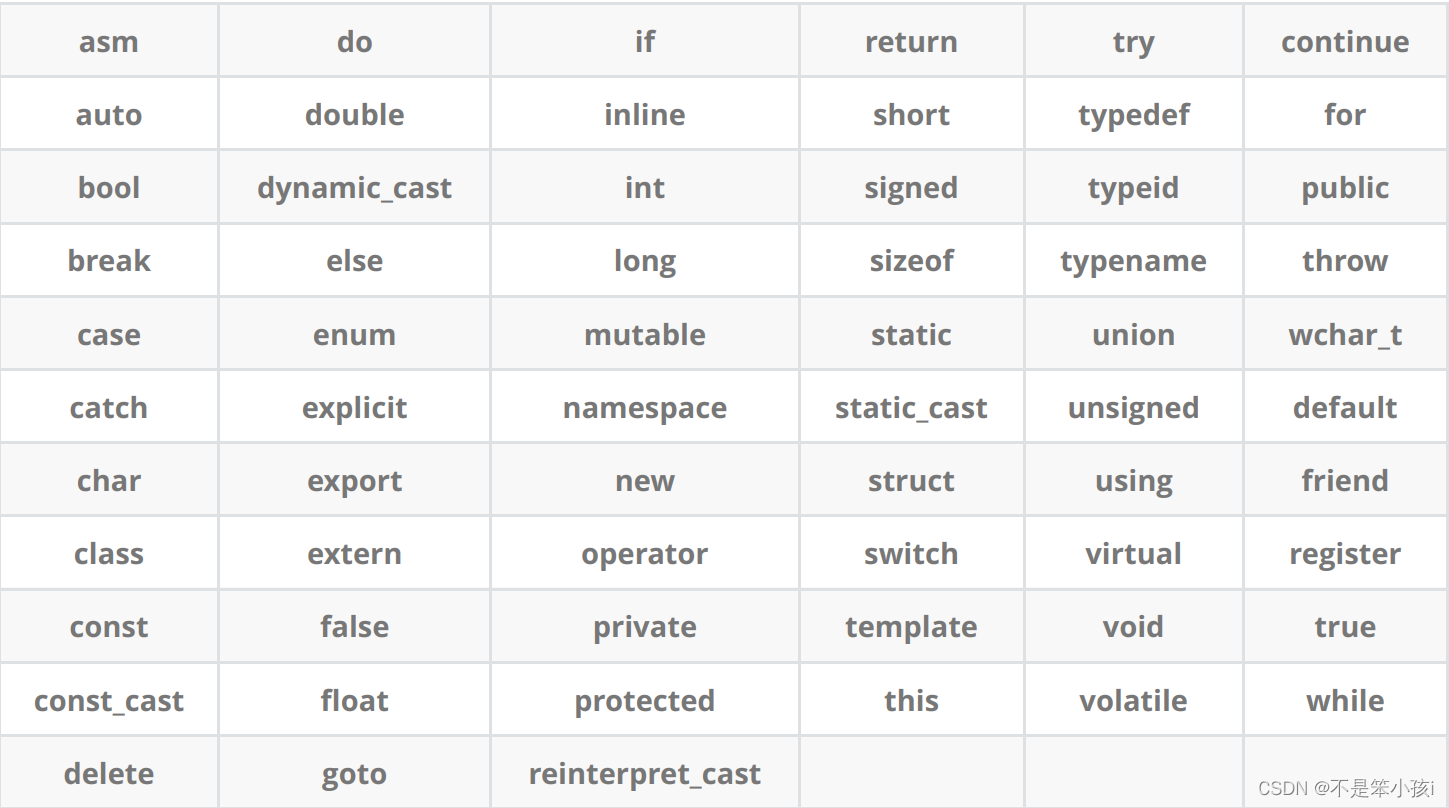
C++的關鍵字
C語言有32個關鍵字,而C++有63個關鍵字
C++關鍵字如下:
命名空間
在C/C++中,變量、函數和后面要學到的類都是大量存在的,這些變量、函數類的名稱將都存在于全局作用域中,可能會導致很多沖突。使用命名空間的目的是對標識符的名稱進行本地化,以避免命名沖突或名字污染,namespace關鍵字的出現就是針對這種問題的。
總而言之,命名空間的出現就是為了解決命名沖突的問題。
命名空間的定義
定義命名空間,需要使用到namespace關鍵字,后面跟命名空間的名字,然后接一對{}即可,{}中即為命名空間的成員。
- 命名空間是可以嵌套使用的
- 同一個工程中允許存在多個相同名稱的命名空間,編譯器最后會合成同一個命名空間中。
命名空間的使用
- 命名空間名稱及作用域限定符
作用域限定符是什么呢?
::就是作用域限定符
代碼舉例:
#include <iostream>
int a = 0;
namespace name
{int a = 110;
}
int main()
{printf("%d\n", a);//a = 0printf("%d\n", name::a); // a= 110return 0;
}
沒有限定的情況下,程序默認在全局查找,加了限定就很明顯了。
- 使用using將命名空間中某個成員引入
如果某個命名空間內的變量我們需要經常用到,如果我們用第一種方法就需要每次都加個限定符,現在我們使用using就可以將那個變量從空間釋放出來,讓外面直接可以訪問到。但是前提是外面不能有和這個變量同名的變量,不然會編譯錯誤。
#include <iostream>int b = 0;namespace name
{int a = 110;int b = 0;
}
using name::a;int main()
{printf("%d\n", a);printf("%d\n", a);return 0;
}- 使用using namespace 命名空間名稱 引入
直接將命名空間的所有內容公開,所有內容別人都可以訪問,但是風險很大。很有可能會出現重命名。
#include <iostream>namespace name
{int a = 110;int b = 0;
}
using namespace name;int main()
{printf("%d\n", a);printf("%d\n", a);return 0;
}C++的輸入和輸出
std是C++標準庫的命名空間名,C++將標準庫的定義實現都放到這個命名空間中。
C++輸入時cin,輸出是cout。
說明:
- 使用cout標準輸出對象(控制臺)和cin標準輸入對象(鍵盤)時,必須包含< iostream >頭文件
以及按命名空間使用方法使用std。- cout和cin是全局的流對象,endl是特殊的C++符號,表示換行輸出,他們都包含在包含< iostream >頭文件中。
- <<是流插入運算符,>>是流提取運算符。
- 使用C++輸入輸出更方便,不需要像printf/scanf輸入輸出時那樣,需要手動控制格式。 C++的輸入輸出可以自動識別變量類型。
- 實際上cout和cin分別是ostream和istream類型的對象。
#include <iostream>
using namespace std;int main()
{int a = 0;double d = 0.0;cin >> a >> d;cout << a << " " << d << endl;return 0;
}
缺省參數
缺省參數是聲明或定義函數時為函數的參數指定一個缺省值。在調用該函數時,如果沒有指定實參則采用該形參的缺省值,否則使用指定的實參。
void func(int a = 0)
{cout << a << endl;
}int main()
{func();// a = 0func(10); // a = 10return 0;
}
- 全缺省參數
void Func(int a = 10, int b = 20, int c = 30)
{
cout<<"a = "<<a<<endl;
cout<<"b = "<<b<<endl;
cout<<"c = "<<c<<endl;
}
- 半缺省參數
void Func(int a = 10, int b = 20, int c = 30)
{
cout<<"a = "<<a<<endl;
cout<<"b = "<<b<<endl;
cout<<"c = "<<c<<endl;
}
注意:
- 半缺省參數必須從右往左依次來給出,不能間隔著給
- 缺省參數不能在函數聲明和定義中同時出現(如果生命與定義位置同時出現,恰巧兩個位置提供的值不同,那編譯器就無法確定到底該用那個缺省值。我們一般是聲明給,定義函數時不給)
- 缺省值必須是常量或者全局變量。
void func(int b,int a = 0);void func(int b,int a)
{cout << b << endl;
}
函數重載
函數重載:是函數的一種特殊情況,C++允許在同一作用域中聲明幾個功能類似的同名函數,這些同名函數的形參列表(參數個數 或 類型 或 類型順序)不同,常用來處理實現功能類似數據類型不同的問題。
- 參數類型不同
int Add(int left, int right)
{cout << "int Add(int left, int right)" << endl;return left + right;
}
double Add(double left, double right)
{cout << "double Add(double left, double right)" << endl;return left + right;
}
- 參數個數不同
void f()
{cout << "f()" << endl;
}
void f(int a)
{cout << "f(int a)" << endl;
}
- 參數順序不同
void f(int a, char b)
{cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{cout << "f(char b, int a)" << endl;
}
引用
引用不是新定義一個變量,而是給已存在變量取了一個別名,編譯器不會為引用變量開辟內存空間,它和它引用的變量共用同一塊內存空間。
類型& 引用變量名(對象名) = 引用實體;
注意:引用類型必須和引用實體是同種類型的。
int main()
{int a = 0;int& b = a;cout << &a << endl;cout << &b << endl;return 0;
}
這里a和b的地址就是一樣的。
引用特性
- 引用在定義時必須初始化
- 一個變量可以有多個引用
- 引用一旦引用一個實體,再不能引用其他實體
int main()
{int a = 0;int& b = a;int& c = a;int& d = b;cout << &a << endl;cout << &b << endl;cout << &c << endl;cout << &d << endl;return 0;
}
b、c、d其實表示的都是a,他們4個的地址也是一樣的。
常引用
void TestConstRef()
{const int a = 10;//int& ra = a; // 該語句編譯時會出錯,a為常量const int& ra = a;// int& b = 10; // 該語句編譯時會出錯,b為常量const int& b = 10;double d = 12.34;//int& rd = d; // 該語句編譯時會出錯,類型不同,所以在賦值的過程中會有一個中間值,這個中間值是常量const int& rd = d;
}總結:
權限可以平移,可以縮小,但不能放大。
使用場景
- 當參數
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
- 做返回值
int& Count()
{static int n = 0;n++;// ...return n;
}
如果函數返回時,出了函數作用域,如果返回對象還在(還沒還給系統),則可以使用引用返回,如果已經還給系統了,則必須使用傳值返回。
以值作為參數或者返回值類型,在傳參和返回期間,函數不會直接傳遞實參或者將變量本身直接返回,而是傳遞實參或者返回變量的一份臨時的拷貝,因此用值作為參數或者返回值類型,效率是非常低下的,尤其是當參數或者返回值類型非常大時,效率就更低。傳值和指針在作為傳參以及返回值類型上效率相差很大。
引用和指針的區別
在語法概念上引用就是一個別名,沒有獨立空間,和其引用實體共用同一塊空間。在底層實現上實際是有空間的,因為引用是按照指針方式來實現的。
引用和指針的不同的:
- 引用概念上定義一個變量的別名,指針存儲一個變量地址。
- 引用在定義時必須初始化,指針沒有要求。
- 引用在初始化時引用一個實體后,就不能再引用其他實體,而指針可以在任何時候指向任何一個同類型實體。
- 沒有NULL引用,但有NULL指針。
- 在sizeof中含義不同:引用結果為引用類型的大小,但指針始終是地址空間所占字節個數(32位平臺下占4個字節)。
- 引用自加即引用的實體增加1,指針自加即指針向后偏移一個類型的大小。
- 有多級指針,但是沒有多級引用。
- 訪問實體方式不同,指針需要顯式解引用,引用編譯器自己處理。
- 引用比指針使用起來相對更安全。
內聯函數
以inline修飾的函數叫做內聯函數,編譯時C++編譯器會在調用內聯函數的地方展開,沒有函數調用建立棧幀的開銷,內聯函數提升程序運行的效率。
特性
- inline是一種以空間換時間的做法,如果編譯器將函數當成內聯函數處理,在編譯階段,會用函數體替換函數調用,缺陷:可能會使目標文件變大,優勢:少了調用開銷,提高程序運行效率。
- inline對于編譯器而言只是一個建議,不同編譯器關于inline實現機制可能不同,一般建 議:將函數規模較小(即函數不是很長,具體沒有準確的說法,取決于編譯器內部實現)、不是遞歸、且頻繁調用的函數采用inline修飾,否則編譯器會忽略inline特性。
宏的優缺點?
優點:
1.增強代碼的復用性。
2.提高性能。
缺點:
1.不方便調試宏。(因為預編譯階段進行了替換)。
2.導致代碼可讀性差,可維護性差,容易誤用。
3.沒有類型安全的檢查 。
C++有哪些技術替代宏?
- 常量定義 換用const enum。
- 短小函數定義 換用內聯函數。
auto關鍵字
在早期C/C++中auto的含義是:使用auto修飾的變量,是具有自動存儲器的局部變量,但遺憾的是一直沒有人去使用它,大家可思考下為什么?
C++11中,標準委員會賦予了auto全新的含義即:auto不再是一個存儲類型指示符,而是作為一個新的類型指示符來指示編譯器,auto聲明的變量必須由編譯器在編譯時期推導而得。
注意:
使用auto定義變量時必須對其進行初始化,在編譯階段編譯器需要根據初始化表達式來推導auto的實際類型。因此auto并非是一種“類型”的聲明,而是一個類型聲明時的“占位符”,編譯器在編譯期會將auto替換為變量實際的類型。
int main()
{int a = 0;auto c = a;auto b = 'c';auto d = 1.34;return 0;
}
- auto與指針和引用結合起來使用
用auto聲明指針類型時,用auto和auto*沒有任何區別,但用auto聲明引用類型時則必須加&。
int main()
{int a = 0;auto pa = &a;auto& b = a;return 0;
}
- 在同一行定義多個變量
當在同一行聲明多個變量時,這些變量必須是相同的類型,否則編譯器將會報錯,因為編譯器實際只對第一個類型進行推導,然后用推導出來的類型定義其他變量。
void TestAuto()
{auto a = 1, b = 2;auto c = 3, d = 4.0; // 該行代碼會編譯失敗,因為c和d的初始化表達式類型不同
}
注意:
- auto不能作為函數的參數。
- auto不能直接用來聲明數組。
基于范圍的for循環
對于一個有范圍的集合而言,由程序員來說明循環的范圍是多余的,有時候還會容易犯錯誤。因此C++11中引入了基于范圍的for循環。for循環后的括號由冒號“ :”分為兩部分:第一部分是范圍內用于迭代的變量,第二部分則表示被迭代的范圍。
int main()
{int arr[] = { 1,2,3,4,5,6,7,8,9 };for (auto e : arr){cout << e << " " << endl;}return 0;
}
注意:
for循環迭代的范圍必須是確定的。
指針空值nullptr
在C++98中,字面常量0既可以是一個整形數字,也可以是無類型的指針(void*)常量,但是編譯器默認情況下將其看成是一個整形常量,如果要將其按照指針方式來使用,必須對其進行強轉(void*)0。所以C++又引入了nullptr作為指針空值。
注意:
- 在使用nullptr表示指針空值時,不需要包含頭文件,因為nullptr是C++11作為新關鍵字引入的。
- 在C++11中,sizeof(nullptr) 與 sizeof((void*)0)所占的字節數相同。
- 為了提高代碼的健壯性,在后續表示指針空值時建議最好使用nullptr。








》ISBN978-7-111-63687-8 第11章 11.1.3 樹的性質 節 第664頁的例9說明)



)





)
