
?
0 什么是伯特?
????????BERT是來自【Bidirectional Encoder Representations from Transformers】變壓器的雙向編碼器表示的縮寫,是用于自然語言處理的機器學習(ML)模型。它由Google AI Language的研究人員于2018年開發,可作為瑞士軍刀解決方案,用于11 +最常見的語言任務,例如情感分析和命名實體識別。
????????從歷史上看,語言對計算機來說很難“理解”。當然,計算機可以收集、存儲和讀取文本輸入,但它們缺乏基本的語言上下文。
????????因此,自然語言處理(NLP)隨之而來:人工智能領域,旨在讓計算機閱讀,分析,解釋并從文本和口語中獲取含義。這種做法結合了語言學、統計學和機器學習,以幫助計算機“理解”人類語言。
????????傳統上,單個NLP任務由為每個特定任務創建的單個模型來解決。也就是說,直到——伯特!
????????BERT通過解決11 +最常見的NLP任務(并且比以前的模型更好)徹底改變了NLP空間,使其成為所有NLP交易的杰克。在本指南中,您將了解BERT是什么,為什么它不同,以及如何開始使用BERT:
- 伯特的用途是什么?
- 伯特是如何工作的?
- BERT模型大小和架構
- BERT在公共語言任務上的表現
- 深度學習對環境的影響
- BERT的開源力量
- 如何開始使用伯特
- 伯特常見問題
- 結論
讓我們開始吧!🚀
1. 伯特的用途是什么?
BERT可用于各種語言任務:
- 可以確定電影評論的正面或負面程度。(情緒分析)
- Helps chatbots answer your questions.?(Question answering)
- Predicts your text when writing an email (Gmail).?(Text prediction)
- 只需幾句話就可以寫一篇關于任何主題的文章。(文本生成)
- 可以快速總結長期法律合同。(摘要)
- 可以根據周圍的文本區分具有多種含義的單詞(如“銀行”)。(多義性分辨率)
還有更多的語言/NLP任務+每個任務背后的更多細節。
有趣的事實:您幾乎每天都與NLP(可能還有BERT)互動!
NLP是谷歌翻譯,語音助手(Alexa,Siri等),聊天機器人,谷歌搜索,語音操作GPS等的背后。
1.1 BERT的例子
自 2020 年 <> 月以來,BERT 幫助 Google 更好地顯示幾乎所有搜索的(英語)結果。
以下是BERT如何幫助Google更好地了解特定搜索的示例,例如:
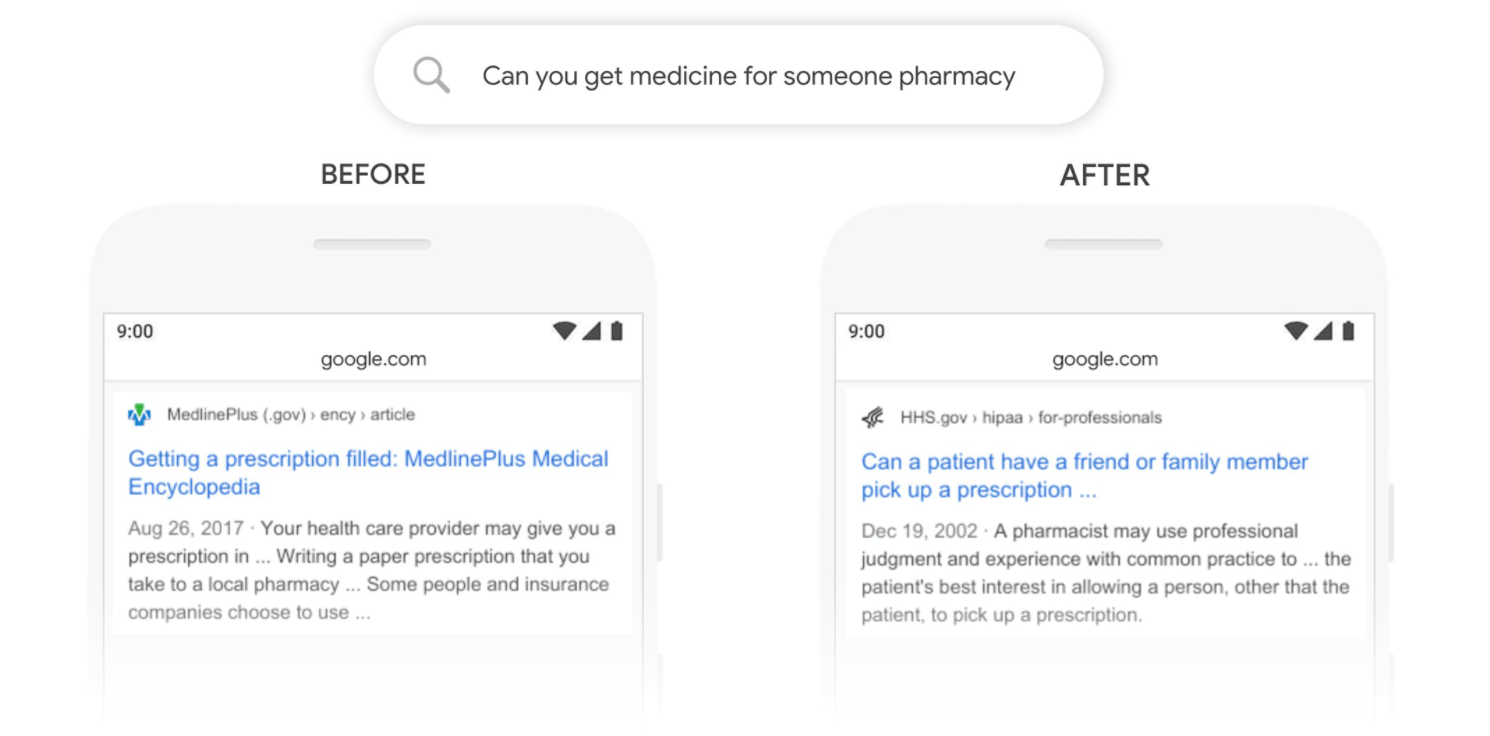
在BERT之前,谷歌浮出水面,提供有關填寫處方的信息。
后伯特谷歌明白“為某人”與為其他人開處方有關,搜索結果現在有助于回答這個問題。
2. 伯特如何工作?
BERT通過利用以下內容來工作:
2.1 大量的訓練數據
3億字的龐大數據集為BERT的持續成功做出了貢獻。
BERT在維基百科(~2.5B字)和谷歌的BooksCorpus(~800M字)上進行了專門訓練。這些大型信息數據集不僅有助于BERT對英語的深入了解,而且有助于深入了解我們的世界!🚀
在這么大的數據集上進行訓練需要很長時間。由于新穎的變壓器架構,BERT的培訓成為可能,并通過使用TPU(張量處理單元 - Google專門為大型ML模型構建的定制電路)來加速。—64 名 TPU 在 4 天內訓練了 BERT。
注意:為了在較小的計算環境(如手機和個人計算機)中使用BERT,對較小的BERT模型的需求正在增加。23 年 2020 月發布了 60 款較小的 BERT 車型。DistilBERT提供了BERT的較輕版本;運行速度提高 95%,同時保持 BERT 性能的 <>% 以上。
2.2 什么是屏蔽語言模型?
MLM通過屏蔽(隱藏)句子中的單詞并迫使BERT雙向使用覆蓋單詞兩側的單詞來預測被屏蔽的單詞,從而實現/強制從文本中進行雙向學習。這是以前從未做過的!
有趣的事實:作為人類,我們自然會這樣做!
屏蔽語言模型示例:
想象一下,你的朋友在冰川國家公園露營時打電話給你,他們的服務開始中斷。在呼叫斷開之前,您聽到的最后一件事是:
朋友:“叮!我出去釣魚了,一條巨大的鱒魚只是[空白]我的線!
你能猜出你朋友說了什么嗎?
您自然能夠通過將缺失單詞前后的單詞雙向視為上下文線索來預測缺失的單詞(除了您對釣魚工作原理的歷史知識)。你猜到你的朋友說,“破產”了嗎?這也是我們預測的,但即使是我們人類也容易出錯。
注意:這就是為什么您經常會看到“人類績效”與語言模型的性能分數進行比較的原因。是的,像BERT這樣的新模型可以比人類更準確!🤯
您為填寫上面的[空白]單詞所做的雙向方法類似于BERT獲得最先進準確性的方式。在訓練過程中隨機隱藏了15%的標記化單詞,BERT的工作是正確預測隱藏的單詞。因此,直接向模型教授有關英語(以及我們使用的單詞)的知識。這不是很整潔嗎?
玩弄BERT的掩蔽預測:
[MASK] 有趣的事實:掩蔽已經存在了很長時間 -?1953年關于完形填空程序(或“掩蔽”)的論文。
2.3 什么是下一句預測?
NSP(下一句預測)用于通過預測給定句子是否遵循前一個句子來幫助BERT了解句子之間的關系。
下一句預測示例:
- 保羅去購物了。他買了一件新襯衫。(正確的句子對)
- 雷蒙娜煮咖啡。香草冰淇淋蛋筒出售。(不正確的句子對)
在訓練中,50%的正確句子對與50%的隨機句子對混合在一起,以幫助BERT提高下一個句子預測的準確性。
有趣的事實:BERT同時接受傳銷(50%)和NSP(50%)的培訓。
2.4 變壓器
轉換器架構可以非常高效地并行化 ML 訓練。因此,大規模并行化使得在相對較短的時間內在大量數據上訓練BERT變得可行。
變形金剛使用注意力機制來觀察單詞之間的關系。最初在2017年流行的Attention Is All You Need論文中提出的一個概念引發了世界各地NLP模型中變形金剛的使用。
自 2017 年推出以來,變形金剛已迅速成為處理自然語言處理、語音識別和計算機視覺等許多領域任務的最先進方法。簡而言之,如果你正在做深度學習,那么你需要變形金剛!
Lewis Tunstall,Hugging Face ML工程師,《變形金剛自然語言處理》作者
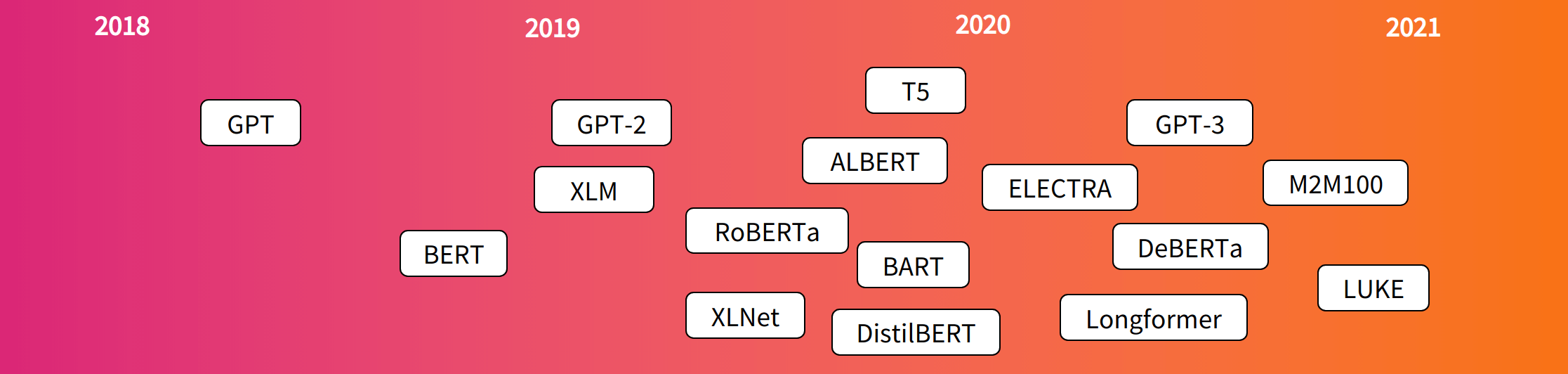
流行的變壓器模型發布時間表:
2.4.1 變壓器如何工作?
變形金剛通過利用注意力來工作,注意力是一種強大的深度學習算法,首次出現在計算機視覺模型中。
—與我們人類通過注意力處理信息的方式并沒有太大區別。我們非常善于忘記/忽略平凡的日常輸入,這些輸入不會構成威脅或需要我們做出回應。例如,你還記得上周二回家時看到和聽到的一切嗎?當然不是!我們大腦的記憶是有限而有價值的。我們的回憶得益于我們忘記瑣碎輸入的能力。
同樣,機器學習模型需要學習如何只關注重要的事情,而不是浪費計算資源來處理不相關的信息。變壓器產生差分權重,指示句子中的哪些單詞對進一步處理最關鍵。
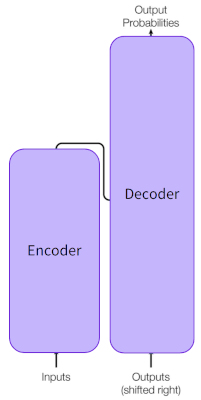
變壓器通過變壓器層堆棧(通常稱為編碼器)連續處理輸入來實現這一點。如有必要,可以使用另一個變壓器層堆棧 - 解碼器 - 來預測目標輸出。—但是,BERT不使用解碼器。變壓器特別適合無監督學習,因為它們可以有效地處理數百萬個數據點。
有趣的事實:自 2011 年以來,Google 一直在使用您的 reCAPTCHA 選擇來標記訓練數據。整個 Google 圖書檔案和《紐約時報》目錄中的 13 萬篇文章已通過輸入 reCAPTCHA 文本的人進行轉錄/數字化。現在,reCAPTCHA要求我們標記Google街景圖像,車輛,紅綠燈,飛機等。如果谷歌讓我們意識到我們參與了這項工作(因為訓練數據可能具有未來的商業意圖),那就太好了,但我跑題了。
要了解有關變形金剛的更多信息,請查看我們的擁抱面變壓器課程。
3. BERT模型大小和架構
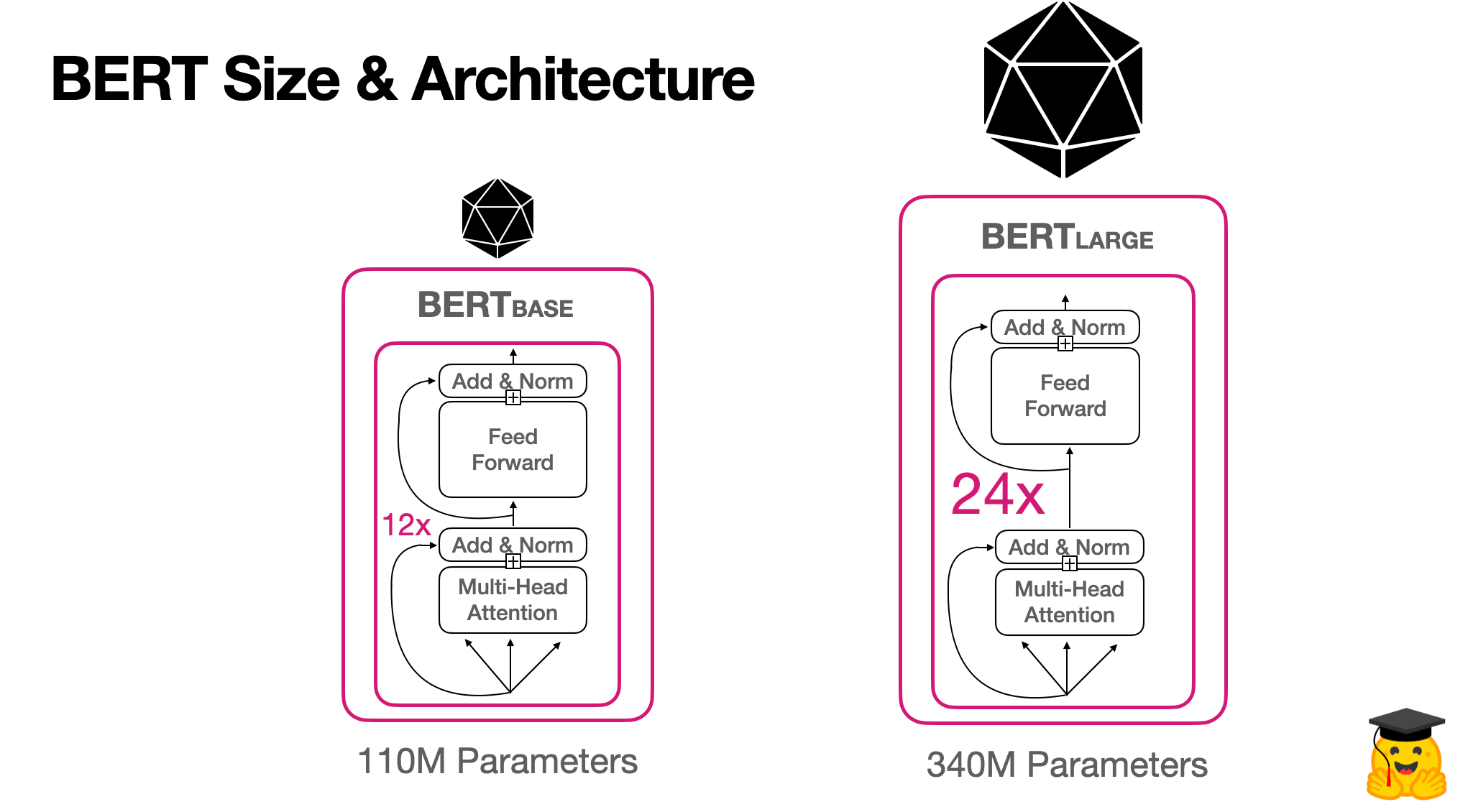
讓我們分解一下兩個原始BERT模型的架構:
ML 架構術語表:
| 機器學習架構部件 | 定義 |
|---|---|
| 參數: | 可用于模型的可學習變量/值的數量。 |
| 變壓器層: | 變壓器塊的數量。轉換器塊將一系列單詞表示轉換為一系列上下文化單詞(編號表示)。 |
| 隱藏大小: | 位于輸入和輸出之間的數學函數層,用于分配權重(單詞)以產生所需的結果。 |
| 注意頭: | 變壓器塊的大小。 |
| 加工: | 用于訓練模型的處理單元的類型。 |
| 培訓時間: | 訓練模型所花費的時間。 |
以下是BERTbase和BERTlarge擁有的上述ML架構部分的數量:
| 變壓器層 | 隱藏尺寸 | 注意頭 | 參數 | 加工 | 培訓時長 | |
|---|---|---|---|---|---|---|
| 伯特基地 | 12 | 768 | 12 | 110米 | 4 個熱塑性聚氨酯 | 4天 |
| 伯特大 | 24 | 1024 | 16 | 340米 | 16 個熱塑性聚氨酯 | 4天 |
讓我們來看看BERTlarge的附加層,注意頭和參數如何提高其在NLP任務中的性能。
4. BERT在公共語言任務上的表現
BERT 在 11 個常見的 NLP 任務上成功實現了最先進的準確性,優于以前的頂級 NLP 模型,并且是第一個超越人類的模型! 但是,如何衡量這些成就?
自然語言處理評估方法:
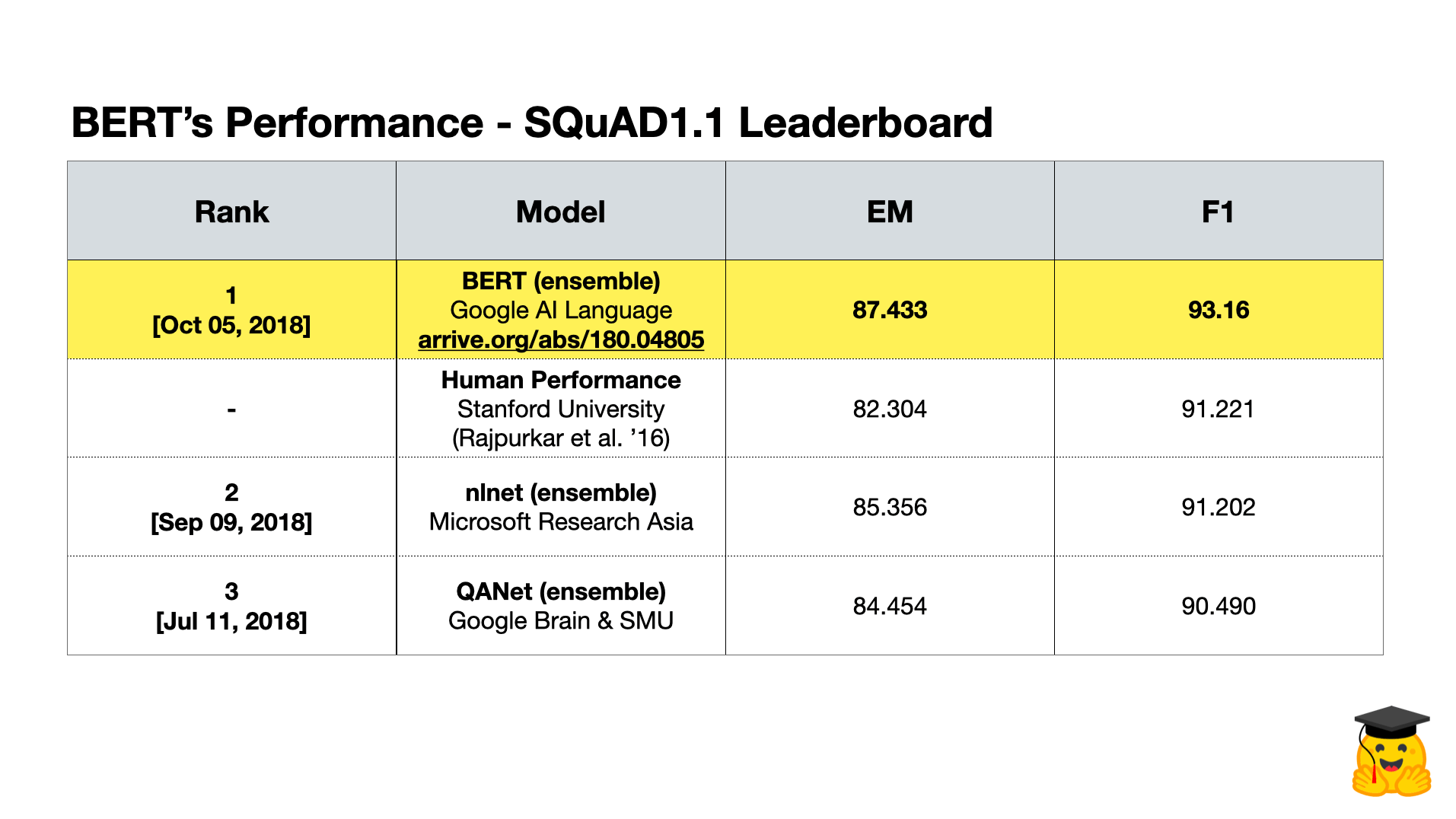
4.1 SQuAD v1.1 & v2.0
SQuAD(斯坦福問答數據集)是一個包含大約 108k 個問題的閱讀理解數據集,可以通過維基百科文本的相應段落回答。BERT在這種評估方法上的表現是超越以前最先進的模型和人類水平表現的巨大成就:
4.2 SWAG 評估法?
SWAG(Situations With Adversarial Generations)是一個有趣的評估,因為它檢測模型推斷常識的能力!它通過一個關于常識情況的 113k 多項選擇題的大規模數據集來做到這一點。這些問題是從視頻場景/情況中轉錄而來的,SWAG 在下一個場景中為模型提供了四種可能的結果。然后,該模型在預測正確答案方面做到最好。
BERT的表現優于以前的頂級模型,包括人類水平的表現:

4.3 格魯基準
GLUE(通用語言理解評估)基準是一組資源,用于訓練、測量和分析彼此比較的語言模型。這些資源由九個“困難”的任務組成,旨在測試NLP模型的理解。以下是其中每個任務的摘要:

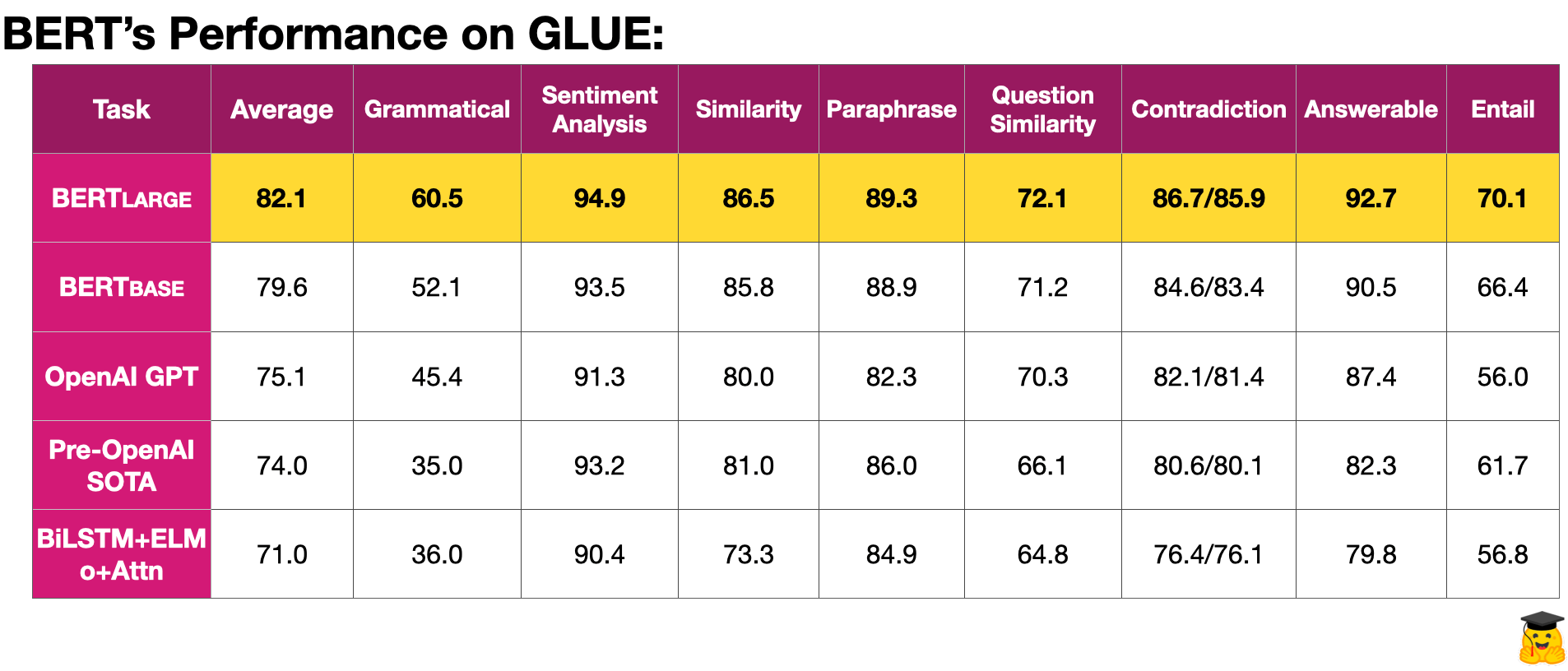
雖然其中一些任務可能看起來無關緊要和平庸,但重要的是要注意,這些評估方法在指示哪些模型最適合您的下一個 NLP 應用程序方面非常強大。
獲得這種機芯的性能并非沒有后果。接下來,讓我們了解機器學習對環境的影響。
5. 深度學習對環境的影響
大型機器學習模型需要大量數據,這在時間和計算資源方面都很昂貴。
這些模型還對環境有影響:
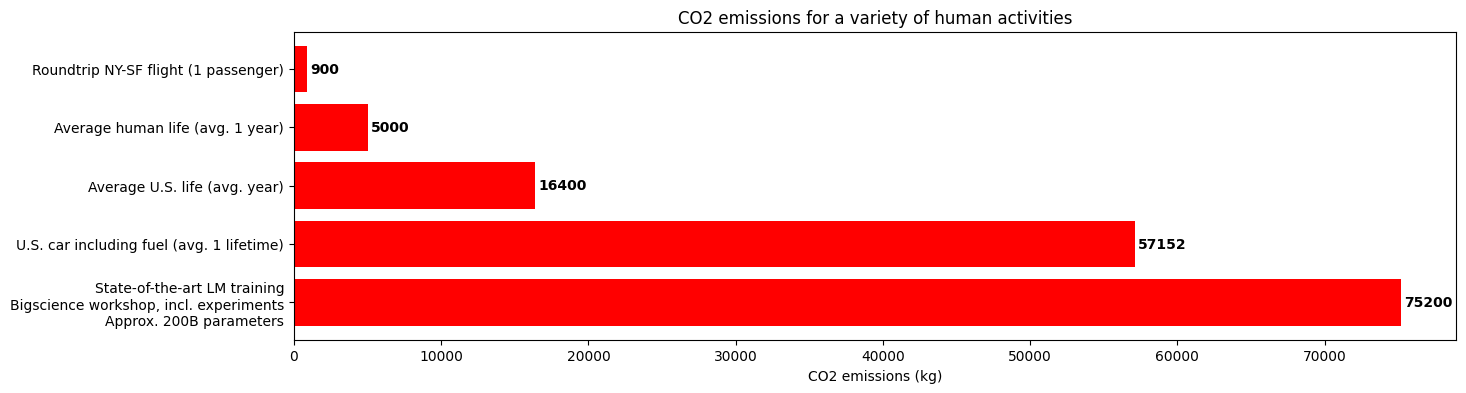
機器學習對環境的影響是我們相信通過開源使機器學習世界民主化的眾多原因之一!共享大型預訓練語言模型對于降低社區驅動工作的總體計算成本和碳足跡至關重要。
6. BERT的開源力量
與GPT-3等其他大型學習模型不同,BERT的源代碼是可公開訪問的(在Github上查看BERT的代碼),從而使BERT在世界各地得到更廣泛的使用。這是一個改變游戲規則的人!
開發人員現在能夠快速啟動并運行像BERT這樣的最先進的模型,而無需花費大量時間和金錢。🤯
相反,開發人員可以將精力集中在微調BERT上,以根據其獨特的任務自定義模型的性能。
重要的是要注意,如果您不想微調BERT,目前有數千個開源和免費的預訓練BERT模型可用于特定用例。
針對特定任務預先訓練的BERT模型:
- 推特情緒分析
- 日文文本分析
- 情緒分類器(英語 - 憤怒、恐懼、喜悅等)
- 臨床筆記分析
- 語音到文本翻譯
- 有害評論檢測
您還可以在擁抱面部集線器上找到數百個預先訓練的開源變壓器模型。
7. 如何開始使用伯特
我們創建了這個筆記本,所以你可以通過谷歌Colab中的這個簡單的教程來嘗試BERT。打開筆記本或將以下代碼添加到你自己的筆記本中。專業提示:使用 (Shift + 單擊) 運行代碼單元格。
注意:Hugging Face 的管道類使得只需一行代碼即可非常輕松地引入像轉換器這樣的開源 ML 模型。
7.1 安裝變壓器
首先,讓我們通過以下代碼安裝轉換器:
!pip install transformers
7.2 試用Bert
????????隨意將下面的句子換成您自己的句子。但是,將[MASK]留在某個地方,以便BERT預測丟失的單詞
from transformers import pipeline
unmasker = pipeline('fill-mask', model='bert-base-uncased')
unmasker("Artificial Intelligence [MASK] take over the world.")
????????當您運行上面的代碼時,您應該看到如下所示的輸出:
[{'score': 0.3182411789894104,'sequence': 'artificial intelligence can take over the world.','token': 2064,'token_str': 'can'},{'score': 0.18299679458141327,'sequence': 'artificial intelligence will take over the world.','token': 2097,'token_str': 'will'},{'score': 0.05600147321820259,'sequence': 'artificial intelligence to take over the world.','token': 2000,'token_str': 'to'},{'score': 0.04519503191113472,'sequence': 'artificial intelligences take over the world.','token': 2015,'token_str': '##s'},{'score': 0.045153118669986725,'sequence': 'artificial intelligence would take over the world.','token': 2052,'token_str': 'would'}]
有點嚇人吧?🙃
7.3 注意模型偏差
讓我們看看BERT為“男人”建議的工作:
unmasker("The man worked as a [MASK].")
運行上述代碼時,您應該看到如下所示的輸出:
[{'score': 0.09747546911239624,'sequence': 'the man worked as a carpenter.','token': 10533,'token_str': 'carpenter'},{'score': 0.052383411675691605,'sequence': 'the man worked as a waiter.','token': 15610,'token_str': 'waiter'},{'score': 0.04962698742747307,'sequence': 'the man worked as a barber.','token': 13362,'token_str': 'barber'},{'score': 0.037886083126068115,'sequence': 'the man worked as a mechanic.','token': 15893,'token_str': 'mechanic'},{'score': 0.037680838257074356,'sequence': 'the man worked as a salesman.','token': 18968,'token_str': 'salesman'}]
BERT預測該男子的工作是木匠,服務員,理發師,機械師或推銷員
現在讓我們看看伯特為“女人”提供哪些工作
unmasker("The woman worked as a [MASK].")
您應該會看到如下所示的輸出:
[{'score': 0.21981535851955414,'sequence': 'the woman worked as a nurse.','token': 6821,'token_str': 'nurse'},{'score': 0.1597413569688797,'sequence': 'the woman worked as a waitress.','token': 13877,'token_str': 'waitress'},{'score': 0.11547300964593887,'sequence': 'the woman worked as a maid.','token': 10850,'token_str': 'maid'},{'score': 0.03796879202127457,'sequence': 'the woman worked as a prostitute.','token': 19215,'token_str': 'prostitute'},{'score': 0.030423851683735847,'sequence': 'the woman worked as a cook.','token': 5660,'token_str': 'cook'}]
BERT預測,該女性的工作是護士,女服務員,女傭,或廚師,在專業角色中表現出明顯的性別偏見。
7.4 您可能喜歡的其他一些BERT筆記本:
BERT首次的可視化筆記本
訓練您的分詞器
+不要忘記查看擁抱面變壓器課程以了解更多信息 🎉
8. Bert常見問題
BERT可以與PyTorch一起使用嗎?
專業提示:Lewis Tunstall,Leandro von Werra和Thomas Wolf還寫了一本書,幫助人們使用Hugging Face構建語言應用程序,名為“使用變形金剛進行自然語言處理”。
BERT可以與Tensorflow一起使用嗎?
預訓練BERT需要多長時間?
微調BERT需要多長時間?
是什么讓伯特與眾不同?
- BERT以無監督的方式對大量未標記的數據(無人工注釋)進行了訓練。
- 然后,從之前的預訓練模型開始,對少量人工注釋的數據對BERT進行訓練,從而獲得最先進的性能。
9. 結論
????????BERT是一種高度復雜和先進的語言模型,可以幫助人們自動理解語言。它實現最先進性能的能力得到了大量數據培訓和利用變壓器架構徹底改變NLP領域的支持。
????????由于BERT的開源庫,以及令人難以置信的AI社區為繼續改進和共享新的BERT模型所做的努力,未觸及的NLP里程碑的未來看起來很光明。

)








)


——CentOS安裝Kibana)



)

——現有網絡模型的使用及修改)