Thread類
位于java.lang包下的Thread類是非常重要的線程類,它實現了Runnable接口,學習Thread類包括這些相關知識:線程的幾種狀態、上下文切換,Thread類中的方法的具體使用。
線程:比進程更小的執行單元,每個進程可能有多條線程,線程需要放在一個進程中才能執行,線程由程序負責管理,而進程則由系統進行調度!
多線程的理解:并行執行多個條指令,將CPU時間片按照調度算法分配給各個線程,實際上是分時執行的,只是這個切換的時間很短,用戶感覺到"同時"而已!
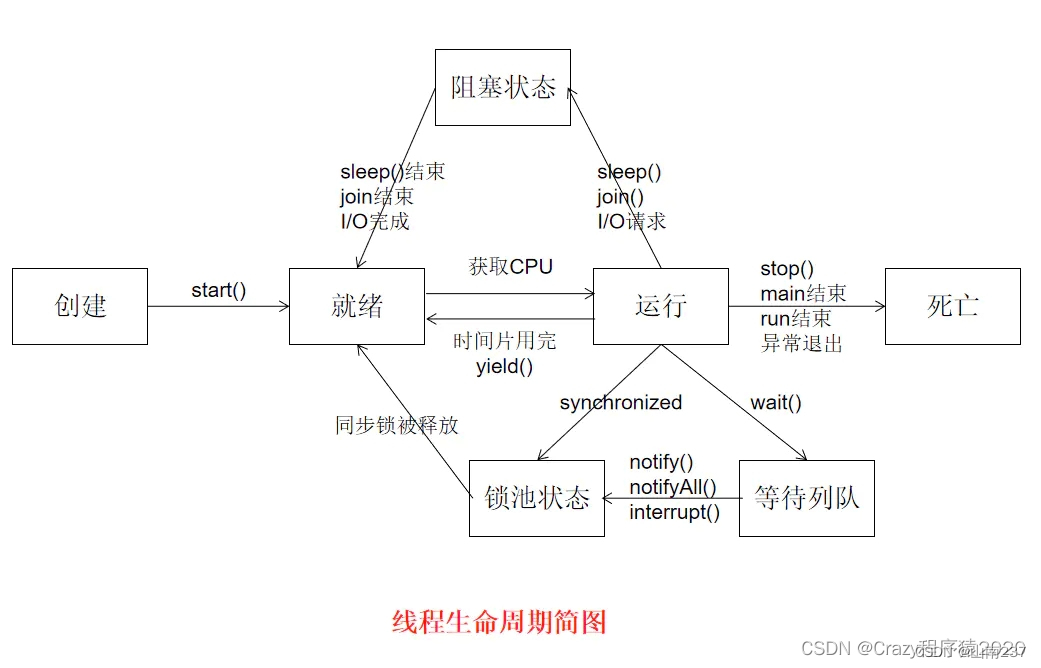
線程的狀態
線程從創建到最終的消亡,要經歷若干個狀態,一般來說包括以下幾個狀態:
- 創建(new)
- 就緒(runnable)
- 運行(running)
- 阻塞(blocked)、主動睡眠(time waiting)、等待喚醒(waiting)
- 消亡(dead)
當需要新起一個線程來執行某個子任務時,就創建了一個線程。但是線程創建之后,不會立即進入就緒狀態,因為線程的運行需要一些條件(比如內存資源,譬如程序計數器、Java棧、本地方法棧都是線程私有的,所以需要為線程分配一定的內存空間),只有線程運行需要的所有條件滿足了,才進入就緒狀態。
當線程進入就緒狀態后,不代表立刻就能獲取CPU執行時間,也許此時CPU正在執行其他的事情,因此它要等待。當得到CPU執行時間之后,線程便真正進入運行狀態。
線程在運行狀態過程中,可能有多個原因導致當前線程不繼續運行下去,比如用戶主動讓線程睡眠(睡眠一定的時間之后再重新執行)、用戶主動讓線程等待,或者被同步塊給阻塞,此時就對應著多個狀態:time waiting(睡眠或等待一定的事件)、waiting(等待被喚醒)、blocked(阻塞)。
當由于突然中斷或者子任務執行完畢,線程就會被消亡。
原文鏈接
創建線程的三種方式
- 通過繼承Thread類本身
class MyThread extends Thread {@Overridepublic void run() {. . .}
}//啟動線程
MyThread myThread = new MyThread ();
new MyThread().start();- 實現Runnalbe接口
實現Runnalbe接口,重載Runnalbe接口中的run()方法。然后可以分配該類的實例,在創建 Thread 時作為一個參數來傳遞并啟動。
class runnable implements Runnable {@Overridepublic void run() {. . .}
}//啟動線程
MyRunnable runnable = new MyRunnable();
new Thread(runnable).start();- 使用匿名方法類:
new Thread(new Runnable() {@Overridepublic void run() {try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}tvThreadResult.setText("線程執行結果");}
}).start();原文鏈接
上下文切換
對于單核CPU來說(對于多核CPU,此處就理解為一個核),CUP在某一個時刻只能運行一個線程,當在運行一個線程的過程中去運行另外一個線程,這個就叫做線程上下文切換。
由于可能當前的線程并沒有執行完,所以在切換時需要保存線程的運行狀態,以便下次線程切換回來的時候能夠以上次狀態去繼續運行,舉個簡單的列子,比如一個線程A正在讀取某個文件的內容,讀取到一半的時候,此時CPU需要切換線程去執行線程B,當再次切換回來執行A的時候,我們不希望線程A從頭開始讀取,因此需要記錄線程A的運行狀態,下次線程回復的時候,我們需要知道線程執行到第幾條指令了,搜易需要記錄程序計數器的值,另外比如說線程正在進行某個計算的時候被掛起了,那么下次繼續執行的時候需要知道之前掛起時變量的值時多少,因此需要記錄CPU寄存器的狀態。所以一般來說,線程上下文切換過程中會記錄程序計數器、CPU寄存器狀態等數據。
對于線程的上下文切換其實就是存儲和回復CPU狀態的過程,他使得線程能從斷點處恢復執行。
雖然多線程可以使得任務執行的效率得到提升,但是由于在線程切換時同樣會帶來一定的開銷代價,并且多個線程會導致系統資源占用的增加,所以在進行多線程編程時要注意這些因素。
Thread類中的方法
Thread類實現了Runnable接口,在Thread類中,有一些比較關鍵的屬性,比如name是表示Thread的名字,可以通過Thread類的構造器中的參數來指定線程名字,priority表示線程的優先級(最大值為10,最小值為1,默認值為5),daemon表示線程是否是守護線程,target表示要執行的任務。
下面是Thread類中常用的方法:
-
start()
start()用來啟動一個線程,當調用start()方法后,系統才會開啟一個新的線程來執行用戶定義的子任務,在這個過程中,會為相應的線程分配需要的資源。 -
run()
run()方法是不需要用戶來調用的,當通過start()方法啟動一個線程之后,當線程獲得了CPU執行時間,便進入run方法體去執行具體的任務。注意,繼承Thread類必須重寫run()方法,在run()方法中定義具體要執行的任務。 -
sleep()
sleep方法有兩個重載版本:
- sleep(long millis) //參數為毫秒
- sleep(long millis,int nanoseconds) //第一參數為毫秒,第二個參數為納秒
sleep方法相當于讓當前線程睡眠,交出CPU,讓CPU去執行其他的任務
當前線程調用sleep()方法進入阻塞狀態后,在其睡眠期間,該線程不會獲得執行機會,即是系統中沒有其他可執行線程,因此sleep方法常用來暫停程序執行。
但是有一點需要注意,sleep()方法不會釋放鎖,也就是說如果當前線程持有某個對象的鎖,調用sleep()方法,其他線程就無法訪問這個對象。
interrupt()
interrupt()方法解釋為中斷線程,實際是為了對線程做一個中斷標記,但是線程還是可能還是會執行,不立即,不強制,默認不終止。
interrput()方法是替換stop()方法,stop()方法已經棄用,為什么棄用呢?
是這樣,線程是一點一點執行,任何時間都有可能發生線程切換,任何時間都可以調用stop()方法,這個線程就會立即停止,可以產生非常隨機的中間狀態,比如在某個時間切到別的線程再也切不回來了,比如正在改某一個對象時線程停止了,會造成不可預估的影響。
所以我們要使用interrupt()方法,讓程序去判斷在什么時候中斷當前線程,這樣就能保證代碼的健壯性和程序的可控性。
既然interrupt()不能立即停止線程,那么怎么才能讓線程按照我們的要求停止呢?
這里我要介紹倆個方法:
- isInterrupted()
- Thread.interrupted()
用法:
//用于判斷當前線程是否為中斷狀態,不會重置狀態
if(isInterrupted()){//做一些收尾工作return ;
}//用于判斷當前線程是否為中斷狀態,先調用isInterrupted(boolean ClearInterrupted)方法,然后重置狀態,true變為false,false還是false
if(Thread.interrupted()){//做一些收尾工作return ;
}而且interrupt()可以打斷睡眠狀態,立即拋出異常。
//判斷是否中斷線程if(Thread.interrupted()){ //檢查當前的線程,//收尾工作}try {Thread.sleep(2000);} catch (InterruptedException e) {//收尾工作}yield()
yield()方法和sleep()方法有點相似,它也是Thread類提供的一個靜態方法,它也可以讓當前正在執行的線程暫停,但它不會阻塞該線程,它只是將該線程轉入到就緒狀態。即讓當前線程暫停一下,讓系統的線程調度器重新調度一次,完全可能的情況是:當某個線程調用了yield()方法暫停之后,線程調度器又將其調度出來重新執行。
調用yield方法會讓當前線程交出CPU權限,讓CPU去執行其他的線程。它跟sleep方法類似,同樣不會釋放鎖。但是yield不能控制具體的交出CPU的時間,另外,當某個線程調用了yield()方法之后,只有優先級與當前線程相同或者比當前線程更高的處于就緒狀態的線程才會獲得執行機會。
注意,調用yield方法并不會讓線程進入阻塞狀態,而是讓線程重回就緒狀態,它只需要等待重新獲取CPU執行時間,這一點是和sleep方法不一樣的。
join()
join方法有三個重載版本:
- join()
- join(long millis) //參數為毫秒
- join(long millis,int nanoseconds) //第一參數為毫秒,第二參數為納秒
假如在main線程中,調用thread.join()方法,則main()方法會等待thread線程執行完畢或者等待一定的時間。如果調用的是無參join()方法,則等待thread執行完畢,如果調用的是指定了時間參數的join方法,則等待一定的事件。
代碼示例:
public class ThreadDemo {private int i = 0 ;public static void main(String[] args) {ThreadDemo threadDemo = new ThreadDemo() ;System.out.println("進入線程"+Thread.currentThread().getName());MyThread thread1 = threadDemo.new MyThread() ;thread1.start();System.out.println("線程等待"+Thread.currentThread().getName());try {thread1.join();} catch (InterruptedException e) {e.printStackTrace();}System.out.println("線程繼續執行"+Thread.currentThread().getName());}class MyThread extends Thread{@Overridepublic void run() {synchronized (ThreadDemo.class){i ++ ;System.out.println("線程:" + Thread.currentThread().getName() + " i = " + i);try {Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("線程:" + Thread.currentThread().getName() + "--睡醒 ");}}}}獲取線程屬性的幾個方法
- getId() 得到線程的ID
- getName和setName 用來得到或者設置線程名稱。
- getPriority和setPriority 用來獲取和設置線程優先級。
- setDaemon和isDaemon 用來設置線程是否成為守護線程和判斷線程是否是守護線程。
- 守護線程和用戶線程的區別在于:守護線程依賴于創建它的線程,而用戶線程不依賴,舉個簡單的例子,如果在main()線程中創建一個守護線程,當main()方法執行結束之后,守護線程也會隨之消亡。而用戶線程不會,用戶線程會一直運行直到運行完畢,在JVM中,像垃圾收集器線程就是守護線程。
- currentThread() 用來獲取當前的線程
8.wait()、notify()、notifyAll()
wait()、notify()、notifyAll()這三個方法不是Thread類中的方法,是Object本地的final方法,但是多線程中也是不可或缺的。
wait()、notify()、notifyAll()和synchronized是配合使用的。
wait()在synchronized中在對應monitor維護等待隊列,會把當前的鎖讓開,其他線程也可以訪問同一個synchronized里面的代碼。
notify()會喚醒同一個monitor的wait(),讓monitor去喚醒,notify()喚醒wait()不確定是哪一個,所以一般不適用notify()這個方法。
notifyAll() 是喚醒同一個moitor所有的wait(),被喚醒后,需要到monitor的執行隊列中等待,等待拿鎖,拿鎖后從wait()位置繼續執行。



)


——CentOS安裝Kibana)



)

——現有網絡模型的使用及修改)



; 及 $grid->column(‘image‘);)
)

