本系列博文為深度學習/計算機視覺論文筆記,轉載請注明出處
標題:Image-to-Image Translation with Conditional Adversarial Networks
鏈接:Image-to-Image Translation with Conditional Adversarial Networks | IEEE Conference Publication | IEEE Xplore
摘要
我們研究了將條件對抗網絡作為通用解決方案,用于圖像到圖像的轉換問題。這些網絡不僅學習從輸入圖像到輸出圖像的映射,還學習了一個損失函數來訓練這種映射。這使得可以將相同的通用方法應用于傳統上需要非常不同損失公式的問題。我們證明了這種方法在從標簽映射合成照片、從邊緣映射重建物體和給圖像上色等任務中是有效的。此外,自從與本論文相關聯的pix2pix軟件發布以來,已經有數百名Twitter用戶發布了使用我們的系統進行藝術實驗的作品。作為一個社區,我們不再手工設計映射函數,這項工作表明我們可以在不手工設計損失函數的情況下獲得合理的結果。
1. 引言
在圖像處理、計算機圖形學和計算機視覺中,許多問題可以被看作是將輸入圖像“翻譯”為相應的輸出圖像。就像一個概念可以用英語或法語表達一樣,一個場景可以被渲染成RGB圖像、梯度場、邊緣映射、語義標簽映射等等。類比于自動語言翻譯,我們將自動圖像到圖像轉換定義為在足夠的訓練數據下,將一個場景的一種可能表示轉換為另一種表示的問題(見圖1)。傳統上,每個任務都使用獨立的、專用的機制來解決(例如,[14、23、18、8、10、50、30、36、16、55、58]),盡管事實上背景始終是相同的:從像素預測像素。本文的目標是為所有這些問題開發一個共同的框架。
圖1:圖像處理、圖形學和視覺領域中的許多問題涉及將輸入圖像轉換為相應的輸出圖像。這些問題通常會使用特定于應用的算法來處理,盡管背景始終相同:將像素映射到像素。條件對抗網絡是一種通用解決方案,似乎在各種各樣的這些問題上表現良好。在這里,我們展示了該方法在幾個問題上的結果。在每種情況下,我們使用相同的架構和目標,只是在不同的數據上進行訓練。
社區已經朝著這個方向邁出了重要的一步,卷積神經網絡(CNNs)已成為各種圖像預測問題的通用工具。CNNs學習最小化損失函數——評估結果質量的目標——雖然學習過程是自動的,但仍需要大量的人工工作來設計有效的損失。換句話說,我們仍然必須告訴CNN我們希望它最小化什么。但是,就像金色國王米達斯一樣,我們必須小心我們的愿望!如果我們采取幼稚的方法,要求CNN最小化預測像素與實際像素之間的歐氏距離,它往往會產生模糊的結果[40、58]。這是因為歐氏距離通過對所有可能的輸出求平均來最小化,從而導致模糊。提出能夠強制CNN執行我們真正想要的任務的損失函數——例如,輸出清晰、逼真的圖像——是一個開放的問題,通常需要專業知識。
如果我們能夠只指定一個高層次的目標,比如“使輸出與現實不可區分”,然后自動學習適合滿足這個目標的損失函數,那將是非常理想的。幸運的是,這正是最近提出的生成對抗網絡(GANs)所做的[22、12、41、49、59]。GANs學習一個損失,試圖分類輸出圖像是真實還是偽造的,同時訓練一個生成模型來最小化這個損失。模糊的圖像將不會被容忍,因為它們看起來顯然是偽造的。因為GANs學習適應數據的損失,所以它們可以應用于許多傳統上需要非常不同類型的損失函數的任務。
在本文中,我們在條件設置下探討了GANs。正如GANs學習數據的生成模型一樣,條件生成對抗網絡(cGANs)學習了一個條件生成模型[22]。這使得cGANs適用于圖像到圖像的轉換任務,我們在輸入圖像的條件下生成相應的輸出圖像。
雖然在過去的兩年里已經對GANs進行了廣泛的研究,并且本文中探討的許多技術之前已經被提出過,但是早期的論文集中在特定的應用上,圖像條件GANs是否可以作為圖像到圖像轉換的通用解決方案仍然不清楚。我們的主要貢獻是證明,在各種各樣的問題上,條件GANs能夠產生合理的結果。我們的第二個貢獻是提出一個簡單的框架,足以實現良好的結果,并分析了幾個重要的架構選擇的影響。代碼可在https://github.com/phillipi/pix2pix上獲得。
2. 相關工作
結構化損失用于圖像建模 圖像到圖像轉換問題通常被制定為像素級的分類或回歸問題(例如,[36、55、25、32、58])。這些制定將輸出空間視為“非結構化”,意味著每個輸出像素在給定輸入圖像的情況下被認為是條件獨立的。相反,條件生成對抗網絡學習的是結構化損失。結構化損失懲罰輸出的聯合配置。大量文獻考慮了這種類型的損失,其中的方法包括條件隨機場[9]、SSIM指標[53]、特征匹配[13]、非參數損失[34]、卷積偽先驗[54],以及基于匹配協方差統計的損失[27]。條件生成對抗網絡的不同之處在于學習了損失,理論上可以懲罰輸出和目標之間的任何可能不同的結構。
條件生成對抗網絡 我們不是第一個將GANs應用于條件設置的人。之前的研究已經將GANs置于離散標簽[38、21、12]、文本[43],以及實際上圖像等條件之下。圖像條件模型已經處理了從法線貼圖[52]預測圖像、未來幀預測[37]、產品照片生成[56],以及從稀疏注釋生成圖像[28、45]的圖像預測問題(參見[44]以獲得同一問題的自回歸方法)。還有其他一些論文也使用GANs進行圖像到圖像的映射,但只是無條件地應用GANs,依賴其他術語(如L2回歸)來強制輸出對輸入進行條件約束。這些論文在修復[40]、未來狀態預測[60]、受用戶約束引導的圖像處理[61]、風格轉移[35]和超分辨率[33]方面取得了令人印象深刻的結果。每種方法都是針對特定應用進行了調整。我們的框架的不同之處在于沒有任何特定于應用的內容。這使得我們的設置比大多數其他方法要簡單得多。
我們的方法在生成器和鑒別器的幾個架構選擇方面也與之前的工作不同。與以往的工作不同,對于生成器,我們使用了基于“U-Net”的架構[47],對于鑒別器,我們使用了卷積“PatchGAN”分類器,該分類器只對圖像塊尺度上的結構進行懲罰。類似的PatchGAN架構之前在[35]中提出,用于捕捉局部風格統計。在這里,我們展示了這種方法在更廣泛的問題上的有效性,并且我們研究了更改圖像塊尺寸的影響。
3. 方法
GANs是生成模型,它們學習從隨機噪聲向量 z z z到輸出圖像 y y y的映射, G : z → y G : z → y G:z→y [22]。相比之下,條件生成對抗網絡學習從觀察到的圖像 x x x和隨機噪聲向量 z z z到 y y y的映射, G : { x , z } → y G : \{x, z\} → y G:{x,z}→y。
生成器 G G G的訓練目標是生成的輸出無法被經過對抗訓練的鑒別器 D D D與“真實”圖像區分開來,鑒別器 D D D的訓練目標是盡可能地檢測生成器的“偽造”圖像。這個訓練過程在圖2中有所說明。
圖2:訓練條件生成對抗網絡從邊緣映射→照片的映射。鑒別器 D D D學習將偽造的(由生成器合成的)和真實的{邊緣映射,照片}元組進行分類。生成器 G G G學習欺騙鑒別器。與無條件的GAN不同,生成器和鑒別器都觀察輸入的邊緣映射。

3.1. 目標函數
條件生成對抗網絡的目標函數可以表示為
L c G A N ( G , D ) = E x , y [ log ? D ( x , y ) ] + E x , z [ log ? ( 1 ? D ( x , G ( x , z ) ) ) ] (1) L_{cGAN}(G, D) = E_{x,y}[\log D(x, y)] + E_{x,z}[\log(1 - D(x, G(x, z)))] \tag{1} LcGAN?(G,D)=Ex,y?[logD(x,y)]+Ex,z?[log(1?D(x,G(x,z)))](1)
其中生成器 G G G試圖最小化這個目標函數,對抗性的鑒別器 D D D試圖最大化它,即 G ? = arg ? min ? G max ? D L c G A N ( G , D ) G^* = \arg\min_G \max_D L_{cGAN}(G, D) G?=argminG?maxD?LcGAN?(G,D)。
為了測試條件鑒別器的重要性,我們還將其與不含條件的變種進行比較,其中鑒別器不觀察 x x x:
L G A N ( G , D ) = E y [ log ? D ( y ) ] + E x , z [ log ? ( 1 ? D ( G ( x , z ) ) ) ] (2) L_{GAN}(G, D) = E_{y}[\log D(y)] + E_{x,z}[\log(1 - D(G(x, z)))] \tag{2} LGAN?(G,D)=Ey?[logD(y)]+Ex,z?[log(1?D(G(x,z)))](2)
先前的方法發現將GAN目標與更傳統的損失(如L2距離)混合是有益的[40]。鑒別器的任務保持不變,但生成器不僅要欺騙鑒別器,還要在L2意義上接近地面實際輸出。我們也探索了這個選項,使用L1距離代替L2,因為L1鼓勵更少的模糊:
L L 1 ( G ) = E x , y , z [ ∥ y ? G ( x , z ) ∥ 1 ] (3) L_{L1}(G) = E_{x,y,z}[\|y - G(x, z)\|_1] \tag{3} LL1?(G)=Ex,y,z?[∥y?G(x,z)∥1?](3)
我們的最終目標是
G ? = arg ? min ? G max ? D ( L c G A N ( G , D ) + λ L L 1 ( G ) ) (4) G^* = \arg\min_G \max_D (L_{cGAN}(G, D) + \lambda L_{L1}(G)) \tag{4} G?=argGmin?Dmax?(LcGAN?(G,D)+λLL1?(G))(4)
在沒有 z z z的情況下,網絡仍然可以從 x x x到 y y y學習映射,但會產生確定性輸出,因此無法匹配除了Delta函數以外的任何分布。過去的條件GAN已經承認了這一點,并且在生成器的輸入中提供了高斯噪聲 z z z,除了 x x x之外(例如,[52])。在初始實驗中,我們發現這種策略并不有效 - 生成器只是學會忽略噪聲 - 這與Mathieu等人的研究一致[37]。相反,對于我們的最終模型,我們只在生成器的幾層上以Dropout的形式提供噪聲,這在訓練和測試時都會應用。盡管有Dropout的噪聲,我們觀察到網絡的輸出只有微小的隨機性。設計能夠產生高度隨機輸出的條件GAN,并因此捕捉所建模條件分布的全部熵,是目前工作中未解決的重要問題。
3.2. 網絡架構
我們從[41]中的生成器和鑒別器架構進行了調整。生成器和鑒別器都使用了形式為卷積-BatchNorm-ReLU [26]的模塊。有關架構的詳細信息可在補充材料中找到,在下面討論了關鍵特征。
3.2.1 具有跳躍連接的生成器
圖像到圖像轉換問題的一個顯著特征是它們將高分辨率輸入網格映射到高分辨率輸出網格。此外,對于我們考慮的問題,輸入和輸出在表面外觀上有所不同,但都是相同基礎結構的渲染。因此,輸入中的結構與輸出中的結構大致對齊。我們圍繞這些考慮設計了生成器架構。
許多先前的解決方案[40、52、27、60、56]針對這個領域的問題使用了編碼器-解碼器網絡[24]。在這樣的網絡中,輸入經過一系列逐漸下采樣的層,直到瓶頸層,此時過程被反轉。這樣的網絡要求所有信息流都通過所有層,包括瓶頸。對于許多圖像轉換問題,輸入和輸出之間共享了大量的低級信息,可以將這些信息直接傳遞到網絡中是可取的。例如,在圖像著色的情況下,輸入和輸出共享突出邊緣的位置。
為了使生成器能夠繞過瓶頸,以傳遞類似信息,我們添加了跳躍連接,遵循“U-Net” [47]的一般形狀。具體來說,我們在每個層 i i i和層 n ? i n - i n?i之間添加跳躍連接,其中 n n n是總層數。每個跳躍連接簡單地將層 i i i和層 n ? i n - i n?i中的所有通道連接起來。
3.2.2 馬爾可夫鑒別器(PatchGAN)
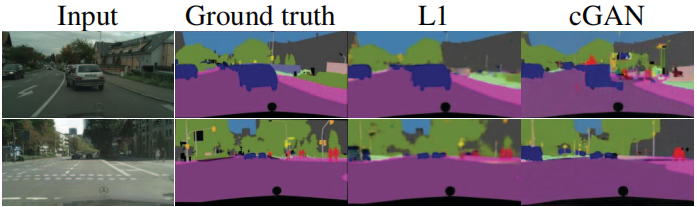
眾所周知,L2損失 - 和L1,參見圖3 - 在圖像生成問題上會產生模糊的結果[31]。盡管這些損失不能鼓勵高頻清晰度,在許多情況下,它們仍然準確捕捉了低頻信息。對于這種情況,我們不需要一個全新的框架來在低頻上強制正確性。L1已經足夠。
圖3:不同損失引發不同質量的結果。 每一列顯示在不同損失下訓練的結果。更多示例請參見 https://phillipi.github.io/pix2pix/ 。

這激發了將GAN鑒別器限制為僅模擬高頻結構,依靠L1項來強制低頻正確性(方程4)。為了模擬高頻,將注意力限制在局部圖像塊的結構上就足夠了。因此,我們設計了一個鑒別器架構 - 我們稱之為PatchGAN - 它僅對圖像塊尺度上的結構進行懲罰。該鑒別器試圖對圖像中的每個 N × N N × N N×N塊進行分類,判斷其是否為真實的或偽造的。我們通過卷積在整個圖像上運行此鑒別器,平均所有響應以提供 D D D的最終輸出。
在第4.4節中,我們證明 N N N可以遠小于圖像的完整尺寸,仍然能夠產生高質量的結果。這是有利的,因為較小的PatchGAN具有較少的參數,運行速度更快,可以應用于任意大的圖像。
這樣的鑒別器有效地將圖像建模為馬爾可夫隨機場,假設在大于一個圖像塊直徑的像素之間是獨立的。這個聯系之前在[35]中探討過,也是紋理[15、19]和風格[14、23、20、34]模型中的常見假設。因此,我們的PatchGAN可以被理解為紋理/風格損失的一種形式。
3.3. 優化與推理
為了優化我們的網絡,我們遵循了[22]中的標準方法:在D上進行一次梯度下降步驟,然后在G上進行一步。我們使用小批量隨機梯度下降(SGD),并應用Adam求解器[29]。
在推理時,我們以與訓練階段完全相同的方式運行生成器網絡。這與通常的協議不同,我們在測試時應用了Dropout,并且我們使用測試批次的統計數據,而不是訓練批次的聚合統計數據來應用批歸一化[26]。當批量大小設置為1時,這種批歸一化的方法被稱為“實例歸一化”,并且已被證明在圖像生成任務上是有效的[51]。在我們的實驗中,根據實驗,我們使用了批量大小在1到10之間。
4. 實驗
為了探索條件生成對抗網絡的普適性,我們在各種任務和數據集上測試了該方法,包括圖形任務(如照片生成)和視覺任務(如語義分割):
- 語義標簽?照片,訓練于Cityscapes數據集[11]。
- 建筑標簽→照片,訓練于CMP Facades [42]。
- 地圖?航拍照片,使用從Google地圖獲取的數據進行訓練。
- 黑白照片→彩色照片,使用[48]進行訓練。
- 邊緣→照片,使用來自[61]和[57]的數據進行訓練;使用HED邊緣檢測器[55]生成的二值邊緣以及后處理。
- 素描→照片:在[17]的人工繪制的素描上測試邊緣→照片模型。
- 白天→夜晚,訓練于[30]的數據。
有關這些數據集的詳細訓練細節可以在在線的補充材料中找到。在所有情況下,輸入和輸出都是1-3通道圖像。定性結果在圖7、圖8、圖9、圖10和圖11中展示,其他結果和失敗案例可以在在線材料中找到(https://phillipi.github.io/pix2pix/)。
4.1. 評估指標
評估合成圖像的質量是一個開放且困難的問題[49]。傳統的指標,如像素級均方誤差,不評估結果的聯合統計信息,因此無法衡量結構化損失旨在捕捉的結構。
為了更全面地評估我們結果的視覺質量,我們采用了兩種策略。首先,我們在Amazon Mechanical Turk(AMT)上進行了“真實與偽造”感知研究。對于顏色化和照片生成等圖形問題,對于人類觀察者來說,可信度通常是最終目標。因此,我們使用這種方法測試了我們的地圖生成、航拍照片生成和圖像著色。
其次,我們衡量我們合成的城市景觀是否足夠逼真,以至于現成的識別系統能夠識別其中的對象。這個指標類似于[49]中的“Inception分數”,[52]中的目標檢測評估,以及[58]和[39]中的“語義可解釋性”度量。
AMT感知研究 對于我們的AMT實驗,我們遵循了[58]中的協議:Turkers被呈現了一系列試驗,其中一個“真實”圖像與由我們的算法生成的“偽造”圖像相對比。在每個試驗中,每個圖像出現1秒鐘,之后圖像消失,Turkers被給予無限時間來回答哪個是偽造的。每個會話的前10張圖像是練習,并且Turkers會得到反饋。在主要實驗的40次試驗中沒有提供反饋。每次會話一次只測試一個算法,Turkers不允許完成多個會話。大約有50名Turkers對每個算法進行評估。所有圖像都以256×256的分辨率呈現。與[58]不同的是,我們沒有包括警覺性試驗。對于我們的著色實驗,真實和偽造的圖像都是從相同的灰度輸入生成的。對于地圖?航拍照片,真實和偽造的圖像不是從相同的輸入生成的,以使任務更加困難,避免底層結果。
FCN分數 盡管量化評估生成模型的挑戰性是眾所周知的,但最近的作品[49、52、58、39]嘗試使用預訓練的語義分類器作為偽指標來測量生成的刺激的可辨別性。直覺是,如果生成的圖像逼真,那么在真實圖像上訓練的分類器也能夠正確地對合成圖像進行分類。為此,我們采用了FCN-8s [36]架構進行語義分割,并在cityscapes數據集上對其進行了訓練。然后,我們通過對這些照片的分類準確率對比這些照片生成的標簽,對合成的照片進行評分。
4.2. 目標函數分析
在方程(4)的目標中,哪些組件是重要的?我們進行消融研究以分離L1項、GAN項的影響,同時比較使用條件化鑒別器(cGAN,方程(1))與使用無條件鑒別器(GAN,方程(2))。
圖3展示了這些變化對兩個標簽→照片問題的定性影響。僅使用L1會導致合理但模糊的結果。僅使用cGAN(在方程(4)中設置λ = 0)會產生更銳利的結果,但會在某些應用中引入視覺偽影。將兩個術語結合在一起(λ = 100)可以減少這些偽影。
我們使用城市景觀標簽→照片任務上的FCN分數來量化這些觀察結果(見表1):基于GAN的目標實現了更高的分數,表明合成圖像包括更多可識別的結構。我們還測試了從鑒別器中移除條件的效果(標記為GAN)。在這種情況下,損失不會懲罰輸入和輸出之間的不匹配;它只關心輸出看起來是否真實。這個變體的性能非常差;檢查結果發現生成器幾乎產生了幾乎相同的輸出,而不管輸入照片。顯然,在這種情況下,損失測量輸入和輸出之間的匹配質量非常重要,事實上cGAN比GAN表現得更好。然而,需要注意的是,添加L1項也鼓勵輸出尊重輸入,因為L1損失懲罰了地面真實輸出與合成輸出之間的距離,這些合成輸出可能不匹配。相應地,L1+GAN也能夠有效地創建尊重輸入標簽映射的真實渲染。將所有術語組合在一起,L1+cGAN的表現也很好。
表1:在Cityscapes數據集上對語義標簽?照片任務進行評估的FCN分數

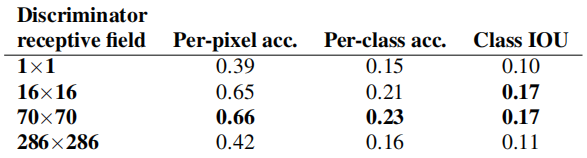
色彩鮮艷性 條件生成對抗網絡引人注目的效果是它們產生銳利的圖像,甚至在輸入標簽映射中不存在空間結構的情況下也產生空間結構的幻覺。人們可能會想象cGAN對光譜維度的“銳化”具有類似的效果 - 即使圖像更豐富多彩。就像當不確定邊緣的確切位置時,L1會鼓勵模糊一樣,它也會在不確定像素應該采用哪個可行的顏色值時,鼓勵選擇平均的灰色。特別地,選擇使L1最小化可能顏色的條件概率密度函數的中值。
另一方面,對抗性損失原則上可以意識到灰色輸出是不現實的,并鼓勵匹配真實的顏色分布[22]。在圖6中,我們調查了我們的cGAN在Cityscapes數據集上是否實現了這種效果。這些圖顯示了Lab顏色空間中輸出顏色值的邊際分布。虛線表示地面真實分布。顯然,L1會導致比地面真實分布更窄的分布,驗證了L1鼓勵平均灰色顏色的假設。另一方面,使用cGAN會將輸出分布推向地面真實分布。
4.3. 生成器架構分析
U-Net架構允許低級信息在網絡中進行快速傳遞。這是否會導致更好的結果?圖4比較了U-Net和編碼器-解碼器在城市景觀生成方面的表現。編碼器-解碼器僅通過切斷U-Net中的跳躍連接來創建。在我們的實驗中,編碼器-解碼器無法學習生成真實圖像。U-Net的優勢似乎不局限于條件性GAN:當U-Net和編碼器-解碼器都使用L1損失進行訓練時,U-Net再次取得了優越的結果(見圖4)。
圖4:在編碼器-解碼器中添加跳過連接以創建“U-Net”會產生更高質量的結果。

4.4. 從PixelGAN到PatchGAN到ImageGAN
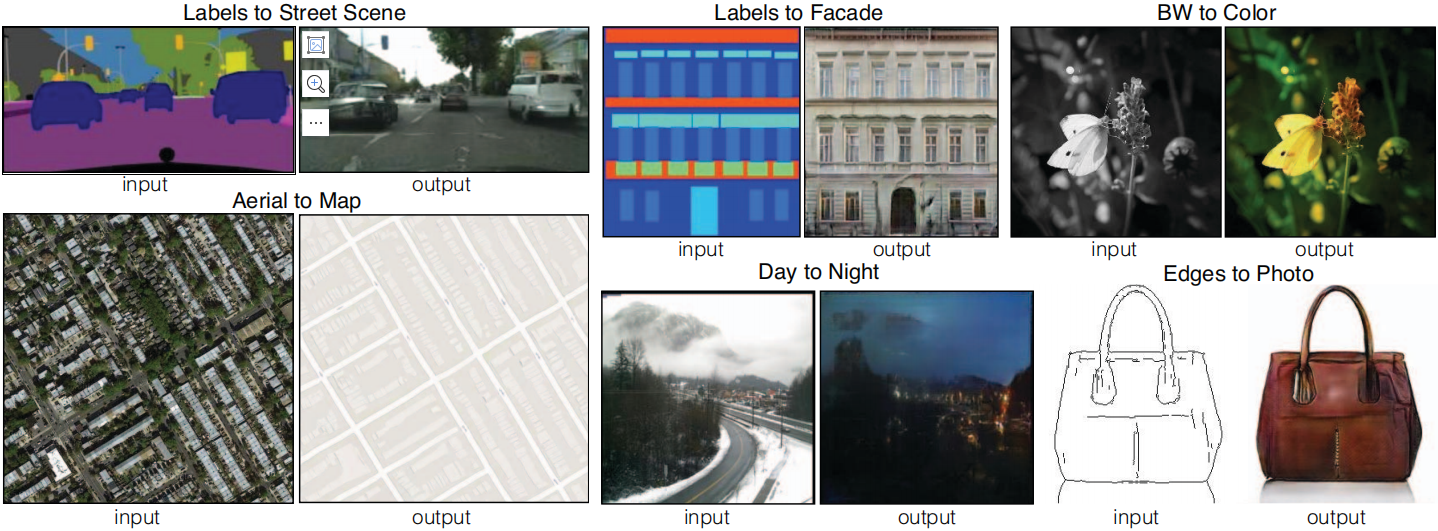
我們測試了變化的鑒別器感受野的補丁大小N的效果,從1 × 1的“PixelGAN”到完整的286 × 286的“ImageGAN”1。圖5顯示了此分析的定性結果,表2定量了使用FCN分數的效果。請注意,在本文的其他部分,除非另有說明,所有實驗都使用70 × 70的PatchGAN,而在本節中,所有實驗都使用L1+cGAN損失。
圖5:補丁大小變化。不同的損失函數會以不同的方式表現出輸出的不確定性。在L1下,不確定的區域變得模糊且不飽和。1x1的PixelGAN鼓勵更大的顏色多樣性,但對空間統計沒有影響。16x16的PatchGAN會產生局部銳利的結果,但也會在其能觀察到的范圍之外產生平鋪偽影。70×70的PatchGAN會在空間和光譜(色彩豐富度)維度上強制產生銳利的輸出,即使是不正確的。完整的286×286的ImageGAN在視覺上與70×70的PatchGAN的結果相似,但根據我們的FCN-score指標(表2)略低一些。請參閱 https://phillipi.github.io/pix2pix/ 獲取其他示例。

表2:在Cityscapes標簽→照片任務上,不同判別器感受野大小的FCN分數。請注意,輸入圖像為256×256像素,較大的感受野大小通過填充零來實現。
PixelGAN對空間清晰度沒有影響,但確實增加了結果的色彩豐富性(在圖6中定量)。例如,圖5中的公共汽車在使用L1損失進行訓練時被涂成灰色,但在使用PixelGAN損失時變成了紅色。顏色直方圖匹配是圖像處理中的常見問題[46],而PixelGAN可能是一個有前景的輕量級解決方案。
圖6:cGAN的顏色分布匹配特性,在Cityscapes數據集上進行測試。(參考原始GAN論文[22]的圖1)。請注意,直方圖交叉分數主要受高概率區域的差異影響,在圖中無法察覺,因為圖中顯示的是對數概率,因此強調低概率區域的差異。
使用16×16的PatchGAN足以促使輸出清晰,并實現良好的FCN分數,但也會導致平鋪偽影。70 × 70的PatchGAN減輕了這些偽影問題,并實現了類似的分數。超越這一點,達到完整的286 × 286的ImageGAN并沒有顯著提高結果的視覺質量,實際上FCN分數顯著降低(表2)。這可能是因為ImageGAN具有比70 × 70的PatchGAN更多的參數和更大的深度,可能更難訓練。
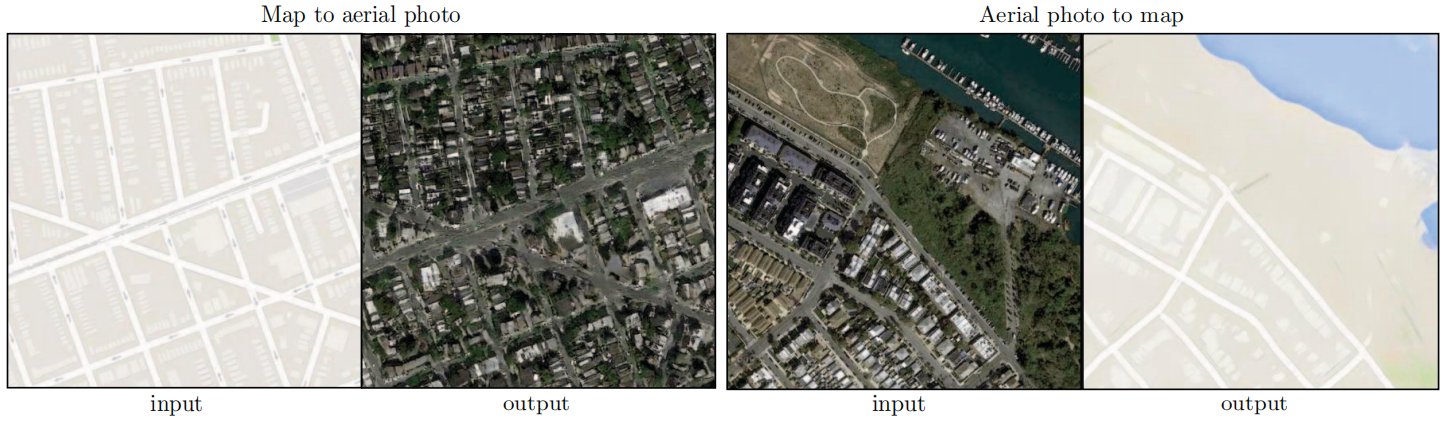
全卷積轉換的一個優勢是,固定大小的補丁鑒別器可以應用于任意大小的圖像。我們還可以在比訓練圖像更大的圖像上對生成器進行卷積。我們在地圖?航拍照片任務上進行了測試。在對256×256圖像進行生成器訓練后,我們在512×512圖像上對其進行測試。圖7中的結果展示了這種方法的有效性。
圖7:在512x512分辨率上的Google Maps示例結果(模型在256x256分辨率圖像上訓練,在測試時在較大圖像上進行了卷積)。為了清晰起見進行了對比度調整。
4.5. 感知驗證
我們在地圖?航拍照片和灰度→彩色任務上驗證了結果的感知逼真度。地圖?照片的AMT實驗結果如表3所示。我們方法生成的航拍照片在18.9%的試驗中欺騙了參與者,明顯高于L1基線,后者產生模糊的結果,幾乎從未欺騙過參與者。相反,在照片→地圖方向上,我們的方法在6.1%的試驗中欺騙了參與者,與L1基線的表現沒有顯著差異(基于bootstrap測試)。這可能是因為地圖中的輕微結構錯誤在視覺上更加明顯,而地圖具有剛性幾何,而航拍照片則更加混亂。
表3:在地圖?航空照片任務上進行的AMT“真實 vs 虛假”測試。

我們在ImageNet[48]上進行了彩色化的訓練,并在[58, 32]引入的測試集上進行了測試。我們的方法,使用L1+cGAN損失,在22.5%的試驗中欺騙了參與者(表4)。我們還測試了[58]的結果以及他們的方法的變體,該方法使用了L2損失(有關詳細信息,請參見[58])。條件GAN的得分與[58]的L2變體相似(通過bootstrap測試的差異不顯著),但未達到[58]的完整方法水平,在我們的實驗中,后者在27.8%的試驗中欺騙了參與者。我們注意到他們的方法專門設計用于在彩色化方面表現良好。
表4:在上色任務上進行的AMT“真實 vs 虛假”測試。

圖8:條件GAN與[58]中的L2回歸和[60]中的完整方法(通過重新平衡進行分類)的上色結果對比。cGAN可以產生引人注目的上色效果(前兩行),但有一個常見的失敗模式,即生成灰度或去飽和的結果(最后一行)。

4.6. 語義分割
條件性GAN似乎在輸出高度詳細或照片般的問題上是有效的,這在圖像處理和圖形任務中很常見。那么對于輸出比輸入更簡單的視覺問題,如語義分割,情況如何呢?
為了開始測試這一點,我們在城市景觀照片→標簽上訓練了一個cGAN(帶/不帶L1損失)。圖11顯示了定性結果,定量分類準確性在表5中報告。有趣的是,沒有L1損失進行訓練的cGAN能夠在合理的精度下解決這個問題。據我們所知,這是第一個成功生成“標簽”的GAN演示,這些標簽幾乎是離散的,而不是具有連續變化的“圖像”2。盡管cGAN取得了一些成功,但它們遠未成為解決這個問題的最佳方法:僅使用L1回歸得到的分數比使用cGAN要好,如表5所示。我們認為對于視覺問題,目標(即預測與地面真值接近的輸出)可能比圖形任務的目標更少模糊,而像L1這樣的重建損失基本足夠。
表5:在城市景觀數據集上進行的照片→標簽任務的性能。
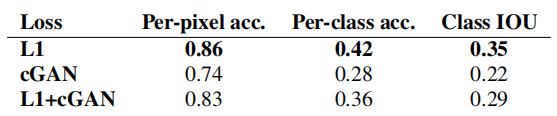
4.7. 社區驅動的研究
自論文和我們的pix2pix代碼庫首次發布以來,Twitter社區,包括計算機視覺和圖形領域的從業者以及藝術家,已經成功地將我們的框架應用于多種新穎的圖像到圖像轉換任務,遠遠超出了原始論文的范圍。圖10僅展示了#pix2pix標簽下的一些示例,例如素描→肖像、”Do as I Do”姿勢轉移、深度→街景、背景去除、調色板生成、素描→寶可夢,以及廣受歡迎的#edges2cats。
圖9:我們方法在幾個任務上的結果(數據來自[42]和[17])。請注意,草圖→照片的結果是由在自動邊緣檢測上訓練并在人工繪制的草圖上測試的模型生成的。請查看在線材料以獲取額外的示例。

圖10:基于我們的pix2pix代碼庫開發的在線社區示例應用:#edges2cats [3] 由Christopher Hesse,Sketch → Portrait [7] 由Mario Kingemann,“Do As I Do” 姿勢轉換 [2] 由Brannon Dorsey,Depth→ Streetview [5] 由Jasper van Loenen,背景去除 [6] 由Kaihu Chen,調色板生成 [4] 由Jack Qiao,以及Sketch→ Pokemon [1] 由Bertrand Gondouin。

圖11:將條件性GAN應用于語義分割。cGAN生成銳利的圖像,乍一看與真實情況相似,但實際上包含許多小型幻像對象。
5. 結論
本文的結果表明,條件性對抗網絡是許多圖像到圖像轉換任務的一種有前途的方法,尤其是涉及高度結構化圖形輸出的任務。這些網絡學習了適應特定任務和數據的損失,使它們適用于各種不同的情境。
致謝
我們感謝Richard Zhang、Deepak Pathak和Shubham Tulsiani的有益討論,感謝Saining Xie為HED邊緣檢測器提供幫助,以及在線社區在探索許多應用并提出改進意見方面的貢獻。本工作部分得到了NSF SMA-1514512、NGA NURI、IARPA通過空軍研究實驗室、Intel Corp、Berkeley Deep Drive以及Nvidia的硬件捐贈的支持。
REFRENCE
- Bertrand Gondouin. https://twitter.com/bgondouin/status/818571935529377792. Accessed, 2017-04-21.
- Brannon Dorsey. https://twitter.com/brannondorsey/status/806283494041223168. Accessed, 2017-04-21.
- Christopher Hesse. https://affinelayer.com/pixsrv/. Accessed: 2017-04-21.
- Jack Qiao. http://colormind.io/blog/. Accessed: 2017-04-21.
- Jasper van Loenen. https://jaspervanloenen.com/neural-city/. Accessed, 2017-04-21.
- Kaihu Chen. http://www.terraai.org/imageops/index.html. Accessed, 2017-04-21.
- Mario Klingemann. https://twitter.com/quasimondo/status/826065030944870400. Accessed, 2017-04-21.
- A. Buades, B. Coll, and J.-M. Morel. A non-local algorithm for image denoising. In CVPR, volume 2, pages 60–65. IEEE, 2005.
- L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Semantic image segmentation with deep convolutional nets and fully connected CRFs. In ICLR, 2015.
- T. Chen, M.-M. Cheng, P. Tan, A. Shamir, and S.-M. Hu. Sketch2photo: internet image montage. ACM Transactions on Graphics (TOG), 28(5):124, 2009.
- M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The Cityscapes Dataset for semantic urban scene understanding. In CVPR, 2016.
- E. L. Denton, S. Chintala, R. Fergus, et al. Deep generative image models using a Laplacian pyramid of adversarial networks. In NIPS, pages 1486–1494, 2015.
- A. Dosovitskiy and T. Brox. Generating images with perceptual similarity metrics based on deep networks. arXiv preprint arXiv:1602.02644, 2016.
- A. A. Efros and W. T. Freeman. Image quilting for texture synthesis and transfer. In SIGGRAPH, pages 341–346. ACM, 2001.
- A. A. Efros and T. K. Leung. Texture synthesis by non-parametric sampling. In ICCV, volume 2, pages 1033–1038. IEEE, 1999.
- D. Eigen and R. Fergus. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, pages 2650–2658, 2015.
- M. Eitz, J. Hays, and M. Alexa. How do humans sketch objects? SIGGRAPH, 31(4):44–1, 2012.
- R. Fergus, B. Singh, A. Hertzmann, S. T. Roweis, and W. T. Freeman. Removing camera shake from a single photograph. In ACM Transactions on Graphics (TOG), volume 25, pages 787–794. ACM, 2006.
- L. A. Gatys, A. S. Ecker, and M. Bethge. Texture synthesis and the controlled generation of natural stimuli using convolutional neural networks. arXiv preprint arXiv:1505.07376, 2015.
- L. A. Gatys, A. S. Ecker, and M. Bethge. Image style transfer using convolutional neural networks. CVPR, 2016.
- J. Gauthier. Conditional generative adversarial nets for convolutional face generation. Class Project for Stanford CS231N: Convolutional Neural Networks for Visual Recognition, Winter semester, 2014(5):2, 2014.
- I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In NIPS, 2014.
- A. Hertzmann, C. E. Jacobs, N. Oliver, B. Curless, and D. H. Salesin. Image analogies. In SIGGRAPH, pages 327–340. ACM, 2001.
- G. E. Hinton and R. R. Salakhutdinov. Reducing the dimensionality of data with neural networks. Science, 313(5786):504–507, 2006.
- S. Iizuka, E. Simo-Serra, and H. Ishikawa. Let there be Color!: Joint End-to-end Learning of Global and Local Image Priors for Automatic Image Colorization with Simultaneous Classification. ACM Transactions on Graphics (TOG), 35(4), 2016.
- S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. 2015.
- J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. 2016.
- L. Karacan, Z. Akata, A. Erdem, and E. Erdem. Learning to generate images of outdoor scenes from attributes and semantic layouts. arXiv preprint arXiv:1612.00215, 2016.
- D. Kingma and J. Ba. Adam: A method for stochastic optimization. ICLR, 2015.
- P.-Y. Laffont, Z. Ren, X. Tao, C. Qian, and J. Hays. Transient attributes for high-level understanding and editing of outdoor scenes. ACM Transactions on Graphics (TOG), 33(4):149, 2014.
- A. B. L. Larsen, S. K. S?nderby, and O. Winther. Autoencoding beyond pixels using a learned similarity metric. arXiv preprint arXiv:1512.09300, 2015.
- G. Larsson, M. Maire, and G. Shakhnarovich. Learning representations for automatic colorization. ECCV, 2016.
- C. Ledig, L. Theis, F. Huszár, J. Caballero, A. Cunningham, A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang, et al. Photo-realistic single image super-resolution using a generative adversarial network. arXiv preprint arXiv:1609.04802, 2016.
- C. Li and M. Wand. Combining Markov random fields and convolutional neural networks for image synthesis. CVPR, 2016.
- C. Li and M. Wand. Precomputed real-time texture synthesis with Markovian generative adversarial networks. ECCV, 2016.
- J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, pages 3431–3440, 2015.
- M. Mathieu, C. Couprie, and Y. LeCun. Deep multi-scale video prediction beyond mean square error. ICLR, 2016.
- M. Mirza and S. Osindero. Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784, 2014.
- A. Owens, P. Isola, J. McDermott, A. Torralba, E. H. Adelson, and W. T. Freeman. Visually indicated sounds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2405–2413, 2016.
- D. Pathak, P. Krahenbuhl, J. Donahue, T. Darrell, and A. A. Efros. Context encoders: Feature learning by inpainting. CVPR, 2016.
- A. Radford, L. Metz, and S. Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434, 2015.
- R. S. Radim Tylecek. Spatial pattern templates for recognition of objects with regular structure. In Proc. GCPR, Saarbrucken, Germany, 2013.
- S. Reed, Z. Akata, X. Yan, L. Logeswaran, B. Schiele, and H. Lee. Generative adversarial text to image synthesis. arXiv preprint arXiv:1605.05396, 2016.
- S. Reed, A. van den Oord, N. Kalchbrenner, V. Bapst, M. Botvinick, and N. de Freitas. Generating interpretable images with controllable structure. Technical report, Technical report, 2016.
- S. E. Reed, Z. Akata, S. Mohan, S. Tenka, B. Schiele, and H. Lee. Learning what and where to draw. In Advances In Neural Information Processing Systems, pages 217–225, 2016.
- E. Reinhard, M. Ashikhmin, B. Gooch, and P. Shirley. Color transfer between images. IEEE Computer Graphics and Applications, 21:34–41, 2001.
- O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In MICCAI, pages 234–241. Springer, 2015.
- O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Imagenet large scale visual recognition challenge. IJCV, 115(3):211–252, 2015.
- T. Salimans, I. Goodfellow, W. Zaremba, V. Cheung, A. Radford, and X. Chen. Improved techniques for training GANs. arXiv preprint arXiv:1606.03498, 2016.
- Y. Shih, S. Paris, F. Durand, and W. T. Freeman. Data-driven hallucination of different times of day from a single outdoor photo. ACM Transactions on Graphics (TOG), 32(6):200, 2013.
- D. Ulyanov, A. Vedaldi, and V. Lempitsky. Instance normalization: The missing ingredient for fast stylization. arXiv preprint arXiv:1607.08022, 2016.
- X. Wang and A. Gupta. Generative image modeling using style and structure adversarial networks. ECCV, 2016.
- Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing, 13(4):600–612, 2004.
- S. Xie, X. Huang, and Z. Tu. Top-down learning for structured labeling with convolutional pseudoprior. 2015.
- S. Xie and Z. Tu. Holistically-nested edge detection. In ICCV, 2015.
- D. Yoo, N. Kim, S. Park, A. S. Paek, and I. S. Kweon. Pixel-level domain transfer. ECCV, 2016.
- A. Yu and K. Grauman. Fine-Grained Visual Comparisons with Local Learning. In CVPR, 2014.
- R. Zhang, P. Isola, and A. A. Efros. Colorful image colorization. ECCV, 2016.
- J. Zhao, M. Mathieu, and Y. LeCun. Energy-based generative adversarial network. arXiv preprint arXiv:1609.03126, 2016.
- Y. Zhou and T. L. Berg. Learning temporal transformations from time-lapse videos. In ECCV, 2016.
- J.-Y. Zhu, P. Kr¨ahenb¨uhl, E. Shechtman, and A. A. Efros. Generative visual manipulation on the natural image manifold. In ECCV, 2016.
rsarial network. arXiv preprint arXiv:1609.03126, 2016. - Y. Zhou and T. L. Berg. Learning temporal transformations from time-lapse videos. In ECCV, 2016.
- J.-Y. Zhu, P. Kr¨ahenb¨uhl, E. Shechtman, and A. A. Efros. Generative visual manipulation on the natural image manifold. In ECCV, 2016.
我們通過調整GAN判別器的深度來實現這種補丁大小的變化。有關此過程的詳細信息以及判別器架構,請參閱在線的補充材料。 ??
請注意,我們訓練時使用的標簽圖并不完全是離散值,因為它們是通過雙線性插值從原始地圖調整大小并保存為JPEG圖像的,其中可能存在一些壓縮偽影。 ??





------ 實現單節點的Diff算法)

 劍指 Offer 12. 矩陣中的路徑 ——【Leetcode每日一題】)






之基礎篇一)




