👨?🎓作者簡介:一位即將上大四,正專攻機器學習的保研er
🌌上期文章:機器學習&&深度學習——自注意力和位置編碼(數學推導+代碼實現)
📚訂閱專欄:機器學習&&深度學習
希望文章對你們有所幫助
transformer(機器翻譯的再實現)
- 引入
- 模型
- 基于位置的前饋網絡
- 殘差連接和層規范化
- 為何使用層規范化
- 編碼器
- 解碼器
- 訓練
- 小結
引入
上一節比較了CNN、RNN和self-attention。容易知道,自注意力同時具有并行計算力強和最大路徑長度的兩個有點,因此使用self-attention來設計模型架構是很有吸引力的。
而transformer模型就是完全基于注意力機制,且其沒有任何的卷積層和循環神經網絡層。transformer最初是應用在文本數據上的序列到序列學習,現在也已經推廣到了語言、視覺、語音和強化學習等領域。
而在之前,我們已經使用了seq2seq來實現了英語到法語的翻譯,那時候發現訓練后的效果并不是很好,接下來將邊講解transformer邊用transformer來進行機器翻譯。
模型
transformer是編碼器-解碼器架構的一個實例,整體實例的架構圖如下所示:
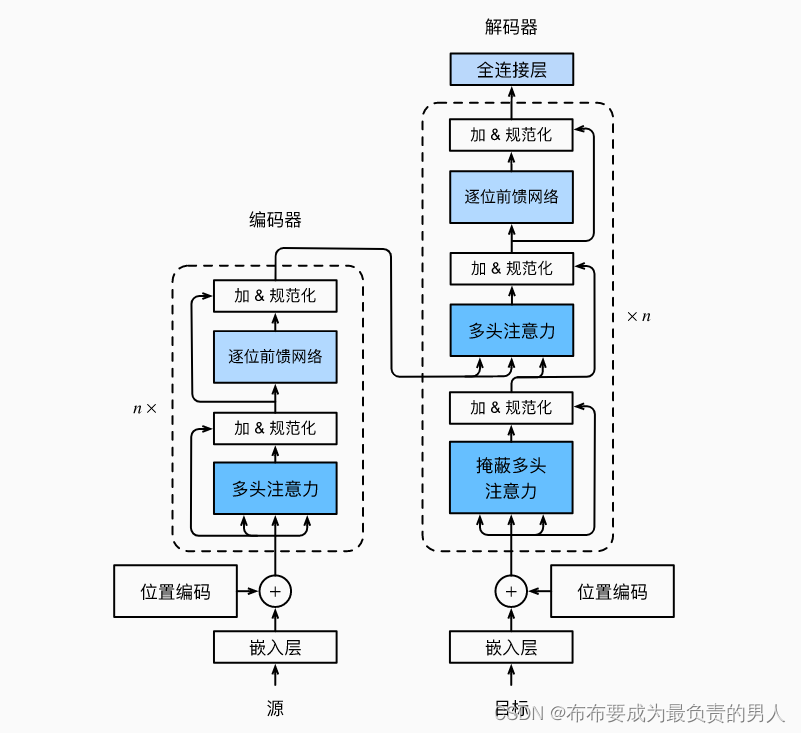
可以看出transformer的編碼器和解碼器時基于自注意力的模塊疊加而成的,源(輸入)序列和目標(輸出)序列的嵌入(embedding)表示將加上位置編碼,再分別輸入到編碼器和解碼器中。
宏觀角度上進行結構上的解釋,transformer的編碼器是由多個相同的層疊加而成的,每個層都有兩個子層(sublayer)。第一個子層是多頭注意力(multi-head self-attention)池化;第二個子層是基于位置的前饋網絡(positionwise feed-forward network(FFT))。也就是說,計算編碼器的自注意力時,查詢、鍵和值都來自前一個編碼器層的輸出。
受殘差網絡ResNet的啟發(具體可以自行去了解一下原理,主要優點是殘差網絡的使用使得模型更容易優化),每個子層都使用了殘差連接。在transformer中,對于序列中任何位置的任何輸入x∈Rd,都要求滿足sublayer(x)∈Rd,一遍殘差連接滿足x+sublayer(x)∈Rd。在殘差連接的加法運算后,要緊接著進行應用層規范化(layer normalization)。因此,輸入序列對應的每個位置,編碼器都將輸出一個d維表示向量。
transformer的解碼器也是由多個相同的層疊加而成的,也使用了殘差連接和層規范化。除了編碼器中描述的兩個子層之外,解碼器還在這兩個子層之間插入了第三個子層,稱為編碼器-解碼器注意力層。這個層的query為前一解碼器層的輸出,而key和value都是來自編碼器的輸出。在解碼器自注意力中,query、key、value都來自上一個解碼器層的輸出。但是解碼器中的每個位置只能考慮該位置之前的所有位置,這和我們之前見過的掩蔽很相似,事實上這種掩蔽注意力就保留了自回歸屬性,確保預測僅僅依賴于已生成的輸出詞元。
import math
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
基于位置的前饋網絡
基于位置的前饋網絡對序列中的所有位置的表示進行變換時使用的是同一個多層感知機(MLP),這就是稱前饋網絡是基于位置的原因。下面進行實現,下面代碼中,輸入X的形狀為(批量大小,時間步數或序列長度,隱單元數或特征維度)將被一個兩層感知機轉換成形狀為(批量大小,時間步數,ffn_num_outputs)的輸出張量。
#@save
class PositionWiseFFN(nn.Module):"""基于位置的前饋網絡"""def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs,**kwargs):super(PositionWiseFFN, self).__init__(**kwargs)self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)self.relu = nn.ReLU()self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)def forward(self, X):return self.dense2(self.relu(self.dense1(X)))
殘差連接和層規范化
現在關注加法和規范化(add&norm)組件,如前面所說,這是由殘差連接和緊隨其后的層規范化組成的,這兩個都是關鍵。
規范化也叫歸一化,他將其改變成均值為0方差為1。
在計算機視覺中,常用批量規范化,也就是在一個小批量的樣本內基于批量規范化對數據進行重新中心化和重新縮放的調整。層規范化是基于特征維度進行規范化。而在NLP(輸入通常是變長序列)中通常使用層規范化。
為何使用層規范化
也就是為啥使用LayerNorm而不使用BatchNorm呢?如下圖:
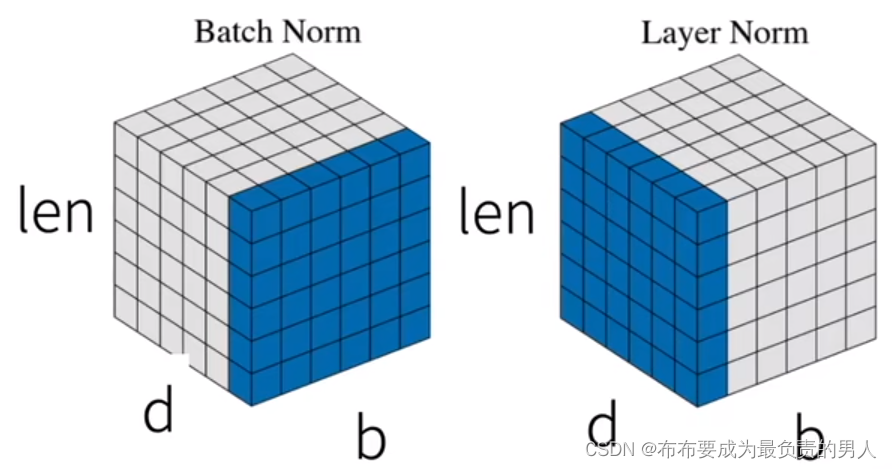
其中,b為batch_size也就是批量大小,len是指代序列的長度。
那么我們知道,批量規范化是對每個特征/通道里的元素進行歸一化,把d規范化了,len留著,但是對于序列長度會變的NLP并不適合,這樣就會不穩定。
而層規范化則是對每個樣本里面的元素進行規范化,相對更穩定。
通過以下的代碼來對比不同維度的層規范化和批量規范化的效果:
ln = nn.LayerNorm(2)
bn = nn.BatchNorm1d(2)
X = torch.tensor([[1, 2], [2, 3]], dtype=torch.float32)
# 在訓練模式下計算X的均值和方差
print('layer norm:', ln(X), '\nbatch norm:', bn(X))
運行結果:

可以很清楚看出來,使用層規范化以后,會對每一個批量中的每一個樣本的不同特征來進行規范化;使用批量規范化以后,會對每一個批量中的每個樣本的同一特征來進行規范化。
接著就可以使用殘差連接和層規范化來實現AddNorm類,dropout也被作為正則化方法使用:
#@save
class AddNorm(nn.Module):"""殘差連接后進行層規范化"""def __init__(self, normalized_shape, dropout, **kwargs):super(AddNorm, self).__init__(**kwargs)self.dropout = nn.Dropout(dropout)self.ln = nn.LayerNorm(normalized_shape)def forward(self, X, Y):return self.ln(self.dropout(Y) + X)
殘差連接要求兩個輸入的形狀相同,以便加法操作后輸出張量的形狀相同。
add_norm = AddNorm([3, 4], 0.5)
add_norm.eval()
print(add_norm(torch.ones((2, 3, 4)), torch.ones((2, 3, 4))).shape)
輸出結果:
torch.Size([2, 3, 4])
編碼器
有了組成Transformer編碼器的基礎組件,現在可以先實現編碼器中的一個層。下面的EncoderBlock類包含兩個子層:多頭自注意力和基于位置的前饋網絡,這兩個子層都使用了殘差連接和緊隨的層規范化。
#@save
class EncoderBlock(nn.Module):"""Transformer編碼器塊"""def __init__(self, key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,dropout, use_bias=False, **kwargs):super(EncoderBlock, self).__init__(**kwargs)self.attention = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout,use_bias)self.addnorm1 = AddNorm(norm_shape, dropout)self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, num_hiddens)self.addnorm2 = AddNorm(norm_shape, dropout)def forward(self, X, valid_lens):Y = self.addnorm1(X, self.attention(X, X, X, valid_lens))return self.addnorm2(Y, self.ffn(Y))
下面實現的Transformer編碼器的代碼中,堆疊了num_layers個EncoderBlock類的實例。由于這里使用的是值范圍在-1和1之間的固定位置編碼,因此通過學習得到的輸入的嵌入表示的值需要先乘以嵌入維度的平方根進行重新縮放,然后再與位置編碼相加。
#@save
class TransformerEncoder(d2l.Encoder):"""Transformer編碼器"""def __init__(self, vocab_size, key_size, query_size, value_size,num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, num_layers, dropout, use_bias=False, **kwargs):super(TransformerEncoder, self).__init__(**kwargs)self.num_hiddens = num_hiddensself.embedding = nn.Embedding(vocab_size, num_hiddens)self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)self.blks = nn.Sequential()for i in range(num_layers):self.blks.add_module("block"+str(i),EncoderBlock(key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, dropout, use_bias))def forward(self, X, valid_lens, *args):# 因為位置編碼值在-1和1之間,# 因此嵌入值乘以嵌入維度的平方根進行縮放,# 然后再與位置編碼相加。X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))self.attention_weights = [None] * len(self.blks)for i, blk in enumerate(self.blks):X = blk(X, valid_lens)self.attention_weights[i] = blk.attention.attention.attention_weightsreturn X
解碼器
Transformer解碼器也是由多個相同的層組成,在DecoderBlock類中實現的每個層包含了三個子層:解碼器自注意力、“編碼器-解碼器”注意力和基于位置的前饋網絡。這些子層也都被殘差連接和緊隨的層規范化圍繞。
在掩蔽多頭解碼器自注意力層(第一個子層)中,查詢、鍵和值都來自上一個解碼器層的輸出。關于序列到序列模型(sequence-to-sequence model),在訓練階段,其輸出序列的所有位置(時間步)的詞元都是已知的;然而,在預測階段,其輸出序列的詞元是逐個生成的。
因此,在任何解碼器時間步中,只有生成的詞元才能用于解碼器的自注意力計算中。為了在解碼器中保留自回歸的屬性,其掩蔽自注意力設定了參數dec_valid_lens,以便任何查詢都只會與解碼器中所有已經生成詞元的位置(即直到該查詢位置為止)進行注意力計算。
class DecoderBlock(nn.Module):"""解碼器中第i個塊"""def __init__(self, key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,dropout, i, **kwargs):super(DecoderBlock, self).__init__(**kwargs)self.i = iself.attention1 = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout)self.addnorm1 = AddNorm(norm_shape, dropout)self.attention2 = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout)self.addnorm2 = AddNorm(norm_shape, dropout)self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens,num_hiddens)self.addnorm3 = AddNorm(norm_shape, dropout)def forward(self, X, state):enc_outputs, enc_valid_lens = state[0], state[1]# 訓練階段,輸出序列的所有詞元都在同一時間處理,# 因此state[2][self.i]初始化為None。# 預測階段,輸出序列是通過詞元一個接著一個解碼的,# 因此state[2][self.i]包含著直到當前時間步第i個塊解碼的輸出表示if state[2][self.i] is None:key_values = Xelse:key_values = torch.cat((state[2][self.i], X), axis=1)state[2][self.i] = key_valuesif self.training:batch_size, num_steps, _ = X.shape# dec_valid_lens的開頭:(batch_size,num_steps),# 其中每一行是[1,2,...,num_steps]dec_valid_lens = torch.arange(1, num_steps + 1, device=X.device).repeat(batch_size, 1)else:dec_valid_lens = None# 自注意力X2 = self.attention1(X, key_values, key_values, dec_valid_lens)Y = self.addnorm1(X, X2)# 編碼器-解碼器注意力。# enc_outputs的開頭:(batch_size,num_steps,num_hiddens)Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)Z = self.addnorm2(Y, Y2)return self.addnorm3(Z, self.ffn(Z)), state
現在我們構建了由num_layers個DecoderBlock實例組成的完整的Transformer解碼器。最后,通過一個全連接層計算所有vocab_size個可能的輸出詞元的預測值。解碼器的自注意力權重和編碼器解碼器注意力權重都被存儲下來,方便日后可視化的需要。
class TransformerDecoder(d2l.AttentionDecoder):def __init__(self, vocab_size, key_size, query_size, value_size,num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, num_layers, dropout, **kwargs):super(TransformerDecoder, self).__init__(**kwargs)self.num_hiddens = num_hiddensself.num_layers = num_layersself.embedding = nn.Embedding(vocab_size, num_hiddens)self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)self.blks = nn.Sequential()for i in range(num_layers):self.blks.add_module("block"+str(i),DecoderBlock(key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, dropout, i))self.dense = nn.Linear(num_hiddens, vocab_size)def init_state(self, enc_outputs, enc_valid_lens, *args):return [enc_outputs, enc_valid_lens, [None] * self.num_layers]def forward(self, X, state):X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))self._attention_weights = [[None] * len(self.blks) for _ in range (2)]for i, blk in enumerate(self.blks):X, state = blk(X, state)# 解碼器自注意力權重self._attention_weights[0][i] = blk.attention1.attention.attention_weights# “編碼器-解碼器”自注意力權重self._attention_weights[1][i] = blk.attention2.attention.attention_weightsreturn self.dense(X), state@propertydef attention_weights(self):return self._attention_weights
訓練
依照Transformer架構來實例化編碼器-解碼器模型。在這里,指定Transformer的編碼器和解碼器都是2層,都使用4頭注意力。為了進行序列到序列的學習,下面將在之前所說的機器翻譯數據集上進行transformer模型的訓練。
num_hiddens, num_layers, dropout, batch_size, num_steps = 32, 2, 0.1, 64, 10
lr, num_epochs, device = 0.005, 200, d2l.try_gpu()
ffn_num_input, ffn_num_hiddens, num_heads = 32, 64, 4
key_size, query_size, value_size = 32, 32, 32
norm_shape = [32]train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)encoder = TransformerEncoder(len(src_vocab), key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,num_layers, dropout)
decoder = TransformerDecoder(len(tgt_vocab), key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
d2l.plt.show()
運行輸出:
loss 0.032, 5786.9 tokens/sec on cpu
運行圖片:
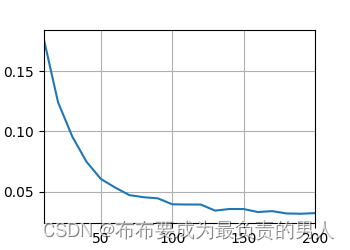
訓練完后,我們可以將一些英語句子翻譯成法語,并且計算翻譯后的BLEU分數(和之前的seq2seq實現的訓練模型一樣的計算方式):
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):translation, dec_attention_weight_seq = d2l.predict_seq2seq(net, eng, src_vocab, tgt_vocab, num_steps, device, True)print(f'{eng} => {translation}, ',f'bleu {d2l.bleu(translation, fra, k=2):.3f}')
運行結果:
go . => va !, bleu 1.000
i lost . => j’ai perdu ., bleu 1.000
he’s calm . => il est mouillé ., bleu 0.658
i’m home . => je suis chez moi ., bleu 1.000
這次的效果比起上一次明顯還是好了很多的。
小結
1、Transformer是編碼器-解碼器架構的一個實踐,盡管在實際情況中編碼器或解碼器可以單獨使用。
2、在Transformer中,多頭自注意力用于表示輸入序列和輸出序列,不過解碼器必須通過掩蔽機制來保留自回歸屬性。
3、Transformer中的殘差連接和層規范化是訓練非常深度模型的重要工具。
4、Transformer模型中基于位置的前饋網絡使用同一個多層感知機,作用是對所有序列位置的表示進行轉換。


)
——Java語言描述、變量和運算符)













)

