Model Sparsity Can Simplify Machine Unlearning
- 背景
- 主要內容
- Contribution Ⅰ:對Machine Unlearning的一個全面的理解
- Contribution Ⅱ:說明model sparsity對Machine Unlearning的好處
- Pruning方法的選擇
- sparse-aware的unlearning framework
- Experiments
- Model sparsity improves approximate unlearning
- Effectiveness of sparsity-aware unlearning
- Application: MU for Trojan model cleanse.
- Application: MU to improve transfer learning.
背景
Machine Unlearning(MU)是指出于對數據隱私保護的目的以及對"RTBF"(right to be forgotten)等數據保護方案的響應,而提出的一種數據遺忘的方法。在現實中,用戶有權請求數據收集者刪除其個人數據,但是僅將用戶數據從數據集中刪除是不夠的。 原因:對model的攻擊,比如成員推理攻擊(membership inference attack,MIA),模型反演攻擊等,能夠從model反推出訓練數據集的信息。 如果model A是用完整的數據集訓練的,那么將用戶信息從數據集中刪除的同時,還需要從model A中抹除用戶的數據信息。
對MU分類,可以分為exact unlearning和approximate unlearning。
- 前者即利用刪除部分數據后的剩余數據集(Dr)重新訓練(Retrain),得到一個新的model,因為這個model的訓練并沒有用到被刪除的數據(Df),自然不包含Df的信息。因此通過Retain得到的model被認為是gold-standard retrained model 。 但是重訓練需要很高的計算成本、時間成本,因為在模型較大、數據集較大的情況下,訓練一個model是需要耗費很多計算資源,并需要很長時間的。因為僅刪除幾條用戶數據,就直接重新訓練一個model是不實際的。
- 因此有了后者,近似MU。近似二字體現出這類MU方法在遺忘的程度和計算成本等上一個trade-off。近似遺忘是指通過其他的方法,比如influence function(也是newton step)去更新模型參數,使得模型不必耗費大量計算資源去重訓練,而大致從模型中,抹除Df的信息。
實際上,在近似MU的過程中,比如利用influence function,或者fasher information matrix去更新模型參數的過程中,涉及到對模型參數的hessian matrix求逆的操作(hessian matrix就是二階偏導),如果模型參數量很大,比如百萬個參數,那么這些操作的計算量依舊是很大的。 因此為了降低計算量,在基于influence function的放上上又有很多優化,涉及很多理論的推導。
主要內容
論文鏈接:Model Sparsity Can Simplify Machine Unlearning
這篇論文的核心內容是,使用model sparsity,縮小approximate MU和exact MU之間的gap。這篇論文的model sparsity就是利用pruning,得到稀疏的模型,再去做MU,即先prune,再unlearn。主要內容如下:
Contribution Ⅰ:對Machine Unlearning的一個全面的理解
本文將approximate MU分為了以下四類:
- Fine-tuning(FT):把原來的model θ.在剩余數據集Dr微調少量的epochs,得到unlearning后的model θu。這個過程是希望能夠通過在Dr上微調以啟動 catastrophic forgetting(即在增量學習、連續學習的過程中,在另外個任務上微調model參數的時候,model就忘掉了在之前任務上學到的東西),使得模型遺忘掉Df的信息(因為原始數據集是Dr+Df)。
- Gradient ascent (GA):模型訓練過程中,模型參數是在往loss減小的方向移動,現在針對Df里面的數據集,將模型參數往在Df上數據點上的loss增大的方向移動。
- Influence unlearning(IU):使用influence function來表示數據點對模型參數w的影響。但是這個方法僅使用刪除的數據Df不大的情況。因為influence function中用到了first-order Taylor expansion,如果數據集變化較大的話,這個近似就不準確了。
- Fisher fogetting(FF):這個方法主要是用到了fisher information matrix(FIM)……【這個方法相關的論文我沒看懂】……FIM的計算量也是很大的。
這篇論文也提到,MU性能的評估指標有很多方面,再related works中各個approximate MU使用的評估指標不僅相同,也不全面,有些方法在metric A下性能可以,但在metric B下就不太優秀;而某些方法則相反。因此這篇論文希望對MU有一個全面的評估:
- Unlearning accuracy (UA):屬于反映unlearning efficacy的指標。UA(θu) = 1 - AccDf(θu)。就是unlearn后的model θu對遺忘數據Df的inference accuracy。AccDf(θu)越小越好,因此UA越大越好。
- Membership inference attack(MIA)on Df:MIA-efficacy是指Df中有多少樣本被MIA預測為unlearn后的model θu的non-training samples。MIA-efficacy越大越好。
- Remaining accuracy(RA):unlearn后的model θu在Dr上的inference accuracy。屬于fidelity of MU。越大越好。
- Test accuracy(TA):unlearn后的model θu在test dataset(不是Df也不是Dr,是一個新的用于測試的數據集)上的inference accuracy,反應了unlearn后的model θu的generalization。
- Run-time efficiency(RTE):以retrain為baseline,看approximate MU在計算上有多少加速。
Contribution Ⅱ:說明model sparsity對Machine Unlearning的好處
model sparsity,其實就是給model的參數上?一個mask(m),保留的wi對應mi=1,不保留的wj對應mj=0。這里先給出了基于gradient ascent的MU方法的unlearning error+model sparsity的理論分析(proposition 2):
θt是迭代更新θ過程中的某個結果,θ0是初始的model。因為mask m只有很少的項為1,因此m使得unlearning error減少了。
之后通過實驗,在上面的4中approximate MU方法上,驗證model sparsity對MU是有好處的,尤其是針對FT,隨著sparsity rate的增加,efficacy上(UA、MIA)有很大的提升:
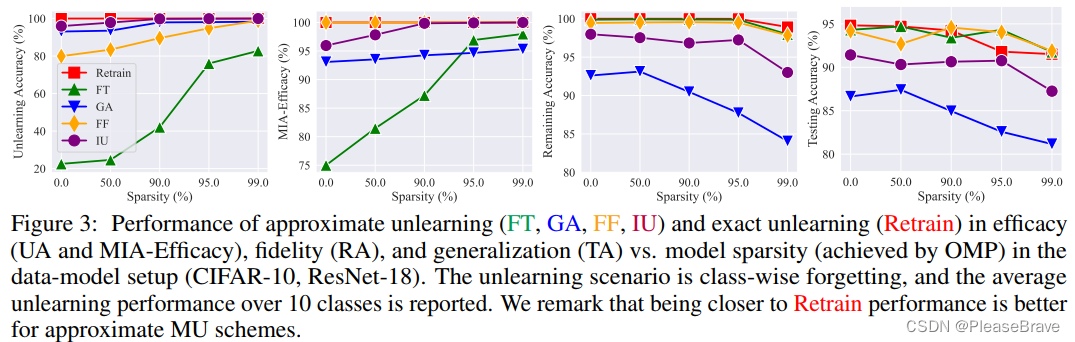
這里的實驗是基于one-shot magnitude pruning(OMP)的。
Pruning方法的選擇
這篇論文提到的主要方法是:先pruning,再unlearn。那么用什么pruning的方法呢?提到了三個criteria:①least dependence on the forgetting dataset (Df);因為最終是要移除model中包含的Df的信息,如果pruning的過程中過多的依賴Df的信息,那么sparse model中還是有很多Df的信息; ② lossless generalization when pruning;這個是希望pruning盡可能小的影響到TA;③ pruning efficiency,這個是希望盡可能小的影響到RTE,需要高效的pruning方法。 最終列出了三種:SynFlow (synaptic flow pruning),OMP (one-shot magnitude pruning),IMP。最終是用了SynFlow和OMP,因為這兩個更優:

OMP和SynFlow在95% sparsity的時候,相對Dense模型,TA有所下降,但是UA提高很多。IMP則是TA有所上升,但是UA下降了。因此最終選擇了OMP和SynFlow。因為IMP這個pruning方法對training dataset是強依賴的。
sparse-aware的unlearning framework
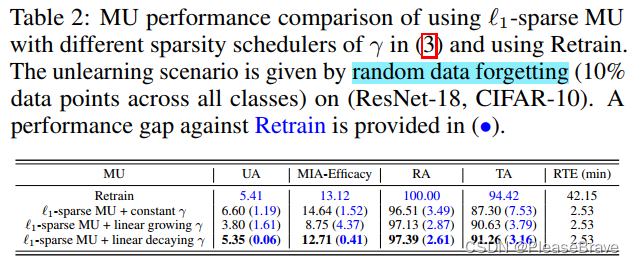
前面提到的都是先pruning再unlearn,后面文章提到pruning和unlearning同時進行,在unlearning的目標函數中引入一項L1-norm sparse regularization,最終MU的目標函數如下:
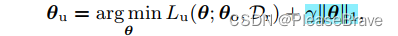
||θ||1越小的話,model也就越稀疏。這里的γ,是這個正則化項的權重,文章給了三種方案極其實驗結果,最后說明“use of a linearly decreasing γ scheduler outperforms other schemes.”
Experiments
Model sparsity improves approximate unlearning
兩種unlearning scenario:class-wise(Df consisting of training data points of an entire class)的和random datapoints(10% of the whole training dataset together)。
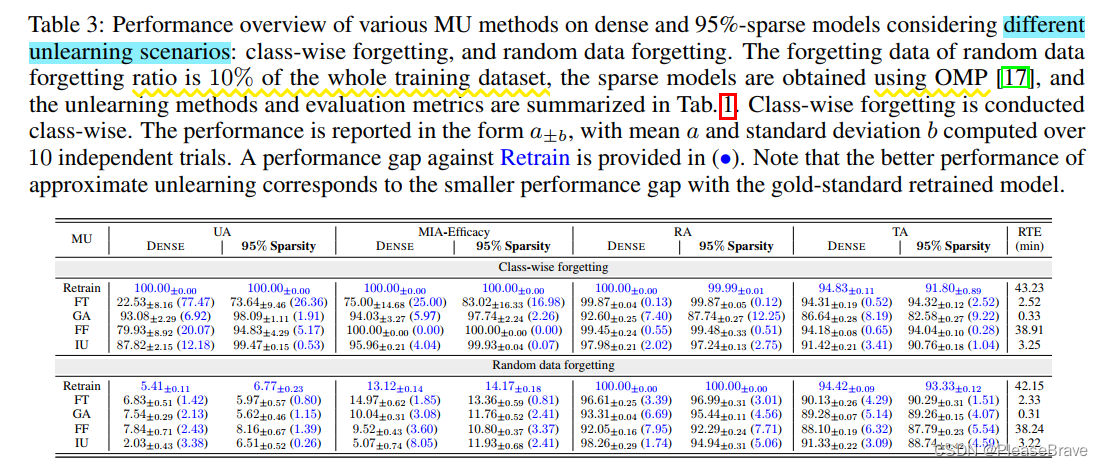
沒一縱列,右邊的和左邊的對比,括號里是與Retain這個gold-standard的對比,數字越小越好。所以文章提出的先pruning能夠boost MU performance。
Effectiveness of sparsity-aware unlearning
實驗驗證文章提出的pruning和unlearning同時進行的sparsity-aware unlearning方法效果:在class-wise forgetting和random data forgetting兩個scenario下,與基于Fine-tuning的MU方法和Retain,在五個metric下對比:

藍線即提出的方法,簡直是五邊形戰士!(但是和FT比有點取巧了吧hhhhFT在dense model上性能本來就不行)。
Application: MU for Trojan model cleanse.
用MU遺忘掉adversarial examples的信息,可以實現后門的移除:
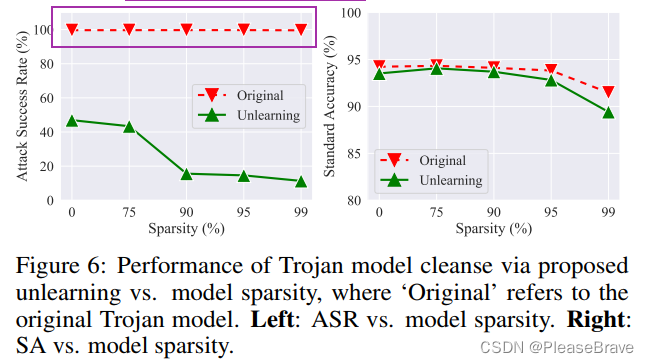
sparsity rate增加,unlearning后的model的ASR明顯下降,同時standard accuracy降低不多。
Application: MU to improve transfer learning.
transfer learning是指在一個領域上學習好的較大的model,換一個領域的數據集微調最后分類相關的層就能繼續用。但是原始的數據集,可能其中一些類對模型遷移影響是負面的,那么如果把這些類移除后訓練的model遷移性更好。那么可以考慮用MU先將一些類的信息從model中移除,再transfer learning:
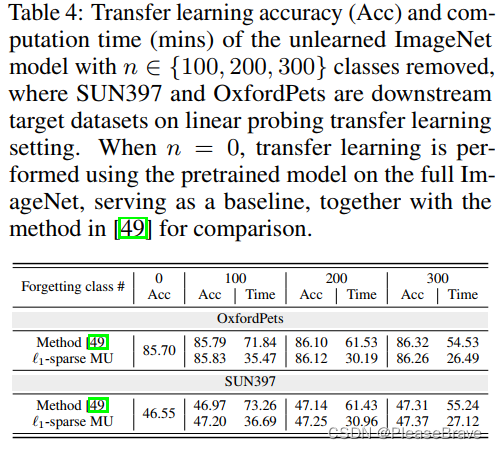
可見本文的方法,與參考方法相比,在兩個數據集上的遷移Acc都有所增加,但是Time更少。

)
——Java語言描述、變量和運算符)













)


