數據庫設計
-
第一范式:有主鍵,具有原子性,字段不可分割
數據庫表中不能出現重復記錄,每個字段是原子性的不能再分
關于第一范式,每一行必須唯一,也就是每個表必須有主鍵。
每一列不可再分!! 就只有一個信息
-
第二范式:完全依賴,沒有部分依賴
第二范式是建立在第一范式基礎上的,另外要求所有非主鍵字段完全依賴主鍵,不能產生部分依賴
-
第三范式:沒有傳遞依賴
數據庫設計盡量遵循三范式,但是還是根據實際情況進行取舍,有時可能會拿冗余換速度,最終用目的要滿足客戶需 求。
多對多的關系數據庫設計
- 多對多,三張表,關系表兩外鍵!!!!
一對多的關系數據庫設計
- 一對多,兩張表,多的表加外鍵!!!!
一對一設計,有兩種設計方案:
- 第一種設計方案:主鍵共享
- 第二種設計方案:外鍵唯一
基本命令行
創建
create database test_data;create table table_test
(id int not NULL auto_increment,IP varchar(15) NULL,primary key (id)
) engine=InnoDB default charset= utf8;drop table table_test;/*添加列*/
alter table table_test add vend_phone CHAR(20);/*刪除列*/
alter table table_test drop column vend_phone;/*修改字段*/
alter table t_student modify student_name varchar(100) ;/*例子*/
insert into emp(empno, ename, job, mgr, hiredate, sal, comm, deptno) values(9996,'zhangsan','MANAGER',null,str_to_date('1981-06-12','%Y-%m-%d') / now(),3000, 500, 10);/*創建新表 復制舊表*/
create table emp_bak as select empno,ename,sal fromemp;
/*查詢的數據直接放到已經存在的表中*/
insert into emp_bak select * from emp where sal=3000;
約束
常見的約束
- a) 非空約束,not null
- b) 唯一約束,unique
- c) 主鍵約束,primary key
- d) 外鍵約束,foreign key
- e) 自定義檢查約束,check(不建議使用)(在 mysql 中現在還不支持)
- 級聯更新與級聯刪除 on update cascade;
drop table if exists t_student; create table t_student( student_id int(10), student_name varchar(20), sex char(2), birthday date, email varchar(30), classes_id int(3) not null, constraint student_id_pk primary key(student_id), constraint fk_classes_id foreign key(classes_id) references t_classes(classes_id) );insert into t_student(student_id, student_name, sex, birthday, email, classes_id) values(1001, 'zhangsan', 'm', '1988-01-01', 'qqq@163.com', null);
查詢
select 字段 from 表名 where ……. group by …….. having …….(就是為了過濾分組后的數據而存在的—不可以單獨的出現) order by ……. limit ...; (限制數據的個數)以上語句的執行順序
原則:能在 where 中過濾的數據,盡量在 where 中過濾,效率較高。having 的過濾是專門對分組之后的數據進行過濾的。
- 首先執行 where 語句過濾原始數據
- 執行 group by 進行分組
- 執行 having 對分組數據進行操作
- 執行 select 選出數據
- 執行 order by 排序
select ephone,ename from person;
select ephone,ename from person where job = "IT";where <> 500; /*不等于*/
where ename =null;
where ename='a' and ephone='118';
where esal > 50 and (ename='a' and ephone='118');
where jbob in ('IT','QQ');
where ename like 'M%'; /*模糊查詢M開頭的所有人 %N 結尾 %O% 有O _A% 第二個字符有A*/ select * from person order by esal asc; /*從小到大 排序*/
select * from person order by esal desc; /*從小到大 排序*/
order by job desc, esal desc; /*多列 遞減*/select * from person where job = upper('it');
select lower(ename) from person;
select length(ename), ename from person where length(ename) > 5;select * from person where HIREDATE='1981-02-20'; /*查詢 1981-02-20 入職的員工*/
select empno, ename, date_format(date, '%Y-%m-%d %H:%i:%s') as date from emp;/*將入職日期格式化成 yyyy-mm-dd hh:mm:ss*/select round(123.56); /*四舍五入*/
select rand(); /*隨機數*/
select ifnull(comm,0) from emp; /*如果 comm 為 null 就替換為 0*/
select count(*) from emp; /*取得所有的員工數*/
select sum(esla) from emp; /*計算某一列的和*/
avg(esal); /*平均數*/ max() min()select job, sum(sal) from emp group by job; /*通過job的個數進行分組,取得每個工作崗位的工資合計,要求顯示崗位名稱和工資合計*/select job,deptno,sum(sal) from emp group by job,deptno; /*按照工作崗位和部門編碼分組,取得的工資合計*/select job, avg(sal) from emp group by job having avg(sal) >2000; /*如果想對分組數據再進行過濾需要使用 having 子句,,取得每個崗位的平均工資大于 2000 *//*取得前 5 條數據*/
select * from emp limit 5;
/*從第二條開始取兩條數據*/
select * from emp limit 1,2;
/*取得薪水最高的前 5 名*/
select * from emp e order by e.sal desc limit 5;
子查詢
在 where 語句中使用子查詢,也就是在 where 語句中加入 select 語句
/*查詢員工信息,查詢哪些人是管理者,要求顯示出其員工編號和員工姓名*/
/*首先取得管理者的編號,去除重復的 distinct 去除重復*/
select distinct mgr from emp where mgr is not null;
/*查詢員工編號包含管理者編號的*/
select empno, ename from emp where empno in(select mgr from emp where mgr is not null);/*查詢哪些人的薪水高于員工的平均薪水,需要顯示員工編號,員工姓名,薪水*/
select empno, ename, sal from emp where sal > (select avg(sal) from emp);在 from 語句中使用子查詢,可以將該子查詢看做一張表
/*查詢員工信息,查詢哪些人是管理者,要求顯示出其員工編號和員工姓名*/
/*首先取得管理者的編號,去除重復的*/
select distinct mgr from emp where mgr is not null;
/*將以上查詢作為一張表,放到 from 語句的后面*/
select e.empno, e.ename
from emp e join (select distinct mgr from emp where mgr is not null) m
on e.empno=m.mgr;/*查詢各個部門的平均薪水所屬等級,需要顯示部門編號,平均薪水,等級編號*/
/*首先取得各個部門的平均薪水*/
select deptno, avg(sal) avg_sal from emp group by deptno;
/*將部門的平均薪水作為一張表與薪水等級表建立連接,取得等級*/
select a.deptno,a.avg_sal,g.grade
from (select deptno,avg(sal) avg_sal from emp group by deptno ) a join salgrade g
on a.avg_sal between g.losal and g.hisal;
在 select 語句中使用子查詢
/*查詢員工信息,并顯示出員工所屬的部門名稱*/
/*在 select 語句中再次嵌套 select 語句完成部分名稱的查詢*/
select e.ename,
(select d.dname from dept d where e.deptno=d.deptno) as dname
from emp e;select e.ename, d.dname from emp e, dept d where e.deptno=d.deptno;
更新
update 表名 set 字段名稱 1=需要修改的值 1, 字段名稱 2=需要修改的值 2 where …….
/*將 job 為 manager 的員工的工資上漲 10%*/
update emp set sal=sal+sal*0.1 where job='MANAGER';
刪除
可以刪除數據,可以根據條件刪除數據
/*語法格式:*/
Delete from 表名 where 。。。。。
/*刪除津貼為 500 的員工*/
delete from emp where comm=500;
/*刪除津貼為 null 的員工*/
delete from emp where comm is null;
創建視圖
我們對視圖進行增刪改查,會影響到原始數據。相當是引用了原始數據
create view test_view as
select * from table_test;drop view test_view;
存儲過程
create procedure test()
beginselect * from table_test;
end;call test();drop procedure test;
事務
start transaction read only;
delete * from table_test;
savepoint delete1; /*保存節點*/
drop table table_test;
rollback to delete1;
commit;
表與表格之間的連接
表與表之間常用的關聯方式有兩種:內連接、外連接,下面以MySQL為例來說明這兩種連接方式。
內連接
內連接通過innner join來實現,它將返回兩張表中滿足連接條件的數據,不滿足條件的數據不會查詢出來。
select e.ename, e.sal, d.dname
from emp e inner join dept d
on e.deptno=d.deptno
where e.sal>2000;
外連接
外連接通過outer join來實現,它會返回兩張表中滿足連接條件的數據,同時返回不滿足連接條件的數據。外連接有兩種形式:左外連接(left outer join)、右外連接(right outer join)。
-
左連接
select e.ename, e.sal, d.dname from dept d left join emp e on e.deptno=d.deptno; -
右連接
select e.ename, e.sal, d.dname from emp e right join dept d on e.deptno=d.deptno;
全連接
full join是兩張表的并集
表合并 union
/*查詢 job 包含 MANAGER 和包含 SALESMAN 的員工*/
select * from emp where job in('MANAGER', 'SALESMAN');select * from emp where job='MANAGER'
union
select * from emp where job='SALESMAN';
導入導出數據庫
-
導出
mysqldump -u用戶名 -p 數據庫名 > /xx/xx/數據庫名.sql mysqldump -uroot -p abc > /xx/xx/abc.sql -
導入
mysql -u用戶名 -p 數據庫名 < 數據庫名.sql mysql -uroot -p123456 < abc.sql
常用的存儲引擎
MyISAM 存儲引擎
MyISAM 存儲引擎是 MySQL 最常用的引擎。
- 它管理的表具有以下特征:
使用三個文件表示每個表:
格式文件 — 存儲表結構的定義(mytable.frm)
數據文件 — 存儲表行的內容(mytable.MYD)
索引文件 — 存儲表上索引(mytable.MYI) —> 相當于一本的書的目錄 用來縮小查找范圍
對于一個表只要是主鍵或者有unique約束的 key 都會自動添加索引;
-
–靈活的 AUTO_INCREMENT 字段處理
-
–可被轉換為壓縮、只讀表來節省空間。
InnoDB 存儲引擎
**安全 ** 事務 InnoDB 存儲引擎是 MySQL 的缺省引擎。
它管理的表具有下列主要特征:
- 每個 InnoDB 表在數據庫目錄中以.frm 格式文件表示
- InnoDB 表空間 tablespace 被用于存儲表的內容 索引也存在 tablespace
- 提供一組用來記錄事務性活動的日志文件
- 用 COMMIT(提交)、SAVEPOINT 及 ROLLBACK(回滾)支持事務處理
- 提供全 ACID 兼容
- 在 MySQL 服務器崩潰后提供自動恢復
- 多版本(MVCC)和行級鎖定 – 支持外鍵及引用的完整性,包括級聯刪除和更新
MEMORY 存儲引擎
使用 MEMORY 存儲引擎的表,其數據存儲在內存中,且行的長度固定,這兩個特點使得 MEMORY 存儲引擎非 常快。
MEMORY 存儲引擎管理的表具有下列特征:
- 在數據庫目錄內,每個表均以.frm 格式的文件表示。
- 表數據及索引被存儲在內存中。
- 表級鎖機制。
- 不能包含 TEXT 或 BLOB 字段。
MEMORY 存儲引擎以前被稱為 HEAP 引擎
事務----InnoDB引擎
什么是數據庫事務
事物就是一個完整的業務邏輯。 只有(update、delete、insert)會產生事務
例子:A 向 B 轉賬
- A的錢扣除
- B的錢增加
把上述的命令作為一個整體向系統提交,要么成功要么失敗!!! 不可再拆分!!
數據庫的 事務(Transaction)是一種機制、一個操作序列,包含了一組數據庫操作命令,其執行的結果必須使數據庫從一種一致性狀態變到另一種一致性狀態。事務把所有的命令作為一個整體一起向系統提交或撤銷操作請求,即這一組數據庫命令要么都執行,要么都不執行,因此事務是一個不可分割的工作邏輯單元。如果任意一個操作失敗,那么整組操作即為失敗,會回到操作前狀態或者是上一個節點。
事務的四大特性ACID
事務具有四個特征 ACID
-
a) 原子性(Atomicity)
整個事務中的所有操作,必須作為一個單元全部完成(或全部取消)。
-
b) 一致性(Consistency)
在事務開始之前與結束之后,數據庫都保持一致狀態。 一個事務中的所有操作要么都是成功,要么都失敗
-
c) 隔離性(Isolation)
一個事務不會影響其他事務的運行。
-
d) **持久性(Durability) **
在事務完成以后,該事務對數據庫所作的更改將持久地保存在數據庫之中,并不會被回滾。
如何實現事務的 ACID 特性
MySQL事務的ACID,一致性是最終目的。
保證一致性的措施有:
- **A原子性:**靠undo log來保證(異常或執行失敗后進行回滾)。
- **D持久性:**靠redo log來保證(保證當MySQL宕機或停電后,可以通過redo log最終將數據保存至磁盤中)。
- **I隔離性:**快照讀(版本鏈和ReadView)和鎖定讀(利用三種鎖)
- **C一致性:**事務的最終目的,即需要數據庫層面保證,又需要應用層面進行保證,并且MySQL底層通過兩階段提交事務保證了事務持久化時的一致性。
事務怎么做的?
InnoDB存儲引擎: 提供了一組用來記錄事務性活動的日志文件。
- 事務開啟了:
insert; update; delete; insert;。。。。。。
- 事務結束了!
這些都會被記錄到事務性活動的日志文件中。
在事務執行的過程中,我們可以提交事務,也可以回滾事務。
-
提交事務
清空事務性的日志文件、將數據全部持久化到數據庫。 提交事務意味著成功的結束事務
-
回滾事務
之前的DML(增、刪、改)操作全部撤銷,清空事務性活動的日志文件。回滾事務意味著失敗的結束事務
事務中存在一些概念:
- a) 事務(Transaction):一批操作(一組 DML)
- b) 開啟事務(Start Transaction)
- c) 回滾事務(rollback) ---- 只能回滾到上一次的提交點.
- d) 提交事務(commit)
- e) SET AUTOCOMMIT:禁用或啟用事務的自動提交模式
提交事務
-
默認提交
在命令行中mysql默認自動提交事務,無法回滾。
-
關閉默認提交
在每次執行MDL語句之前,執行 即可關閉. 然后
start transaction; insert; delete; update; ......;rollback; /*回到 start transaction 之前的位置 */
事務的隔離
事務的隔離級別

- 讀-未提交
讀取數據不需要加 共享鎖,這樣就不會跟被修改的數據上的 排他鎖 沖突;
- 讀-已提交
各自事務操作,某個事務提交以后,另外的就可以查詢
讀操作需要加 共享鎖,但是在語句執行完以后釋放共享鎖;
- 可重復-讀
各自事務操作數據快照、結束事務之后才合并。一直查看的之前快照數據。
讀操作需要加 共享鎖,但是在事務提交之前并不釋放共享鎖,也就是必須等待事務執行完畢以后才釋放共享鎖;
- 串行化
是限制性最強的隔離級別,因為該級別 鎖定整個范圍的鍵,并一直持有鎖,直到事務完成。 相當于同步鎖。
索引
書的目錄 縮小查找范圍
索引被用來快速找出在一個列上用一特定值的行。沒有索引,MySQL 不得不首先以第一條記錄開始,然后讀完整個表直到它找出相關的行。表越大,花費時間越多。對于一個 有序字段,可以運用二分查找(Binary Search),這就是為什么性能能得到本質上的提高。MYISAM 和 INNODB 都是用 B+Tree 作為索引結構 (主鍵,unique 都會默認的添加索引)
優點
- 通過創建唯一索引,可以保證數據庫表中每一行數據的唯一性。
- 可以大大加快數據的查詢速度,這也是創建索引的主要原因。
- 在使用分組和排序子句進行數據查詢時,也可以顯著減少查詢中分組和排序的時間。
缺點
- 索引需要占磁盤空間,除了數據表占數據空間之外,每一個索引還要占一定的物理空間,如果有大量的索引,索引文件可能比數據文件更快達到最大文件尺寸。
- 當對表中的數據進行增加、刪除和修改的時候,索引也要動態地維護,這樣就降低了數據的維護速度。
實現原理
利用主鍵或者某一列的數據作為key,構建一個B+樹,樹中存儲數據具體的物理位置,以供訪問。
MySQL使用B+樹作為主要的索引實現機制。B+樹是一種平衡樹數據結構,它優化了傳統B樹的性能,并且適用于磁盤存儲。下面是MySQL索引的實現原理:
- B+樹結構:MySQL使用B+樹作為索引的底層數據結構。B+樹是一種多叉樹,具有平衡的特性,可以高效地支持范圍查詢和按順序遍歷。
- 索引類型:MySQL支持多種索引類型,包括聚集索引(Clustered Index)和非聚集索引(Non-Clustered Index)。聚集索引決定了表中數據的物理排序順序,而非聚集索引則是基于聚集索引的副本,它們分別適用于不同的查詢需求。
- 索引鍵選擇:在創建索引時,可以選擇一個或多個列作為索引鍵(Index Key)。索引鍵的選擇對查詢性能有重要影響,通常建議選擇常用于查詢條件和連接操作的列作為索引鍵。
- 索引維護:當插入、更新或刪除表中的數據時,索引也需要進行相應的維護,以保持數據的一致性和索引的有效性。這包括插入新的索引項、刪除舊的索引項、更新索引鍵值等操作。
- 索引選擇器(Index Selector):MySQL的查詢優化器(Query Optimizer)根據查詢條件和可用索引的統計信息選擇最合適的索引來執行查詢。優化器會考慮多個因素,如索引選擇性、查詢成本等。
- 覆蓋索引:當索引包含了查詢所需的所有列時,稱之為覆蓋索引(Covering Index)。覆蓋索引可以避免回表(Table Lookup)操作,提高查詢性能。
創建索引
如經常根據 sal 進行查詢,并且遇到了性能瓶頸,首先查看程序是否存算法問題,再考慮對 sal 建立索引。
create unique index 索引名 on 表名(列名);
create unique index u_ename on emp(ename);create index test_index on emp (sal);
刪除索引
drop index u_ename on emp(ename);
alter table 表名 add unique index 索引名 (列名);
查看索引
show index from emp;
使用索引
explain select sal from emp where sal > 1500;
索引失效的情況
使用函數操作:當在索引列上使用函數操作時,索引可能會失效。例如,考慮以下查詢:
explain SELECT * FROM table WHERE UPPER(column) = 'VALUE';在這個例子中,如果
column是一個索引列,使用UPPER()函數會導致索引失效,因為MySQL無法利用索引的有序性來進行快速篩選。使用OR操作符連接條件:當使用OR操作符連接多個條件時,索引可能會失效。例如:
explain SELECT * FROM table WHERE column1 = 'VALUE1' OR column2 = 'VALUE2';如果
column1和column2都是索引列,MySQL可能無法同時使用這兩個索引,而是選擇全表掃描。使用NOT操作符:在某些情況下,使用
NOT操作符可能導致索引失效。例如:explain SELECT * FROM table WHERE NOT column = 'VALUE';這會使MySQL無法使用索引進行快速篩選,而是進行全表掃描。
LIKE查詢使用通配符前綴:當使用LIKE查詢時,如果通配符(%)出現在查詢的開頭,索引可能無法生效。例如:
explain SELECT * FROM table WHERE column LIKE '%VALUE';這會導致MySQL無法使用索引進行前綴匹配,而是進行全表掃描。
使用函數索引:在某些情況下,將函數應用于索引列本身可能導致索引失效。例如,創建了一個函數索引:
CREATE INDEX idx_func ON table (UPPER(column));在這種情況下,查詢中直接使用
column而不是UPPER(column)可能無法使用該函數索引。
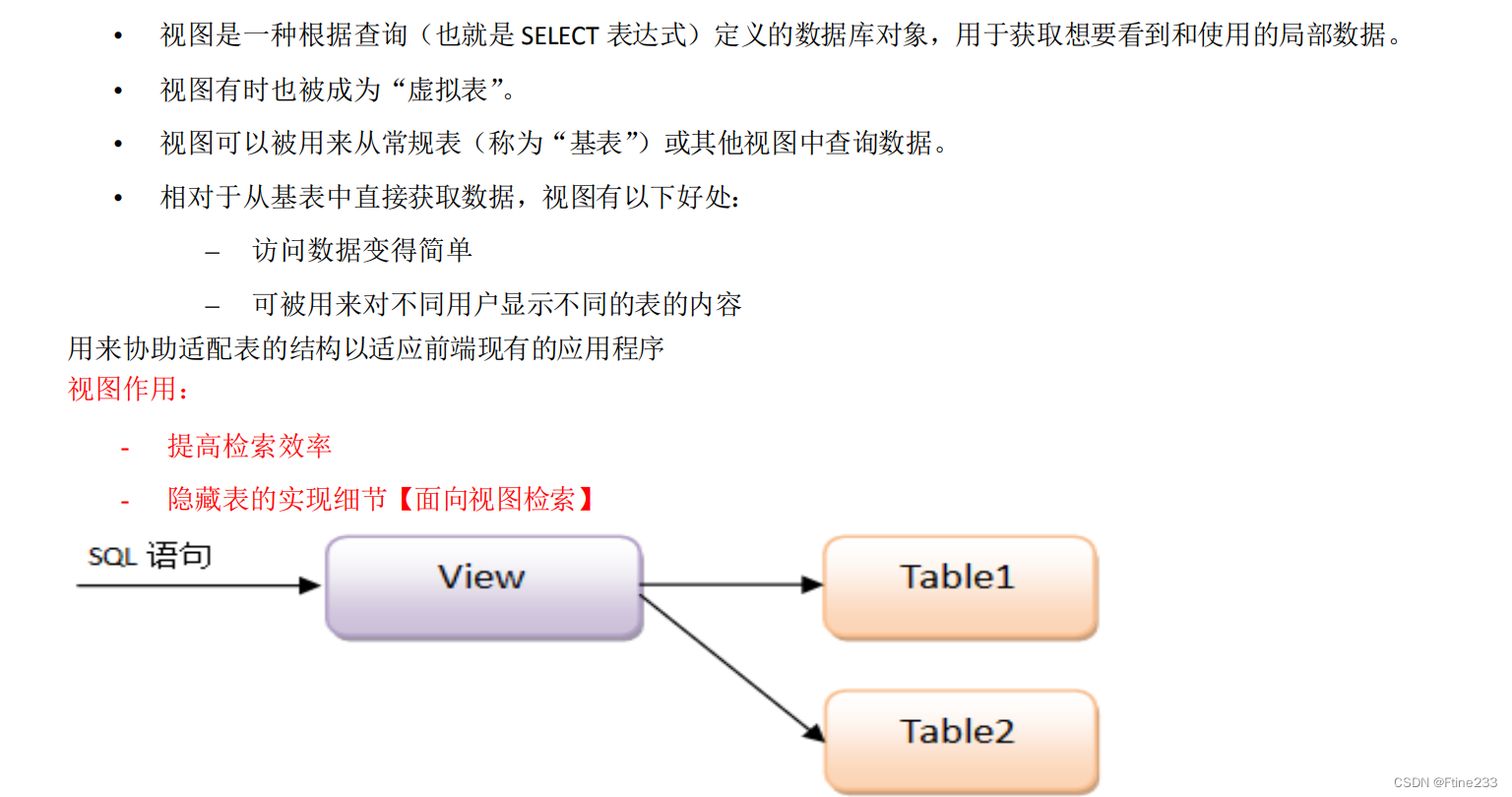
視圖
create view test_view as
select * from table_test;drop view test_view;
MySQL視圖在計算機中以文件存在的,可以把其表格一樣看待。
簡化查詢:視圖可以隱藏復雜的查詢邏輯和數據結構,提供一個簡單的接口供用戶查詢。通過將多個表的關聯查詢、過濾條件和計算邏輯封裝在一個視圖中,用戶可以使用簡單的SELECT語句查詢視圖,而無需了解底層的復雜性。
數據安全性:視圖可以用于限制用戶對數據的訪問權限。通過在視圖上設置適當的權限,可以控制用戶只能訪問視圖中指定的列或行,而不是直接訪問基礎表。這提供了一種更細粒度的數據安全性控制機制。
數據重用和模塊化:視圖可以被視為可重用的查詢模塊。一旦定義了視圖,它可以在多個查詢中使用,避免了在每個查詢中重復編寫相同的查詢邏輯。這樣可以提高開發效率,并且在需要修改查詢邏輯時,只需修改視圖定義而不影響使用該視圖的查詢。
數據邏輯抽象:視圖可以將底層數據結構進行邏輯抽象,使得數據的表現形式更符合業務需求。通過對基礎表進行聚合、過濾、連接等操作,視圖可以提供更易于理解和使用的數據模型。
性能優化:在某些情況下,使用視圖可以提高查詢性能。通過將復雜的查詢邏輯預先計算并緩存為視圖,可以減少每次查詢時的計算量,提高查詢效率。









)



)

:從零構建擴散模型)

(片元著色器))
)
)