????????需要編寫自定義集成層來滿足數據管道中的特定要求?了解如何使用 Go 通過 Kafka 和 OpenSearch 實現此目的。
????????可擴展的數據攝取是OpenSearch等大規模分布式搜索和分析引擎的一個關鍵方面。構建實時數據攝取管道的方法之一是使用Apache Kafka。它是一個開源事件流平臺,用于處理高數據量(和速度),并與包括關系數據庫和 NoSQL 數據庫在內的各種來源集成。例如,規范用例之一是異構系統(源組件)之間的數據實時同步,以確保 OpenSearch 索引是最新的,并且可以通過儀表板和可視化用于分析或使用下游應用程序。
????????這篇博文將介紹如何創建數據管道,其中寫入 Apache Kafka 的數據被引入 OpenSearch。我們將使用Amazon OpenSearch Serverless和Amazon Managed Streaming for Apache Kafka (Amazon MSK) Serverless。Kafka Connect非常適合此類需求。它為 OpenSearch 和 ElasticSearch 提供接收器連接器(如果您選擇將 ElasticSearch OSS 引擎與 Amazon OpenSearch 結合使用,則可以使用該連接器)。但有時,有特定的要求或原因可能需要使用定制解決方案。
????????例如,您可能正在使用 Kafka Connect 不支持的數據源(很少見,但可能會發生),并且不想從頭開始編寫數據源。或者,這可能是一次性集成,您想知道是否值得花費精力來設置和配置 Kafka Connect。也許還有其他問題,例如許可等。
????????值得慶幸的是,Kafka 和 OpenSearch 提供了多種編程語言的客戶端庫,使您可以編寫自己的集成層。這正是本博客所涵蓋的內容!我們將利用自定義Go應用程序通過Kafka和OpenSearch的 Go 客戶端來攝取數據。
你將學習:
- 概述如何設置所需的 AWS 服務:OpenSearch Serverless、MSK Serverless、AWS Cloud9 以及 IAM 策略和安全配置
- 應用程序的高級演練
- 啟動并運行數據攝取管道
- 如何在 OpenSearch 中查詢數據
在深入討論之前,我們先簡要概述一下 OpenSearch Serverless 和 Amazon MSK Serverless。
Amazon OpenSearch 無服務器和 Amazon MSK 無服務器簡介
OpenSearch 是一個開源搜索和分析引擎,用于日志分析、實時監控和點擊流分析。Amazon OpenSearch Service 是一項托管服務,可簡化 AWS 中 OpenSearch 集群的部署和擴展。
Amazon OpenSearch Service 支持 OpenSearch 和舊版 Elasticsearch OSS(直至 7.10,該軟件的最終開源版本)。創建集群時,您可以選擇使用哪個搜索引擎。
您可以創建一個 OpenSearch Service 域(與 OpenSearch 集群同義)來表示一個集群,其中每個 Amazon EC2 實例充當一個節點。然而,OpenSearch Serverless 通過為 OpenSearch 服務提供按需無服務器配置來消除操作復雜性。它使用索引集合來支持特定的工作負載,與傳統集群不同,它分離了索引和搜索組件,并使用Amazon S3作為索引的主存儲。該架構支持獨立擴展搜索和索引功能。
您可以參考比較 OpenSearch Service 和 OpenSearch Serverless中的詳細信息。
Amazon MSK(Apache Kafka 的托管流)是一項完全托管的服務,用于使用 Apache Kafka 處理流數據。它處理集群管理操作,例如創建、更新和刪除。您可以使用標準 Apache Kafka 數據操作來生成和使用數據,而無需修改應用程序。它支持開源 Kafka 版本,確保與現有工具、插件和應用程序的兼容性。
MSK Serverless 是 Amazon MSK 中的一種集群類型,無需手動管理和擴展集群容量。它根據需求自動配置和擴展資源,并負責主題分區管理。采用即用即付定價模式,您只需為實際使用量付費。MSK Serverless 非常適合需要靈活、自動擴展流容量的應用程序。
讓我們首先討論高級應用程序架構,然后再討論架構注意事項。
應用概述和關鍵架構注意事項
這是應用程序架構的簡化版本,概述了組件以及它們如何相互交互。
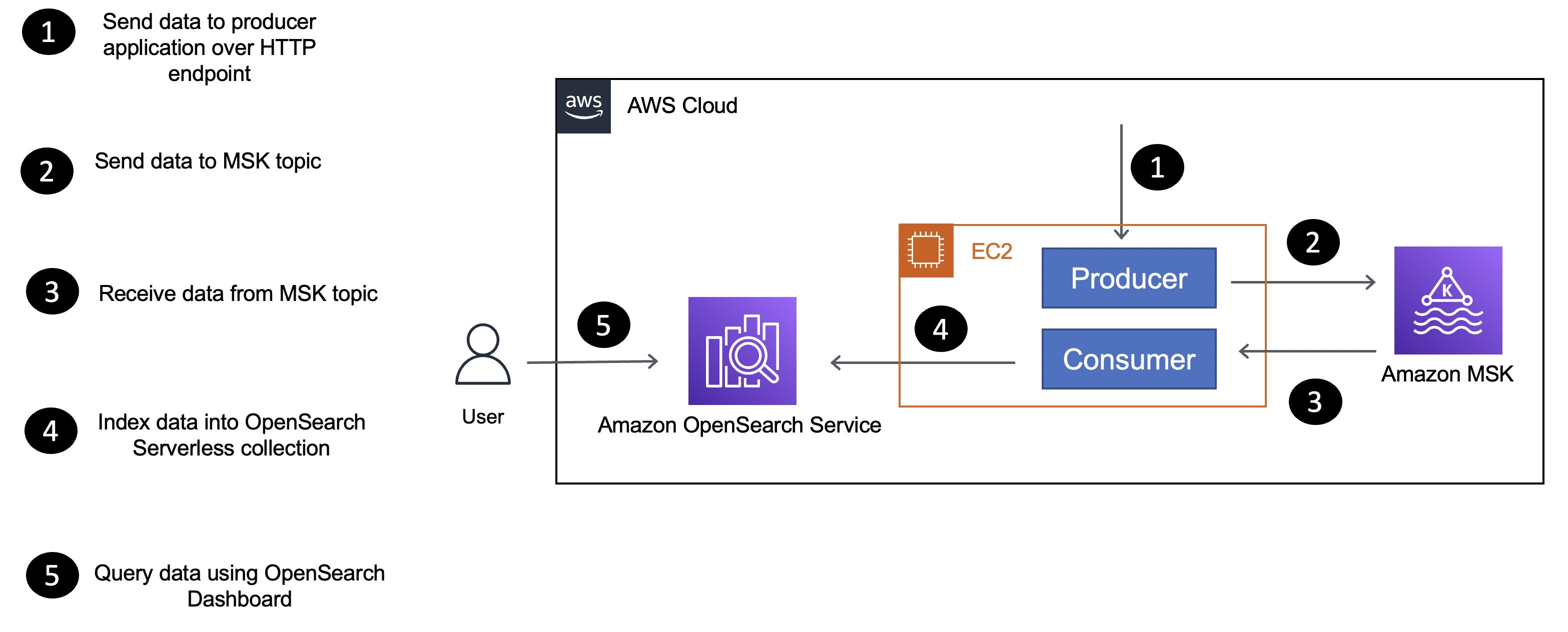
該應用程序由生產者和消費者組件組成,它們是部署到實例的 Go 應用程序EC2:
- 顧名思義,生產者將數據發送到 MSK Serverless 集群。
- 消費者應用程序
movie從 MSK Serverless 主題接收數據(信息),并使用 OpenSearch Go 客戶端對movies集合中的數據進行索引。
注重簡單性
值得注意的是,該博客文章已針對簡單性和易于理解進行了優化,因此該解決方案并未針對運行生產工作負載進行調整。以下是一些已進行的簡化:
- 生產者和消費者應用程序在同一計算平臺(EC2 實例)上運行。
- 有一個消費者應用程序實例處理來自 MSK 主題的數據。但是,您可以嘗試運行使用者應用程序的多個實例,并查看數據如何在實例之間分布。
- 不是使用 Kafka CLI 來生成數據,而是用 Go 編寫自定義生成器應用程序以及 REST 端點來發送數據。這演示了如何用 Go 編寫 Kafka 生產者應用程序并模仿 Kafka CLI。
- 使用的數據量很小。
- OpenSearch Serverless 集合具有公共訪問類型。
對于生產工作負載,您應該考慮以下一些事項:
根據數據量和可擴展性要求為您的消費者應用程序選擇合適的計算平臺 - 下文將詳細介紹。
為您的 OpenSearch Serverless 集合選擇?VPC訪問類型。
考慮使用Amazon OpenSearch Ingestion創建數據管道。
如果您仍然需要部署自定義應用程序來構建從 MSK 到 OpenSearch 的數據管道,以下是您可以選擇的計算選項范圍:
容器:您可以將消費者應用程序打包為 Docker 容器(Dockerfile可在 GitHub 存儲庫中獲取)并將其部署到Amazon EKS或Amazon ECS。
如果您將應用程序部署到 Amazon EKS,您還可以考慮使用KEDA根據 MSK 主題中的消息數量自動擴展您的消費者應用程序。
無服務器:還可以使用MSK 作為 AWS Lambda 函數的事件源。您可以將消費者應用程序編寫為 Lambda 函數,并將其配置為由 MSK 事件觸發,或者在AWS Fargate上運行。
由于生產者應用程序是 REST API,因此您可以將其部署到 AWS App Runner。
最后,您可以利用Amazon EC2 Auto Scaling 組為您的消費者應用程序自動擴展 EC2 隊列。
有足夠的材料討論如何使用基于 Java 的 Kafka 應用程序通過IAM 與 MSK Serverless連接。
讓我們繞道了解一下 Go 的工作原理。
Go 客戶端應用程序如何使用 IAM 通過 MSK Serverless 進行身份驗證?
MSK Serverless 需要 IAM 訪問控制來處理 MSK 集群的身份驗證和授權。這意味著您的 MSK 客戶端應用程序(在本例中為生產者和消費者)必須使用 IAM 向 MSK 進行身份驗證,基于此它們將被允許或拒絕特定的 Apache Kafka 操作。
好處是franz-goKafka 客戶端庫支持 IAM 身份驗證。以下是消費者應用程序的片段,展示了它在實踐中的工作原理:
func init() {
//......cfg, err = config.LoadDefaultConfig(context.Background(), config.WithRegion("us-east-1"), config.WithCredentialsProvider(ec2rolecreds.New()))creds, err = cfg.Credentials.Retrieve(context.Background())
//....func initializeKafkaClient() {opts := []kgo.Opt{kgo.SeedBrokers(strings.Split(mskBroker, ",")...),kgo.SASL(sasl_aws.ManagedStreamingIAM(func(ctx context.Context) (sasl_aws.Auth, error) {return sasl_aws.Auth{AccessKey: creds.AccessKeyID,SecretKey: creds.SecretAccessKey,SessionToken: creds.SessionToken,UserAgent: "msk-ec2-consumer-app",}, nil})),
//.....
基礎設施設置
本節將幫助您設置以下組件:
- 所需的 IAM 角色
- MSK 無服務器集群
- OpenSearch 無服務器集合
- 用于運行應用程序的 AWS Cloud9 EC2 環境
MSK 無服務器集群
您可以按照本文檔使用 AWS 控制臺設置 MSK 無服務器集群。執行此操作后,記下以下集群信息:VPC、子網、安全組(“屬性”選項卡)和集群端點(單擊“查看客戶端信息”)。
應用程序 IAM 角色
本教程需要不同的 IAM 角色。
首先創建 IAM 角色來執行后續步驟,并按照步驟 1:配置權限(在 Amazon OpenSearch 文檔中)的權限使用 OpenSearch Serverless。
為客戶端應用程序創建另一個 IAM 角色,該角色將與 MSK Serverless 集群交互,并使用 OpenSearch Go 客戶端對 OpenSearch Serverless 集合中的數據建立索引。創建如下內聯 IAM 策略 - 確保替換所需的值。
{"Version": "2012-10-17","Statement": [{"Effect": "Allow","Action": ["kafka-cluster:*"],"Resource": ["<ARN of the MSK Serverless cluster>","arn:aws:kafka:us-east-1:<AWS_ACCOUNT_ID>:topic/<MSK_CLUSTER_NAME>/*","arn:aws:kafka:us-east-1:AWS_ACCOUNT_ID:group/<MSK_CLUSTER_NAME>/*"]},{"Effect": "Allow","Action": ["aoss:APIAccessAll"],"Resource": "*"}]
}使用以下信任策略:
{"Version": "2012-10-17","Statement": [{"Effect": "Allow","Principal": {"Service": "ec2.amazonaws.com"},"Action": "sts:AssumeRole"}]
}最后,您將向其附加 OpenSearch Serverless數據訪問策略的另一個 IAM 角色- 下一步將詳細介紹這一點。
OpenSearch 無服務器集合
使用文檔創建 OpenSearch Serverless 集合。在遵循步驟 2:創建集合中的第 8 點時,請確保配置兩個數據策略;即,在上一節的步驟 2 和 3 中創建的每個 IAM 角色。
注意:出于本教程的目的,我們選擇公共訪問類型。建議為生產工作負載選擇VPC。
AWS Cloud9 EC2 環境
使用此文檔創建 AWS Cloud9 EC2 開發環境。確保使用與 MSK Serverless 集群相同的VPC。
完成后,您需要執行以下操作: 打開 Cloud9 環境。在EC2 實例下,單擊管理 EC2 實例。在 EC2 實例中,導航到安全性并記下附加的安全組。
打開與 MSK Serverless 集群關聯的安全組并添加入站規則以允許 Cloud9 EC2 實例連接到它。選擇Cloud9 EC2實例的安全組作為源,9098作為端口,選擇TCP協議。
您現在已準備好運行該應用程序!
選擇 Cloud9 環境并選擇Open in Cloud9以啟動 IDE。打開終端窗口,克隆 GitHub 存儲庫,然后將目錄更改為該文件夾。
git clone https://github.com/build-on-aws/opensearch-using-kafka-golangcd opensearch-using-kafka-golang啟動生產者應用程序:
cd msk-producerexport MSK_BROKER=<enter MSK Serverless cluster endpoint>
export MSK_TOPIC=moviesgo run main.go您應該在終端中看到以下日志:
MSK_BROKER <MSK Serverless cluster endpoint>
MSK_TOPIC movies
starting producer app
http server ready要將數據發送到 MSK 無服務器集群,請使用 bash 腳本,該腳本將調用HTTP您剛剛啟動的應用程序公開的端點,并使用movies.txt以下格式提交電影數據(來自文件):JSONcurl
./send-data.sh在生產者應用程序終端日志中,您應該看到類似于以下內容的輸出:
producing data to topic
payload {"directors": ["Joseph Gordon-Levitt"], "release_date": "2013-01-18T00:00:00Z", "rating": 7.4, "genres": ["Comedy", "Drama"], "image_url": "http://ia.media-imdb.com/images/M/MV5BMTQxNTc3NDM2MF5BMl5BanBnXkFtZTcwNzQ5NTQ3OQ@@._V1_SX400_.jpg", "plot": "A New Jersey guy dedicated to his family, friends, and church, develops unrealistic expectations from watching porn and works to find happiness and intimacy with his potential true love.", "title": "Don Jon", "rank": 1, "running_time_secs": 5400, "actors": ["Joseph Gordon-Levitt", "Scarlett Johansson", "Julianne Moore"], "year": 2013}
record produced successfully to offset 2 in partition 0 of topic moviesproducing data to topic
payload {"directors": ["Ron Howard"], "release_date": "2013-09-02T00:00:00Z", "rating": 8.3, "genres": ["Action", "Biography", "Drama", "Sport"], "image_url": "http://ia.media-imdb.com/images/M/MV5BMTQyMDE0MTY0OV5BMl5BanBnXkFtZTcwMjI2OTI0OQ@@._V1_SX400_.jpg", "plot": "A re-creation of the merciless 1970s rivalry between Formula One rivals James Hunt and Niki Lauda.", "title": "Rush", "rank": 2, "running_time_secs": 7380, "actors": ["Daniel Br\u00c3\u00bchl", "Chris Hemsworth", "Olivia Wilde"], "year": 2013}
record produced successfully to offset 4 in partition 1 of topic movies.....出于本教程的目的并使其簡單易懂,數據量已特意限制為 1500 條記錄,并且腳本在將每條記錄發送到生產者后有意休眠 1 秒。您應該能夠輕松地跟隨。
當生產者應用程序忙于向movies主題發送數據時,您可以啟動消費者應用程序,開始處理來自 MSK Serverless 集群的數據,并將其在 OpenSearch Serverless 集合中建立索引。
cd msk-consumerexport MSK_BROKER=<enter MSK Serverless cluster endpoint>
export MSK_TOPIC=movies
export OPENSEARCH_INDEX_NAME=movies-index
export OPENSEARCH_ENDPOINT_URL=<enter OpenSearch Serverless endpoint>go run main.go您應該在終端中看到以下輸出,這表明它確實已開始從 MSK Serverless 集群接收數據并在 OpenSearch Serverless 集合中對其建立索引。
using default value for AWS_REGION - us-east-1
MSK_BROKER <MSK Serverless cluster endpoint>
MSK_TOPIC movies
OPENSEARCH_INDEX_NAME movies-index
OPENSEARCH_ENDPOINT_URL <OpenSearch Serverless endpoint>
using credentials from: EC2RoleProvider
kafka consumer goroutine started. waiting for records
paritions ASSIGNED for topic movies [0 1 2]got record from partition 1 key= val={"directors": ["Joseph Gordon-Levitt"], "release_date": "2013-01-18T00:00:00Z", "rating": 7.4, "genres": ["Comedy", "Drama"], "image_url": "http://ia.media-imdb.com/images/M/MV5BMTQxNTc3NDM2MF5BMl5BanBnXkFtZTcwNzQ5NTQ3OQ@@._V1_SX400_.jpg", "plot": "A New Jersey guy dedicated to his family, friends, and church, develops unrealistic expectations from watching porn and works to find happiness and intimacy with his potential true love.", "title": "Don Jon", "rank": 1, "running_time_secs": 5400, "actors": ["Joseph Gordon-Levitt", "Scarlett Johansson", "Julianne Moore"], "year": 2013}
movie data indexed
committing offsets
got record from partition 2 key= val={"directors": ["Ron Howard"], "release_date": "2013-09-02T00:00:00Z", "rating": 8.3, "genres": ["Action", "Biography", "Drama", "Sport"], "image_url": "http://ia.media-imdb.com/images/M/MV5BMTQyMDE0MTY0OV5BMl5BanBnXkFtZTcwMjI2OTI0OQ@@._V1_SX400_.jpg", "plot": "A re-creation of the merciless 1970s rivalry between Formula One rivals James Hunt and Niki Lauda.", "title": "Rush", "rank": 2, "running_time_secs": 7380, "actors": ["Daniel Br\u00c3\u00bchl", "Chris Hemsworth", "Olivia Wilde"], "year": 2013}
movie data indexed
committing offsets.....該過程完成后,您應該1500在 OpenSearch Serverless 集合中為電影建立索引。不過,您不必等待它完成。一旦有了數百條記錄,您就可以繼續導航到OpenSearch 儀表板中的開發工具來執行以下查詢。
在 OpenSearch 中查詢電影數據
運行簡單查詢
讓我們從一個簡單的查詢開始,列出索引中的所有文檔(不帶任何參數或過濾器)。
GET movies-index/_search僅獲取特定字段的數據
默認情況下,搜索請求會檢索對文檔建立索引時提供的整個 JSON 對象。使用該_source選項從選定字段檢索源。例如,要僅檢索title、plot和genres字段,請運行以下查詢:
GET movies-index/_search
{"_source": {"includes": ["title","plot","genres"]}
}獲取數據以與術語查詢的精確搜索術語匹配
您可以使用術語查詢來實現此目的。例如,要搜索字段christmas中包含該術語的電影title,請運行以下查詢:
GET movies-index/_search
{"query": {"term": { "title": {"value": "christmas"}}}
}**將選擇性字段選擇與術語查詢相結合。
您可以使用此查詢僅檢索某些字段,但對特定術語感興趣:
GET movies-index/_search
{"_source": {"includes": ["title","actors"]},"query": {"query_string": {"default_field": "title","query": "harry"}}
}聚合
使用聚合根據特定字段中的值分組來計算匯總值。例如,您可以匯總ratings、 、genre和 等字段year,以根據這些字段的值搜索結果。通過聚合,我們可以回答這樣的問題:“每種類型有多少部電影?”
GET movies-index/_search
{"size":0,"aggs": {"genres": {"terms":{"field": "genres.keyword"}}}
}結論
回顧一下,您部署了一個管道,使用 Kafka 將數據提取到 OpenSearch Serverless 中,然后以不同的方式對其進行查詢。在此過程中,您還了解了生產工作負載需要記住的架構注意事項和計算選項,以及使用基于 Go 的 Kafka 應用程序和 MSK IAM 身份驗證。我還建議閱讀文章在 Go 中為 Amazon OpenSearch 構建 CRUD 應用程序,特別是如果您正在尋找以通過 Go SDK 執行 OpenSearch 操作為中心的教程。
)



)

:從零構建擴散模型)

(片元著色器))
)
)

)






