基于用戶的協同過濾算法(UserCF)
因為我寫的是博客項目,博客數量可能比用戶數量還多
所以選擇基于用戶的協同過濾算法
重要思想
當要向用戶u進行推薦時,我們先找出與用戶u最相似的幾個用戶,再從這幾個用戶的喜歡的物品中預測出用戶u最喜歡的幾個物品并且用戶u沒有交互過的物品進行推薦
聽起來好像很麻煩,實則不然,搞清楚思路后就是簡單的套公式而已,我們就根據這個基本思想來進行所有的操作,就是說,這個思想會貫穿始終。
完整思路
步驟一:首先,我們要找出與用戶u最相似的幾個用戶
那我們是不是要知道2個用戶之間的相似度是怎么計算的,然后根據其他所有用戶與用戶u的相似度進行一個排序,這樣最前面k位就是與u最相似的k個用戶。
這里我給出相似度公式---Jaccard公式
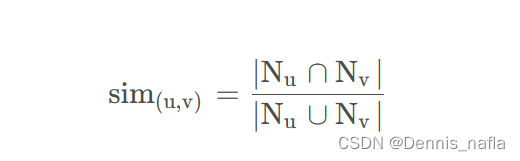
解釋
- sim( u , v ) 是集合 u?和集合 v?的 Jaccard 相似度。
- |Nu∩ Nv| 表示集合 u?和集合 v?的交集的大小。
- |Nu∪ Nv| 表示集合 u?和集合 v?的并集的大小。
那么這些集合的含義又是什么?
這些集合表示的是用戶所交互過的物品的集合
比如Nu就是用戶u所交互過的物品的集合
什么是交互就不用我說了吧,比如我對某篇博客進行點贊,或者收藏,都是交互,其實點踩也是,但是我們是在做推薦系統,所以只要正反饋。
簡單地說,這個公式的意思是:
用戶u與用戶v之間的相似度,是用戶 u和用戶 v?共同交互過的物品的數量
除以根號下(用戶 u的交互過的物品總數*用戶 v交互過的物品總數)
所以根據公式:我們需要得到2個東西:
? 1.每2個用戶之間共同交互過的物品數量(又叫做協同過濾矩陣)
? 2.每個用戶所交互過的物品總數量
1.先來求第一個條件--每2個用戶之間共同交互過的物品數量
正常思路就是先得到每個用戶交互過的物品的集合,再建立倒排表,表示每個博客被哪些用戶交互過,這是很關鍵的一步。
? 這是我的從數據庫取數據的操作,你們根據自己的實際情況來獲取數據即可,
我的用戶id是賬號是String類型,博客Id就是它在博客表中的主鍵id,是int
//1.將user表里面所有用戶查出來//2.遍歷所有用戶,將點贊表,收藏表里面該用戶的記錄中的博客id都找出來,放在一個Set//每遍歷完一個用戶就存Map里面List<User> users = userMapper.getAllUser();Map<String,Set<Integer>>userToBlogs = new HashMap<>();Map<String, Integer> num = new HashMap<>();for(User user:users){//這個Set存放當前遍歷到的用戶所交互過的所有博客的idSet<Integer> blogIds = new HashSet<>();//下面這個blogIdsFromUpvote是用戶所有點贊過的博客idList<Integer> blogIdsFromUpvote = upvoteMapper.getBlogIdByUserId(user.getAccount());blogIds.addAll(blogIdsFromUpvote);//下面這個blogIdsFromCollect是用戶所有收藏了的博客idList<Integer> blogIdsFromCollect = collectMapper.getAllBlogIdByUserId(user.getAccount());blogIds.addAll(blogIdsFromCollect);userToBlogs.put(user.getAccount(),blogIds);num.put(user.getAccount(),blogIds.size());}不管過程怎么樣,反正最終只需要得到2個Map:
?1.Map<String,Set<Integer>>userToBlogs = new HashMap<>();
這個Map存的是用戶ID所對應的一個交互過的博客id的Set集合,Set有自動去重功能。
2.Map<String, Integer> num = new HashMap<>();
這個Map存的是每個用戶ID對應的該用戶交互過的物品總數。
?num到后面計算jaccard相似度的時候才用,現在只需要根據userToBlogs來建立倒排表,表示每個博客被哪些用戶交互過。
也很簡單,遍歷userToBlogs這個Map的每個鍵值對,在嵌套內循環遍歷每個鍵值對中的Set<Integer>,也就是用戶交互過的物品集合,將每個遍歷到的物品和當前對應的鍵(也就是當前遍歷到的用戶)存進倒排表,就是這樣一個Map,表示每個物品所對應的交互過這個物品的用戶的集合:
Map<Integer, Set<String>> itemToUsers
代碼:
package com.mycsdn.util.UserCF;import com.mycsdn.pojo.Blog;import java.util.*;public class InvertedIndex {public static Map<Integer, Set<String>> getItemToUsers(Map<String, Set<Integer>> userToItems) {Map<Integer, Set<String>> ItemToUsers = new HashMap<>();for (Map.Entry<String, Set<Integer>> entry : userToItems.entrySet()) {String userId = entry.getKey();Set<Integer> blogs = entry.getValue();for (Integer blogId : blogs) {//如果當前博客對應的用戶集合中沒有用戶,就新建一個Set再把當前用戶加進去,如果有的話就之間加進去Set<String> users = ItemToUsers.getOrDefault(blogId, new HashSet<>());users.add(userId);ItemToUsers.put(blogId, users);}}return ItemToUsers;}
}
現在得到了倒排表,就是這樣一個Map,表示每個物品所對應的交互過這個物品的用戶的集合:
Map<Integer, Set<String>> itemToUsers
開始求協同過濾矩陣
我們需要根據這個倒排表來求出協同過濾矩陣,也就是一個表示每2個用戶之間共同交互過的物品數量
Map<String, Map<String, Integer>> CFMatrix = new HashMap<>();
String表示當前用戶,對應的 Map<String, Integer>表示其他各個用戶以及與當前用戶的共同交互過的物品的數量
1.遍歷這個倒排表,嵌套內循環遍歷每個物品對應的用戶集合的每個用戶
2.對于遍歷到的每個用戶,通過遍歷其他所有用戶,將當前用戶與其他用戶的共同交互物品數加1
代碼:
package com.mycsdn.util.UserCF;import java.util.HashMap;
import java.util.Map;
import java.util.Set;public class GetCFMatrix {//得到的協同過濾矩陣是對于用戶A,其他與A有共同交互過的博客的用戶ID和共同交互過的博客的數量public static Map<String, Map<String, Integer>> getCFMatrix( Map<Integer, Set<String>> itemToUsers) {Map<String, Map<String, Integer>> CFMatrix = new HashMap<>();System.out.println("開始構建協同過濾矩陣....");// 遍歷所有的物品,統計用戶兩兩之間交互的物品數for (Map.Entry<Integer, Set<String>> entry : itemToUsers.entrySet()) {Integer item = entry.getKey();Set<String> users = entry.getValue();// 首先統計每個用戶交互的物品個數for (String u : users) {//遍歷所有該博客對應的交互過的用戶// 統計每個用戶與其它用戶共同交互的物品個數if (!CFMatrix.containsKey(u)) {CFMatrix.put(u, new HashMap<>());}for (String v : users) {//再次遍歷所有用戶,對不是u的其他用戶進行操作if (!v.equals(u)) {if (!CFMatrix.get(u).containsKey(v)) {CFMatrix.get(u).put(v, 0);}CFMatrix.get(u).put(v, CFMatrix.get(u).get(v) + 1);}}}}//還要返回num這個Mapreturn CFMatrix;}}現在得到了協同過濾矩陣,也就是每2個用戶之間的共同交互物品數:
Map<String, Map<String, Integer>> CFMatrix?
2.再來求第二個條件--每個用戶所交互過的物品總數量
這個已經在第一遍順手得出來了,就是這個num。
Map<String, Integer> num = new HashMap<>();
有了這2個條件后,就可以使用jaccard公式了
步驟二:根據協同過濾矩陣和每個用戶所交互的物品總數求相似度-jaccard公式
很簡單,直接套公式
package com.mycsdn.util.UserCF;import java.util.HashMap;
import java.util.Map;public class SimMatrix {public static Map<String, Map<String, Double>> getSimMatrix(Map<String, Map<String, Integer>> CFMatrix, Map<String, Integer> num) {Map<String, Map<String, Double>> sim =new HashMap<>();System.out.println("構建用戶相似度矩陣....");for (Map.Entry<String, Map<String, Integer>> entry : CFMatrix.entrySet()) {//遍歷協同過濾矩陣,遍歷每個鍵值對String u = entry.getKey();Map<String, Integer> otherUser = entry.getValue();for (Map.Entry<String, Integer> userScore : otherUser.entrySet()) {String v = userScore.getKey();int score = userScore.getValue();if(!sim.containsKey(u)){sim.put(u,new HashMap<>());}sim.get(u).put(v, CFMatrix.get(u).get(v) / Math.sqrt(num.get(u) * num.get(v)));}}return sim;}
}
現在得到了?Map<String, Map<String, Double>> sim =new HashMap<>();
表示當前用戶對應的其他用戶以及其他用戶與當前用戶的相似度
接下來我們只需要取前k位用戶,遍歷這些用戶的交互過的物品但是被推薦用戶還沒有交互過的物品進行計分
分數就是(用戶相似度 *物品分數),這個物品分數因為我們博客項目是隱式計分,也就是沒有對哪篇博客進行過打分,所以交互過的博客都是1分。
也就是說,每篇博客的推薦指數就是被交互過的用戶的相似度之和?
代碼:
package com.mycsdn.util.UserCF;import java.util.*;public class Recommend {public static Set<Integer> recommendForUser(Map<String, Map<String, Double>> sim,Map<String, Set<Integer>> valUserItem,int K, int N, String targetUser) {System.out.println("給測試用戶進行推薦....");Map<Integer, Double> itemRank = new HashMap<>();if (valUserItem.containsKey(targetUser)) {Set<Integer> items = valUserItem.get(targetUser);// sim[u] 的格式為 {user_id: similarity,....} // 按照相似度進行排序,然后取前 K 個List<Map.Entry<String, Double>> sortedSim = new ArrayList<>(sim.get(targetUser).entrySet());Collections.sort(sortedSim, new Comparator<Map.Entry<String, Double>>() {public int compare(Map.Entry<String, Double> o1, Map.Entry<String, Double> o2) {return Double.compare(o2.getValue(), o1.getValue());}});System.out.println("檢查對相似度矩陣排序后的矩陣");for (Map.Entry<String, Double> entry : sortedSim) {String item = entry.getKey();Double similarity = entry.getValue();System.out.println("用戶 " + item + ", 相似度: " + similarity);}for (int i = 0; i < K; i++) {//前k個相似度高的用戶if (i >= sortedSim.size())break;String similarUser = sortedSim.get(i).getKey();double score = sortedSim.get(i).getValue();// 找出相似用戶中有交互的物品,但當前用戶并未交互過的物品進行推薦for (int item : valUserItem.get(similarUser)) {if (valUserItem.get(targetUser).contains(item))//如果用戶已經對該物品交互過,就不用再推薦continue;itemRank.put(item, itemRank.getOrDefault(item, 0.0) + score);//這里就得到的推薦候選的一個集合}}}// 根據評分進行排序,取排名靠前的 N 個物品作為推薦列表List<Map.Entry<Integer, Double>> topNItems = new ArrayList<>(itemRank.entrySet());Collections.sort(topNItems, new Comparator<Map.Entry<Integer, Double>>() {public int compare(Map.Entry<Integer, Double> o1, Map.Entry<Integer, Double> o2) {return Double.compare(o2.getValue(), o1.getValue());}});Set<Integer> recommendedItems = new HashSet<>();for (int i = 0; i < Math.min(N, topNItems.size()); i++) {recommendedItems.add(topNItems.get(i).getKey());}return recommendedItems;}
}至此,我們已經得到了被推薦的物品的id集合
Set<Integer> recommendedItems;
只要根據id查出對應的物品再返回前端,前端進行渲染即可。
缺點:
項目建立之初,還未收集足夠的用戶信息,協同過濾算法不能為指定用戶找到合適的鄰居,從而無法向用戶提供推薦預測。
對于新注冊的用戶由于系統里沒有他們的歷史數據信息,所以協同過濾算法也無法為新用戶推薦商品。
對于冷門的商品,可能從未被評過分,比如新加進的商品或者是比較小眾的商品,它們也是不可能會被推薦給用戶的。
?
如果是在寫音樂播放器或者電影播放器,請移步基于物品的協同過濾算法



用戶刪除)




)
:下載與安裝)

)





![[Go版]算法通關村第十一關青銅——理解位運算的規則](http://pic.xiahunao.cn/[Go版]算法通關村第十一關青銅——理解位運算的規則)

