
全球各行業對 3D 世界和虛擬環境的需求呈指數級增長。3D 工作流程是工業數字化的核心,開發實時模擬來測試和驗證自動駕駛車輛和機器人,操作數字孿生來優化工業制造,并為科學發現鋪平新的道路。
如今,3D 設計和世界構建仍然是高度手動的。雖然 2D 藝術家和設計師已經擁有了輔助工具,但 3D 工作流程仍然充滿了重復、乏味的任務。
為場景創建或查找對象是一個耗時的過程,需要長期磨練的專業 3D 技能,例如建模和紋理化。正確放置對象以及將 3D 環境藝術引導至完美需要數小時的微調。
為了減少手動、重復性任務并幫助創作者和設計師專注于工作中富有創意和樂趣的方面,NVIDIA 推出了眾多 AI 項目,例如用于生成式AI/
人工智能的 變革
借助 ChatGPT,我們現在正在體驗變革,各種技術水平的個人都可以使用日常語言與高級計算平臺進行交互。大模型(LLM) 變得越來越復雜,當像 ChatGPT 這樣的用戶友好界面讓每個人都可以使用它們時,它成為歷史上增長最快的應用,推出后僅兩個月就超過了 1 億用戶。現在,每個行業都計劃利用人工智能的力量進行廣泛的應用,例如藥物發現、自主機器和虛擬助手。
最近,我們嘗試了 OpenAI 的病毒式 ChatGPT 和新的 GPT-4 大型多模態模型,以展示開發可為NVIDIA Omniverse中的虛擬世界快速生成 3D 對象的自定義工具是多么容易。OpenAI 聯合創始人 Ilya Sutskever 在GTC 2023上與 NVIDIA 創始人兼首席執行官黃仁勛的爐邊聊天中表示,與 ChatGPT 相比,GPT-4 標志著“在許多方面都有相當大的改進” 。
通過將 GPT-4 與Omniverse DeepSearch(一種智能 AI應用,能夠搜索未標記 3D 資產的海量數據庫)相結合,我們能夠快速開發一個自定義擴展,通過簡單的基于文本的提示檢索 3D 對象,并將它們自動添加到3D 場景。
AI生成3D內容
NVIDIA Omniverse(3D 應用程序開發平臺)中的這一有趣實驗向開發人員和技術美術人員展示了快速開發利用生成式 AI 來填充現實環境的自定義工具是多么容易。最終用戶只需輸入基于文本的提示即可自動生成和放置高保真對象,從而節省創建復雜場景通常所需的數小時時間。
從擴展生成的對象基于通用場景描述(USD)?SimReady 資產。SimReady 資產是物理上精確的 3D 對象,可以在任何模擬中使用,并且其行為就像在現實世界中一樣。
獲取有關 3D 場景的信息
一切都從 Omniverse 中的場景開始。用戶可以使用 Omniverse 中的鉛筆工具輕松圈出一個區域,輸入他們想要生成的房間/環境類型(例如倉庫或接待室),然后單擊一下即可創建該區域
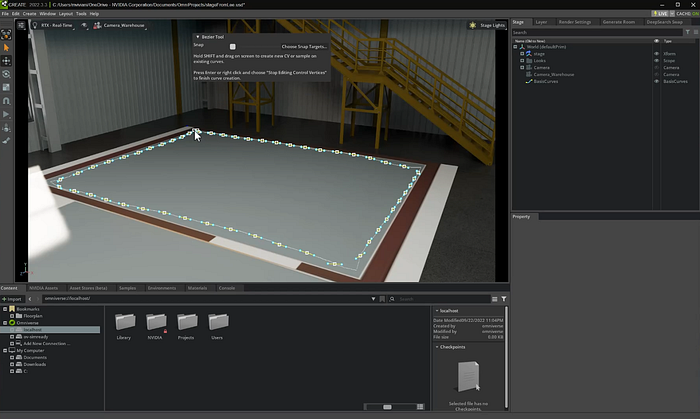 ?
?
創建 ChatGPT 提示
? ChatGPT提示由四部分組成:系統輸入、用戶輸入示例、助手輸出示例和用戶提示。
讓我們從適合用戶場景的提示的各個方面開始。這包括用戶輸入的文本以及場景中的數據。
例如,如果用戶想要創建一個接待室,他們會指定類似“這是我們會見客戶的房間。確保有一套舒適的扶手椅、沙發和咖啡桌。”?或者,如果他們想要添加一定數量的項目,他們可以添加“確保至少包含 10 個項目”。
該文本與場景信息相結合,例如我們將在其中放置項目作為用戶提示的區域的大小和名稱。
“接待室,7 x10 米,原點為( 0.0 , 0.0 , 0.0 )。這是我們會見客戶
的房間。確保有一套舒適的扶手椅、沙發和咖啡桌”將用戶的文本與場景細節相結合的想法非常強大。在場景中選擇一個對象并以編程方式訪問其詳細信息比要求用戶編寫提示來描述所有這些詳細信息要簡單得多。我懷疑我們會看到很多利用這種文本+場景到場景模式的 Omniverse 擴展。
除了用戶提示之外,我們還需要使用系統提示和一兩次訓練來啟動 ChatGPT。
為了創建可預測的、確定性的結果,人工智能根據系統提示和示例專門返回一個 JSON,其中所有信息都以明確定義的方式格式化,以便可以在 Omniverse 中使用。
以下是我們將發送的四部分提示。
系統提示
這為人工智能設置了約束和指令
您是一個區域生成專家。在給定一定大小的區域后,您可以生成適合該區域的物品列表,并將它們放置在正確的位置。
您在一個三維空間中操作,使用 X、Y、Z 坐標系。其中,X 代表寬度,Y 代表高度,Z 代表深度。坐標 (0.0, 0.0, 0.0) 表示默認的空間原點。
您從用戶那里接收到區域的名稱、X 和 Z 軸上的尺寸(以厘米為單位)、區域的原點(即區域中心點)。
您的回答只需生成包含以下信息的 JSON 文件:
- area_name:區域名稱
- X:區域在 X 軸上的坐標
- Y:區域在 Y 軸上的坐標
- Z:區域在 Z 軸上的坐標
- area_size_X:區域在 X 軸上的尺寸(厘米)
- area_size_Z:區域在 Z 軸上的尺寸(厘米)
- area_objects_list:區域中所有物品的列表
對于每個物品,您需要存儲以下信息:
- object_name:物品名稱
- X:物品在 X 軸上的坐標
- Y:物品在 Y 軸上的坐標
- Z:物品在 Z 軸上的坐標
每個物品的名稱應包含適當的形容詞。
請記住,物品應該放置在區域內,以創建最有意義的布局,并且它們不應重疊。所有物品必須位于區域尺寸的邊界內;永遠不要將物品放置在距離原點超過區域長度或深度的一半的位置。還要注意,物品應根據區域的原點分布在整個區域內,您也可以使用負值來正確顯示物品,因為區域的原點始終位于區域的中心。
請記住,您只需生成 JSON 代碼,不需要其他內容。這非常重要。
?用戶輸入示例
? 這是用戶可能提交的內容的示例。請注意,它是場景數據和文本提示的組合。
“接待室,7 x10m,原點為 ( 0.0 , 0.0 , 0.0 )。這是我們會見客戶的房間
。確保有一套舒適的扶手椅、沙發和咖啡 桌”
輔助輸出示例
這提供了人工智能必須使用的模板。請注意我們如何描述我們期望的JSON。
{"area_name": "Reception","X": 0.0,"Y": 0.0,"Z": 0.0,"area_size_X": 700,"area_size_Z": 1000,"area_objects_list": [{"object_name": "White_Round_Coffee_Table","X": -120,"Y": 0.0,"Z": 130},{"object_name": "Leather_Sofa","X": 250,"Y": 0.0,"Z": -90},{"object_name": "Comfortable_Armchair_1","X": -150,"Y": 0.0,"Z": 50},{"object_name": "Comfortable_Armchair_2","X": -150,"Y": 0.0,"Z": -50} ]
}連接到 OpenAI
該提示通過 Python 代碼從擴展發送到 AI。這在 Omniverse Kit 中非常簡單,只需使用最新的O?penAI Python 庫的幾個命令即可完成。請注意,我們正在將系統輸入、示例用戶輸入和我們剛剛概述的示例預期助理輸出傳遞給 OpenAI API。變量“response”將包含來自 ChatGPT 的預期響應。
# Create a completion using the chatGPT model response = openai.ChatCompletion.create(model="gpt-3.5-turbo",# if you have access, you can swap to model="gpt-4",messages=[{"role": "system", "content": system_input},{"role": "user", "content": user_input},{"role": "assistant", "content": assistant_input},{"role": "user", "content": my_prompt},])# parse response and extract texttext = response["choices"][0]["message"]['content']將 ChatGPT 的結果傳遞到 Omniverse DeepSearch API 并生成場景
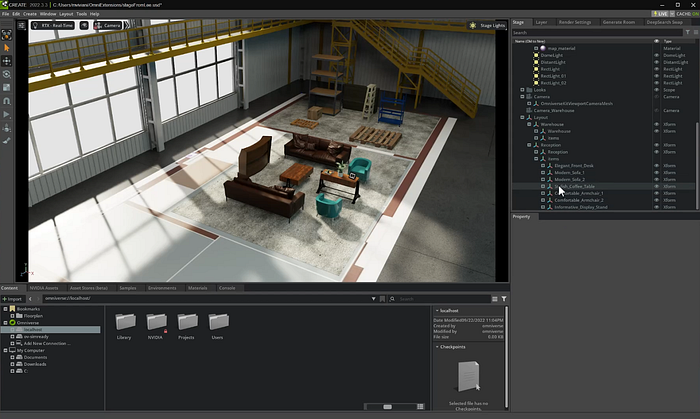 ?
?
然后,擴展程序會解析 ChatGPT JSON 響應中的項目,并將其傳遞到 Omnivere DeepSearch API。DeepSearch 允許用戶使用自然語言查詢搜索存儲在 Omniverse Nucleus 服務器中的 3D 模型。
這意味著,例如,即使我們不知道沙發模型的確切文件名,我們也可以通過搜索“Comfortable Sofa”來檢索它,這正是我們從 ChatGPT 中獲得的。
DeepSearch 能夠理解自然語言,通過向其詢問“舒適的沙發”,我們會得到一份項目列表,我們樂于助人的人工智能圖書館員從我們當前資產庫中選擇的資產中確定了最適合的項目。它在這方面出奇地好,所以我們經常可以使用它返回的第一個項目,但當然,我們建立了選擇,以防用戶想要從列表中選擇某些內容。
從那里,我們只需將對象添加到舞臺即可。
將 DeepSearch 中的項目添加到 Omniverse 階段
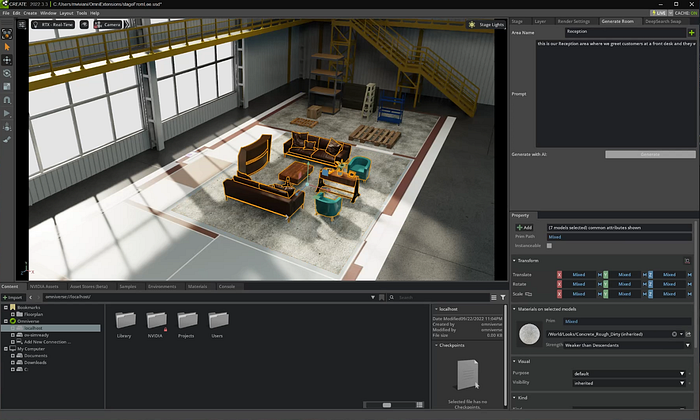 ?
?
現在 DeepSearch 已返回結果,我們只需要將對象放入 Omniverse 中即可。在我們的擴展中,我們創建了一個名為 place_deepsearch_results() 的函數,它處理所有項目并將它們放置在場景中。
def place_deepsearch_results(gpt_results, query_result, root_prim_path):index = 0for item in query_result:# Define Prim stage = omni.usd.get_context().get_stage()prim_parent_path = root_prim_path + item[‘object_name’].replace(" ", "_")parent_xForm = UsdGeom.Xform.Define(stage, prim_parent_path)prim_path = prim_parent_path + "/" + item[‘object_name’].replace(" ", "_")next_prim = stage.DefinePrim(prim_path, 'Xform')# Add reference to USD Assetreferences: Usd.references = next_prim.GetReferences()references.AddReference(assetPath="your_server://your_asset_folder" + item[‘asset_path’])# Add reference for future search refinement config = next_prim.CreateAttribute("DeepSearch:Query", Sdf.ValueTypeNames.String)config.Set(item[‘object_name’])# translate primnext_object = gpt_results[index]index = index + 1x = next_object['X']y = next_object['Y']z = next_object['Z']此方法用于放置項目,迭代我們從 GPT 獲得的 query_result 項目,使用 USD API 創建和定義新原語,根據 gpt_results 中的數據設置其轉換和屬性。我們還將 DeepSearch 查詢保存在美元的屬性中,以便以后我們想再次運行 DeepSearch 時可以使用它。請注意,assetPath“your_server//your_asset_folder”是一個占位符,應替換為執行 DeepSearch 的文件夾的真實路徑。
使用 DeepSearch 交換項目
然而,我們可能不喜歡第一次檢索到的所有項目。因此,我們構建了一個小型配套擴展程序,允許用戶瀏覽類似的對象并只需單擊即可交換它們。借助 Omniverse,可以非常輕松地以模塊化方式構建,因此您可以通過其他擴展輕松擴展您的工作流程。
 ?
?
這個配套擴展非常簡單。它采用通過 DeepSearch 生成的對象作為參數,并提供兩個按鈕來從相關 DeepSearch 查詢中獲取下一個或上一個對象。例如,如果 USD 文件包含屬性“DeepSearch:Query = Modern Sofa”,它將通過 DeepSearch 再次運行此搜索并獲得下一個最佳結果。當然,您可以將其擴展為包含所有搜索結果圖片的可視化 UI,類似于我們用于一般 DeepSearch 查詢的窗口。為了使這個示例簡單,我們只選擇了兩個簡單的按鈕。
請參閱下面的代碼,其中顯示了增加索引的函數,以及實際根據索引操作對象交換的函數replace_reference(self) 。
def increment_prim_index():if self._query_results is None:return self._index = self._index + 1if self._index >= len(self._query_results.paths):self._index = 0self.replace_reference()def replace_reference(self):references: Usd.references = self._selected_prim.GetReferences()references.ClearReferences()references.AddReference(assetPath="your_server://your_asset_folder" + self._query_results.paths[self._index].uri)請注意,如上所述,路徑“your_server://your_asset_folder”只是一個占位符,您應該將其替換為執行 DeepSearch 查詢的 Nucleus 文件夾。
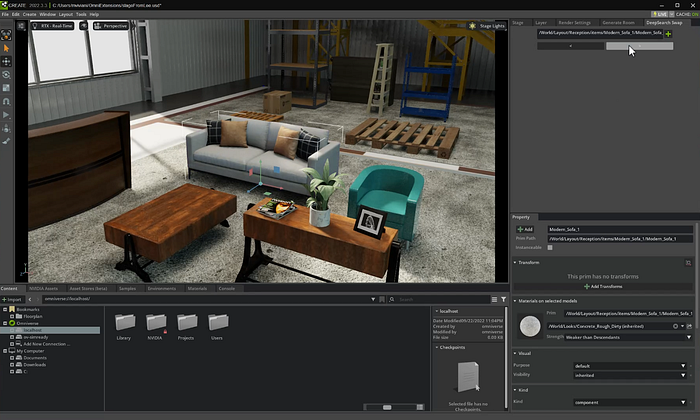 ?
?
使用 DeepSearch 將灰色沙發替換為棕色沙發
這展示了如何通過結合 LLM 和 Omniverse API 的力量,可以創建增強創造力和加快流程的工具。
從 ChatGPT 到 GPT-4
OpenAI 的新 GPT-4 的主要進步之一是其在大型語言模型中增強的空間意識。
我們最初使用ChatGPT API,它基于GPT-3.5-turbo。雖然 GPT-4 提供了良好的空間感知,但它提供了更好的結果。您在上面視頻中看到的版本使用的是 GPT-4。
GPT-4 相對于 GPT-3.5 在解決復雜任務和理解復雜指令方面有了很大的改進。因此,在設計文本提示“指導人工智能”時,我們可以更具描述性并使用自然語言
我們可以給人工智能非常明確的指令,例如:
- “每個對象名稱都應該包含一個適當的形容詞。”
- “請記住,對象應該放置在該區域中以創建盡可能最有意義的布局,并且它們不應該重疊。”
- “所有物體都必須在區域大小的范圍內;切勿將物體放置在距原點超過該區域長度 1/2 或深度 1/2 的位置。”
- “還要記住,對象應該放置在相對于區域原點的整個區域上,并且您也可以使用負值來正確顯示項目,因為區域的原點始終位于區域的中心。該地區。”
人工智能在生成響應時正確遵循這些系統提示的事實尤其令人印象深刻,因為人工智能表明對空間意識以及如何正確放置物品有很好的理解。使用 GPT-3.5 執行此任務的挑戰之一是有時對象會在房間外或奇怪的位置生成。
GPT-4 不僅將物體放置在房間的正確邊界內,而且還邏輯地放置物體:床頭柜實際上會出現在床的一側,咖啡桌將放置在兩個沙發之間,等等。
構建您自己的 ChatGPT 支持的擴展
雖然這只是人工智能連接到 3D 空間后可以做什么的一個小演示,但我們相信它將為場景構建之外的各種工具打開大門。開發人員可以在 Omniverse 中構建人工智能驅動的擴展,用于照明、相機、動畫、角色對話和其他優化創作者工作流程的元素。他們甚至可以開發工具將物理附加到場景并運行整個模擬。



發布)
)



)



: TCP重傳、滑動窗口、流量控制、擁塞控制)

)
)



