主成分分析
?引言
主成分分析(PCA)是一種能夠極大提升無監督特征學習速度的數據降維算法。更重要的是,理解PCA算法,對實現白化算法有很大的幫助,很多算法都先用白化算法作預處理步驟。
假設你使用圖像來訓練算法,因為圖像中相鄰的像素高度相關,輸入數據是有一定冗余的。具體來說,假如我們正在訓練的16x16灰度值圖像,記為一個256維向量 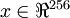 ,其中特征值
,其中特征值 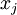 對應每個像素的亮度值。由于相鄰像素間的相關性,PCA算法可以將輸入向量轉換為一個維數低很多的近似向量,而且誤差非常小。
對應每個像素的亮度值。由于相鄰像素間的相關性,PCA算法可以將輸入向量轉換為一個維數低很多的近似向量,而且誤差非常小。
?
實例和數學背景
在我們的實例中,使用的輸入數據集表示為 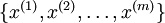 ,維度
,維度 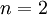 即
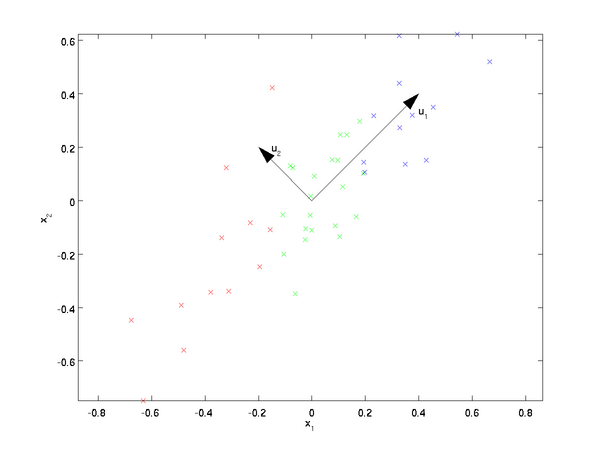
即 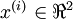 。假設我們想把數據從2維降到1維。(在實際應用中,我們也許需要把數據從256維降到50維;在這里使用低維數據,主要是為了更好地可視化算法的行為)。下圖是我們的數據集:
。假設我們想把數據從2維降到1維。(在實際應用中,我們也許需要把數據從256維降到50維;在這里使用低維數據,主要是為了更好地可視化算法的行為)。下圖是我們的數據集:
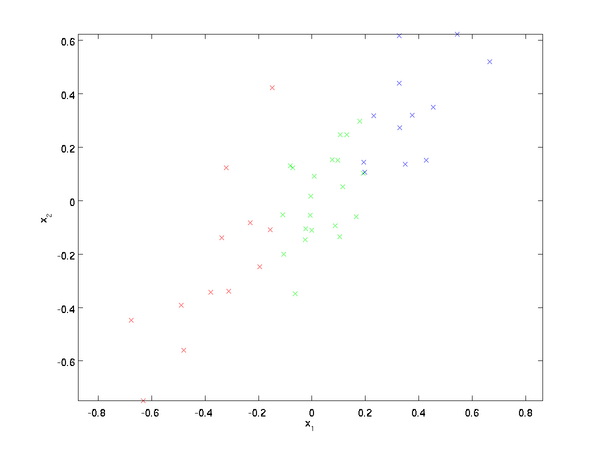
這些數據已經進行了預處理,使得每個特征 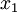 和
和 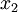 具有相同的均值(零)和方差。
具有相同的均值(零)和方差。
為方便展示,根據 值的大小,我們將每個點分別涂上了三種顏色之一,但該顏色并不用于算法而僅用于圖解。
PCA算法將尋找一個低維空間來投影我們的數據。從下圖中可以看出, 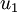 是數據變化的主方向,而
是數據變化的主方向,而 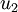 是次方向。
是次方向。
也就是說,數據在 方向上的變化要比在 方向上大。為更形式化地找出方向 和 ,我們首先計算出矩陣  ,如下所示:
,如下所示:
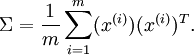
假設  的均值為零,那么 就是x的協方差矩陣。(符號 ,讀"Sigma",是協方差矩陣的標準符號。雖然看起來與求和符號
的均值為零,那么 就是x的協方差矩陣。(符號 ,讀"Sigma",是協方差矩陣的標準符號。雖然看起來與求和符號 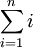 比較像,但它們其實是兩個不同的概念。)
比較像,但它們其實是兩個不同的概念。)
可以證明,數據變化的主方向 就是協方差矩陣 的主特征向量,而 是次特征向量。
注:如果你對如何得到這個結果的具體數學推導過程感興趣,可以參看CS229(機器學習)PCA部分的課件(鏈接在本頁底部)。但如果僅僅是想跟上本課,可以不必如此。
你可以通過標準的數值線性代數運算軟件求得特征向量(見實現說明).我們先計算出協方差矩陣的特征向量,按列排放,而組成矩陣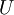 :
:
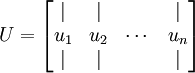
此處, 是主特征向量(對應最大的特征值), 是次特征向量。以此類推,另記 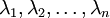 為相應的特征值。
為相應的特征值。
在本例中,向量 和 構成了一個新基,可以用來表示數據。令 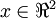 為訓練樣本,那么
為訓練樣本,那么 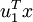 就是樣本點 在維度 上的投影的長度(幅值)。同樣的,
就是樣本點 在維度 上的投影的長度(幅值)。同樣的, 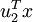 是 投影到 維度上的幅值。
是 投影到 維度上的幅值。
?
旋轉數據
至此,我們可以把 用 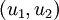 基表達為:
基表達為:
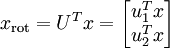
(下標“rot”來源于單詞“rotation”,意指這是原數據經過旋轉(也可以說成映射)后得到的結果)
對數據集中的每個樣本  分別進行旋轉:
分別進行旋轉: 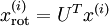 for every ,然后把變換后的數據
for every ,然后把變換后的數據 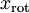 顯示在坐標圖上,可得:
顯示在坐標圖上,可得:
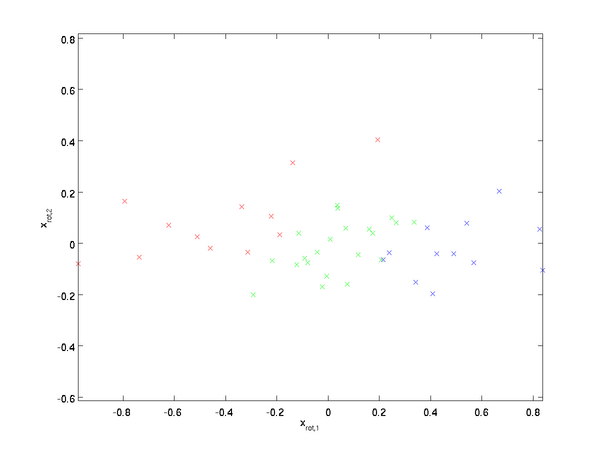
這就是把訓練數據集旋轉到 , 基后的結果。一般而言,運算 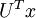 表示旋轉到基 ,, ...,
表示旋轉到基 ,, ...,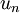 之上的訓練數據。矩陣 有正交性,即滿足?
之上的訓練數據。矩陣 有正交性,即滿足? 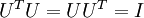 ,所以若想將旋轉后的向量 還原為原始數據 ,將其左乘矩陣即可:
,所以若想將旋轉后的向量 還原為原始數據 ,將其左乘矩陣即可: 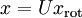 , 驗算一下:
, 驗算一下: 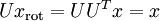 .
.
?
數據降維
數據的主方向就是旋轉數據的第一維 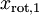 。因此,若想把這數據降到一維,可令:
。因此,若想把這數據降到一維,可令:
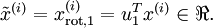
更一般的,假如想把數據 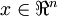 降到
降到 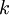 維表示?
維表示? 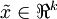 (令
(令 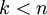 ),只需選取 的前 個成分,分別對應前 個數據變化的主方向。
),只需選取 的前 個成分,分別對應前 個數據變化的主方向。
PCA的另外一種解釋是: 是一個 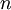 維向量,其中前幾個成分可能比較大(例如,上例中大部分樣本第一個成分
維向量,其中前幾個成分可能比較大(例如,上例中大部分樣本第一個成分 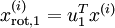 的取值相對較大),而后面成分可能會比較小(例如,上例中大部分樣本的
的取值相對較大),而后面成分可能會比較小(例如,上例中大部分樣本的 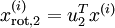 較小)。
較小)。
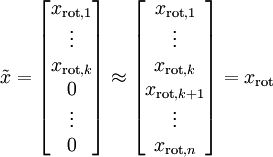
PCA算法做的其實就是丟棄 中后面(取值較小)的成分,就是將這些成分的值近似為零。具體的說,設 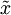 是
是 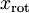 的近似表示,那么將 除了前 個成分外,其余全賦值為零,就得到:
的近似表示,那么將 除了前 個成分外,其余全賦值為零,就得到:
在本例中,可得 的點圖如下(取 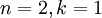 ):
):
然而,由于上面 的后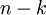 項均為零,沒必要把這些零項保留下來。所以,我們僅用前 個(非零)成分來定義 維向量 。
項均為零,沒必要把這些零項保留下來。所以,我們僅用前 個(非零)成分來定義 維向量 。
這也解釋了我們為什么會以 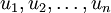 為基來表示數據:要決定保留哪些成分變得很簡單,只需取前 個成分即可。這時也可以說,我們“保留了前 個PCA(主)成分”。
為基來表示數據:要決定保留哪些成分變得很簡單,只需取前 個成分即可。這時也可以說,我們“保留了前 個PCA(主)成分”。
?
還原近似數據
現在,我們得到了原始數據 的低維“壓縮”表征量 , 反過來,如果給定 ,我們應如何還原原始數據 呢?查看以往章節以往章節可知,要轉換回來,只需 即可。進一步,我們把 看作將 的最后 個元素被置0所得的近似表示,因此如果給定 ,可以通過在其末尾添加 個0來得到對 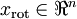 的近似,最后,左乘 便可近似還原出原數據 。具體來說,計算如下:
的近似,最后,左乘 便可近似還原出原數據 。具體來說,計算如下:
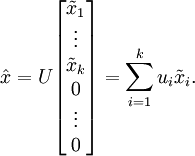
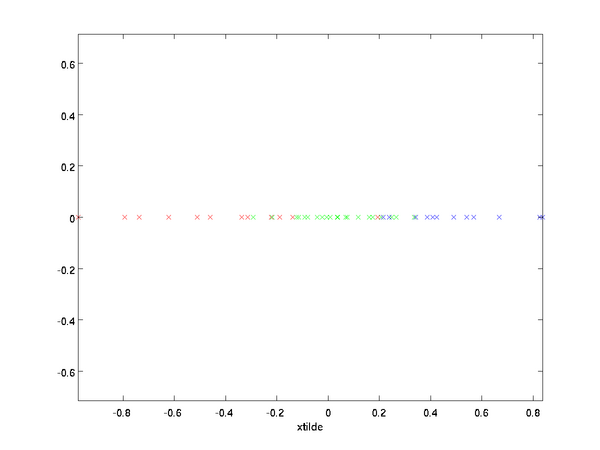
上面的等式基于先前對 的定義。在實現時,我們實際上并不先給 填0然后再左乘 ,因為這意味著大量的乘0運算。我們可用 來與 的前 列相乘,即上式中最右項,來達到同樣的目的。將該算法應用于本例中的數據集,可得如下關于重構數據 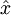 的點圖:
的點圖:
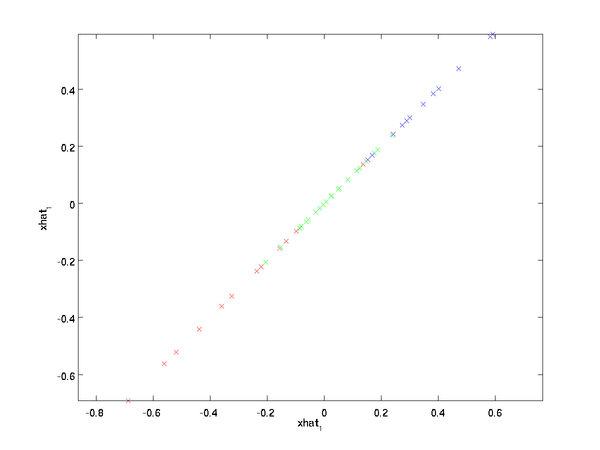
由圖可見,我們得到的是對原始數據集的一維近似重構。
在訓練自動編碼器或其它無監督特征學習算法時,算法運行時間將依賴于輸入數據的維數。若用 取代 作為輸入數據,那么算法就可使用低維數據進行訓練,運行速度將顯著加快。對于很多數據集來說,低維表征量 是原數據集的極佳近似,因此在這些場合使用PCA是很合適的,它引入的近似誤差的很小,卻可顯著地提高你算法的運行速度。
?
選擇主成分個數
我們該如何選擇 ,即保留多少個PCA主成分?在上面這個簡單的二維實驗中,保留第一個成分看起來是自然的選擇。對于高維數據來說,做這個決定就沒那么簡單:如果 過大,數據壓縮率不高,在極限情況 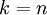 時,等于是在使用原始數據(只是旋轉投射到了不同的基);相反地,如果 過小,那數據的近似誤差太太。
時,等于是在使用原始數據(只是旋轉投射到了不同的基);相反地,如果 過小,那數據的近似誤差太太。
決定 值時,我們通常會考慮不同 值可保留的方差百分比。具體來說,如果 ,那么我們得到的是對數據的完美近似,也就是保留了100%的方差,即原始數據的所有變化都被保留下來;相反,如果 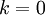 ,那等于是使用零向量來逼近輸入數據,也就是只有0%的方差被保留下來。
,那等于是使用零向量來逼近輸入數據,也就是只有0%的方差被保留下來。
一般而言,設 表示 的特征值(按由大到小順序排列),使得 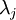 為對應于特征向量
為對應于特征向量 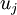 的特征值。那么如果我們保留前 個成分,則保留的方差百分比可計算為:
的特征值。那么如果我們保留前 個成分,則保留的方差百分比可計算為:
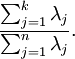
在上面簡單的二維實驗中,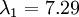 ,
,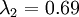 。因此,如果保留
。因此,如果保留 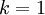 個主成分,等于我們保留了
個主成分,等于我們保留了 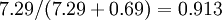 ,即91.3%的方差。
,即91.3%的方差。
對保留方差的百分比進行更正式的定義已超出了本教程的范圍,但很容易證明,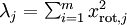 。因此,如果
。因此,如果 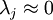 ,則說明
,則說明 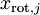 也就基本上接近于0,所以用0來近似它并不會產生多大損失。這也解釋了為什么要保留前面的主成分(對應的 值較大)而不是末尾的那些。 這些前面的主成分 變化性更大,取值也更大,如果將其設為0勢必引入較大的近似誤差。
也就基本上接近于0,所以用0來近似它并不會產生多大損失。這也解釋了為什么要保留前面的主成分(對應的 值較大)而不是末尾的那些。 這些前面的主成分 變化性更大,取值也更大,如果將其設為0勢必引入較大的近似誤差。
以處理圖像數據為例,一個慣常的經驗法則是選擇 以保留99%的方差,換句話說,我們選取滿足以下條件的最小 值:
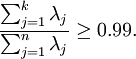
對其它應用,如不介意引入稍大的誤差,有時也保留90-98%的方差范圍。若向他人介紹PCA算法詳情,告訴他們你選擇的 保留了95%的方差,比告訴他們你保留了前120個(或任意某個數字)主成分更好理解。
?
對圖像數據應用PCA算法
為使PCA算法能有效工作,通常我們希望所有的特征 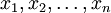 都有相似的取值范圍(并且均值接近于0)。如果你曾在其它應用中使用過PCA算法,你可能知道有必要單獨對每個特征做預處理,即通過估算每個特征 的均值和方差,而后將其取值范圍規整化為零均值和單位方差。但是,對于大部分圖像類型,我們卻不需要進行這樣的預處理。假定我們將在自然圖像上訓練算法,此時特征 代表的是像素
都有相似的取值范圍(并且均值接近于0)。如果你曾在其它應用中使用過PCA算法,你可能知道有必要單獨對每個特征做預處理,即通過估算每個特征 的均值和方差,而后將其取值范圍規整化為零均值和單位方差。但是,對于大部分圖像類型,我們卻不需要進行這樣的預處理。假定我們將在自然圖像上訓練算法,此時特征 代表的是像素  的值。所謂“自然圖像”,不嚴格的說,是指人或動物在他們一生中所見的那種圖像。
的值。所謂“自然圖像”,不嚴格的說,是指人或動物在他們一生中所見的那種圖像。
注:通常我們選取含草木等內容的戶外場景圖片,然后從中隨機截取小圖像塊(如16x16像素)來訓練算法。在實踐中我們發現,大多數特征學習算法對訓練圖片的確切類型并不敏感,所以大多數用普通照相機拍攝的圖片,只要不是特別的模糊或帶有非常奇怪的人工痕跡,都可以使用。
在自然圖像上進行訓練時,對每一個像素單獨估計均值和方差意義不大,因為(理論上)圖像任一部分的統計性質都應該和其它部分相同,圖像的這種特性被稱作平穩性(stationarity)。
具體而言,為使PCA算法正常工作,我們通常需要滿足以下要求:(1)特征的均值大致為0;(2)不同特征的方差值彼此相似。對于自然圖片,即使不進行方差歸一化操作,條件(2)也自然滿足,故而我們不再進行任何方差歸一化操作(對音頻數據,如聲譜,或文本數據,如詞袋向量,我們通常也不進行方差歸一化)。實際上,PCA算法對輸入數據具有縮放不變性,無論輸入數據的值被如何放大(或縮小),返回的特征向量都不改變。更正式的說:如果將每個特征向量 都乘以某個正數(即所有特征量被放大或縮小相同的倍數),PCA的輸出特征向量都將不會發生變化。
既然我們不做方差歸一化,唯一還需進行的規整化操作就是均值規整化,其目的是保證所有特征的均值都在0附近。根據應用,在大多數情況下,我們并不關注所輸入圖像的整體明亮程度。比如在對象識別任務中,圖像的整體明亮程度并不會影響圖像中存在的是什么物體。更為正式地說,我們對圖像塊的平均亮度值不感興趣,所以可以減去這個值來進行均值規整化。
具體的步驟是,如果 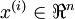 代表16x16的圖像塊的亮度(灰度)值(
代表16x16的圖像塊的亮度(灰度)值(  ),可用如下算法來對每幅圖像進行零均值化操作:
),可用如下算法來對每幅圖像進行零均值化操作:
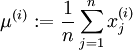
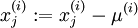 , for all
, for all
請注意:1)對每個輸入圖像塊 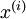 都要單獨執行上面兩個步驟,2)這里的?
都要單獨執行上面兩個步驟,2)這里的? 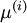 是指圖像塊 的平均亮度值。尤其需要注意的是,這和為每個像素 單獨估算均值是兩個完全不同的概念。
是指圖像塊 的平均亮度值。尤其需要注意的是,這和為每個像素 單獨估算均值是兩個完全不同的概念。
如果你處理的圖像并非自然圖像(比如,手寫文字,或者白背景正中擺放單獨物體),其他規整化操作就值得考慮了,而哪種做法最合適也取決于具體應用場合。但對自然圖像而言,對每幅圖像進行上述的零均值規整化,是默認而合理的處理。
白化
介紹
我們已經了解了如何使用PCA降低數據維度。在一些算法中還需要一個與之相關的預處理步驟,這個預處理過程稱為白化(一些文獻中也叫sphering)。舉例來說,假設訓練數據是圖像,由于圖像中相鄰像素之間具有很強的相關性,所以用于訓練時輸入是冗余的。白化的目的就是降低輸入的冗余性;更正式的說,我們希望通過白化過程使得學習算法的輸入具有如下性質:(i)特征之間相關性較低;(ii)所有特征具有相同的方差。
?
2D 的例子
下面我們先用前文的2D例子描述白化的主要思想,然后分別介紹如何將白化與平滑和PCA相結合。
如何消除輸入特征之間的相關性? 在前文計算??時實際上已經消除了輸入特征之間的相關性。得到的新特征??的分布如下圖所示:
這個數據的協方差矩陣如下:
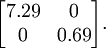
(注: 嚴格地講, 這部分許多關于“協方差”的陳述僅當數據均值為0時成立。下文的論述都隱式地假定這一條件成立。不過即使數據均值不為0,下文的說法仍然成立,所以你無需擔心這個。)
?協方差矩陣對角元素的值為?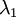 ?和?
?和?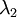 ?絕非偶然。并且非對角元素值為0; 因此,??和?
?絕非偶然。并且非對角元素值為0; 因此,??和?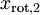 ?是不相關的, 滿足我們對白化結果的第一個要求 (特征間相關性降低)。
?是不相關的, 滿足我們對白化結果的第一個要求 (特征間相關性降低)。
為了使每個輸入特征具有單位方差,我們可以直接使用?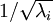 ?作為縮放因子來縮放每個特征?
?作為縮放因子來縮放每個特征?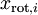 ?。具體地,我們定義白化后的數據?
?。具體地,我們定義白化后的數據?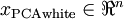 ?如下:
?如下:
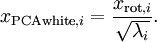
繪制出?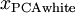 ?,我們得到:
?,我們得到:
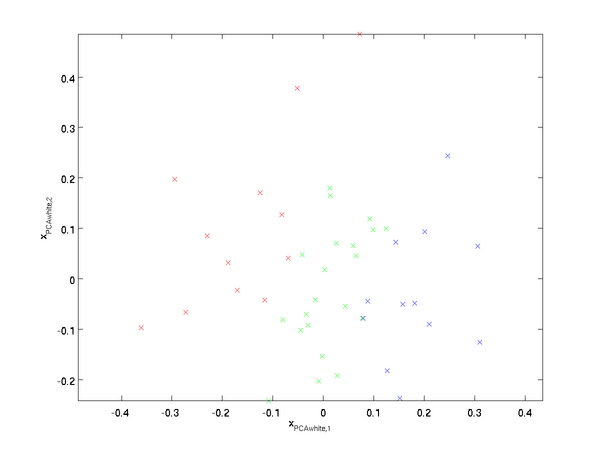
這些數據現在的協方差矩陣為單位矩陣?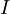 ?。我們說,?是數據經過PCA白化后的版本:??中不同的特征之間不相關并且具有單位方差。
?。我們說,?是數據經過PCA白化后的版本:??中不同的特征之間不相關并且具有單位方差。
白化與降維相結合。 如果你想要得到經過白化后的數據,并且比初始輸入維數更低,可以僅保留??中前??個成分。當我們把PCA白化和正則化結合起來時(在稍后討論),?中最后的少量成分將總是接近于0,因而舍棄這些成分不會帶來很大的問題。
?
ZCA白化
最后要說明的是,使數據的協方差矩陣變為單位矩陣??的方式并不唯一。具體地,如果?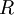 ?是任意正交矩陣,即滿足?
?是任意正交矩陣,即滿足?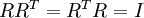 ?(說它正交不太嚴格,?可以是旋轉或反射矩陣), 那么?
?(說它正交不太嚴格,?可以是旋轉或反射矩陣), 那么?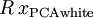 ?仍然具有單位協方差。在ZCA白化中,令?
?仍然具有單位協方差。在ZCA白化中,令?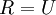 ?。我們定義ZCA白化的結果為:
?。我們定義ZCA白化的結果為:
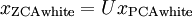
繪制?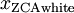 ,得到:
,得到:
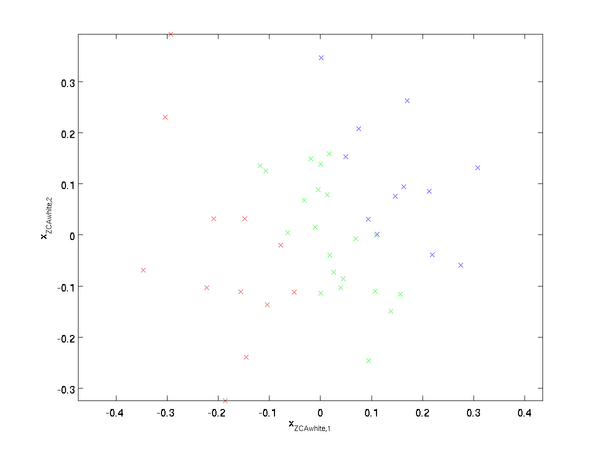
可以證明,對所有可能的?,這種旋轉使得??盡可能地接近原始輸入數據??。
當使用 ZCA白化時(不同于 PCA白化),我們通常保留數據的全部??個維度,不嘗試去降低它的維數。
?
正則化
實踐中需要實現PCA白化或ZCA白化時,有時一些特征值?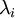 ?在數值上接近于0,這樣在縮放步驟時我們除以?
?在數值上接近于0,這樣在縮放步驟時我們除以?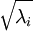 ?將導致除以一個接近0的值;這可能使數據上溢 (賦為大數值)或造成數值不穩定。因而在實踐中,我們使用少量的正則化實現這個縮放過程,即在取平方根和倒數之前給特征值加上一個很小的常數?
?將導致除以一個接近0的值;這可能使數據上溢 (賦為大數值)或造成數值不穩定。因而在實踐中,我們使用少量的正則化實現這個縮放過程,即在取平方根和倒數之前給特征值加上一個很小的常數?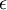 :
:
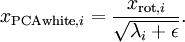
當??在區間?![\textstyle [-1,1]](http://deeplearning.stanford.edu/wiki/images/math/8/5/a/85a1c5a07f21a9eebbfb1dca380f8d38.png) ?上時, 一般取值為?
?上時, 一般取值為?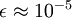 。
。
對圖像來說, 這里加上??,對輸入圖像也有一些平滑(或低通濾波)的作用。這樣處理還能消除在圖像的像素信息獲取過程中產生的噪聲,改善學習到的特征(細節超出了本文的范圍)。
ZCA 白化是一種數據預處理方法,它將數據從??映射到??。 事實證明這也是一種生物眼睛(視網膜)處理圖像的粗糙模型。具體而言,當你的眼睛感知圖像時,由于一幅圖像中相鄰的部分在亮度上十分相關,大多數臨近的“像素”在眼中被感知為相近的值。因此,如果人眼需要分別傳輸每個像素值(通過視覺神經)到大腦中,會非常不劃算。取而代之的是,視網膜進行一個與ZCA中相似的去相關操作 (這是由視網膜上的ON-型和OFF-型光感受器細胞將光信號轉變為神經信號完成的)。由此得到對輸入圖像的更低冗余的表示,并將它傳輸到大腦。
實現主成分分析和白化
在這一節里,我們將總結PCA, PCA白化和ZCA白化算法,并描述如何使用高效的線性代數庫來實現它們。
首先,我們需要確保數據的均值(近似)為零。對于自然圖像,我們通過減去每個圖像塊(patch)的均值(近似地)來達到這一目標。為此,我們計算每個圖像塊的均值,并從每個圖像塊中減去它的均值。(譯注:參見PCA一章中“對圖像數據應用PCA算法”一節)。Matlab實現如下:
avg = mean(x, 1); ?% 分別為每個圖像塊計算像素強度的均值。 x = x - repmat(avg, size(x, 1), 1);
下面,我們要計算?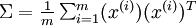 ?,如果你在Matlab中實現(或者在C++, Java等中實現,但可以使用高效的線性代數庫),直接求和效率很低。不過,我們可以這樣一氣呵成。
?,如果你在Matlab中實現(或者在C++, Java等中實現,但可以使用高效的線性代數庫),直接求和效率很低。不過,我們可以這樣一氣呵成。
sigma = x * x' / size(x, 2);
(自己推導一下看看)這里,我們假設?x?為一數據結構,其中每列表示一個訓練樣本(所以?x?是一個?×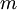 ?的矩陣)。
?的矩陣)。
接下來,PCA計算?Σ?的特征向量。你可以使用Matlab的?eig?函數來計算。但是由于?Σ?是對稱半正定的矩陣,用?svd?函數在數值計算上更加穩定。
具體來說,如果你使用
[U,S,V] = svd(sigma);
那矩陣?U?將包含?Sigma?的特征向量(一個特征向量一列,從主向量開始排序),矩陣S 對角線上的元素將包含對應的特征值(同樣降序排列)。矩陣?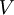 ?等于??的轉置,可以忽略。
?等于??的轉置,可以忽略。
(注意?svd?函數實際上計算的是一個矩陣的奇異值和奇異向量,就對稱半正定矩陣的特殊情況來說,它們對應于特征值和特征向量,這里我們也只關心這一特例。關于奇異向量和特征向量的詳細討論超出了本文范圍。)
最后,我們可以這樣計 算?和??:
xRot = U' * x; ?% 數據旋轉后的結果。 xTilde = U(:,1:k)' * x;?% 數據降維后的結果,這里k希望保留的特征向量的數目。
這以??的形式給出了數據的PCA表示。順便說一下,如果?x?是一個包括所有訓練數據的?×?矩陣,這也是一種向量化的實現方式,上面的式子可以讓你一次對所有的訓練樣本計算出?xrot?和?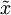 ?。得到的?xrot?和?中,每列對應一個訓練樣本。
?。得到的?xrot?和?中,每列對應一個訓練樣本。
為計算PCA白化后的數據?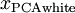 ?,可以用
?,可以用
xPCAwhite = diag(1./sqrt(diag(S) + epsilon)) * U' * x;
因為?S?的對角線包括了特征值??,這其實就是同時為所有樣本計算?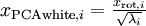 ?的簡潔表達。
?的簡潔表達。
最后,你也可以這樣計算ZCA白化后的數據:
xZCAwhite = U * diag(1./sqrt(diag(S) + epsilon)) * U' * x;
原鏈接:http://deeplearning.stanford.edu/wiki/index.php/%E4%B8%BB%E6%88%90%E5%88%86%E5%88%86%E6%9E%90










)


![[AlwaysOn Availability Groups] 健康模型 Part 2 ——擴展](http://pic.xiahunao.cn/[AlwaysOn Availability Groups] 健康模型 Part 2 ——擴展)





)