
背景
在時序數據庫中,資源的操作是一個復雜且關鍵的任務。這些操作通常涉及到多個步驟,每個步驟都可能會失敗,導致資源處于不一致的狀態。例如,一個用戶可能想要在CnosDB集群中刪除一個租戶,這個操作可能需要刪除租戶下的各種資源(role、database、member等)。如果在這個過程中的任何一步失敗了,那么這個操作可能會導致集群處于不一致的狀態,為了解決這個問題,我們設計了一個解決方案。
基于這個目標,我們參考了一些設計比較好的產品。
方案參考:HBase的ProcedureV2?(Pv2)?Framework
HBase?中?Procedure?代表一個或一組操作,Procedure?分為了如下狀態:
INITIALIZING?-?Procedure?構造中,未提交執行
RUNNABLE??-?Procedure?提交,準備好執行
WAITING?-?Procedure?等待子?Procedure?完成
WAITING_TIMEOUT?-?Procedure等待超時或事件中斷
ROLLEDBACK?-?由于Procedure或子Procedure失敗,Procedure會回滾,回滾過程中會清理執行時創建的資源。在失敗或者重啟場景下,回滾會發生多次,因此回滾步驟要保證冪等性
SUCCESS?-?Procedure成功完成,無失敗
FAILED?-?Procedure至少執行了一次且失敗,已經或尚未回滾,任何處于失敗狀態的Procedure都將會切換到回滾狀態
通過對Procedure的各個步驟的清晰切分和記錄,實現了多步驟執行的原子性和一致性。
最終方案:ResourceManager
基于CnosDB的情況,我們引入了ResourceManager功能。
ResourceManager可以在后臺重試失敗任務,直到操作成功。這樣,即使某個步驟失敗了,ResourceManager也可以保證最終的一致性。例如,在上述的刪除租戶操作中,如果在進行到刪除database的步驟失敗了,那么我們可以創建一個異步任務來重試這個步驟及后續步驟。這個異步任務會在后臺運行,并且會不斷重試,直到成功。通過這種方式,我們可以確保即使在面對失敗時,我們的系統也能保持一致性。
ResourceManager也支持延遲任務,可以對任務預設一個執行時間,當到達時間時,會執行任務,如果失敗,也會進行重試。
總的來說,ResourceManager提供了一種強大而靈活的方式來處理時序數據庫中的多步驟任務操作,并確保系統的最終一致性。
任務狀態劃分
根據任務的情況,會被分為不同的狀態:
Schedule?-?任務提交到ResourceManager,未執行
Executing?-?正在執行該任務
Successed?-?任務執行成功
Failed?-?任務執行失敗,會進行重試
Cancel?-?任務未執行,被取消
Fatal?-?任務執行過程中發生無法恢復錯誤,不會進行重試
任務狀態查看
為了清楚地知道任務當前的執行情況,提供了系統表resource_status,可以通過如下命令查看:
SELECT?*?FROM?information_schema.resource_status;
表信息如下:
| time | name | action | try_count | status | comment |
| 2023-11-03?05:47:28 | cnosdb-db1 | DropDatabase | 1 | Successed |
time?-?任務發生時間
name?-?任務名稱
action?-?任務動作
try_count?-?嘗試次數
status?-?任務當前狀態
comment?-?任務執行信息
具體場景
場景一

在CnosDB集群中,資源操作請求可能會被下發到任意節點進行處理。
例如,一個請求可能會被下發到名為node1的節點。然而,由于網絡延遲、硬件故障或其他一些原因,這個請求可能會失敗。當node1節點在處理請求時遇到失敗,它不只會簡單地返回一個錯誤,并且還會將這個請求作為失敗任務記錄到meta中。
在CnosDB集群中,多個節點(例如node1、node2)會定時從meta中讀取失敗任務。為了防止多個節點重試同一個任務,只有一個節點能夠成功地讀取這個任務。在我們的假設中,node2節點成功地讀取了這個任務。
一旦node2節點獲取了這個失敗任務,它就會開始循環重試這個任務,直到任務成功為止,并且在重試過程中,會記錄執行失敗的錯誤信息。這種設計可以確保即使在面對失敗時,我們的系統也能夠最終完成所有的請求。
目前支持失敗重試的操作:
DropTenant,
DropDatabase,
DropTable,
DropColumn,
AddColumn,
AlterColumn,
RenameTagName,
UpdateTagValue
場景二
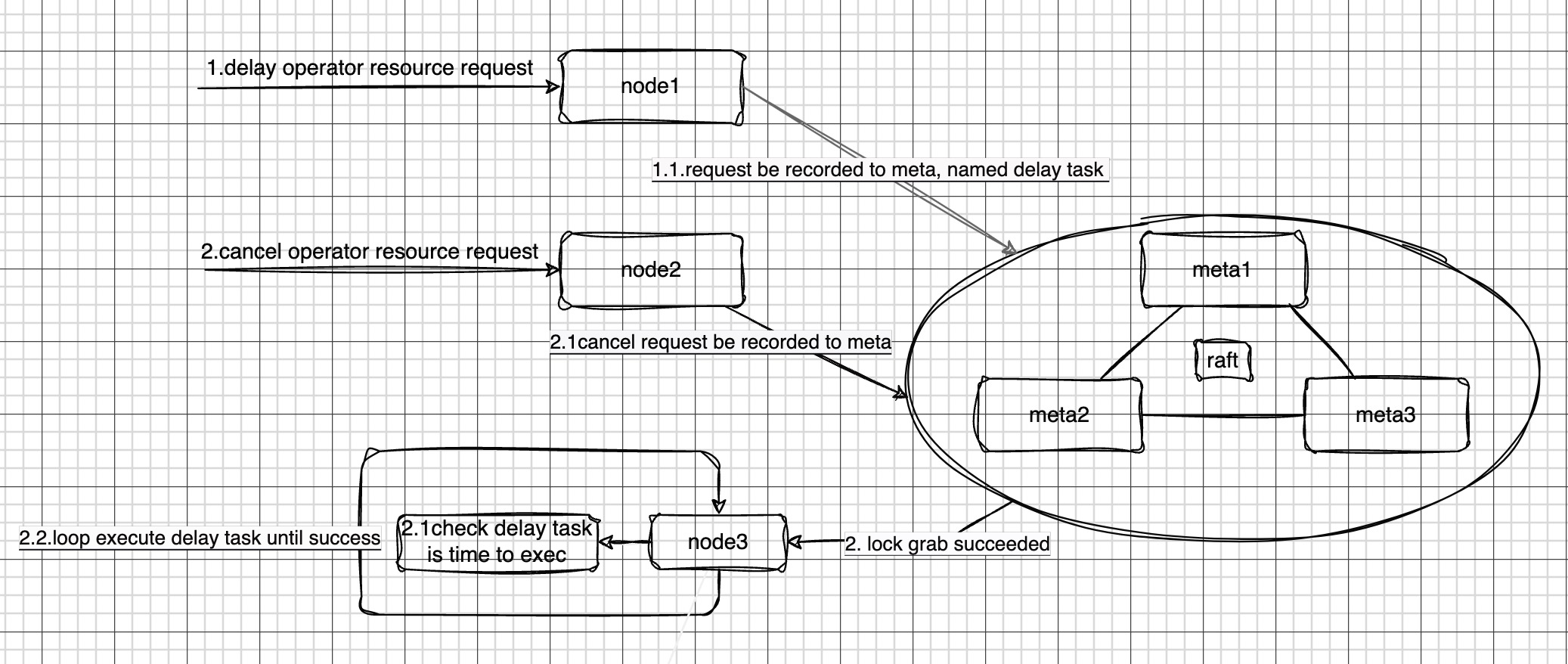
在CnosDB集群中,當node1接收到一個延遲任務時,這個任務會被記錄到meta中。meta中有一個用于存儲任務信息的數據結構,它能夠被系統中的所有節點訪問和讀取。
多個節點(例如node1、node2、node3等)會嘗試從meta中讀取任務列表。然而,為了保證任務的一致性和正確性,系統設計了一種鎖機制,使得在多個節點中,只有一個節點能夠成功地讀取到任務列表。在這個例子中,我們假設node3是成功讀取任務的節點。
當node3成功地從meta中讀取到任務列表后,它會開始對任務進行遍歷處理。首先,它會檢查當前的時間是否已經達到了任務的預定執行時間。如果還沒有到達預定的執行時間,node3會跳過該任務;如果已經到達預定的執行時間,node3則會開始執行這個任務。
在執行任務的過程中,node3會采用一種循環執行的策略。也就是說,如果任務在第一次執行時沒有成功,node3會再次嘗試執行這個任務,直到任務成功為止。此外,為了保證系統的可靠性和可追蹤性,在每次執行任務時,node3都會將當前的執行狀態和結果記錄到系統表中,可以通過查看系統表查看任務的執行狀態。
另一種情況是在node3成功讀取前,取消延遲任務的請求下發給node2,該請求會被記錄到meta,此時該延遲任務到預設時間后也不會被執行。
通過以上的設計和實現,系統能夠對延遲任務進行有效和正確的處理,并且能夠實時地跟蹤和記錄任務的執行狀態和結果。
目前支持延遲任務的操作:DropTenant、DropDatabase。
CnosDB簡介
CnosDB是一款高性能、高易用性的開源分布式時序數據庫,現已正式發布及全部開源。
歡迎關注我們的社區網站:https://cn.cnosdb.com




)


![[AlwaysOn Availability Groups] 健康模型 Part 2 ——擴展](http://pic.xiahunao.cn/[AlwaysOn Availability Groups] 健康模型 Part 2 ——擴展)





)




 限定符)
