一、論文
- 研究領域:全監督3D語義分割(室內,室外RGB,kitti)
- 論文:RandLA-Net: Ef?cient Semantic Segmentation of Large-Scale Point Clouds
-
CVPR 2020
-
牛津大學、中山大學、國防科技大學
- 論文鏈接
- 論文github
?
二、論文概要
2.1 主要思路
現有的語義分割網絡幾乎所有都限于極小的3D點云(例如,4k個點或1×1米塊),并且不能直接擴展到更大的點云;即使最近有工作已經開始解決直接處理大規模點云的任務,他們的預處理和體素化步驟的計算量太大,部署在實時應用程序。
- 現有大規模點云語義分割方法的預處理和體素化步驟的計算量太大
- 大規模點云語義分割已經有人實現,但消耗內存且計算量很大
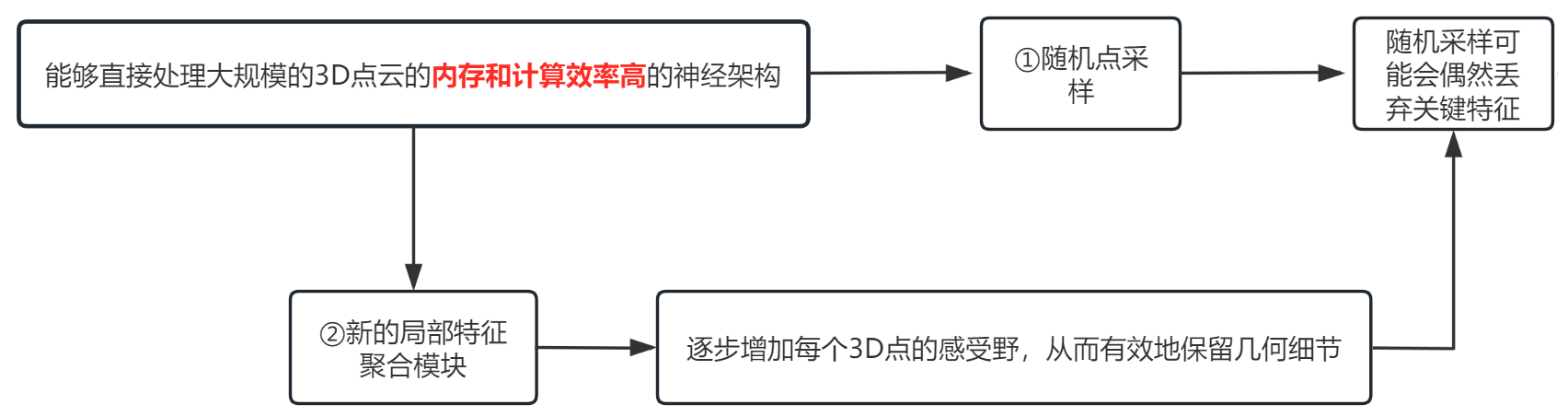
RandLA-Net中,我們的目標是設計一個內存和計算效率高的神經架構,它能夠直接處理大規模的3D點云,而不需要任何預/后處理步驟,如體素化,塊分區或圖形構建。
我們的方法的關鍵是使用隨機點采樣。雖然計算和存儲效率非常高,但隨機采樣可能會偶然丟棄關鍵特征。為了克服這一點,我們引入了一種新的局部特征聚合模塊,以逐步增加每個3D點的感受野,從而有效地保留幾何細節。
?
2.1.1 實現步驟


給定一個具有數百萬個點的大規模點云,跨越數百米,要用深度神經網絡處理它,不可避免地需要在每個神經層中對這些點進行漸進和有效的下采樣,而不會丟失有用的點特征。?在RandLA-Net的每一層中,大規模的點云被顯著地下采樣,但能夠保留精確分割所必需的特征。
隨機點采樣:

隨機采樣從原始N個點中均勻地選擇K個點。它的計算復雜度是O(1),這與輸入點的總數無關,即,它是恒定時間且因此固有地可縮放。與FPS和IDIS相比,無論輸入點云的規模如何,隨機采樣都具有最高的計算效率。處理10^6個點只需要0.004s。
?
新的局部特征聚合模塊:
局部特征聚合模塊并行應用于每個3D點,它由三個神經單元組成:
局部空間編碼(LocSE)、注意池化、擴張的殘余塊
①?Local Spatial Encoding?
(1)Finding Neighbouring Points
? ? ? ? ? 對于第i個點,它的相鄰點通過簡單的K近鄰(KNN)算法計算得到;
(2) Relative Point Position Encoding
? ? ? ? ? 對于中心點pi的最接近的K個點{p1 i · · · pk i · ·pKi}中的每一個,我們如下明確地對相對點位置進行編碼:?
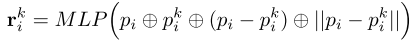
(3) Point Feature Augmentation
? ? ? ? ?對于每個相鄰點pk i,將編碼的相對點位置rki與其對應的點特征fki連接,從而獲得增強的特征向量(fki)。
LocSE單元的輸出是一組新的相鄰特征Fi = {f1 i · · ·fk i · ·fKi},其明確地編碼中心點pi的局部幾何結構。
② Attentive Pooling
?(1)Computing Attention Scores
給定局部特征集合Fi = {f1 i · · · ·fk i · · ·fK i },設計一個共享函數g來學習每個特征的唯一注意力分數。基本上,函數g()由共享MLP和softmax組成。其正式定義如下:
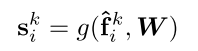
?(2)Weighted Summation
這些特征被加權求和如下
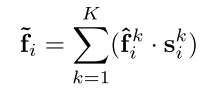
?給定輸入點云P,對于第i個點pi,我們的LocSE和注意力池單元學習聚合其K個最近點的幾何圖案和特征,并最終生成信息特征向量~ fi。
③?Dilated Residual Block 殘差塊
?
由于大的點云將被大幅下采樣,顯著增加每個點的感受野,使得即使一些點被丟棄,輸入點云的幾何細節也更可能被保留。
?
2.2 主要貢獻
RandLA-Net在三個方面有所區別:
1)它僅依賴于網絡內的隨機采樣,從而需要少得多的存儲器和計算;
2)所提出的局部特征聚合器通過顯式地考慮局部空間關系和點特征,可以獲得連續更大的感受野,從而對學習復雜的局部模式更加有效和魯棒;
3)整個網絡僅由共享的MLP組成,而不依賴于任何昂貴的操作,例如圖構建和核化,因此對于大規模點云非常有效。
2.3 實驗表現
Semantic 3D上不同方法的定量結果:

?
?SemanticKITTI上不同方法的定量結果:
?
S3DIS?上不同方法的定量結果:
?
?
消融實驗結果:

?
三、論文全文
RandLA-Net:大規模點云的高效語義分割
- 摘要
?研究了大規模三維點云數據的高效語義分割問題。由于依賴于昂貴的采樣技術或計算量大的預/后處理步驟,大多數現有方法只能在小規模點云上進行訓練和操作。在本文中,我們介紹了RandLA-Net,這是一種高效且輕量級的神經架構,可以直接推斷大規模點云的逐點語義。我們的方法的關鍵是使用隨機點采樣,而不是更復雜的點選擇方法。雖然計算和存儲效率非常高,但隨機采樣可能會偶然丟棄關鍵特征。為了克服這一點,我們引入了一種新的局部特征聚合模塊,以逐步增加每個3D點的接收場,從而有效地保留幾何細節。大量的實驗表明,我們的RandLA-Net可以在單次通過中處理100萬個點,比現有方法快200倍。此外,我們的RandLA-Net在兩個大型基準Semantic 3D和SemanticKITTI上明顯超過了最先進的語義分割方法。
- Introduction
大規模三維點云的有效語義分割是實時智能系統(如自動駕駛和增強現實)的基本和必要能力。一個關鍵的挑戰是深度傳感器獲取的原始點云通常是不規則采樣的、非結構化的和無序的。盡管深度卷積網絡在結構化2D計算機視覺任務中表現出出色的性能,但它們不能直接應用于這種類型的非結構化數據[下圖參考]。

最近,開創性的工作PointNet [43]已經成為直接處理3D點云的有前途的方法。它使用共享多層感知器(MLP)學習每點特征。這在計算上是高效的,但無法捕獲每個點的更廣泛的上下文信息。為了學習更豐富的局部結構,許多專用的神經模塊隨后被迅速引入。這些模塊通常可分類為:1)相鄰特征池化[44,32,21,70,69],2)圖形消息傳遞[57,48,55,56,5,22,34],3)基于內核的卷積[49,20,60,29,23,24,54,38],以及4)基于注意力的聚合[61,68,66,42]。盡管這些方法實現了對象識別和語義分割的令人印象深刻的結果,但是它們中的幾乎所有都限于極小的3D點云(例如,4k個點或1×1米塊),并且不能直接擴展到更大的點云(例如,數百萬個點和高達200×200米),而無需預處理步驟,如塊分割。這種限制的原因有三方面。
1)這些網絡常用的點采樣方法要么計算量大,要么內存效率低。例如,廣泛采用的最遠點采樣[44]需要超過200秒才能對100萬個點中的10%進行采樣。
2)大多數現有的局部特征學習器通常依賴于計算昂貴的核化或圖構造,從而無法處理大量的點。
3)對于通常由數百個對象組成的大規模點云,現有的局部特征學習器要么無法捕獲復雜結構,要么效率低下,因為它們的感受野大小有限
PointNet 只能處理小規模點云
共享多層感知器(Shared Multi-Layer Perceptron, Shared MLP)是一種常見的神經網絡結構,在多個任務共享一個神經網絡時經常使用。這個網絡結構可以使每個任務共享相同的特征提取層,從而提高訓練效率和泛化性能。在共享 MLP 中,每個任務都有自己的輸出層,但是多個輸出層共享相同的網絡權重。
共享 MLP 的主要作用是減少網絡中需要學習的參數數量,因為每個任務只需要擁有自己的輸出層,而特征提取層和中間層的參數是在多個任務之間共享的,因此可以減少每個任務需要學習的參數量。同時,由于多個任務共享相同的特征提取層,可以有效地利用不同任務之間相同的特征,從而提高神經網絡的泛化性能。
除了共享 MLP,神經網絡中還有其他一些可以在多個任務之間共享的神經網絡結構,如共享卷積層的卷積神經網絡(Shared Convolutional Neural Network, Shared CNN)等。這些共享網絡結構相較于單任務網絡和每個任務單獨擁有網絡結構的多任務網絡,具有更高的效率和更好的性能。
最近的一些工作已經開始解決直接處理大規模點云的任務。SPG [26]在應用神經網絡學習每個超點語義之前,將大型點云預處理為超級圖。FCPN [45]和PCT [7]都聯合收割機了體素化和點級網絡來處理大量點云。雖然它們實現了體面的分割精度,預處理和體素化步驟的計算量太大,部署在實時應用程序。
在本文中,我們的目標是設計一個內存和計算效率高的神經架構,它能夠直接處理大規模的3D點云在一個單一的通行證,而不需要任何預/后處理步驟,如體素化,塊分區或圖形構建。然而,這項任務極具挑戰性,因為它需要:
1)存儲器和計算上高效的采樣方法,以逐步下采樣大規模點云,以適應當前GPU的限制,以及2)有效的局部特征學習器,以逐步增加感受野大小,以保留復雜的幾何結構。為此,我們首先系統地證明了隨機采樣是深度神經網絡有效處理大規模點云的關鍵因素。然而,隨機采樣可能會丟棄關鍵信息,特別是對于具有稀疏點的對象。為了對抗隨機采樣的潛在不利影響,我們提出了一個新的和有效的本地特征聚合模塊來捕獲復雜的局部結構逐漸變小的點集。
- 現有方法的預處理和體素化步驟的計算量太大
在現有的采樣方法中,最遠點采樣和逆密度采樣最常用于小規模點云[44,60,33,70,15]。由于點采樣是這些網絡中的一個基本步驟,我們在第3.2節中研究了不同方法的相對優點,在那里我們看到常用的采樣方法限制了對大型點云的擴展,并成為實時處理的一個重要瓶頸。然而,我們認為隨機采樣是迄今為止最適合大規模點云處理的組件,因為它速度快,擴展效率高。隨機采樣不是沒有成本的,因為突出的點特征可能會被偶然丟棄,并且它不能直接用于現有網絡而不引起性能損失。為了克服這個問題,我們在第3.3節中設計了一個新的局部特征聚合模塊,該模塊能夠通過逐步增加每個神經層中的感受野大小來有效地學習復雜的局部結構。具體地,對于每個3D點,我們首先引入局部空間編碼(LocSE)單元來顯式地保留局部幾何結構。其次,我們利用細心的池自動保持有用的本地功能。第三,我們堆疊多個LocSE單元和注意力池作為一個擴張的殘留塊,大大增加了每個點的有效感受野。注意,所有這些神經組件都被實現為共享的MLP,因此具有顯著的存儲器和計算效率。
- 最遠點采樣和逆密度采樣最常用于小規模點云
- 隨機采樣是迄今為止最適合大規模點云處理的組件,因為它速度快,擴展效率高
隨機采樣會使得 突出的點特征可能會被偶然丟棄,設計了一個新的局部特征聚合模塊,該模塊能夠通過逐步增加每個神經層中的感受野大小來有效地學習復雜的局部結構
總的來說,基于簡單隨機采樣和有效的局部特征聚合器的原則,我們的高效神經架構RandLA-Net不僅比現有的大規模點云方法快200倍,而且還超過了Semantic 3D [17]和SemanticKITTI [3]基準測試中最先進的語義分割方法。圖1顯示了我們的方法的定性結果。我們的主要貢獻是:
- 我們分析和比較現有的采樣方法,確定隨機采樣作為最合適的組件,有效地學習大規模點云。
- 我們提出了一個有效的局部特征聚合模塊,通過逐漸增加每個點的感受野來保留復雜的局部結構。
- 我們在基線上展示了顯著的內存和計算增益,并在多個大規模基準測試中超越了最先進的語義分割方法。
- Related Work
為了從3D點云中提取特征,傳統方法通常依賴于手工制作的特征[11,47,25,18]。最近的基于學習的方法[16,43,37]主要包括基于投影,基于體素和基于點的方案,這里概述了這些方案。
基于投影的網絡。
為了利用2D CNN的成功,許多作品[30,8,63,27]將3D點云投影/展平到2D圖像上,以解決對象檢測的任務。然而,在投影期間可能丟失幾何細節。
基于體素的網絡
可以將點云體素化為3D網格,然后在[14,28,10,39,9]中應用強大的3D CNN。雖然它們在語義分割和目標檢測方面取得了領先的結果,但其主要局限性是計算量大,尤其是在處理大規模點云時。
基于點的網絡。
受PointNet/PointNet++ [43,44]的啟發,許多最近的作品引入了復雜的神經模塊來學習每個點的局部特征。這些模塊通常可以被分類為1)相鄰特征池化[32,21,70,69],2)圖形消息傳遞[57,48,55,56,5,22,34,31],3)基于內核的卷積[49,20,60,29,23,24,54,38],以及4)基于注意力的聚合[61,21,70,69]。68、66、42]。雖然這些網絡在小的點云上顯示出有希望的結果,但由于其高計算和內存成本,它們中的大多數不能直接擴展到大的場景。
與它們相比,我們提出的RandLA-Net在三個方面有所區別:
1)它僅依賴于網絡內的隨機采樣,從而需要少得多的存儲器和計算;
2)所提出的局部特征聚合器通過顯式地考慮局部空間關系和點特征,可以獲得連續更大的感受野,從而對學習復雜的局部模式更加有效和魯棒;
3)整個網絡僅由共享的MLP組成,而不依賴于任何昂貴的操作,例如圖構建和核化,因此對于大規模點云非常有效。
學習大規模點云。
SPG [26]將大型點云預處理為超點圖以學習每個超點語義。
最近的FCPN [45]和PCT [7]應用基于體素和基于點的網絡來處理大量點云。然而,圖分區和體素化兩者在計算上都是昂貴的。相比之下,我們的RandLA-Net是端到端可訓練的,不需要額外的前/后處理步驟。
- RandLA-Net
Overview
如圖2所示,給定一個具有數百萬個點的大規模點云,跨越數百米,要用深度神經網絡處理它,不可避免地需要在每個神經層中對這些點進行漸進和有效的下采樣,而不會丟失有用的點特征。在我們的RandLA-Net中,我們建議使用簡單快速的隨機采樣方法來大大降低點密度,同時應用精心設計的局部特征聚合器來保留突出的特征。這允許整個網絡在效率和有效性之間實現極好的權衡。
?在RandLA-Net的每一層中,大規模的點云被顯著地下采樣,但能夠保留精確分割所必需的特征。
The quest for efficient sampling
現有的點采樣方法[44,33,15,12,1,60]可以大致分為啟發式和基于學習的方法。然而,仍然沒有標準的采樣策略,是適合于大規模的點云。因此,我們分析和比較它們的相對優點和復雜性如下。
啟發式抽樣
最遠點采樣(FPS):為了從具有N個點的大規模點云P中采樣K個點,FPS返回度量空間{p1 · · · pk · · · pK}的重新排序,使得每個pk是距離前k ? 1個點最遠的點。FPS在[44,33,60]中被廣泛用于小點集的語義分割。雖然它有一個很好的覆蓋整個點集,其計算復雜度為O(N2)。對于大規模點云(N 106),FPS在單個GPU上處理需要200秒1。這表明FPS不適合大規模點云。
逆密度重要性抽樣(IDIS):為了從N個點中采樣K個點,IDIS根據每個點的密度對所有N個點進行重新排序,然后選擇前K個點[15]。其計算復雜度約為O(N)。根據經驗,處理106個點需要10秒。與FPS相比,IDIS更有效,但對離群值更敏感。然而,它對于在實時系統中使用仍然太慢。
隨機采樣(RS):隨機采樣從原始N個點中均勻地選擇K個點。它的計算復雜度是O(1),這與輸入點的總數無關,即,它是恒定時間且因此固有地可縮放。與FPS和IDIS相比,無論輸入點云的規模如何,隨機采樣都具有最高的計算效率。處理106個點只需要0.004s。
Learning-based Sampling
基于發生器的采樣(GS):GS [12]學習生成一個小的點集來近似表示原始的大點集。然而,FPS通常用于在推理階段將生成的子集與原始集合進行匹配,從而產生額外的計算。在我們的實驗中,對106個點中的10%進行采樣需要長達1200秒。
基于連續松弛的采樣(CRS):CRS方法[1,66]使用重新參數化技巧將采樣操作放松到連續域以進行端到端訓練。特別地,基于全點云上的加權和來學習每個采樣點。當使用一遍矩陣乘法同時對所有新點進行采樣時,它會導致大的權重矩陣,從而導致無法負擔的存儲器成本。例如,估計需要超過300GB的內存占用來對106個點的10%進行采樣。
基于策略梯度的采樣(PGS):PGS將采樣操作公式化為馬爾可夫決策過程[62]。它順序地學習概率分布來采樣點。然而,當點云較大時,由于極大的探索空間,學習概率具有較高的方差。例如,對106個點的10%采樣,探索空間是C105 106,并且不太可能學習有效的采樣策略。我們經驗發現,如果PGS用于大的點云,網絡是難以收斂 。
總體而言,FPS、IDIS和GS在計算上過于昂貴,不能應用于大規模點云。CRS方法具有過多的內存占用,PGS很難學習。相比之下,隨機抽樣具有以下兩個優點:
1)它是顯著的計算效率,因為它對輸入點的總數是不可知的,
2)它不需要額外的存儲器用于計算。因此,我們安全地得出結論,隨機采樣是迄今為止最適合的方法處理大規模點云相比,所有現有的替代方案。然而,隨機采樣可能導致許多有用的點特征被丟棄。為了克服這個問題,我們提出了一個強大的本地特征聚合模塊,在下一節中介紹。
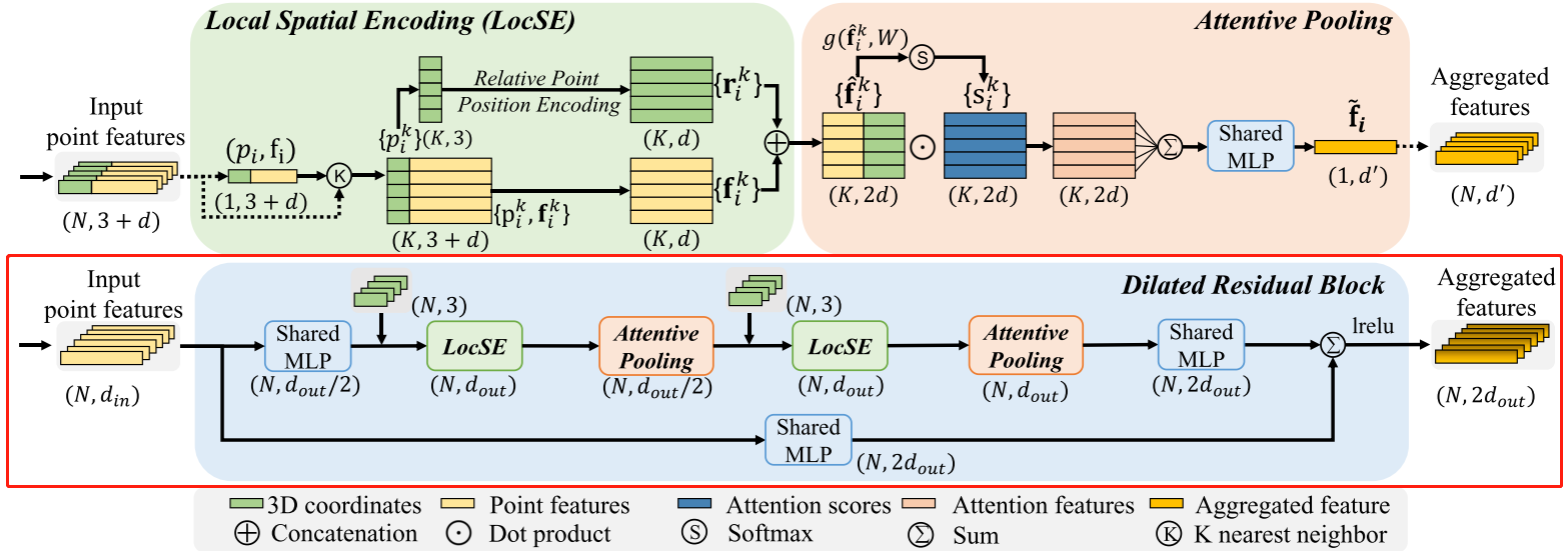
3.3. Local Feature Aggregation局部特征聚合?
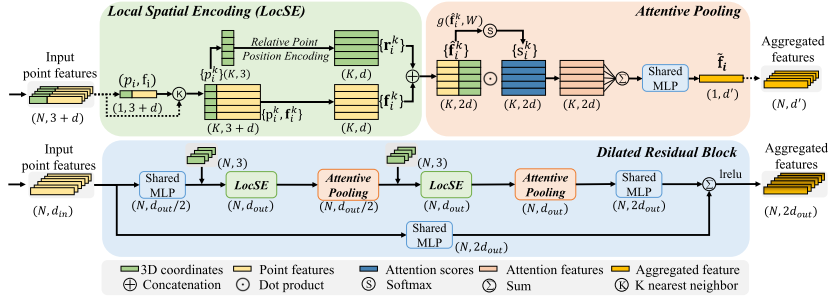
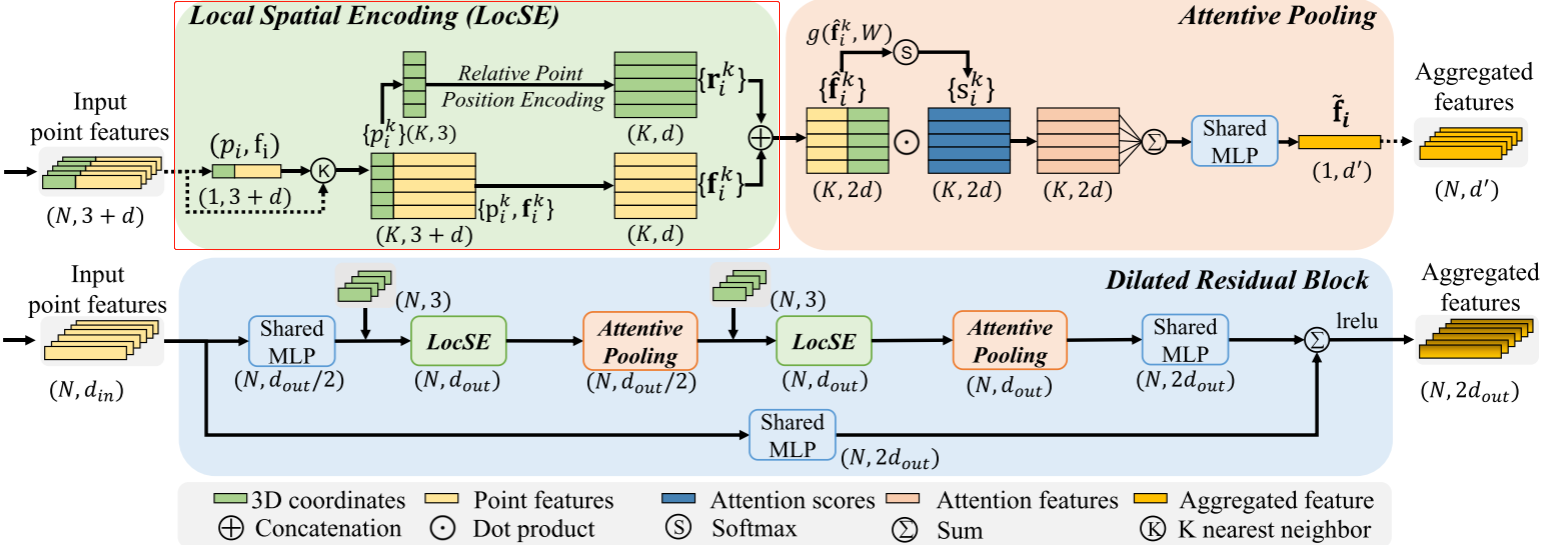
如圖3所示,我們的局部特征聚合模塊并行應用于每個3D點,它由三個神經單元組成:
1)局部空間編碼(LocSE)
2)注意池化
3)擴張的殘余塊
提出的局部特征聚合模塊。頂部面板示出了提取特征的位置空間編碼塊,以及基于局部上下文和幾何形狀對最重要的相鄰特征加權的注意池化機制。下圖示出了這些組件中的兩個如何鏈接在一起,以增加殘余塊內的感受野大小。
Local Spatial Encoding
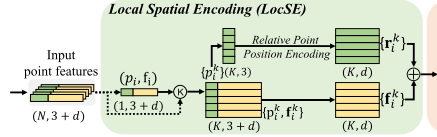
給定點云P連同每點特征(例如,原始RGB,或中間學習特征),該局部空間編碼單元顯式地嵌入所有相鄰點的x-y-z坐標,使得對應的點特征總是知道它們的相對空間位置。這允許LocSE單元顯式地觀察局部幾何圖案,從而最終有利于整個網絡有效地學習復雜的局部結構。特別地,該單元包括以下步驟:
1 Finding Neighbouring Points
對于第i個點,它的相鄰點首先通過簡單的K近鄰(KNN)算法收集效率。KNN基于逐點歐氏距離。
2 Relative Point Position Encoding?
對于中心點pi的最接近的K個點{p1 i · · · pk i · ·pKi}中的每一個,我們如下明確地對相對點位置進行編碼:
![]()
?其中pi和pk,i是點的x-y-z位置,是級聯操作,并且||·||計算相鄰點和中心點之間的歐幾里得距離。
似乎rk i是從冗余點位置編碼的。有趣的是,這往往有助于網絡學習本地特征,并在實踐中獲得良好的性能。
3?Point Feature Augmentation.
對于每個相鄰點pk i,將編碼的相對點位置rki與其對應的點特征fki連接,從而獲得增強的特征向量(fki)。
最后,LocSE單元的輸出是一組新的相鄰特征(Fi = {f1 i · · ·fk i · ·fKi},其明確地編碼中心點pi的局部幾何結構。我們注意到最近的工作[36]也使用點位置來改進語義分割。然而,在[36]中,位置用于學習點得分,而我們的LocSE顯式地編碼相對位置以增強相鄰點特征。
Attentive Pooling

該神經單元用于聚合相鄰點特征的集合(Fi)。現有作品[44,33]通常使用最大/平均池化來硬集成相鄰特征,導致大部分信息丟失。相比之下,我們轉向強大的注意力機制來自動學習重要的局部特征。特別是,受[65]的啟發,我們的專注池單元包括以下步驟。
1 Computing Attention Scores.?
給定局部特征集合Fi = {f1 i · · · ·fk i · · ·fK i },我們設計一個共享函數g()來學習每個特征的唯一注意力分數。基本上,函數g()由共享MLP和softmax組成。其正式定義如下:?
?其中W是共享MLP的可學習權重。?
在機器學習中,注意力機制是一種常見的神經網絡技術,可以為每個輸入特征賦予不同的權重,從而使得網絡更加關注對于當前任務更為重要的特征。其中的
- 注意力分數:指為每個特征分配的權重,它可以體現每個特征對于當前任務的重要性程度。
- 共享函數g學習每個特征的唯一注意力分數,說明該函數能夠學習到每個特征應該被分配的權重,并將這些權重應用于網絡的后續計算中,從而提高網絡的性能。
Attentive Pooling是一種神經網絡結構,常用于處理自然語言處理(NLP)任務中的文本序列數據。它的主要作用是在池化階段融入注意力機制,從而使神經網絡更加關注重要的信息,提高模型性能。
在傳統的池化操作中,通常使用簡單的聚合函數(如平均或最大池化)將一定范圍內的輸入信息聚合成一個代表性的輸出。但在實際應用中,不同位置或不同時間的輸入信息對于模型的判斷和輸出可能是不同的,因此簡單的池化操作可能會丟失一些重要的信息。
Attentive Pooling通過引入注意力機制來解決這個問題。它通過將輸入序列中的每個元素與一個可學習的權重向量相乘,并將結果歸一化得到每個元素的注意力分數。然后,將這些分數作為權重加權聚合,并將聚合結果作為神經網絡的輸出。這種方式使網絡能夠自適應地選擇重要的信息,同時減少池化過程中對有用信息的丟失。
通過使用Attentive Pooling,神經網絡能夠更好地處理不同位置和時間的信息,提高模型的準確性和性能。
?
Weighted Summation.
學習的注意力分數可以被視為自動選擇重要特征的軟掩模。形式上,這些特征被加權求和如下:?
?總之,給定輸入點云P,對于第i個點pi,我們的LocSE和注意力池單元學習聚合其K個最近點的幾何圖案和特征,并最終生成信息特征向量~ fi。
Dilated Residual Block 殘差塊

由于大的點云將被基本上下采樣,因此期望顯著地增加每個點的感受場,使得輸入點云的幾何細節更可能被保留,即使一些點被丟棄。如圖3所示,受成功的ResNet [19]和有效的擴張網絡[13]的啟發,我們將多個LocSE和Attentive Pooling單元與跳過連接堆疊為擴張的殘差塊。
感受野(Receptive Field)指的是神經網絡中的某個神經元對于輸入的局部感受范圍,即它能接受到的輸入數據的區域大小。在卷積神經網絡中,每個卷積層的神經元都會通過卷積核在輸入圖像上掃描得到一個輸出值,同時也會受到前一層神經元輸出的影響。由于神經網絡在不同層次提取不同抽象層次的特征,因此每一層的感受野大小不同,通常隨著網絡層數增加而增大。
具體來說,感受野可以分為三種類型:局部感受野、全局感受野和有效感受野。
- 局部感受野是指單個神經元對于輸入數據的局部區域,
- 全局感受野是指整個網絡對于輸入數據的完整感受范圍,
- 而有效野可以理解為神經元實際上能夠接受到的輸入數據的范圍,通常比全局感受野要小。通過了解感受野的大小和類型,可以更好地設計和優化神經網絡的結構,從而提高模型的性能。
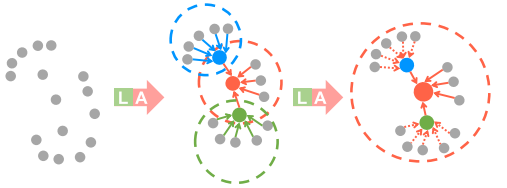
為了進一步說明我們的擴張殘差塊的能力,圖4示出了紅色3D點在第一LocSE/Attentive Pooling操作之后觀察K個相鄰點,并且然后能夠從多達K2個相鄰點,即,第二個之后的兩個街區。
?擴張的殘余塊的圖示,其顯著增加了每個點的感受野(虛線圓),彩色點表示聚合特征。L:局部空間編碼,A:注意力集中。
這是一種通過特征傳播擴大感受野和擴大有效鄰域的廉價方式。從理論上講,我們堆疊的單位越多,這個方塊的威力就越大,因為它的范圍越來越大。然而,更多的單元將不可避免地犧牲整體計算效率。此外,整個網絡很可能會過度裝配。在我們的RandLA-Net中,我們簡單地堆疊兩組LocSE和Attentive Pooling作為標準殘差塊,實現了效率和有效性之間的滿意平衡。
總體而言,我們的本地功能聚合模塊的目的是有效地保留復雜的本地結構,通過明確考慮相鄰的幾何形狀和顯著增加的感受野。此外,該模塊僅由前饋MLP組成,因此計算效率高。
Implementation
我們通過堆疊多個本地特征聚合模塊和隨機采樣層來實現RandLA-Net。詳細的體系結構見附錄。我們使用帶有默認參數的Adam優化器。初始學習率被設置為0.01,并且在每個時期之后降低5%。最近點的數量K被設置為16。為了并行訓練我們的RandLA-Net,我們從每個點云中采樣固定數量的點(105)作為輸入。在測試過程中,整個原始點云被饋送到我們的網絡中,以推斷每個點的語義,而無需進行幾何或塊劃分等預/后處理。所有實驗均在NVIDIA RTX 2080 Ti GPU上進行。
- Experiments
Efficiency of Random Sampling
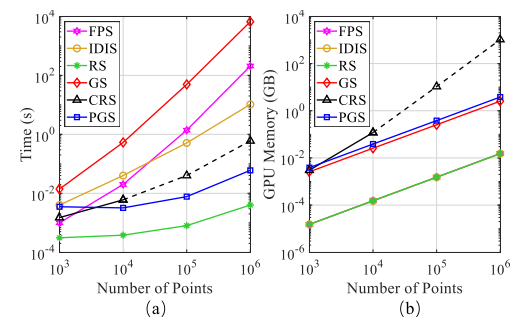
在本節中,我們對現有采樣方法(包括FPS、IDIS、RS、GS、CRS和PGS)的效率進行了實證評估,這些方法已在第3.2節中討論。具體地,我們進行了以下4組實驗。
第1組。給定一個小規模的點云(大約103個點),我們使用每種采樣方法對其進行逐步下采樣。具體地,點云通過五個步驟進行下采樣,其中在單個GPU上的每個步驟中僅保留25%的點,即四倍抽取比。這意味著最后只剩下(1/4)5 × 103個點。這種下采樣策略模擬了PointNet++ [44]中使用的過程。對于每種采樣方法,我們總結其時間和內存消耗以進行比較。
圖5??不同采樣方法的時間和內存消耗。虛線表示由于有限的GPU存儲器而估計的值。?
第2/3/4組。點的總數向大規模增加,即,分別為104、105和106點。我們使用與第1組相同的五個采樣步驟。?
?圖5比較了處理不同比例點云的每種采樣方法的總時間和內存消耗。可以看出:
1)對于小規模點云(103),所有采樣方法往往具有相似的時間和內存消耗,并且不太可能引起沉重或有限的計算負擔。
2)對于大規模的點云(106),FPS/IDIS/GS/CRS/PGS要么非常耗時,要么占用內存。相比之下,隨機采樣總體上具有上級的時間和內存效率。該結果清楚地表明,大多數現有網絡[44,33,60,36,70,66]只能在小塊點云上進行優化,主要是因為它們依賴于昂貴的采樣方法。基于此,我們在RandLA-Net中使用了高效的隨機采樣策略。
Efficiency of RandLA-Net
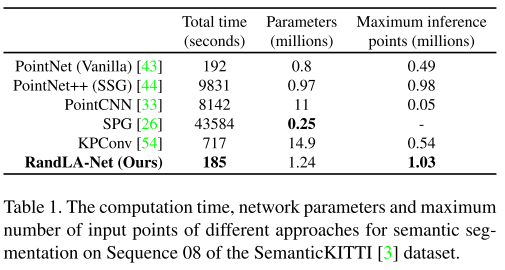
在本節中,我們系統地評估了我們的RandLA-Net在真實世界的大規模點云語義分割上的整體效率。特別地,我們在SemanticKITTI [3]數據集上評估RandLA-Net,獲得我們的網絡在Sequence 08上的總時間消耗,其中共有4071個點云掃描。我們還評估了在同一數據集上最近的代表性作品[43,44,33,26,54]的時間消耗。為了公平的比較,我們饋送相同數量的點(即,81920)從每個掃描到每個神經網絡。
此外,我們還評估了RandLA-Net的內存消耗和基線。特別是,我們不僅報告每個網絡的參數總數,而且還測量每個網絡可以在單次傳遞中作為輸入的最大3D點數量,以推斷每個點的語義。注意,所有實驗都在具有AMD 3700X@3.6GHz CPU和NVIDIA RTX 2080 Ti GPU的同一機器上進行。
表1定量地顯示了不同方法的總時間和內存消耗。可以看出,
1)SPG [26]具有最少的網絡參數,但由于昂貴的幾何劃分和超級圖構造步驟,處理點云所花費的時間最長;
2)PointNet++ [44]和PointCNN [33]在計算上也很昂貴,主要是因為FPS采樣操作;
3)PointNet [43]和KPConv [54]無法獲取非常大規模的點云(例如106個點),這是由于它們的存儲器低效操作。
4)由于簡單的隨機采樣和高效的基于MLP的本地特征聚合器,我們的RandLA-Net花費最短的時間(平均185秒,平均4071幀→大約22 FPS)來推斷每個大規模點云(最多106個點)的語義標簽。
Semantic Segmentation on Benchmarks
在本節中,我們評估了RandLA-Net在三個大規模公共數據集上的語義分割:室外Semantic 3D [17]和SemanticKITTI [3],以及室內S3 DIS [2]。
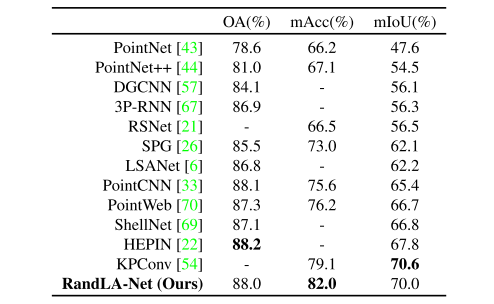
Evaluation on Semantic3D.?
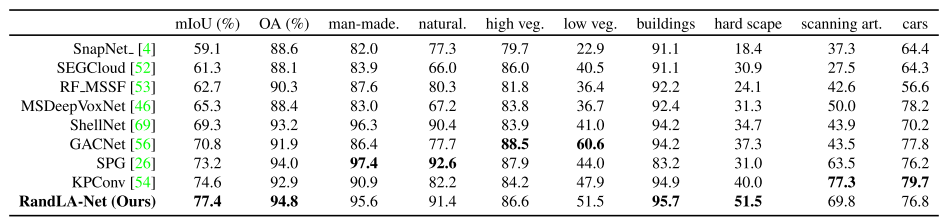
Semantic3D數據集[17]由15個用于訓練的點云和15個用于在線測試的點云組成。每個點云最多有10^8個點,在真實世界的3D空間中覆蓋160×240×30米。原始3D點屬于8類,并且包含3D坐標、RGB信息和強度。我們只使用3D坐標和顏色信息來訓練和測試我們的RandLANet。所有類別的平均相交度(mIoU)和總體準確度(OA)被用作標準度量。為了進行公平比較,我們僅包括最近發表的強基線結果[4,52,53,46,69,56,26]和當前最先進的方法KPConv [54]。
表2給出了不同方法的定量結果。RandLA-Net在mIoU和OA方面明顯優于所有現有方法。值得注意的是,RandLANet還在八個類別中的六個類別上實現了上級的性能,除了低植被和掃描藝術。
?表2. Semantic 3D上不同方法的定量結果(減少-8)[17]。只有最近公布的方法進行比較。于二零二零年三月三十一日查閱。
?SemanticKITTI上不同方法的定量結果[3]。僅比較最近發表的方法,并且從在線單掃描評估軌道獲得所有分數。于二零二零年三月三十一日查閱。?
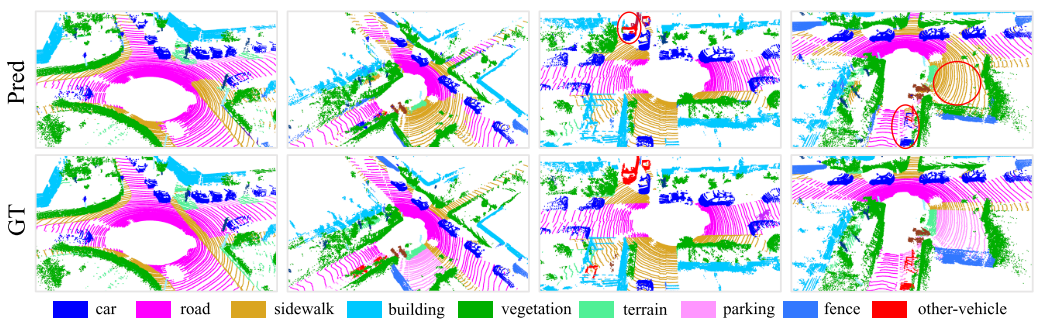
?RandLA-Net在SemanticKITTI [3]驗證集上的定性結果。紅色圓圈表示失敗案例。
Evaluation on SemanticKITTI.
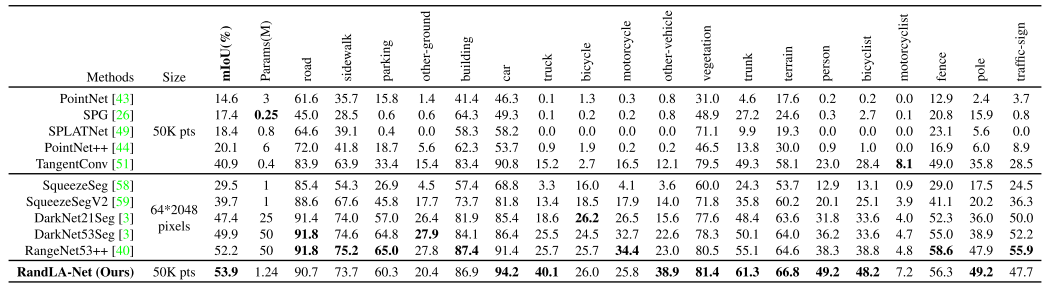
SemanticKITTI [3]由屬于21個序列的43552個密集注釋的LIDAR掃描組成。每個掃描是一個大規模的點云,包含10^5個點,在3D空間中跨度高達160×160×20米。正式地,序列00 07和09 10(19130次掃描)用于訓練,序列08(4071次掃描)用于驗證,序列11 21(20351次掃描)用于在線測試。原始3D點僅具有3D坐標而不具有顏色信息。超過19個類別的mIoU分數被用作標準度量。
表3顯示了我們的RandLANet與兩個最近方法家族的定量比較,即1)基于點的方法[43,26,49,44,51]和2)基于投影的方法[58,59,3,40],圖6顯示了RandLA-Net在驗證分割上的一些定性結果。可以看出,我們的RandLA-Net大大超過了所有基于點的方法[43,26,49,44,51]。我們還優于所有基于投影的方法[58,59,3,40],但并不顯著,主要是因為RangeNet++ [40]在小對象類別(如交通標志)上實現了更好的結果。然而,我們的RandLA-Net的網絡參數比RangeNet++ [40]少40倍,并且計算效率更高,因為它不需要昂貴的前/后投影步驟。
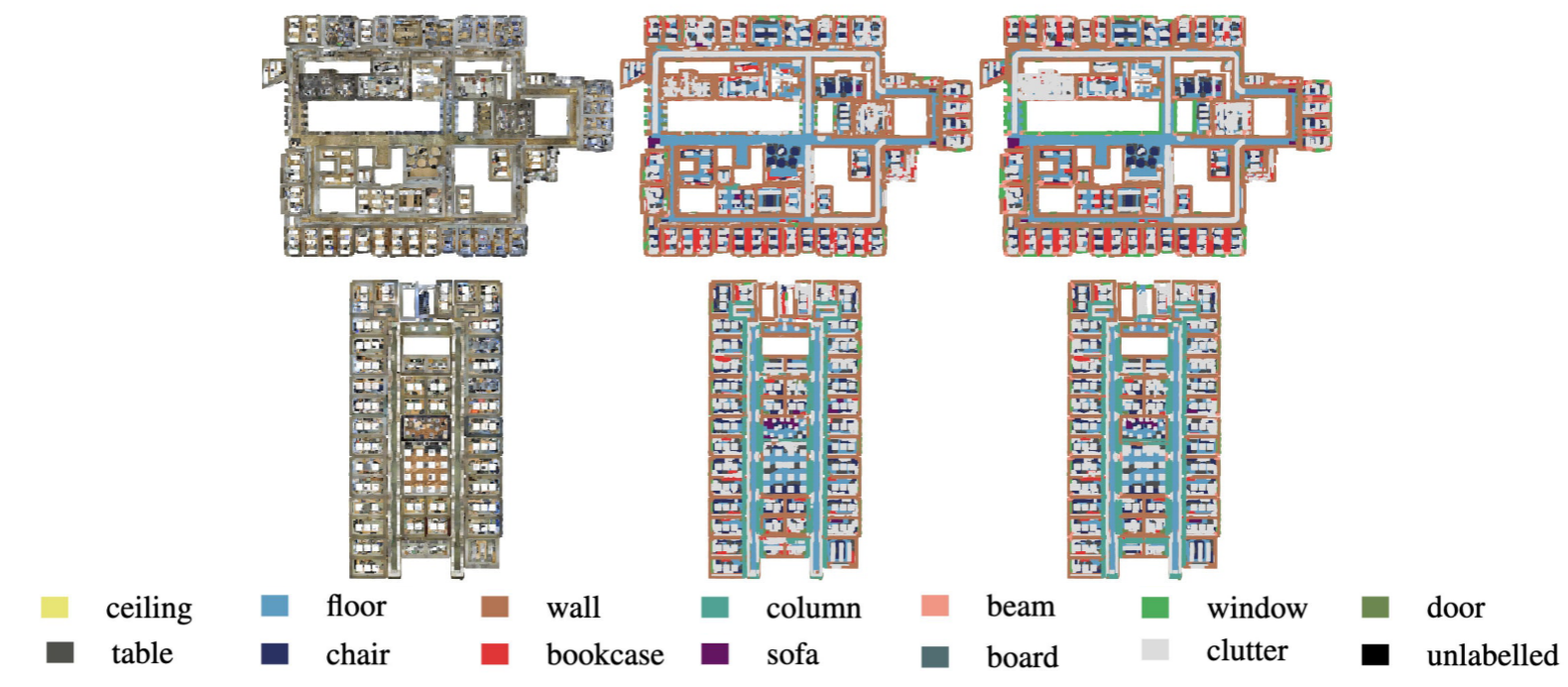
Evaluation on S3DIS
S3DIS數據集[2]由屬于6個大區域的271個房間組成。每個點云都是一個中等大小的單間(20×15×5米),其中包含密集的3D點。為了評估我們的RandLA-Net的語義分割,我們在實驗中使用標準的6折交叉驗證。比較了總共13個類別的平均IoU(mIoU)、平均類別準確度(mAcc)和總體準確度(OA)。
如表4所示,我們的RandLA-Net實現了與最先進的方法同等或更好的性能。注意,這些基線[44,33,70,69,57,6]中的大多數傾向于使用復雜但昂貴的操作或采樣來優化小塊上的網絡(例如,1×1米)的點云,而相對較小的房間在它們的優勢被分成小塊。相比之下,RandLA-Net將整個房間作為輸入,并且能夠在單次傳遞中高效地推斷每點語義。
?S3DIS數據集上不同方法的定量結果[2](6倍交叉驗證)。僅包括最近公布的方法。?
Ablation Study 消融研究
由于在第4.1節中充分研究了隨機采樣的影響,因此我們對局部特征聚合模塊進行了以下消融研究。所有消融的網絡都在序列00 07和09 10上訓練,并在SemanticKITTI數據集的序列08上測試[3]。
(1) Removing local spatial encoding (LocSE).?
該單元使每個3D點能夠明確地觀察其局部幾何形狀。在移除locSE之后,我們直接將局部點特征饋送到后續的關注池中。?
(2~4) Replacing attentive pooling by max/mean/sum?pooling.
注意池化單元學習自動聯合收割機所有局部點特征。相比之下,廣泛使用的最大值/平均值/總和池往往難以選擇或聯合收割機特征,因此它們的性能可能是次優的。
(5) Simplifying the dilated residual block.
擴張的殘余塊堆疊多個LocSE單元和注意池,基本上擴張每個3D點的感受野。通過簡化該塊,我們每層僅使用一個LocSE單元和注意池化,即我們不像在原始RandLA-Net中那樣鏈接多個塊。
表5比較了所有消融網絡的mIoU評分。由此可見:
1)最大的影響是由鏈式空間嵌入和注意池化塊的移除引起的。這在圖4中突出顯示,圖4示出了使用兩個鏈式塊如何允許信息從更寬的鄰域傳播,即,大約K2點,而不是只有K點。這對于隨機采樣尤其重要,因為不能保證保留特定的點集。
2)局部空間編碼單元的去除示出了對性能的下一個最大影響,表明該模塊對于有效地學習局部和相對幾何上下文是必要的。
3)移除注意力模塊由于不能有效地保留有用的特征而降低了性能。從這項消融研究中,我們可以看到所提出的神經單元如何相互補充,以達到我們最先進的性能。
- Conclusion
在本文中,我們證明了它是可能的,有效地分割大規模的點云,通過使用一個輕量級的網絡架構。與依賴于昂貴的采樣策略的大多數當前方法相反,我們在我們的框架中使用隨機采樣來顯著減少內存占用和計算成本。還引入了一個局部特征聚合模塊,以有效地保留有用的功能,從廣泛的鄰里。在多個基準上的大量實驗證明了我們的方法的高效率和最先進的性能。通過借鑒最近的工作[64]以及實時動態點云處理[35],擴展我們的框架用于大規模點云上的端到端3D實例分割將是有趣的。
致謝:這項工作得到了中國國家留學基金管理理事會(CSC)獎學金的部分支持。國家自然科學基金項目(No. 61972435)、廣東省自然科學基金(2019A1515011271)、深圳市科技創新委員會。

—— 編譯C程序)
)




學習GPU Instancing)

】)







)

:初識機器學習)