jieba庫的使用:
? ? ? jieba庫是一款優秀的 Python 第三方中文分詞庫,jieba?支持三種分詞模式:精確模式、全模式和搜索引擎模式,下面是三種模式的特點。
? ? ?精確模式:試圖將語句最精確的切分,不存在冗余數據,適合做文本分析
? ? ?全模式:將語句中所有可能是詞的詞語都切分出來,速度很快,但是存在冗余數據
? ? ? 搜索引擎模式:在精確模式的基礎上,對長詞再次進行切分.
?
?
jieba的使用
# -*- coding: utf-8 -*-
import jieba
seg_str = "好好學習,天天向上。"
print("/".join(jieba.lcut(seg_str))) # 精簡模式,返回一個列表類型的結果
print("/".join(jieba.lcut(seg_str, cut_all=True))) # 全模式,使用 'cut_all=True' 指定?
print("/".join(jieba.lcut_for_search(seg_str))) # 搜索引擎模式

?
?
jieba庫對英文單詞的統計
# -*- coding: utf-8 -*-
def get_text():
txt = open("1.txt", "r", encoding='UTF-8').read()
txt = txt.lower()
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~':
txt = txt.replace(ch, " ") # 將文本中特殊字符替換為空格
return txt
file_txt = get_text()
words = file_txt.split() # 對字符串進行分割,獲得單詞列表
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())?
items.sort(key=lambda x: x[1], reverse=True)
for i in range(5):
word, count = items[i]
print("{0:<5}->{1:>5}".format(word, count))
?
?
詞云的制作
完成安裝jieba , wordcloud ,matplotlib
(1)打開taglue官網,點擊import words,把運行的結果copy過來。
(2)選擇形狀,在這里是網上下載的圖片進行的導入。
(3)選擇字體。
(4)點擊Visualize生成圖片。

from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jiebadef create_word_cloud(filename):text = open("哈姆雷特.txt".format(filename)).read()wordlist = jieba.cut(text, cut_all=True) wl = " ".join(wordlist)wc = WordCloud(background_color="black",max_words=2000,font_path='simsun.ttf',height=1200,width=1600,max_font_size=100,random_state=100,)myword = wc.generate(wl) plt.imshow(myword)plt.axis("off")plt.show()wc.to_file('img_book.png')if __name__ == '__main__':create_word_cloud('mytext') 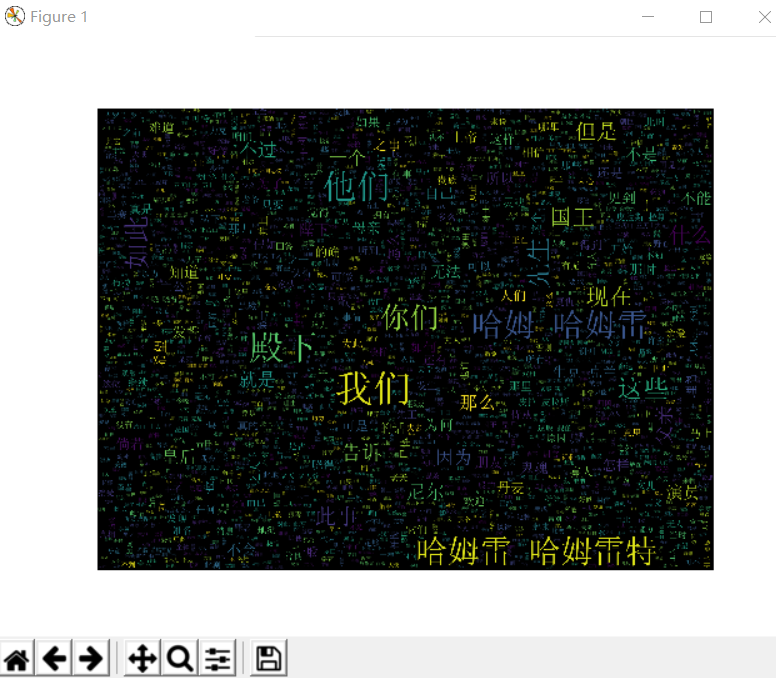
?




使用JDBC向數據庫發起查詢請求)
下刪除Ubuntu啟動項)
)

神舟戰神游戲本風扇狂轉掉電大寫燈狂閃維修實例...)


)





)

