中文分詞是中文自然語言處理中的重要的步驟,有一個更高精度的中文分詞模型會顯著提升文檔分類、情感預測、社交媒體處理等任務的效果[1]。
Pubseg是基于BiLSTM中文分詞工具,基于ICWS2005PKU語料訓練集訓練而成,其優點在于在ICWS2005-PKU語料下訓練精度達到99.99%,測試集上精度94.34%,召回94.21%, F1值94.26%。
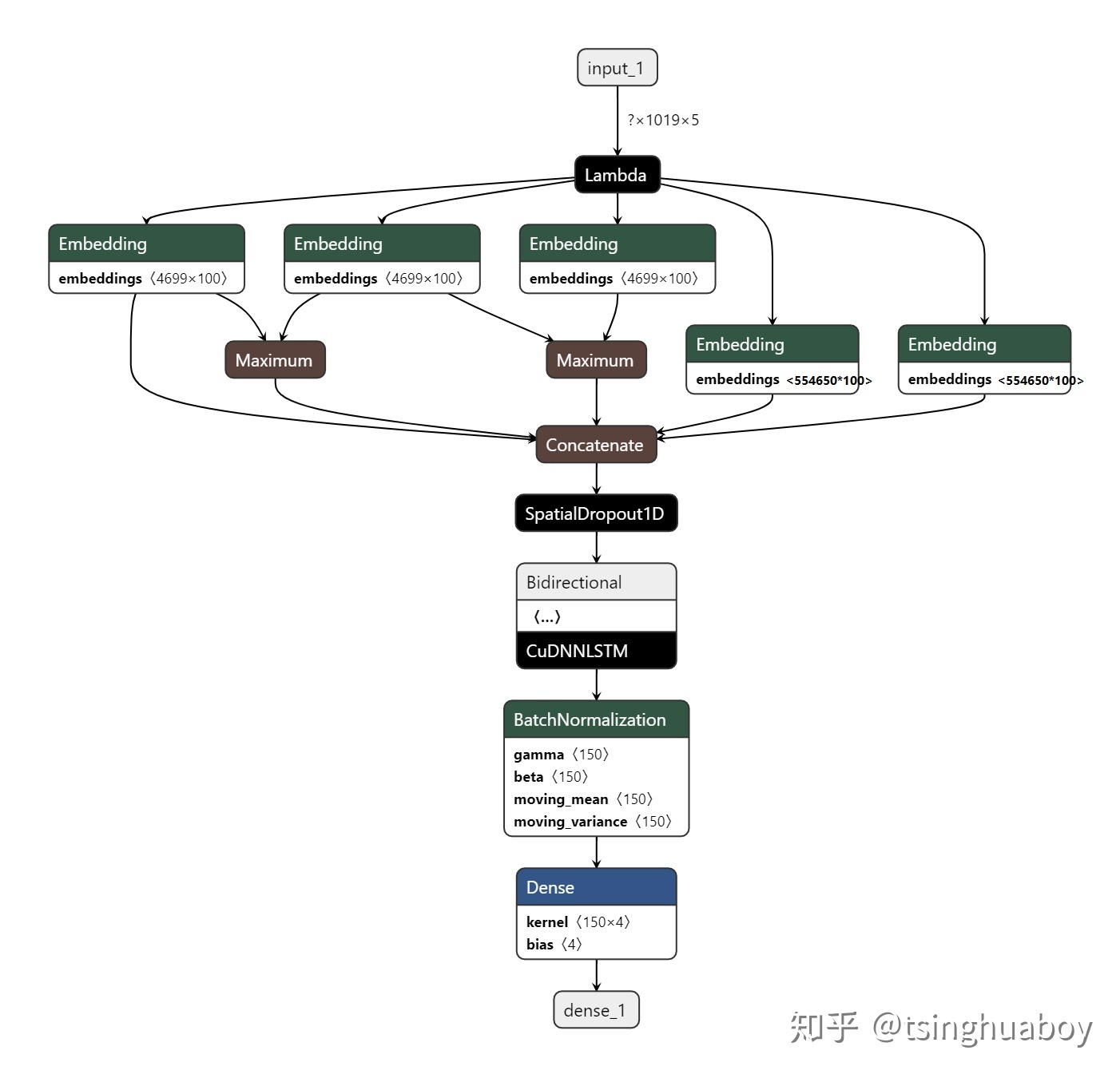
分詞模型是基于Keras設計,其詳細描述見[2],其模型結構如圖1:
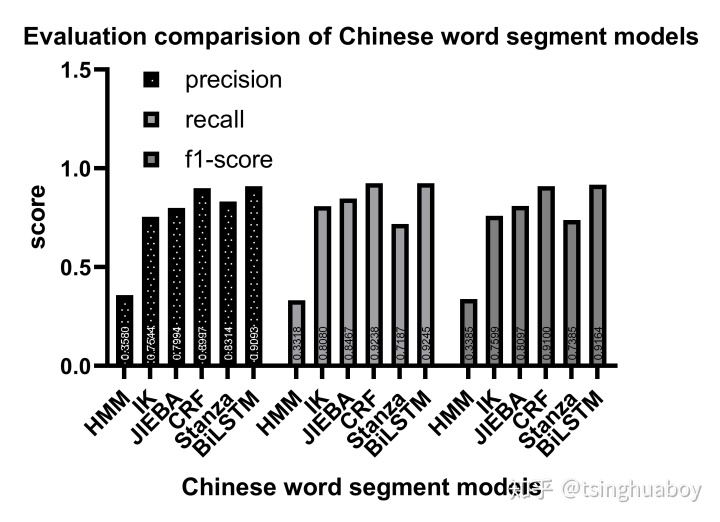
在ICWS2005PKU測試集下比較jieba、IK、pkuseg、Stanza的評價,其對比結果如圖2所示:
下面介紹如何安裝使用Pubseg工具。準備工作,準備python3.6以上版本。安裝依賴: numpy==1.18.1, keras==2.2.4, tensorflow-gpu==1.15.2。
下載Pubseg中文分詞模型,由于模型太大,結構文件與權重文件分開存儲。下載地址如下:https://pan.baidu.com/s/1LnjZD9HVQ164uAe0-XpPsg;提取碼:zm41;也可以掃碼下載,下載地址見圖3:

模型下載后,需要下載Pubseg代碼git clone https://github.com/ShenDezhou/LSTM。
下面介紹基本用法,
首先,創建一個PUB_BiLSTM_BN類的對象bilstm;
其次,通過命令行指定字典文件和模型文件路徑:-u <unigramfile> -b <bigramfile> -a <archfile> -w <weightfile>,默認路徑為:
UNIGRAM = 'pku_dic/pku_dict.utf8' #字典
BIGRAM = 'pku_dic/pku_bigram.utf8' #二字詞典
MODELARCH = 'keras/B20-E60-F5-PU-Bi-Bn-De.json' #keras模型
MODELWEIGHT = "keras/B20-E60-F5-PU-Bi-Bn-De-weights.h5" #keras權重再次,調用對象bilstm的加載Keras模型函數loadKeras;
最后,調用對象bilstm的cut函數,入參為待分詞中文文本,返回結果為空格分隔后的中文文本。
完整代碼如下:
bilstm = PUB_BiLSTM_BN()
bilstm.loadKeras()
segs = bilstm.cut(["我昨天去清華大學。", "他明天去北京大學,再后天去麻省理工大學。"])完整代碼見[3]。
模型的性能如下,在ICWS2005-PKU語料下訓練精度達到99.99%,測試集上精度94.34%,召回94.21%, F1-值94.26%。
模型加載性能、推理性能:
CPU:Intel i56300HQ 2.30Ghz
SSD: Samsung 970 EVO 1TB M.2 NVMe PCIe SSD
GPU:GeForce GTX 950M-DDR3
字典加載時間:176ms
模型及權重加載時間:1m45s664ms
推理性能:
47.47ms/字 #以"我 昨天 去 清華 大學 。他 明天 去 北京 大學 , 再 后天 去 麻省 理工大學 。"為測試條件;
13.30ms/行 #以PKUTEST1944行 為測試條件。
結論,本文提出了一種基于預訓練字與二字向量的BiLSTM中文分詞工具Pubseg,其性能在PKU測試集上取得了超過同類分詞模型的效果。
[1]待論證。
[2]基于Pretrained-UnigramBigram的中文分詞模型 https://zhuanlan.zhihu.com/p/111681404
[3]Pubseg:一種單雙字串的BiLSTM中文分詞工具 https://github.com/ShenDezhou/LSTM

)





![[ZJOI2019]麻將](http://pic.xiahunao.cn/[ZJOI2019]麻將)

)






)
![[Linux]幾個armhf的ubuntu源](http://pic.xiahunao.cn/[Linux]幾個armhf的ubuntu源)

