目錄
1. 數據庫索引
1.1 索引的概念
1.2 索引的特點
1.3 索引查詢對比普通的查詢
1.4 索引的操作
?1.5 索引的原理
?1.6 B樹
1.7 B+樹?
1.8 B+樹的優點
1. 數據庫索引
1.1 索引的概念
數據庫的索引是一種特殊的數據結構,里面包含著數據表中所有記錄的引用,可以對表中一列或者多列創建索引并指定類型
可以將數據庫的索引想象為書的目錄,可以幫助數據庫系統快速定位和訪問表中的特定數據,而不必掃描整個表。
1.2 索引的特點
- 通過索引可以直接定位數據,不需要逐個掃描數據表中的記錄,可以提高數據庫的查詢性能
- 數據表在進行插入/更新/刪除操作時,因為要更新索引,導致效率降低
- 由于索引需要單獨存儲,需要引入額外的存儲開銷
- 一般建議高頻的查詢建立索引(如:根據用戶名—密碼)
- 在實際的工作中,查詢使用的頻率遠遠高于數據的增加/刪除/修改
1.3 索引查詢對比普通的查詢
普通select查詢
- 需要遍歷整個表
- 將遍歷的當前行帶入條件中,看條件是否成立
- 如果條件成立,則將這一行保留,不成立則會跳過
索引查詢
- 不需要遍歷整個表
- 只需要讀取索引頁和少量的數據頁
- 并通過索引數據結構(B+樹)快速定位數據
?索引屬于針對查詢操作進行的優化手段,可以通過索引來加快查詢的速度,由于數據存儲在硬盤中,如果每次插敘都訪問硬盤,數據從硬盤中加載進入內存,進行對比,這一系列操作開銷雖然不大,但是數據量如果非常多的話,則會導致開銷很大,所以引入索引是很有必要的
1.4 索引的操作
(1)查看索引
show index from 表名;
(2)創建索引
create index 索引名 on 表名(字段名);
(3)刪除索引
drop index 索引名 on 表名;
注意:
- 一個索引是針對一個列來指定的,只有這一列進行查詢的時候,查詢速度才會被優化
- 一個表中可以存在多個索引
- 創建索引一般在創建表的時候就需要規定好索引
- 如果現有的數據很多,整個時候如果增加一個索引,很有可能會造成數據庫的崩潰
?1.5 索引的原理
- 索引的實現肯定是依靠數據結構,但是我們平常使用的數據結構,并不適合
- 順序表:適合通過下表訪問和尾插
- 鏈表:適合中間插入和刪除,不適合查詢
- 棧/隊列/堆:這些更不適合
- 二叉搜索樹: 由于平衡性問題,查詢效率會降低(不穩定),硬盤數據的存儲效率低,查詢效率低
- 哈希表:只適合點到點的精準查詢,不能進行范圍查詢和模糊查詢
- 紅黑樹:雖然可以精準查詢和模糊查詢,但是由于樹的高度較高,查詢訪問的IO訪問次數會變多
由于常見的這些數據結構,都不適合數據庫操作,故引入了新的數據結構—B+樹(N叉搜索樹)
?1.6 B樹
在了解B+樹之前,先了解B樹
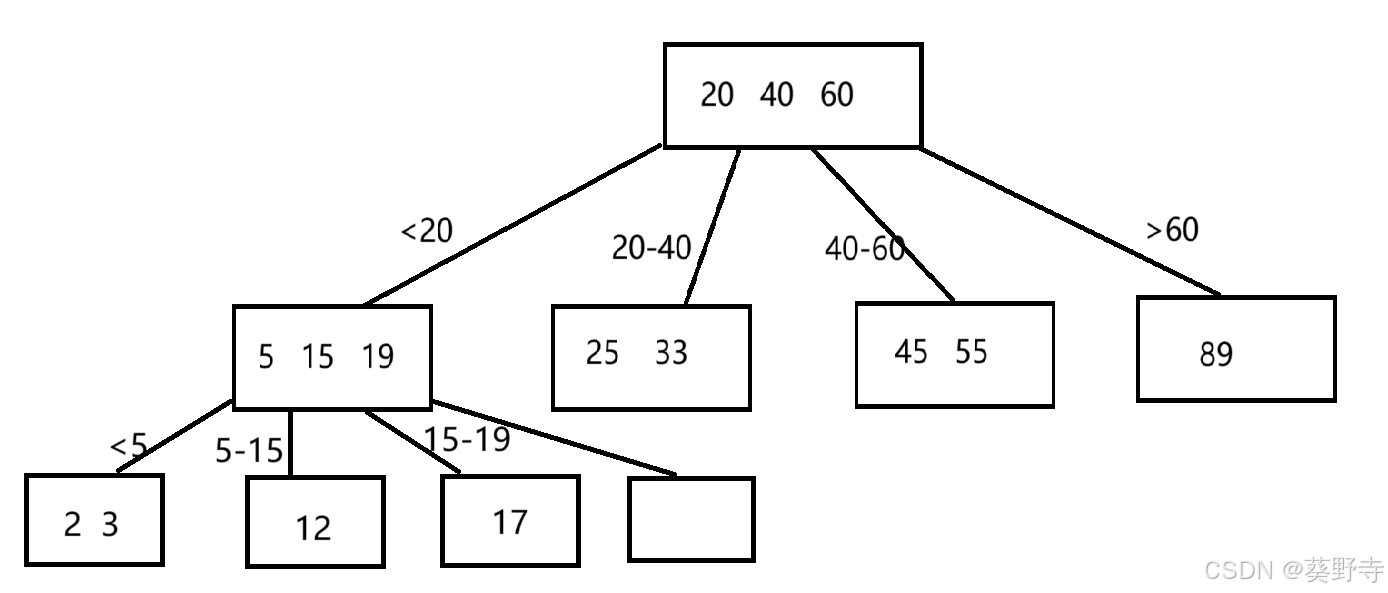
類似于這樣的結構,就是B樹
- 節點內部Key按順序排列,自動保持樹的高度平衡,所有葉子節點位于同一層,每個節點可以有多個子節點
- 每一個節點可以存在多個Key?,但是也不是無限存儲,到達一定的規模會觸發節點的分裂,刪除元素到達一定的數據也會觸發合并
- 一個節點上保存N個key值就可以劃分出N+1個區間,每個區間都可以衍生出一系列的子樹
- 像這些節點,都存儲在硬盤的一塊區域中,一次讀取節點,意味著讀取出多個Key,再進行幾次比較,就可以快速找到自己想要的數值
1.7 B+樹?
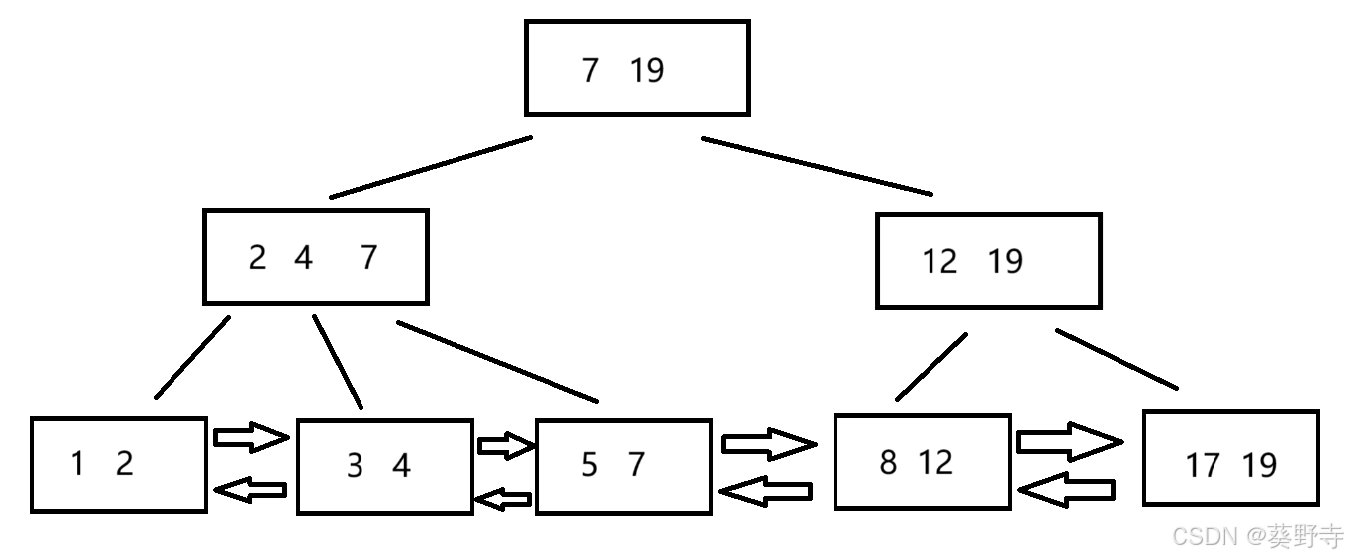
- 所有的數據都保存在葉子節點中,除葉子結點外的節點,不保存數據,只是用來索引
- 節點中,最右邊為最大值(根節點中,最右邊為整個元素中的最大值)
- 無論增加或刪除什么元素,都需要保證根節點的最右邊是最大元素
- 每一個父節點元素都出現在子節點中,是子節點最大(或最小)元素。
?在進行查詢的時候,從根節點觸發,判定要查詢的數據,在節點的那個區間,決定往哪里走,葉子節點之間,通過雙鏈表進行連接,方便數據集合之間按照范圍進行查詢,也可以快速進行刪除和增加等操作
1.8 B+樹的優點
相比于B樹,紅黑樹來說
- N叉搜索樹,樹的高度有限,降低了IO訪問次數
- 由于葉子節點之間的鏈表結構,方便增加和刪除操作
- 所有葉子節點之間屬于有序鏈表,方便范圍查詢。
- 由于葉子節點存放數據,查詢開銷非常的穩定(穩定性好)



詳細介紹)
)
(單片機選型主要考慮的參數與因素))
提示詞工程介紹)
相比,有什么優缺點?)




的MCAL配置之GtmCfg)

 ,功能全面、界面美觀)
安裝)



