文章目錄
- 01. Kafka 消費者分區再均衡是什么?
- 02. Kafka 消費者分區再均衡的觸發條件?
- 03. Kafka 消費者分區再均衡的過程?
- 04. Kafka 如何判定消費者已經死亡?
- 05. Kafka 如何避免消費者的分區再均衡?
- 06. Kafka 消費者分區再均衡有什么影響?
- 07. Kafka 消費者分區再均衡的兩種機制?
- 08. kafka 消費者分區再均衡協議
- 09. kafka 消費者分區再均衡流程
- 10. Kafka 消費者組固定成員是什么?
- 11. Kafka 消費者分區再均衡的4種場景
01. Kafka 消費者分區再均衡是什么?
消費者群組里的消費者共享主題分區的所有權。當一個新消費者加入群組時,它將開始讀取一部分原本由其他消費者讀取的消息。當一個消費者被關閉或發生崩潰時,它將離開群組,原本由它讀取的分區將由群組里的其他消費者讀取。
分區的所有權從一個消費者轉移到另一個消費者的行為稱為再均衡。再均衡非常重要,它為消費者群組帶來了高可用性和伸縮性(你可以放心地添加或移除消費者)。不過,在正常情況下,我們并不希望發生再均衡。
Rebalance 本質上是一組協議,它規定了一個消費者組是如何達成一致來分配訂閱 主題的所有分區的。假設某個組下有20個消費者實例,該組訂閱了一個有著100個分區的主題。正常情況下,Kafka會為每個消費者平均分配5個分區。這個分配過程就被稱為 Rebalance。
Rebalance 就是說如果消費組里的消費者數量有變化或消費的分區數有變化,kafka 會重新分配消費者消費分區的關系。
02. Kafka 消費者分區再均衡的觸發條件?
主題發生變化(比如管理員添加了新分區)會導致分區重分配。Kafka 消費者端的 Rebalance 操作會在以下情況下發生:
① 消費者組中新增或減少了消費者;
② 消費者所訂閱的主題的分區數量發生變化;
③ 消費者訂閱的主題個數發生變化;
后面兩個通常都是運維的主動操作,所以它們引發的 Rebalance 大都是不可避免的。實際上大部分情況下,導致分區再均衡的原因都是消費者組成員數量發生變化。
03. Kafka 消費者分區再均衡的過程?
Rebalance 是通過消費者群組中的稱為“群組首領”消費者客戶端進行的。
① 選擇群組首領:當一個消費者想要加入消費者群組時,它會向群組協調器發送 JoinGroup 請求。第一個加入群組的消費者將成為群組首領。
② 消費者通過向被指派為群組協調器(Coordinator)的 Broker 定期發送心跳來維持它們和群組的從屬關系以及它們對分區的所有權。
③ 群組首領從群組協調器獲取群組的成員列表(列表中包含了所有最近發送過心跳的消費者,它們被認為還“活著”),并負責為每一個消費者分配分區。它使用實現了PartitionAssignor接口的類來決定哪些分區應該被分配給哪個消費者。
④ 分區分配完畢之后,群組首領會把分區分配信息發送給群組協調器;
⑤ 群組協調器再把這些信息發送給所有的消費者。每個消費者只能看到自己的分配信息,只有群組首領會持有所有消費者及其分區所有權的信息。
04. Kafka 如何判定消費者已經死亡?
消費者會向被指定為群組協調器的broker(不同消費者群組的協調器可能不同)發送心跳,以此來保持群組成員關系和對分區的所有權關系。心跳是由消費者的一個后臺線程發送的,只要消費者能夠以正常的時間間隔發送心跳,它就會被認為還“活著”。
如果消費者在足夠長的一段時間內沒有發送心跳,那么它的會話就將超時,群組協調器會認為它已經“死亡”,進而觸發再均衡。如果一個消費者發生崩潰并停止讀取消息,那么群組協調器就會在幾秒內收不到心跳,它會認為消費者已經“死亡”,進而觸發再均衡。在這幾秒時間里,“死掉”的消費者不會讀取分區里的消息。在關閉消費者后,協調器會立即觸發一次再均衡,盡量降低處理延遲。
05. Kafka 如何避免消費者的分區再均衡?
真實應用場景中引發 rebalance 最常見的原因就是消費者組中新增或減少了消費者,特別是consumer崩潰的情況。這里的崩潰不一定就是指 consumer進程“掛掉”或consumer進程所在的機器宕機。以下兩種情況也被視為消亡,我們要做的就是如何避免這兩種不必要的 Rebalance 出現。
① 未及時發送心跳
由于消費者未能及時發送心跳,導致消費者被提出消費者組而導致的Rebalance,因此需要仔細地設置session.timeout.ms 和 heartbeat.interval.ms的值,這里給出一些推薦數值,可以“無腦”地應用在生產環境中。
(1) 設置 session.timeout.ms = 6s。
(2) 設置 heartbeat.interval.ms = 2s。
要保證消費者實例在被判定為死亡之前,能夠發送至少 3 輪的心跳請求,即 session.timeout.ms >= 3 * heartbeat.interval.ms。將 session.timeout.ms 設置成 6s 主要是為了讓 Coordinator 能夠更快地定位已經掛掉的 Consumer。畢竟,我們還是希望能盡快揪出那些“尸位素餐”的 Consumer,早日把它們踢出 Group。
② 消費者消費時間過長,無法在指定的時間內完成消息的處理
之前有一個客戶,在他們的場景中,消費者消費數據時需要將消息處理之后寫入到 MongoDB。顯然這是一個很重的消費邏輯。MongoDB 的一丁點不穩定都會導致消費者程序消費時長的增加。此時,max.poll.interval.ms 參數值的設置顯得尤為關鍵。如果要避免非預期的 Rebalance,你最好將該參數值設置得大一點,比你的下游最大處理時間稍長一點。就拿 MongoDB 這個例子來說,如果寫 MongoDB 的最長時間是 7 分鐘,那么你可以將該參數設置為 8 分鐘左右。
06. Kafka 消費者分區再均衡有什么影響?
① 影響消費者組的消費速度和吞吐量:消費者重新分配分區,可能會導致消費者停止消費一段時間,直到重新分配完成。
② 可能會產生消息重復消費:
因為Consumer消費分區消息的offset提交過程,不是實時的,由參數auto.commit.interval.ms控制提交的最小頻率,默認是5000,也就是最少每5s提交一次。我們試想以下場景:提交位移之后的 3 秒發生了 Rebalance ,在 Rebalance 之后,所有 Consumer 從上一次提交的位移處繼續消費,但該位移已經是 3 秒前的位移數據了,故在 Rebalance 發生前 3 秒消費的所有數據都要重新再消費一次。雖然可以通過減少 auto.commit.interval.ms 的值來提高提交頻率,但這么做只能縮小重復消費的時間窗口,不可能完全消除它。
遺憾的是,目前kafka社區對于Reblance帶來的影響,也沒有徹底的解決辦法。只能通過避免不必要的Rebalance減少影響。
07. Kafka 消費者分區再均衡的兩種機制?
根據消費者群組所使用的分區分配策略的不同,再均衡可以分為兩種類型。
① 主動再均衡 (range 、round-robin、sticky 分區分配策略)
在進行主動再均衡期間,所有消費者都放棄當前分配到的分區所有權,即停止讀取消息。消費者重新加入群組,獲得重新分配到的分區,并繼續讀取消息。這樣可以確保消費者群組中的每個消費者都獲得相同數量的分區,從而實現負載均衡。但這個過程會導致整個消費者群組在一個很短的時間窗口內不可用,這個時間窗口的長短取決于消費者群組的大小和幾個配置參數。
② 協作再均衡(cooperative sticky 分區分配策略)
Kafka協作再均衡(也稱為增量再均衡)用于在消費者組成員發生變化時重新分配分區。 協作再均衡機制只會重新分配發生變化的分區,而不是所有分區(比如一個消費者退出消費者組后,它所消費的分區會重新分區給其他消費者)。
協作再均衡通常是指將一個消費者的部分分區重新分配給另一個消費者,其他消費者則繼續讀取沒有被重新分配的分區。在協作再均衡中,消費者群組首領會通知所有消費者,它們將失去部分分區的所有權,然后消費者會停止讀取這些分區,并放棄對它們的所有權。接著,消費者群組首領會將這些沒有所有權的分區分配給其他消費者,從而實現分區的重新分配。雖然這種增量再均衡可能需要進行幾次迭代,直到達到穩定狀態,但它避免了主動再均衡中出現的“停止世界”停頓。這對大型消費者群組來說尤為重要,因為它們的再均衡可能需要很長時間。
08. kafka 消費者分區再均衡協議
rebalance 本質上是一組協議。group 與 coordinator 共同使用這組協議完成group的rebalance。最新版本Kafka中提供了下面5個協議來處理rebalance相關事宜。
① JoinGroup請求:consumer請求加入組。
② SyncGroup請求:group leader把分配方案同步更新到組內所有成員中。
③ Heartbeat請求:consumer定期向coordinator匯報心跳表明自己依然存活。
④ LeaveGroup請求:consumer主動通知coordinator該consumer即將離組。
⑤ DescribeGroup 請求:查看組的所有信息,包括成員信息、協議信息、分配方案以及訂閱信息等。該請求類型主要供管理員使用。coordinator不使用該請求執行rebalance。
在rebalance過程中,coordinator主要處理consumer發過來的JoinGroup和SyncGroup請求。當consumer主動離組時會發送LeaveGroup請求給coordinator。
在成功rebalance之后,組內所有consumer都需要定期地向coordinator發送Heartbeat請求。而每個 consumer也是根據 Heartbeat請求的響應中是否包含REBALANCE_IN_PROGRESS來判斷當前group是否開啟了新一輪rebalance。
09. kafka 消費者分區再均衡流程
目前 rebalance主要分為兩步:加入組和同步更新分配方案。
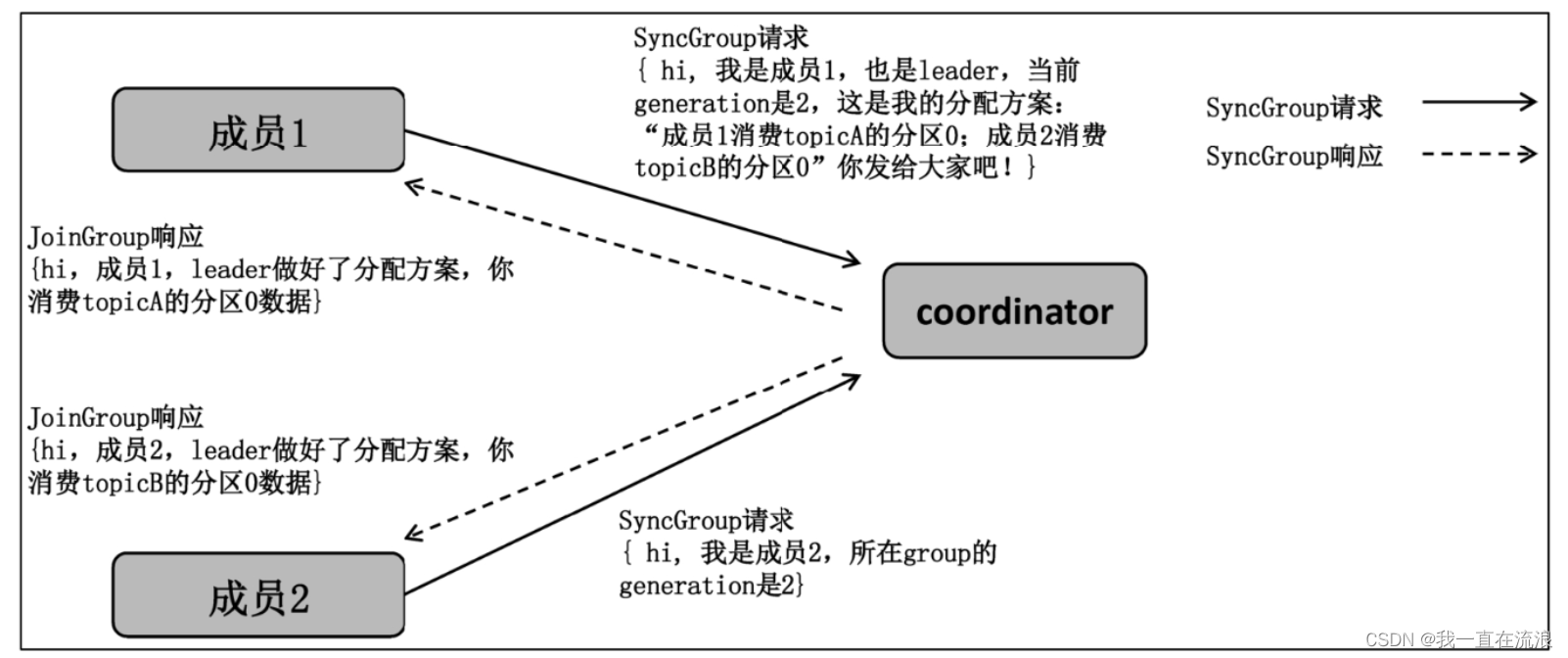
① 加入組:組內所有 consumer 向 coordinator 發送 JoinGroup請求。當收集全 JoinGroup請求后,coordinator從中選擇一個 consumer 擔任group的leader,并把所有成員信息以及它們的訂閱信息發送給leader。特別需要注意的是,group 的 leader 和coordinator 不是一個概念。leader 是某個consumer 實例,coordinator 通常是Kafka 集群中的一個 broker。另外 leader 而非coordinator負責為整個group的所有成員制定分配方案。

② 同步更新分配方案:group 的 leader 開始制定分配方案,即根據前面提到的分配策略決定每個consumer都負責哪些topic的哪些分區。一旦分配完成,leader會把這個分配方案封裝進 SyncGroup 請求并發送給 coordinator。比較有意思的是,組內所有成員都會發送 SyncGroup請求,不過只有 leader發送的 SyncGroup請求中包含了分配方案。coordinator 接收到分配方案后把屬于每個 consumer 的方案單獨抽取出來作為SyncGroup請求的response返還給各自的consumer。
10. Kafka 消費者組固定成員是什么?
在默認情況下,消費者的群組成員身份標識是臨時的。當一個消費者離開群組時,分配給它的分區所有權將被撤銷;當該消費者重新加入時,將通過再均衡協議為其分配一個新的成員ID和新分區。
可以給消費者分配一個唯一的group.instance.id,讓它成為群組的固定成員。通常,當消費者第一次以固定成員身份加入群組時,群組協調器會按照分區分配策略給它分配一部分分區。當這個消費者被關閉時,它不會自動離開群組——它仍然是群組的成員,直到會話超時。當這個消費者重新加入群組時,它會繼續持有之前的身份,并分配到之前所持有的分區。群組協調器緩存了每個成員的分區分配信息,只需要將緩存中的信息發送給重新加入的固定成員,不需要進行再均衡。
如果兩個消費者使用相同的group.instance.id加入同一個群組,則第二個消費者會收到錯誤,告訴它具有相同ID的消費者已存在。
如果應用程序需要維護與消費者分區所有權相關的本地狀態或緩存,那么群組固定成員關系就非常有用。如果重建本地緩存非常耗時,那么你肯定不希望在每次重啟消費者時都經歷這個過程。更重要的是,在消費者重啟時,消費者所擁有的分區不會被重新分配。在重啟過程中,消費者不會讀取這些分區,所以當消費者重啟完畢時,讀取進度會稍稍落后,但你要相信它們一定會趕上。
需要注意的是,群組的固定成員在關閉時不會主動離開群組,它們何時“真正消失”取決于session.timeout.ms參數。你可以將這個參數設置得足夠大,避免在進行簡單的應用程序重啟時觸發再均衡,但又要設置得足夠小,以便在出現嚴重停機時自動重新分配分區,避免這些分區的讀取進度出現較大的滯后。
11. Kafka 消費者分區再均衡的4種場景
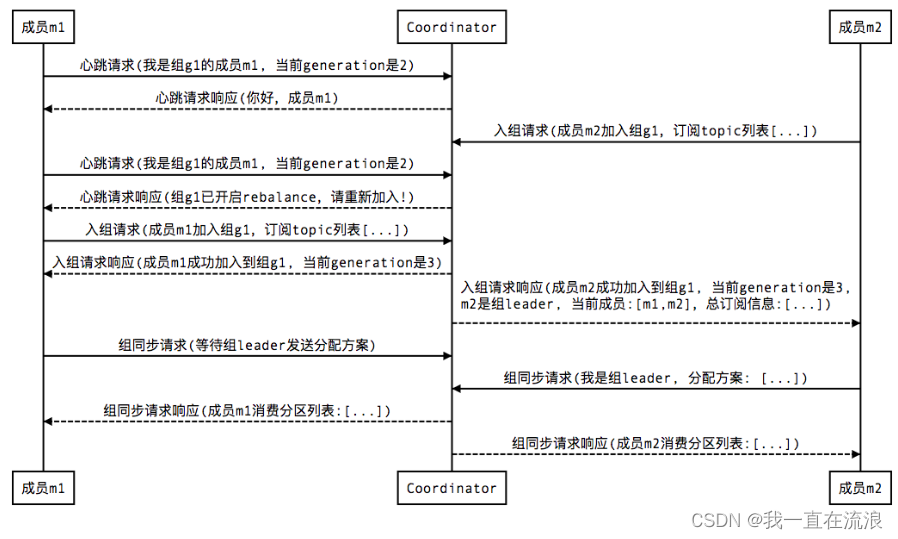
① 新成員加入組:
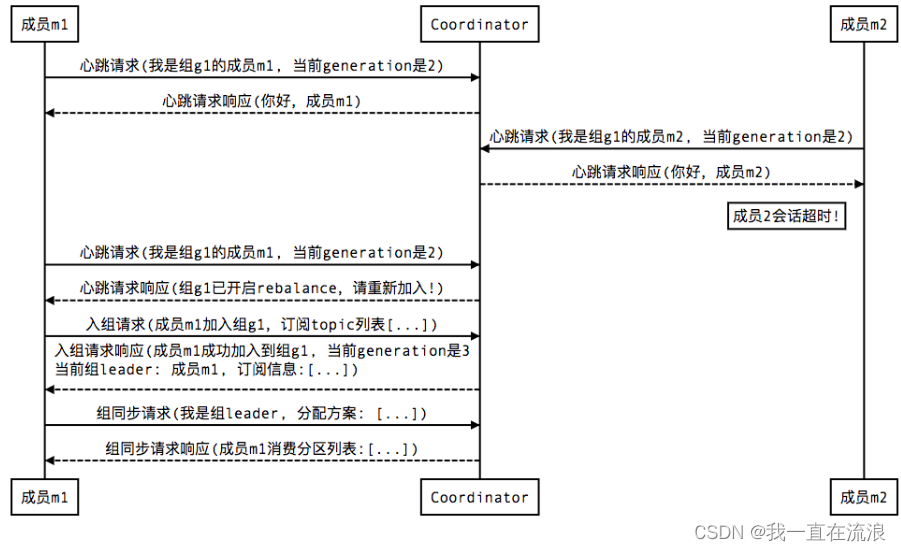
② 組成員崩潰:
組成員崩潰和組成員主動離開是兩個不同的場景。因為在崩潰時成員并不會主動地告知 coordinator 此事,coordinator 有可能需要一個完整的 session.timeout 周期才能檢測到這種崩潰,這必然會造成 consumer 的滯后。可以說離開組是主動地發起 rebalance;而崩潰則是被動地發起rebalance。
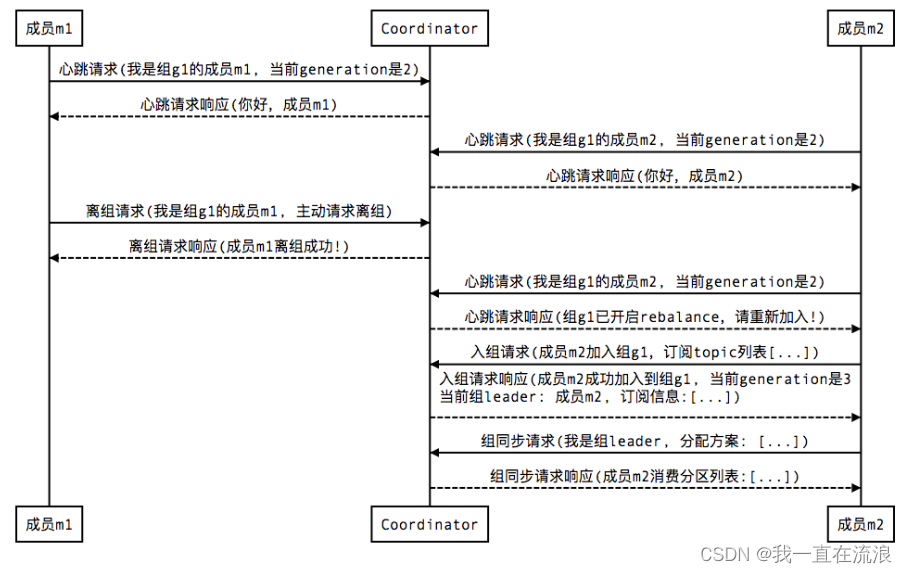
③ 組成員主動離開組:
④ 提交位移:










,Java)




題解)

的區別)


