1. C/S架構
Kubernetes 遵循非常傳統的客戶端服務端架構,客戶端通過 RESTful 接口或者直接使用 kubectl 與 Kubernetes 集群進行通信,這兩者在實際上并沒有太多的區別,后者也只是對 Kubernetes 提供的 RESTful API 進行封裝并提供出來。
左側是一個官方提供的名為 kubectl 的 CLI (Command Line Interface)工具,用于使用 K8S 開放的 API 來管理集群和操作對象等。
右側則是 K8S 集群的后端服務及開放出的 API 等。
2. 集群架構
每一個 Kubernetes 集群都由一組 Master 節點和一系列的 Worker 節點組成,其中 Master 節點主要負責存儲集群的狀態并為 Kubernetes 對象分配和調度資源。

2.1 Master
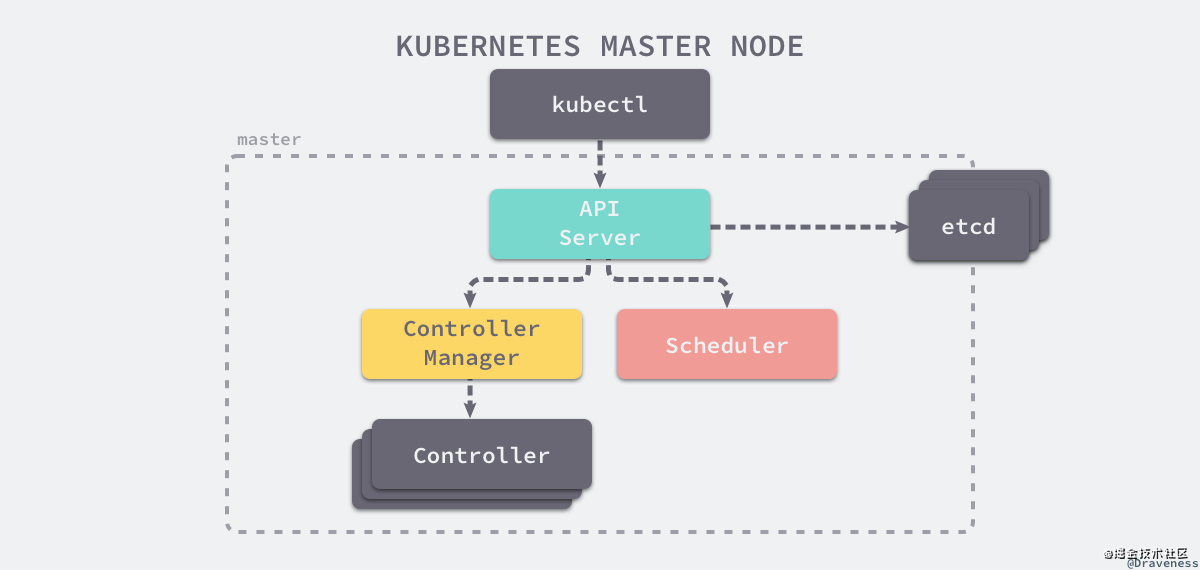
Master 是整個 K8S 集群的“大腦”,與大腦類似,它有幾個重要的功能:
- 接收:外部的請求和集群內部的通知反饋
- 發布:對集群整體的調度和管理
- 存儲:存儲
它主要包含以下幾個重要的組成部分。
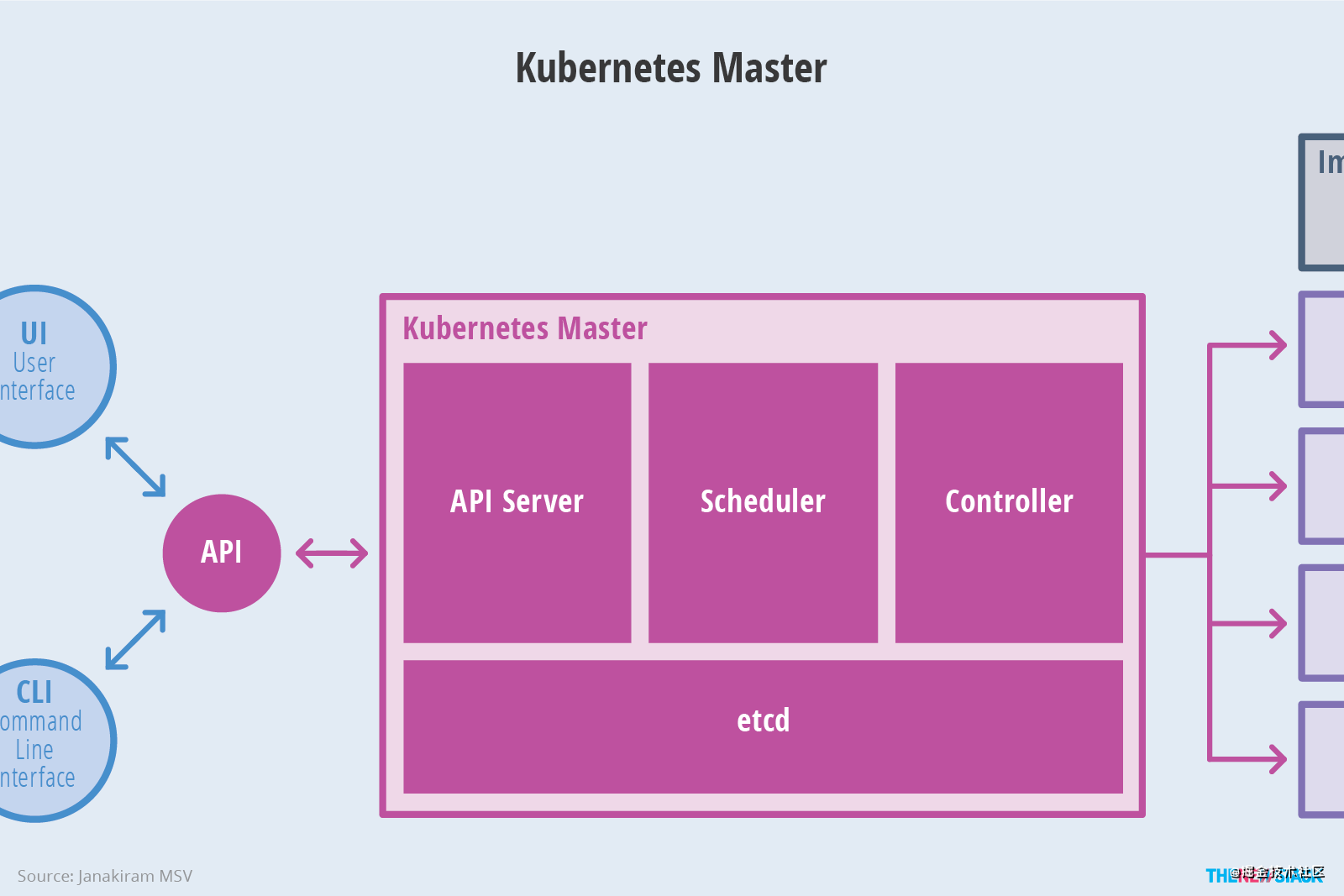
2.1.1 Cluster state store
存儲集群所有需持久化的狀態,并且提供 watch 的功能支持,可以快速的通知各組件的變更等操作。
因為目前 Kubernetes 的存儲層選擇是 etcd ,所以一般情況下,大家都直接以 etcd 來代表集群狀態存儲服務。即:將所有狀態存儲到 etcd 實例中。
2.1.2 API Server
其中 API Server 負責處理來自用戶的請求,其主要作用就是對外提供 RESTful 的接口,包括用于查看集群狀態的讀請求以及改變集群狀態的寫請求,也是唯一一個與 etcd 集群通信的組件。
2.1.3 Controller Manager
而 Controller 管理器運行了一系列的控制器進程,這些進程會按照用戶的期望狀態在后臺不斷地調節整個集群中的對象,當服務的狀態發生了改變,控制器就會發現這個改變并且開始向目標狀態遷移。
2.1.4 Scheduler
最后的 Scheduler 調度器其實為 Kubernetes 中運行的 Pod 選擇部署的 Worker 節點,它會根據用戶的需要選擇最能滿足請求的節點來運行 Pod,它會在每次需要調度 Pod 時執行。
2.2 Node
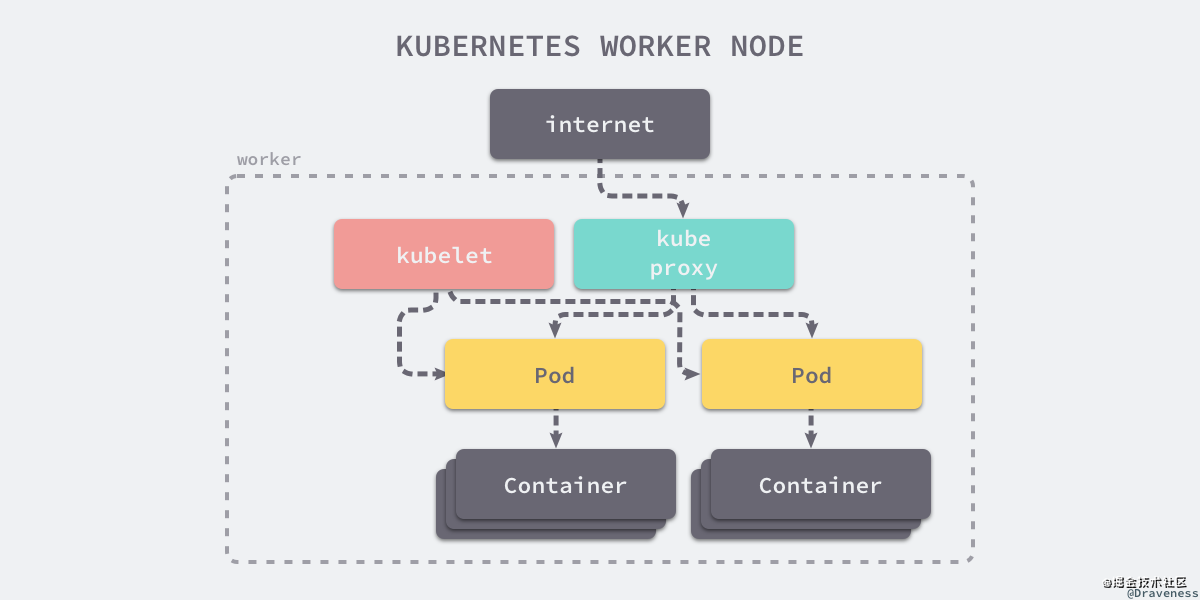
簡單來說就是加入集群中的機器。那 Node 是如何加入集群接受調度,并運行服務的呢?這都要歸功于運行在 Node 上的幾個核心組件。
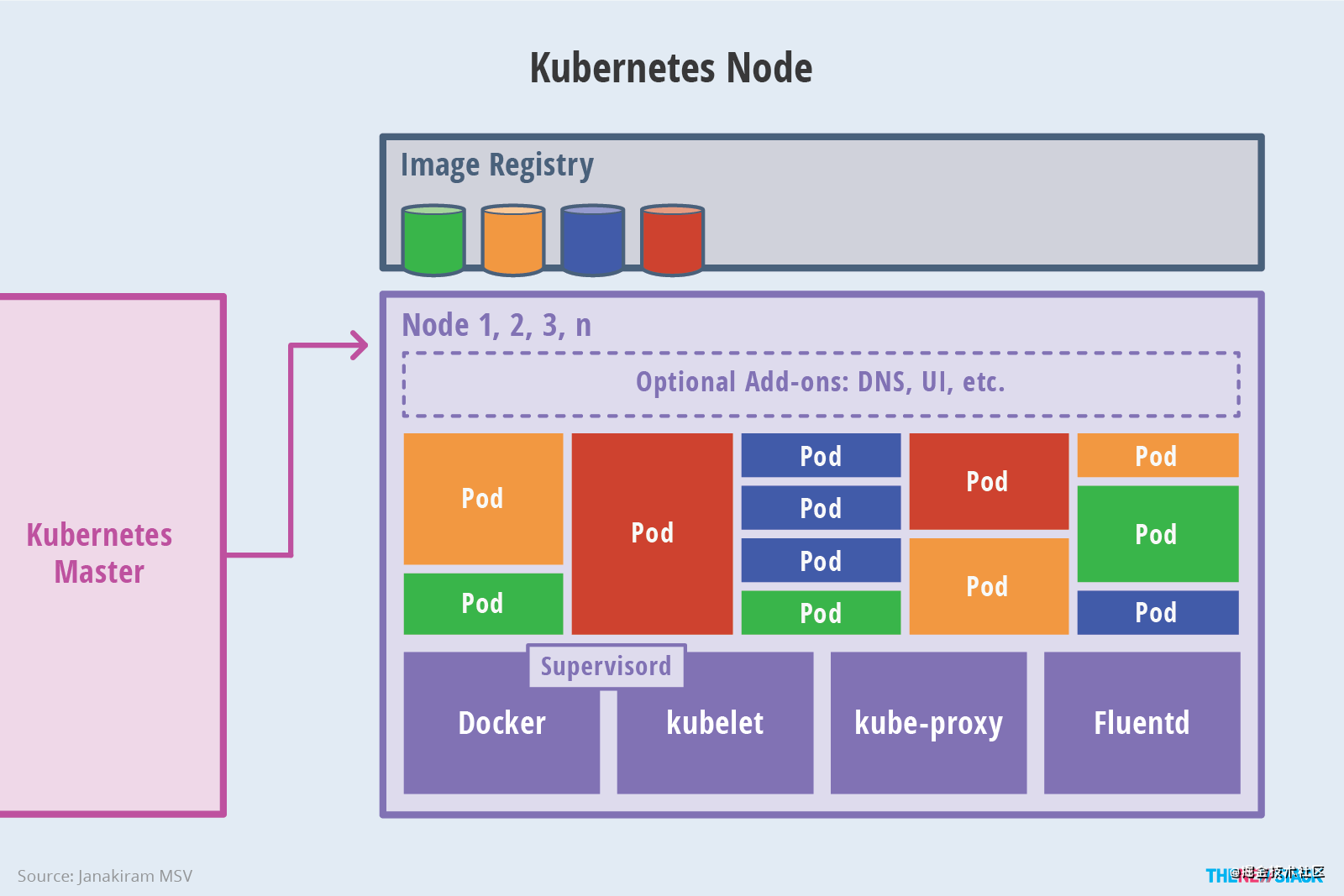
2.2.1 Kubelet
kubelet 是一個節點上的主要服務,它周期性地從 API Server 接受新的或者修改的 Pod 規范并且保證節點上的 Pod 和其中容器的正常運行,還會保證節點會向目標狀態遷移,該節點仍然會向 Master 節點發送宿主機的健康狀況。
2.2.2 Container runtime
容器運行時最主要的功能是下載鏡像和運行容器,我們最常見的實現可能是 Docker , 目前還有其他的一些實現,比如 rkt, cri-o。
K8S 提供了一套通用的容器運行時接口 CRI (Container Runtime Interface), 凡是符合這套標準的容器運行時實現,均可在 K8S 上使用。
2.2.3 Kube Proxy
另一個運行在各個節點上的代理服務 kube-proxy 負責宿主機的子網管理,同時也能將服務暴露給外部,其原理就是在多個隔離的網絡中把請求轉發給正確的 Pod 或者容器。
3. 重要概念
3.1 對象
Kubernetes 對象是系統中的持久實體,它使用這些對象來表示集群中的狀態,這些對象能夠描述:哪些應用應該運行在集群中,它們請求的資源下限和上限以及重啟、升級和容錯的策略。每一個創建的對象其實都是我們對集群狀態的改變,這些對象描述的其實就是集群的期望狀態,Kubernetes 會根據我們指定的期望狀態不斷檢查對當前的集群狀態進行遷移。
3.2 Pod
Pod 是 Kubernetes 中最基本的概念,它也是 Kubernetes 對象模型中我們可以創建或者部署的最小并且最簡單的單元。
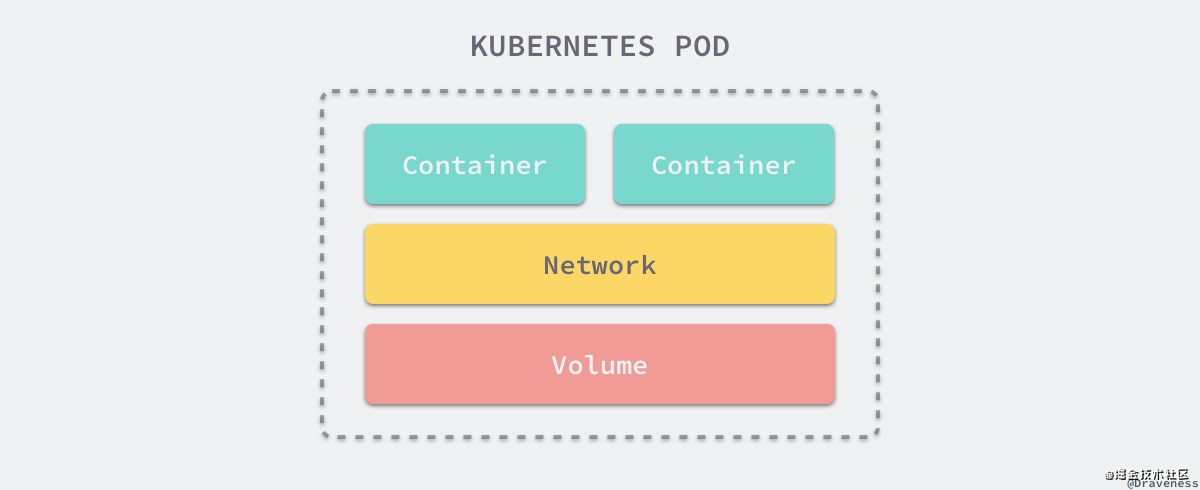
它將應用的容器、存儲資源以及獨立的網絡 IP 地址等資源打包到了一起,表示一個最小的部署單元,但是每一個 Pod 中的運行的容器可能不止一個,這是因為 Pod 最開始設計時就能夠在多個進程之間進行協調,構建一個高內聚的服務單元,這些容器能夠共享存儲和網絡,非常方便地進行通信。
3.3 控制器
最后要介紹的就是 Kubernetes 中的控制器,它們其實是用于創建和管理 Pod 的實例,能夠在集群的層級提供復制、發布以及健康檢查的功能,這些控制器其實都運行在 Kubernetes 集群的主節點上。
參考資料
《Kubernetes 從上手到實踐》
![caioj1522: [NOIP提高組2005]過河](http://pic.xiahunao.cn/caioj1522: [NOIP提高組2005]過河)




![[高精度乘法]BZOJ 1754 [Usaco2005 qua]Bull Math](http://pic.xiahunao.cn/[高精度乘法]BZOJ 1754 [Usaco2005 qua]Bull Math)

集群安裝)




集群配置)





)
