蝙蝠俠遙控器pcb
背景 (Background)
Wait! Isn’t the above equation different from what we found last time? Yup, very different but still looks exactly the same or maybe a bit better. Just in case you are wondering what I am talking about, please refer Part I of this series. Many ideas stated here are derived in that article and explained very clearly. The main ones being: why circles become like squares, how we can look at it as an intersection of trenches and how we can build our own graphs and equations by intersecting those trenches.
等待! 上面的方程式與我們上次發現的方程式有區別嗎? 是的,非常不同,但看起來還是一樣的,甚至可能更好。 萬一您想知道我在說什么,請參閱本系列的第一部分。 該文章中提到的許多想法都是從該文章中得出的,并且解釋得很清楚。 主要的是:為什么圓變得像正方形,我們如何將其視為溝槽的交點,以及如何通過將這些溝槽相交來構建自己的圖形和方程式。
挑戰 (The Challenge)
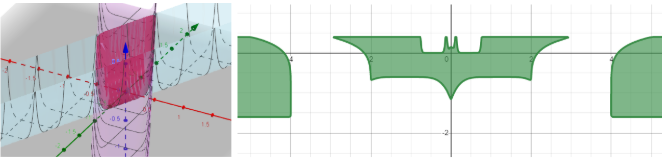
Working with trenches isn’t a very joyful experience, is it? Honestly? They have two walls and we generally use only one. The other one just lingers around and sometimes creates unwanted regions. Remember, we had to trim our Batman for the same reason. Next, we were able to perform only intersection and negation(flipping the sign of the power) of trenches but their union is still a bit challenging yet very useful. With great power comes the great computational difficulty. It is not common to raise our inputs to very high powers and is not very efficient computationally either. Thus, the scope of what we derived and obtained earlier was a bit limited by our designing skills.
使用戰es不是很快樂的經歷,不是嗎? 老實說 他們有兩堵墻,我們通常只使用一堵。 另一個只是徘徊,有時會創建不需要的區域。 記住,出于同樣的原因,我們不得不修剪蝙蝠俠。 接下來,我們只能執行溝槽的相交和求反(翻轉功率的符號),但是它們的結合仍然有些挑戰,但非常有用。 強大的功能帶來了巨大的計算難度。 將輸入提高到非常高的功率并不常見,而且計算效率也不高。 因此,我們早期獲得和獲得的內容的范圍受到我們設計技能的限制。
The universal set of mathematics is infinite and we would never be able to express it as the union of our finite ideas. So let’s start finding solutions to our challenges!
數學的通用集是無限的,我們永遠無法將其表達為有限思想的結合。 因此,讓我們開始尋找應對挑戰的解決方案!
從戰to到邊界 (From Trenches to Boundaries)
Remember, whenever the powers become too large to control, logarithms and exponents come to the rescue. The fundamental reason for having trenches was that when large even powers were used then two walls would form. One at y-f(x)=1(which we generally use) and the other at y-f(x)=-1(which we generally discard). Thus we have to make some changes to get only one wall per trench(that makes it just a wall). We can do this pretty easily. Just replace x^(2n) with e^(nx). The main reason why everything worked was that for absolute input values greater than 1 we would have function increasing above 1 very fast and for ones less than 1 we would have values near zero. In the case of e^(nx) for positive x, we have output values going above 1 very fast and for negative x, they are near zero. The first challenge is solved! Exponents are commonly used and have fast implementations. That’s a nice property to have, ain’t it?
請記住,每當冪數變得太大而無法控制時,對數和指數就可以解救。 具有溝槽的根本原因是,當使用大的偶數功率時,會形成兩堵墻。 一個在yf(x)= 1(我們通常使用),另一個在yf(x)=-1(我們通常丟棄)。 因此,我們必須進行一些更改,以使每個溝槽只有一堵墻(這使其成為一堵墻)。 我們可以很容易地做到這一點。 只需將x ^(2n)替換為e ^(nx)。 一切正常的主要原因是,對于大于1的絕對輸入值,我們將使函數快速增加到1以上;對于小于1的絕對輸入,我們將具有接近零的值。 對于正x的e ^(nx),我們的輸出值非常快地超過1,而對于負x,它們的輸出值接近零。 第一個挑戰已經解決! 指數是常用的并且具有快速實現。 那是一個不錯的財產,不是嗎?

A wall is always better than a trench, especially when no one has to pay for it (at least not computationally in our case).
墻總是比溝槽更好,尤其是在沒有人需要為此付費的情況下(至少在我們的案例中不是這樣)。
補語,交集和聯合 (Complement, Intersection and Union)
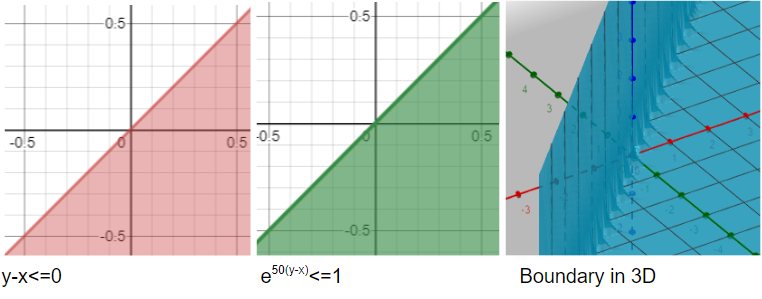
Once we have this right tool, we can understand what all great things we can do with it. The boundary we just defined has near-zero values for negative x and tends to infinity for positive x. Let’s understand what is a set then. A set here is essentially an inequality like y≤x or x2+y2-1≤0. The boundary of these sets is what we want to represent. Thus we can multiply with large n and exponentiate both sides to get our boundaries. Thus y-x≤0 will look like e^(50(y-x))≤1, which is akin to (y-x)??≤1 (one of our previous trench boundaries). The same logic we saw earlier applies to both cases.
一旦有了這個正確的工具,我們就可以了解使用它可以做的所有偉大的事情。 我們剛剛定義的邊界對于負x具有接近零的值,對于正x趨于無窮大。 讓我們了解什么是集合。 這里的集合本質上是一個不等式,例如y≤x或x2+y2-1≤0。 這些集合的邊界就是我們想要表示的。 因此,我們可以乘以大的n并對兩側求冪以得出邊界。 因此yx≤0看起來像e ^(50(yx))≤1,類似于(yx)??≤1(我們先前的溝槽邊界之一)。 我們在前面看到的相同邏輯適用于兩種情況。
Let’s look at the complement of our sets which we can obtain by simply changing the sign of the power as we did last time.
讓我們看一下我們的集合的補充,通過像上次那樣簡單地改變冪的符號就可以獲得。

Next, let’s look at our favourite intersection. It’s the same as what we derived earlier as there is nothing different in the logic of the sum of small numbers being less than 1. This can be seen as follows:
接下來,讓我們看看我們最喜歡的路口。 它與我們先前導出的結果相同,因為小數之和小于1的邏輯沒有什么不同。這可以看到如下:
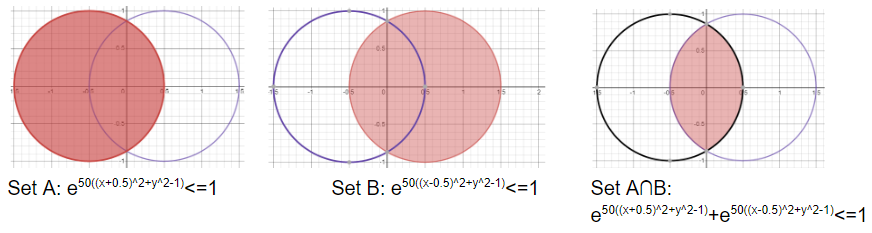
And finally our newcomer, union. Let’s derive it. By De-Morgan’s law, we know that AUB = (A’∩B’)’. Thus that means the inverse of the sum of the inverse of the sets. Ahhh! It’s just like how you evaluate the resistance of parallel resistors (1/Rt=1/R1+1/R2). Or, for those who are familiar, it is the Harmonic Mean instead of the sum. Let’s see:
最后是我們的新來者,工會。 讓我們得出它。 根據德摩根定律,我們知道AUB =(A'∩B')'。 因此,這意味著集合的逆的總和的逆。 啊! 就像評估并聯電阻(1 / Rt = 1 / R1 + 1 / R2)的電阻一樣。 或者,對于那些熟悉的人,它是諧波均值而不是總和。 讓我們來看看:
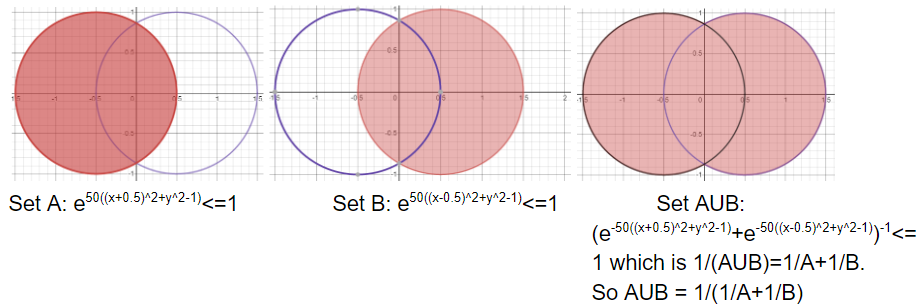
There is also a very important observation. The property of value tending to zero for points inside the set and to infinite for points outside the set is also applicable to the results of the above set operations. Thus these set operations are also repeatable without doing exponentiation again. This means we can compute more complex operations like AU(B∩(CUD)) by applying the above set operations one by one.
還有一個非常重要的發現。 對于集合內的點趨于零而對于集合外的點趨于無窮的值的屬性也適用于上述集合操作的結果。 因此,這些設置操作也是可重復的,而無需再次進行求冪。 這意味著我們可以通過逐個應用上述設置操作來計算更復雜的操作,如AU(B∩(CUD))。
The union of a variety of ideas in algebra and set theory has guided us through the narrow intersection of mathematics and creative art. Summing up all our high powered ideas, I can say that the difference from our goal will soon tend to zero. With one final activity, which I would like to exponentiate on, we would be all set to fit the application in Machine Learning.
代數理論和集合論中各種思想的結合,引導我們度過了數學與創意藝術的狹窄交集。 總結我們所有有力的想法,我可以說與目標的差距很快就會趨于零。 在最后的一項活動(我想對之進行總結)中,我們將全部適應于機器學習中的應用程序。
讓我們做點什么! (Let’s Make Something!)
Let’s make the following puzzle piece:
讓我們制作以下拼圖:
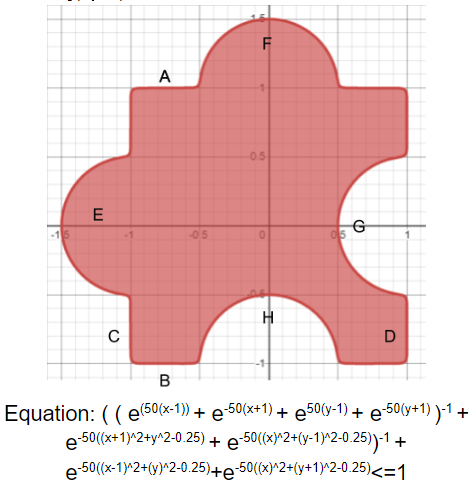
The above equation can be obtained by first creating a square, then taking union with 2 circles (the ones protruding) followed by the intersection with the complement of other 2 circles (the ones removed). Let the 4 edges of the square be represented as A, B, C and D. Each edge is a single line. The circles undergoing union be represented as E and F. And circles being removed be represented as G and H. Thus the above figure is: ((A ∩ B ∩ C ∩ D) U E U F) ∩ G’ ∩ H’.
可以通過首先創建一個正方形,然后與2個圓(突出的圓)進行并集,然后與其他2個圓的補碼的相交(去除的圓)獲得上式。 假設正方形的4條邊分別表示為A,B,C和D。每條邊都是一條直線。 經過合并的圓用E和F表示,被除去的圓用G和H表示。因此,上圖是:((A∩B∩C∩D)UEUF)∩G'∩H'。
Let’s represent the sets:
讓我們代表集合:
- A: e^(50(x-1)) 答:e ^(50(x-1))
- B: e^(-50(x+1)) minus sign to change the direction of the set (to make it face inside the figure) B:e ^(-50(x + 1))減號可更改集合的方向(使其面向圖形內部)
- C: e^(50(y-1)) C:e ^(50(y-1))
- D: e^(-50(y+1)) minus sign to change the direction of the set D:e ^(-50(y + 1))減號以更改集合的方向
- E: e^(50((x+1)2+y2-0.25)) E:e ^(50((x + 1)2+y2-0.25))
- F: e^(50((x)2+(y-1)2-0.25)) F:e ^(50((x)2+(y-1)2-0.25))
- G: e^(50((x-1)2+(y)2-0.25)) G:e ^(50((x-1)2+(y)2-0.25))
- H: e^(50((x)2+(y+1)2-0.25)) 高:e ^(50((x)2+(y + 1)2-0.25))
Performing (A ∩ B ∩ C ∩ D) gives: (e^(50(x-1))+e^(-50(x+1))+e^(50(y-1))+e^(-50(y+1)))
執行(A∩B∩C∩D)得到:(e ^(50(x-1))+ e ^(-50(x + 1))+ e ^(50(y-1))+ e ^( -50(y + 1)))
This is followed by taking union with the circles thus giving:
接下來是與圈子合而為一:
((e^(50(x-1))+e^(-50(x+1))+e^(50(y-1))+e^(-50(y+1)))^-1+e^(-50((x+1)2+y2-0.25))+e^(-50((x)2+(y-1)2-0.25)))^-1
(((e ^(50(x-1))+ e ^(-50(x + 1))+ e ^(50(y-1))+ e ^(-50(y + 1)))^- 1 + e ^(-50((x + 1)2+y2-0.25))+ e ^(-50((x + 1)2+(y-1)2-0.25)))^-1
Finally performing intersection with the complement of other 2 circles gives the desired equation shown in the figure above.
最終與其他2個圓的補碼執行相交,得出所需的方程式如上圖所示。
All the above operations are also compatible with what we had learnt previously thus the square can take back its true form: x??+y??=1. Giving an alternate equation for the same figure as shown below. Note the first term.
上述所有操作也與我們先前學到的兼容,因此平方可以取回其真實形式:x??+y??= 1。 如下圖所示,為該圖給出一個替代方程。 注意第一項。
((x??+y??)^-1+e^(-50((x+1)2+y2-0.25))+e^(-50((x)2+(y-1)2-0.25)))^-1+e^(-50((x-1)2+(y)2-0.25))+e^(-50((x)2+(y+1)2-0.25))≤1
(((x??+y??)^-1 + e ^(-50((x + 1)2+y2-0.25))+ e ^(-50((x)2+(y-1)2-0.25))) )^-1 + e ^(-50((x-1)2+(y)2-0.25))+ e ^(-50((x)2+(y + 1)2-0.25))≤1
實際應用 (Real Applications)
Remember, if we can create good looking graphs and their equations then we can also create some pretty interesting functions commonly used in various fields or even make some for ourselves. My background is in Machine Learning therefore I am acquainted with some of these functions used in my field.
請記住,如果我們可以創建漂亮的圖形及其方程式,那么我們還可以創建一些非常有趣的函數,這些函數通常用于各個領域,甚至為自己創建一些函數。 我的背景是機器學習,因此我熟悉本領域中使用的一些功能。
派生Log-sum-exp和Softmax (Deriving Log-sum-exp and Softmax)
We all have learnt so much about the max function which takes in multiple numbers and spits out the largest one. In many applications in machine learning, we want the max operation to not only be as close as possible to the actual largest number but to also have some relation with the numbers which are not the largest. The closer these numbers are to the largest, the more they should contribute to the result. This is important because it allows gradients to propagate through non-maximum terms as well during backpropagation or other training algorithms. Not going deep into ML, we can say we need an approximation of the max operation which accounts for all the terms. Such approximation of fixed(hard) decision functions like max, if-else, sorting etc. is called softening.
我們都學到了很多關于max函數的知識,max函數接受多個數字并吐出最大的一個。 在機器學習的許多應用中,我們希望max運算不僅要盡可能接近實際最大數,還要與不是最大數的數具有某種關系。 這些數字離最大值越近,它們對結果的貢獻就越大。 這很重要,因為它允許梯度在反向傳播或其他訓練算法期間通過非最大項傳播。 不深入學習ML,可以說我們需要近似max運算,該運算要考慮所有項。 固定(硬)決策函數(例如max,if-else,sort等)的這種近似稱為softening 。
What is max essentially? It is the union of the individual functions and the largest one is represented at the output. Note that the largest function in the union operation automatically has smaller ones under it. For 1 dimensional example, max(y=1,y=2,y=3) is y=3. We can also write this as the boundary of Union(y≤1,y≤2,y≤3). The union is y≤3 so the boundary is y=3. Let’s visualize this for some more realistic functions:
本質上是什么? 它是各個功能的并集,最大的代表在輸出中。 請注意,并集操作中的最大功能會自動在其下方顯示較小的功能。 對于一維示例,max(y = 1,y = 2,y = 3)是y = 3。 我們也可以將其寫為Union(y≤1,y≤2,y≤3)的邊界。 聯合為y≤3,因此邊界為y = 3。 讓我們將其可視化為一些更實際的功能:
Let the input functions be f(x), g(x) and h(x). We can represent them as y-f(x)≤0, y-g(x)≤0 and y-h(x)≤0. Lets perform the union of these borders to generate our approximation for max function:
令輸入函數為f(x),g(x)和h(x)。 我們可以將它們表示為yf(x)≤0,yg(x)≤0和yh(x)≤0。 讓我們執行這些邊界的并集以生成max函數的近似值:
(e^(-n(y-f(x))+e^(-n(y-g(x))+e^(-n(y-h(x)))^-1≤1
(e ^(-n(yf(x))+ e ^(-n(yg(x))+ e ^(-n(yh(x)))^-1≤1
Taking the points on the border, we get: (e^(-n(y-f(x))+e^(-n(y-g(x))+e^(-n(y-h(x)))^-1=1
取邊界上的點,我們得到:(e ^(-n(yf(x))+ e ^(-n(yg(x))+ e ^(-n(yh(x)))^-1 = 1
Rearranging the result to make it a function of x gives:
重新排列結果使其成為x的函數將給出:
y = ln(e^(nf(x))+e^(ng(x))+e^(nh(x)))/n
y = ln(e ^(nf(x))+ e ^(ng(x))+ e ^(nh(x)))/ n
This is essentially the log-sum-exp form. 1/n is generally referred to as the temperature and is denoted as T and is generally taken to be 1. For multiple terms we get: y=ln(sum(e^x?, for all i)). Thus deriving its name log-sum-exp (LSE).
這本質上是log-sum-exp形式。 1 / n通常稱為溫度,并表示為T,通常取為1。對于多個項,我們得到:y = ln(sum(e ^x?,對于所有i))。 因此派生其名稱log-sum-exp(LSE)。
What about all that softening and ML stuff said earlier? Note that the log-sum-exp is always greater than the actual max. This difference accounts for the terms which are second largest, third-largest, and so on …. The output is a mixture of all terms as seen in the above equation but larger terms contribute much more than the smaller ones as we have approximated the max operation. Remember!! larger was the value of n, closer was the circle to a square. Similarly, larger n means bigger terms contribute exponentially more than smaller ones thus making the approximation more accurate. Notice the curved differentiable corners as well, this is another benefit of our approximation very helpful in ML. By the way, what’s the derivative of log-sum-exp? It’s our common friend Softmax(Yes, the classification layer one). I hope now you see how this famous function also derived its name. And yes, I know this is not a Wikipedia article, so I will move on.
前面說過的所有軟化和ML東西怎么辦? 請注意,log-sum-exp始終大于實際最大值。 這種差異說明了第二大,第三大等等的術語。 如上式所示,輸出是所有項的混合,但是較大的項比較小的項貢獻更大,因為我們已經近似了最大運算。 記得!! n的值越大,則圓與正方形的距離越近。 同樣,較大的n表示較大的項比較小的項在指數上的貢獻更大,從而使近似值更精確。 還要注意彎曲的可微角,這是我們在ML中非常有用的近似值的另一個好處。 順便說一句,log-sum-exp的派生是什么? 這是我們的共同朋友Softmax (是的,分類第一層)。 我希望您現在看到這個著名的函數也是如何派生其名稱的。 是的,我知道這不是維基百科的文章,所以我繼續。
There is no dearth of applications of the log-sum-exp equation. Many of its properties are discussed on its Wikipedia page. There are also papers using it as an architecture directly like ones using it as universal convex approximator and as universal function approximator. There are many many more applications of this function, hence it has inbuilt efficient implementations in nearly all ML libraries from Numpy to Pytorch and Tensorflow. The upcoming applications are like special cases of this one.
log-sum-exp方程沒有任何應用。 它的許多屬性在其Wikipedia頁面上進行了討論。 也有論文將其作為體系結構直接用作將其用作通用凸逼近器和通用函數逼近器的論文 。 此功能還有很多應用程序,因此它在從Numpy到Pytorch和Tensorflow的幾乎所有ML庫中都內置了高效的實現。 即將到來的應用程序就像本例的特殊情況。
導出Soft-Plus激活功能 (Deriving Soft-Plus Activation function)
The soft-plus activation is a type of non-linearity used in neural networks. One common non-linearity is ReLU which takes the form max(0,x) and is very commonly used. Under many conditions as described in this paper, we need to approximate the ReLU function. Not diving deep into activation function and ML details, we can handle this challenge by approximating the ReLU function with the methods we just learnt.
軟加激活是神經網絡中使用的一種非線性類型。 一種常見的非線性是ReLU,其形式為max(0,x),并且非常常用。 在本文所述的許多條件下,我們需要近似ReLU函數。 我們不會深入研究激活功能和ML細節,而是可以通過使用我們剛剛學習的方法近似ReLU函數來應對這一挑戰。
Thus we have to approximate max(0,x). Why not just refer our derivation in log-sum-exp. The two needed components are y≤0 and y-x≤0. This will thus give the union as (e^(-ny)+e^(-n(y-x)))^-1≤1. This will thus give us the equation: y = ln(1+e^(nx))/n. When n is 1, this is referred to as the softplus activation function. Beyond its original paper, this function is also used in other activation functions like swish, mish and soft++.
因此,我們必須近似max(0,x)。 為什么不只在log-sum-exp中引用我們的推導。 所需的兩個分量是y≤0和yx≤0。 因此,這將使并集為(e ^(-ny)+ e ^(-n(yx)))^-1≤1。 因此,這將給我們方程:y = ln(1 + e ^(nx))/ n。 當n為1時,這稱為softplus激活函數。 除了原始論文外,此功能還用于其他激活功能,例如swish , mish和soft ++ 。
We can even go beyond and create our own variant of softplus and call it leaky-softplus. Essentially an approximation of leaky-ReLU ( max(0.05x, x) ) with the same procedure. The function takes the following form: y = ln(e^(0.05nx)+e^(nx))/n. And according to the common ritual, we make n=1. The result is shown below. Testing and experimentation are left to the reader. ;-)
我們甚至可以超越并創建我們自己的softplus變體,并將其稱為leaky-softplus。 用相同的方法本質上是泄漏ReLU(max(0.05x,x))的近似值。 該函數采用以下形式:y = ln(e ^(0.05nx)+ e ^(nx))/ n。 并根據共同的儀式,使n = 1。 結果如下所示。 測試和實驗留給讀者。 ;-)
推導對數共損失 (Deriving log-cosh loss)
In many regression tasks, a loss function called absolute loss which is essentially the average absolute value of the errors is used. This loss is non-differentiable at zero and also doesn’t have a second derivative for training algorithms using higher-order derivatives. Log-cosh handles these problems very well by approximating it thus looking like mean squared error near zero and like absolute loss away from it. More can be learnt in this article. Thus, we have to approximate |x| which is essentially max(x,-x). We can use the same old trick and get: y=ln(e^nx+e^-nx)/n. We haven’t reached our goal yet. We can now add and subtract ln(2)/n giving us: ln((e^nx+e^-nx)/2)/n+ln(2)/n. The next step is to make n=1 and ignore the constant as it doesn’t affect the training procedure. This gives us: ln((e^x+e^-x)/2) which is ln(cosh(x)). This is our log-cosh loss function.
在許多回歸任務中,使用稱為絕對損失的損失函數,該函數實質上是誤差的平均絕對值。 該損失為零時不可微,對于使用高階導數的訓練算法也沒有二階導數。 Log-cosh通過近似地很好地解決了這些問題,因此看起來像均方誤差接近零,并且像絕對誤差一樣遠離它。 更可以在了解到這個文章。 因此,我們必須近似| x |。 本質上是max(x,-x)。 我們可以使用相同的舊技巧來獲取:y = ln(e ^ nx + e ^ -nx)/ n。 我們尚未達到目標。 現在我們可以對ln(2)/ n進行加減法運算,從而得出:ln((e ^ nx + e ^ -nx)/ 2)/ n + ln(2)/ n。 下一步是使n = 1并忽略該常數,因為它不會影響訓練過程。 這樣得出:ln((e ^ x + e ^ -x)/ 2)是ln(cosh(x))。 這是我們的log-cosh損失函數。
結論 (Conclusion)
Simple ideas coming out of sheer curiosity can have a very wide range of applications. There are no ceilings for curiosity and what it can give us. Hope these articles have provided you with new tools and perspectives which you can apply in fields as diverse as science, engineering and art. For curious minds, I would like to leave a good resource to improve your understanding of this idea: Differentiable Set Operations for Algebraic Expressions.
出于好奇而產生的簡單想法可能具有廣泛的應用范圍。 好奇心沒有上限,它可以給我們帶來什么。 希望這些文章為您提供新的工具和觀點,您可以將其應用于科學,工程和藝術等各個領域。 對于好奇的人,我想留下一個很好的資源來增進您對這個想法的理解: 代數表達式的可微集運算 。
挑戰 (Challenge)
Make this figure with a single inequation:
用一個不等式使這個數字:

Make this figure with a single inequation without using modulus function:
在不使用模函數的情況下,使該圖具有單個不等式:
翻譯自: https://towardsdatascience.com/from-circle-to-ml-via-batman-part-ii-699aa5de4a66
蝙蝠俠遙控器pcb
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/391119.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/391119.shtml 英文地址,請注明出處:http://en.pswp.cn/news/391119.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
)
camera驅動框架分析(上)

工程項目管理需要注意哪些問題
)
leetcode 872. 葉子相似的樹(dfs)

探索感染了COVID-19的動物的數據

Facebook哭暈在廁所,調查顯示用VR體驗社交的用戶僅為19%


解決Javascript疲勞的方法-以及其他所有疲勞

Java 8 的List<V> 轉成 Map<K, V>

已知兩點坐標拾取怎么操作_已知的操作員學習-第4部分

北京供銷大數據集團發布SinoBBD Cloud 一體化推動產業云發展

windows下有趣的小玩意

rxjs angular_Angular RxJS深度

HashMap, LinkedHashMap 和 TreeMap的區別

“陪護機器人”研報:距離真正“陪護”還差那么一點

neo-6m uno_Uno-統治所有人的平臺

【轉】消息隊列應用場景

JDK和JRE區別是什么


lime 模型_使用LIME的糖尿病預測模型解釋— OneZeroBlog
