python機器學習預測
Note from Towards Data Science’s editors: While we allow independent authors to publish articles in accordance with our rules and guidelines, we do not endorse each author’s contribution. You should not rely on an author’s works without seeking professional advice. See our Reader Terms for details.
Towards Data Science編輯的注意事項: 盡管我們允許獨立作者按照我們的 規則和指南 發表文章 ,但我們不認可每位作者的貢獻。 您不應在未征求專業意見的情況下依賴作者的作品。 有關 詳細信息, 請參見我們的 閱讀器條款 。
With the recent volatility of the stock market due to the COVID-19 pandemic, I thought it was a good idea to try and utilize machine learning to predict the near-future trends of the stock market. I’m fairly new to machine learning, and this is my first Medium article so I thought this would be a good project to start off with and showcase.
鑒于最近由于COVID-19大流行而導致的股市波動,我認為嘗試利用機器學習來預測股市的近期趨勢是一個好主意。 我是機器學習的新手,這是我的第一篇中型文章,所以我認為這是一個很好的項目,首先要進行展示。
This article tackles different topics concerning data science, namely; data collection and cleaning, feature engineering, as well as the creation of machine learning models to make predictions.
本文討論了與數據科學有關的不同主題,即: 數據收集和清理,功能工程以及創建機器學習模型以進行預測。
Author’s disclaimer: This project is not financial or investment advice. It is not a guarantee that it will provide the correct results most of the time. Therefore you should be very careful and not use this as a primary source of trading insight.
作者免責聲明:該項目不是財務或投資建議。 不能保證大部分時間都會提供正確的結果。 因此,您應該非常小心,不要將其用作交易洞察力的主要來源。
You can find all the code on a jupyter notebook on my github:
您可以在我的github上的jupyter筆記本上找到所有代碼:
1.進口和數據收集 (1. Imports and Data Collection)
To begin, we include all of the libraries used for this project. I used the yfinance API to gather all of the historical stock market data. It’s taken directly from the yahoo finance website, so it’s very reliable data.
首先,我們包括用于該項目的所有庫。 我使用yfinance API收集了所有歷史股票市場數據。 它直接來自雅虎財經網站,因此它是非常可靠的數據。
import yfinance as yf
import datetime
import pandas as pd
import numpy as np
from finta import TA
import matplotlib.pyplot as pltfrom sklearn import svm
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import confusion_matrix, classification_report
from sklearn import metricsWe then define some constants that used in data retrieval and data processing. The list with the indicator symbols is useful to help use produce more features for our model.
然后,我們定義一些用于數據檢索和數據處理的常量。 帶有指示器符號的列表對于幫助使用為我們的模型產生更多功能很有用。
"""
Defining some constants for data mining
"""NUM_DAYS = 10000 # The number of days of historical data to retrieve
INTERVAL = '1d' # Sample rate of historical data
symbol = 'SPY' # Symbol of the desired stock# List of symbols for technical indicators
INDICATORS = ['RSI', 'MACD', 'STOCH','ADL', 'ATR', 'MOM', 'MFI', 'ROC', 'OBV', 'CCI', 'EMV', 'VORTEX']Here’s a link where you can find the actual names of some of these features.
在此鏈接中,您可以找到其中某些功能的實際名稱。
Now we pull our historical data from yfinance. We don’t have many features to work with — not particularly useful unless we find a way to normalize them at least or derive more features from them.
現在,我們從yfinance中提取歷史數據。 我們沒有很多功能可以使用-除非我們找到一種方法至少可以將它們標準化或從中獲得更多功能,否則它就沒有什么用處。
"""
Next we pull the historical data using yfinance
Rename the column names because finta uses the lowercase names
"""start = (datetime.date.today() - datetime.timedelta( NUM_DAYS ) )
end = datetime.datetime.today()data = yf.download(symbol, start=start, end=end, interval=INTERVAL)
data.rename(columns={"Close": 'close', "High": 'high', "Low": 'low', 'Volume': 'volume', 'Open': 'open'}, inplace=True)
print(data.head())tmp = data.iloc[-60:]
tmp['close'].plot()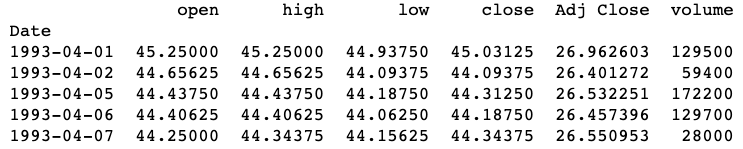
2.數據處理與特征工程 (2. Data Processing & Feature Engineering)
We see that our data above is rough and contains lots of spikes for a time series. It isn’t very smooth and can be difficult for the model to extract trends from. To reduce the appearance of this we want to exponentially smooth our data before we compute the technical indicators.
我們看到上面的數據是粗糙的,并且包含一個時間序列的許多峰值。 它不是很平滑,模型很難從中提取趨勢。 為了減少這種情況的出現,我們希望在計算技術指標之前以指數方式平滑數據。
"""
Next we clean our data and perform feature engineering to create new technical indicator features that our
model can learn from
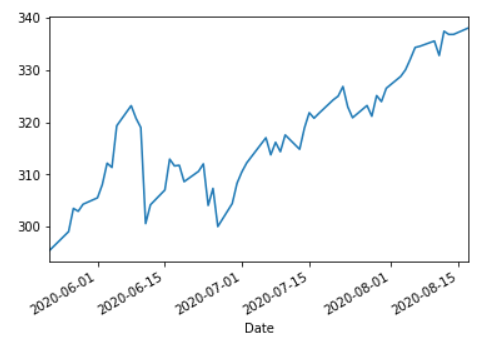
"""def _exponential_smooth(data, alpha):"""Function that exponentially smooths dataset so values are less 'rigid':param alpha: weight factor to weight recent values more"""return data.ewm(alpha=alpha).mean()data = _exponential_smooth(data, 0.65)tmp1 = data.iloc[-60:]
tmp1['close'].plot()
We can see that the data is much more smoothed. Having many peaks and troughs can make it hard to approximate, or be difficult to extract tends when computing the technical indicators. It can throw the model off.
我們可以看到數據更加平滑。 在計算技術指標時,具有許多波峰和波谷會使其難以估計或難以提取趨勢。 它可能會使模型失效。
Now it’s time to compute our technical indicators. As stated above, I use the finta library in combination with python’s built in eval function to quickly compute all the indicators in the INDICATORS list. I also compute some ema’s at different average lengths in addition to a normalized volume value.
現在該計算我們的技術指標了。 如上所述,我結合使用finta庫和python的內置eval函數來快速計算INDICATORS列表中的所有指標。 除了歸一化的體積值,我還計算了不同平均長度下的一些ema。
I remove the columns like ‘Open’, ‘High’, ‘Low’, and ‘Adj Close’ because we can get a good enough approximation with our ema’s in addition to the indicators. Volume has been proven to have a correlation with price fluctuations, which is why I normalized it.
我刪除了諸如“打開”,“高”,“低”和“調整關閉”之類的列,因為除指標外,我們還可以獲得與ema足夠好的近似值。 交易量已被證明與價格波動有關,這就是為什么我將其標準化。
def _get_indicator_data(data):"""Function that uses the finta API to calculate technical indicators used as the features:return:"""for indicator in INDICATORS:ind_data = eval('TA.' + indicator + '(data)')if not isinstance(ind_data, pd.DataFrame):ind_data = ind_data.to_frame()data = data.merge(ind_data, left_index=True, right_index=True)data.rename(columns={"14 period EMV.": '14 period EMV'}, inplace=True)# Also calculate moving averages for featuresdata['ema50'] = data['close'] / data['close'].ewm(50).mean()data['ema21'] = data['close'] / data['close'].ewm(21).mean()data['ema15'] = data['close'] / data['close'].ewm(14).mean()data['ema5'] = data['close'] / data['close'].ewm(5).mean()# Instead of using the actual volume value (which changes over time), we normalize it with a moving volume averagedata['normVol'] = data['volume'] / data['volume'].ewm(5).mean()# Remove columns that won't be used as featuresdel (data['open'])del (data['high'])del (data['low'])del (data['volume'])del (data['Adj Close'])return datadata = _get_indicator_data(data)
print(data.columns)Index(['close', 'RSI', 'MACD', 'SIGNAL', '14 period STOCH %K','MFV', '14 period ATR', 'MOM', '14 period MFI', 'ROC', 'OBV_x', 'OBV_y', '20 period CCI', '14 period EMV', 'VIm', 'VIp', 'ema50', 'ema21', 'ema14', 'ema5', 'normVol'], dtype='object')Right before we gather our predictions, I decided to keep a small bit of data to predict future values with. This line captures 5 rows corresponding to the 5 days of the week on July 27th.
在我們收集預測之前,我決定保留少量數據來預測未來價值。 該行捕獲與7月27日一周中的5天相對應的5行。
live_pred_data = data.iloc[-16:-11]Now comes one of the most important part of this project — computing the truth values. Without these, we wouldn’t even be able to train a machine learning model to make predictions.
現在是該項目最重要的部分之一-計算真值。 沒有這些,我們甚至無法訓練機器學習模型來進行預測。
How do we obtain truth value? Well it’s quite intuitive. If we want to know when a stock will increase or decrease (to make a million dollars hopefully!) we would just need to look into the future and observe the price to determine if we should buy or sell right now. Well, with all this historical data, that’s exactly what we can do.
我們如何獲得真理價值? 好吧,這很直觀。 如果我們想知道什么時候股票會增加或減少(希望能賺到一百萬美元!),我們只需要展望未來并觀察價格,以確定我們現在是否應該買賣。 好吧,有了所有這些歷史數據,這正是我們所能做的。
Going back to the table where we initially pulled our data, if we want to know the buy (1) or sell (0) decision on the day of 1993–03–29 (where the closing price was 11.4375), we just need to look X days ahead to see if the price is higher or lower than that on 1993–03–29. So if we look 1 day ahead, we see that the price increased to 11.5. So the truth value on 1993–03–29 would be a buy (1).
回到我們最初提取數據的表,如果我們想知道1993-03-29日(收盤價為11.4375)當天的買入(1)或賣出(0)決定,我們只需要提前X天查看價格是否高于或低于1993-03-29的價格。 因此,如果我們提前1天查看價格,價格會升至11.5。 因此,1993-03-29年的真值將為購買(1)。
Since this is also the last step of data processing, we remove all of the NaN value that our indicators and prediction generated, as well as removing the ‘close’ column.
由于這也是數據處理的最后一步,因此我們刪除了指標和預測生成的所有NaN值,并刪除了“關閉”列。
def _produce_prediction(data, window):"""Function that produces the 'truth' valuesAt a given row, it looks 'window' rows ahead to see if the price increased (1) or decreased (0):param window: number of days, or rows to look ahead to see what the price did"""prediction = (data.shift(-window)['close'] >= data['close'])prediction = prediction.iloc[:-window]data['pred'] = prediction.astype(int)return datadata = _produce_prediction(data, window=15)
del (data['close'])
data = data.dropna() # Some indicators produce NaN values for the first few rows, we just remove them here
data.tail()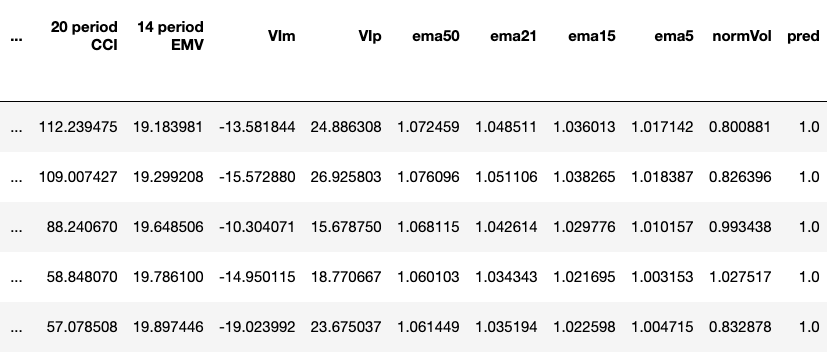
Because we used Pandas’ shift() function, we lose about 15 rows from the end of the dataset (which is why I captured the week of July 27th before this step).
因為我們使用了Pandas的shift()函數,所以從數據集的末尾損失了大約15行(這就是為什么我在此步驟之前于7月27日那周捕獲了數據)。

3.模型創建 (3. Model Creation)
Right before we train our model we must split up the data into a train set and test set. Obvious? That’s because it is. We have about a 80 : 20 split which is pretty good considering the amount of data we have.
在訓練模型之前,我們必須將數據分為訓練集和測試集。 明顯? 那是因為。 考慮到我們擁有的數據量,我們大約進行了80:20的劃分。
def _split_data(data):"""Function to partition the data into the train and test set:return:"""y = data['pred']features = [x for x in data.columns if x not in ['pred']]X = data[features]X_train, X_test, y_train, y_test = train_test_split(X, y, train_size= 4 * len(X) // 5)return X_train, X_test, y_train, y_testX_train, X_test, y_train, y_test = _split_data(data)
print('X Train : ' + str(len(X_train)))
print('X Test : ' + str(len(X_test)))
print('y Train : ' + str(len(y_train)))
print('y Test : ' + str(len(y_test)))X Train : 5493
X Test : 1374
y Train : 5493
y Test : 1374Next we’re going to use multiple classifiers to create an ensemble model. The goal here is to combine the predictions of several models to try and improve on predictability. For each sub-model, we’re also going to use a feature from Sklearn, GridSearchCV, to optimize each model for the best possible results.
接下來,我們將使用多個分類器創建一個集成模型。 此處的目標是結合幾種模型的預測,以嘗試并提高可預測性。 對于每個子模型,我們還將使用Sklearn的GridSearchCV功能來優化每個模型以獲得最佳結果。
First we create the random forest model.
首先,我們創建隨機森林模型。
def _train_random_forest(X_train, y_train, X_test, y_test):"""Function that uses random forest classifier to train the model:return:"""# Create a new random forest classifierrf = RandomForestClassifier()# Dictionary of all values we want to test for n_estimatorsparams_rf = {'n_estimators': [110,130,140,150,160,180,200]}# Use gridsearch to test all values for n_estimatorsrf_gs = GridSearchCV(rf, params_rf, cv=5)# Fit model to training datarf_gs.fit(X_train, y_train)# Save best modelrf_best = rf_gs.best_estimator_# Check best n_estimators valueprint(rf_gs.best_params_)prediction = rf_best.predict(X_test)print(classification_report(y_test, prediction))print(confusion_matrix(y_test, prediction))return rf_bestrf_model = _train_random_forest(X_train, y_train, X_test, y_test){'n_estimators': 160}
precision recall f1-score support
0.0 0.88 0.72 0.79 489
1.0 0.86 0.95 0.90 885
accuracy 0.87 1374
macro avg 0.87 0.83 0.85 1374
weighted avg 0.87 0.87 0.86 1374
[[353 136]
[ 47 838]]Then the KNN model.
然后是KNN模型。
def _train_KNN(X_train, y_train, X_test, y_test):knn = KNeighborsClassifier()# Create a dictionary of all values we want to test for n_neighborsparams_knn = {'n_neighbors': np.arange(1, 25)}# Use gridsearch to test all values for n_neighborsknn_gs = GridSearchCV(knn, params_knn, cv=5)# Fit model to training dataknn_gs.fit(X_train, y_train)# Save best modelknn_best = knn_gs.best_estimator_# Check best n_neigbors valueprint(knn_gs.best_params_)prediction = knn_best.predict(X_test)print(classification_report(y_test, prediction))print(confusion_matrix(y_test, prediction))return knn_bestknn_model = _train_KNN(X_train, y_train, X_test, y_test){'n_neighbors': 1}
precision recall f1-score support
0.0 0.81 0.84 0.82 489
1.0 0.91 0.89 0.90 885
accuracy 0.87 1374
macro avg 0.86 0.86 0.86 1374
weighted avg 0.87 0.87 0.87 1374
[[411 78]
[ 99 786]]Finally, the Gradient Boosted Tree.
最后,梯度提升樹。
def _train_GBT(X_train, y_train, X_test, y_test):clf = GradientBoostingClassifier()# Dictionary of parameters to optimizeparams_gbt = {'n_estimators' :[150,160,170,180] , 'learning_rate' :[0.2,0.1,0.09] }# Use gridsearch to test all values for n_neighborsgrid_search = GridSearchCV(clf, params_gbt, cv=5)# Fit model to training datagrid_search.fit(X_train, y_train)gbt_best = grid_search.best_estimator_# Save best modelprint(grid_search.best_params_)prediction = gbt_best.predict(X_test)print(classification_report(y_test, prediction))print(confusion_matrix(y_test, prediction))return gbt_bestgbt_model = _train_GBT(X_train, y_train, X_test, y_test){'learning_rate': 0.2, 'n_estimators': 180}
precision recall f1-score support
0.0 0.81 0.70 0.75 489
1.0 0.85 0.91 0.88 885
accuracy 0.84 1374
macro avg 0.83 0.81 0.81 1374
weighted avg 0.83 0.84 0.83 1374
[[342 147]
[ 79 806]]And now finally we create the voting classifier
現在,我們終于創建了投票分類器
def _ensemble_model(rf_model, knn_model, gbt_model, X_train, y_train, X_test, y_test):# Create a dictionary of our modelsestimators=[('knn', knn_model), ('rf', rf_model), ('gbt', gbt_model)]# Create our voting classifier, inputting our modelsensemble = VotingClassifier(estimators, voting='hard')#fit model to training dataensemble.fit(X_train, y_train)#test our model on the test dataprint(ensemble.score(X_test, y_test))prediction = ensemble.predict(X_test)print(classification_report(y_test, prediction))print(confusion_matrix(y_test, prediction))return ensembleensemble_model = _ensemble_model(rf_model, knn_model, gbt_model, X_train, y_train, X_test, y_test)0.8748180494905385
precision recall f1-score support
0.0 0.89 0.75 0.82 513
1.0 0.87 0.95 0.90 861
accuracy 0.87 1374
macro avg 0.88 0.85 0.86 1374
weighted avg 0.88 0.87 0.87 1374
[[387 126]
[ 46 815]]We can see that we gain slightly more accuracy by using ensemble modelling (given the confusion matrix results).
我們可以看到,通過使用集成建模(鑒于混淆矩陣結果),我們獲得了更高的準確性。
4.結果驗證 (4. Verification of Results)
For the next step we’re going to predict how the S&P500 will behave with our predictive model. I’m writing this article on the weekend of August 17th. So to see if this model can produce accurate results, I’m going to use the closing data from this week as the ‘truth’ values for the prediction. Since this model is tuned to have a 15 day window, we need to feed in the input data with the days in the week of July 27th.
下一步,我們將預測S&P500在預測模型中的表現。 我在8月17日的周末寫這篇文章。 因此,要查看該模型是否可以產生準確的結果,我將使用本周的結束數據作為預測的“真實”值。 由于此模型已調整為具有15天的窗口,因此我們需要將輸入數據與7月27日中的星期幾一起輸入。
July 27th -> August 17th
7月27日-> 8月17日
July 28th -> August 18th
7月28日-> 8月18日
July 29th -> August 19th
7月29日-> 8月19日
July 30th -> August 20th
7月30日-> 8月20日
July 31st -> August 21st
7月31日-> 8月21日
We saved the week we’re going to use in live_pred_data.
我們在live_pred_data中保存了將要使用的一周。
live_pred_data.head()
Here are the five main days we are going to generate a prediction for. Looks like the models predicts that the price will increase for each day.
這是我們要進行預測的五個主要日子。 看起來模型預測價格會每天上漲。
Lets validate our prediction with the actual results.
讓我們用實際結果驗證我們的預測。
del(live_pred_data['close'])
prediction = ensemble_model.predict(live_pred_data)
print(prediction)[1. 1. 1. 1. 1.]Results
結果
July 27th : $ 322.78 — August 17th : $ 337.91
7月27日:$ 322.78 — 8月17日:$ 337.91
July 28th : $ 321.74 — August 18th : $ 338.64
7月28日:321.74美元-8月18日:338.64美元
July 29th : $ 323.93 — August 19th : $ 337.23
7月29日:$ 323.93 — 8月19日:$ 337.23
July 30th : $ 323.95 — August 20th : $ 338.28
7月30日:$ 323.95-8月20日:$ 338.28
July 31st : $ 325.62 — August 21st : $ 339.48
7月31日:$ 325.62-8月21日:$ 339.48
As we can see from the actual results, we can confirm that the model was correct in all of its predictions. However there are many factors that go into determining the stock price, so to say that the model will produce similar results every time is naive. However, during relatively normal periods of time (without major panic that causes volatility in the stock market), the model should be able to produce good results.
從實際結果可以看出,我們可以確認該模型在所有預測中都是正確的。 但是,決定股價的因素有很多,因此說該模型每次都會產生相似的結果是很幼稚的。 但是,在相對正常的時間段內(沒有引起股票市場波動的重大恐慌),該模型應該能夠產生良好的結果。
5.總結 (5. Summary)
To summarize what we’ve done in this project,
總結一下我們在此項目中所做的工作,
- We’ve collected data to be used in analysis and feature creation. 我們已經收集了用于分析和特征創建的數據。
- We’ve used pandas to compute many model features and produce clean data to help us in machine learning. Created predictions or truth values using pandas. 我們已經使用熊貓來計算許多模型特征并生成干凈的數據,以幫助我們進行機器學習。 使用熊貓創建預測或真值。
- Trained many machine learning models and then combined them using ensemble learning to produce higher prediction accuracy. 訓練了許多機器學習模型,然后使用集成學習對其進行組合以產生更高的預測精度。
- Ensured our predictions were accurate with real world data. 確保我們的預測對真實世界的數據是準確的。
I’ve learned a lot about data science and machine learning through this project, and I hope you did too. Being my first article, I’d love any form of feedback to help improve my skills as a programmer and data scientist.
通過這個項目,我已經學到了很多有關數據科學和機器學習的知識,希望您也能做到。 作為我的第一篇文章,我希望獲得任何形式的反饋,以幫助提高我作為程序員和數據科學家的技能。
Thanks for reading :)
謝謝閱讀 :)
翻譯自: https://towardsdatascience.com/predicting-future-stock-market-trends-with-python-machine-learning-2bf3f1633b3c
python機器學習預測
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/391045.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/391045.shtml 英文地址,請注明出處:http://en.pswp.cn/news/391045.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

線程系列3--Java線程同步通信技術
)
Python數據結構之四——set(集合)

volatile關鍵字有什么用

knn 機器學習_機器學習:通過預測意大利葡萄酒的品種來觀察KNN的工作方式
)
MMU內存管理單元(看書筆記)

Java中如何讀取文件夾下的所有文件

github pages_如何使用GitHub Actions和Pages發布GitHub事件數據

c# .Net 緩存 使用System.Runtime.Caching 做緩存 平滑過期,絕對過期

python 實現分步累加_Python網頁爬取分步指南

Java 到底有沒有析構函數呢?

關于雙黑洞和引力波,LIGO科學家回答了這7個你可能會關心的問題

如何使用HTML,CSS和JavaScript構建技巧計算器

用于MLOps的MLflow簡介第1部分:Anaconda環境
![[WCF] - 使用 [DataMember] 標記的數據契約需要聲明 Set 方法](http://pic.xiahunao.cn/[WCF] - 使用 [DataMember] 標記的數據契約需要聲明 Set 方法)
[WCF] - 使用 [DataMember] 標記的數據契約需要聲明 Set 方法

sql注入語句示例大全_SQL Group By語句用示例語法解釋
的區別是什么?)
ConcurrentHashMap和Collections.synchronizedMap(Map)的區別是什么?

pymc3 貝葉斯線性回歸_使用PyMC3估計的貝葉斯推理能力

Hadoop Streaming詳解

mongodb分布式集群搭建手記
