在這三部分的博客中跟隨了演示之后,您將能夠: (After following along with the demos in this three part blog you will be able to:)
- Understand how you and your Data Science teams can improve your MLOps practices using MLflow 了解您和您的數據科學團隊如何使用MLflow改進您的MLOps實踐
- Use all the Components of MLflow (Tracking, Projects, Models, Registry) 使用MLflow的所有組件(跟蹤,項目,模型,注冊表)
- Use MLflow in an Anaconda Environment 在Anaconda環境中使用MLflow
- Use MLflow in a Docker Environment (Including running an IDE inside of a container) 在Docker環境中使用MLflow(包括在容器內運行IDE)
- Use Postgres Backend Store and Minio Artifact Store for Easy Collaboration 使用Postgres后端商店和Minio Artifact商店進行輕松協作
The instructions and demos below assume you are using a Mac OSX operating system. Other operating systems can be used with minor modifications.
以下說明和演示假定您使用的是Mac OSX操作系統。 其他操作系統可以稍作修改即可使用。
目錄: (Table of Contents:)
Part 1: Anaconda Environment
第1部分:Anaconda環境
What is MLflow and Why Should You Use It?
什么是MLflow?為什么要使用它?
Using MLflow with a Conda Environment
在Conda環境中使用MLflow
1.什么是MLflow,為什么要使用它? (1. What is MLflow and Why Should You Use It?)
基本概念 (Basic Concepts)
MLflow is an MLOps tool that can be used to increase the efficiency of machine learning experimentation and productionalization. MLflow is organized into four components (Tracking, Projects, Models, and Registry). You can use each of these components on their own but they are designed to work well together. MLflow is designed to work with any machine learning library, determine most things about your code by convention, and require minimal changes to integrate into an existing codebase. It aims to take any codebase written in its format and make it reproducible and reusable by multiple data scientists. MLflow lets you train, reuse, and deploy models with any library and package them into reproducible steps that other data scientists can use as a “black box”, without even having to know which library you are using.
MLflow是一種MLOps工具,可用于提高機器學習實驗和生產化的效率。 MLflow被組織為四個組件(跟蹤,項目,模型和注冊表)。 您可以單獨使用這些組件中的每個組件,但是它們被設計為可以很好地協同工作。 MLflow旨在與任何機器學習庫一起使用,按照約定確定有關代碼的大多數內容,并且只需進行最小的更改即可集成到現有代碼庫中。 它旨在獲取以其格式編寫的任何代碼庫,并使其可被多個數據科學家復制和重用。 MLflow允許您使用任何庫來訓練,重用和部署模型,并將它們打包為可重復的步驟,其他數據科學家可以將其用作“黑匣子”,而不必知道您使用的是哪個庫。
機器學習中的生產力挑戰 (Productivity Challenges in Machine Learning)
It is difficult to keep track of experiments
很難跟蹤實驗
If you are just working with a script or notebook, how do you tell which data, code, and parameters went into getting a particular model result?
如果您只是在使用腳本或筆記本,那么如何確定獲取特定模型結果的數據,代碼和參數呢?
It is difficult to reproduce code
難以復制代碼
Even if you have meticulously tracked the code versions and parameters, you need to capture the whole environment (e.g. library dependencies) to get the same result. This is especially challenging if you want another data scientist to use your code, or if you want to run the same code at scale on another platform (e.g. in the cloud).
即使您已經仔細跟蹤了代碼版本和參數,也需要捕獲整個環境(例如,庫依賴項)才能獲得相同的結果。 如果您想讓另一個數據科學家使用您的代碼,或者想在另一個平臺(例如,在云中)上大規模運行相同的代碼,則這尤其具有挑戰性。
There’s no standard way to package and deploy models
沒有打包和部署模型的標準方法
Every data science team comes up with its own approach for each ML library it uses, and the link between a model and the code and parameters that produced it is often lost.
每個數據科學團隊都會針對其使用的每個ML庫提出自己的方法,并且模型與產生該模型的代碼和參數之間的鏈接通常會丟失。
There is no central store to manage models (their version and stage transitions)
沒有中央存儲來管理模型(它們的版本和階段轉換)
A data science team creates many models. In the absence of a central place to collaborate and manage model lifecycle, data science teams face challenges in how they manage models and stages.
數據科學團隊會創建許多模型。 在缺乏協作和管理模型生命周期的中心位置的情況下,數據科學團隊在如何管理模型和階段方面面臨挑戰。
MLflow組件 (MLflow Components)
MLflow Tracking
MLflow追蹤
This is an API and UI for logging parameters, code versions, metrics, and artifacts when running your machine learning code and later for visualizing results. You can use MLflow Tracking in any environment (e.g. script or notebook) to log results to local files or to a server, then compare multiple runs. Teams can use MLflow tracking to compare results from different users.
這是一個API和UI,用于在運行機器學習代碼時記錄參數,代碼版本,指標和工件,并在以后用于可視化結果。 您可以在任何環境(例如腳本或筆記本)中使用MLflow Tracking將結果記錄到本地文件或服務器中,然后比較多次運行。 團隊可以使用MLflow跟蹤來比較不同用戶的結果。
MLflow Projects
MLflow項目
MLflow Projects are a standard format for packaging reusable data science code. Each project is simply a directory with code, and uses a descriptor file to specify its dependencies and how to run the code. For example, a project can contain a conda.yaml for specifying a Python Anaconda environment.
MLflow項目是用于包裝可重用數據科學代碼的標準格式。 每個項目只是一個包含代碼的目錄,并使用描述符文件指定其依賴關系以及如何運行代碼。 例如,一個項目可以包含conda.yaml用于指定Python Anaconda環境。
MLflow Models
MLflow模型
MLflow Models offer a convention for packaging machine learning models in multiple flavors, and a variety of tools to help deploy them. Each model is saved as a directory containing arbitrary files and a descriptor file that lists several “flavors” the model can be used in. For example, a Tensorflow model can be loaded as a TensorFlow DAG, or as a python function to apply to input data.
MLflow模型提供了一種用于包裝多種形式的機器學習模型的約定,并提供了多種工具來幫助部署它們。 每個模型都保存為包含任意文件的目錄和一個描述符文件,該文件列出了可以在其中使用的幾種“樣式”。例如,可以將Tensorflow模型作為TensorFlow DAG加載,或者作為python函數加載到輸入中數據。
MLflow Registry
MLflow注冊表
MLflow Registry offers a centralized model store, set of APIs, and UI, to collaboratively manage the full lifecycle of a MLflow model. It provides model lineage (which MLflow experiment and run produced the model), model versioning, stage transitions (for example from staging to production or archiving), and annotations.
MLflow Registry提供了一個集中的模型存儲,一組API和UI,以協作管理MLflow模型的整個生命周期。 它提供模型沿襲(由MLflow實驗并運行以生成模型),模型版本控制,階段過渡(例如,從登臺到生產或歸檔)和注釋。
可擴展性和大數據 (Scalability and Big Data)
An individual MLflow run can execute on a distributed cluster. You can launch runs on the distributed infrastructure of your choice and report results to a tracking server to compare them.
單個MLflow運行可以在分布式集群上執行。 您可以在您選擇的分布式基礎架構上啟動運行,并將結果報告給跟蹤服務器以進行比較。
MLflow supports launching multiple runs in parallel with different parameters, for example for hyperparameter tuning. You can use the Projects API to start multiple runs and the tracking API to track them.
MLflow支持并行啟動具有不同參數的多個運行,例如用于超參數調整。 您可以使用Projects API來啟動多個運行,并使用跟蹤API來跟蹤它們。
MLflow Projects can take input from, and write output to, distributed storage systems such as AWS S3. This means that you can write projects that build large datasets, such as featurizing a 100TB file.
MLflow項目可以從分布式存儲系統(例如AWS S3)中獲取輸入,或將輸出寫入到其中。 這意味著您可以編寫構建大型數據集的項目,例如將100TB文件特征化。
MLflow Model Registry offers large organizations a central hub to collaboratively manage a complete model lifecycle. Many data science teams within an organization develop hundreds of models, each model with its experiments, runs, versions, artifacts, and stage transitions.
MLflow Model Registry為大型組織提供了一個中心樞紐,以協作管理一個完整的模型生命周期。 組織中的許多數據科學團隊都會開發數百個模型,每個模型都包含其實驗,運行,版本,工件和階段轉換。
用例范例 (Example Use Cases)
Individual Data Scientists
個人數據科學家
Individual data scientists can use MLflow Tracking to track experiments locally on their machine, organize code in projects for future reuse, and output models that production engineers can then deploy using MLflow’s deployment tools.
單個數據科學家可以使用MLflow跟蹤來在其計算機上本地跟蹤實驗,組織項目中的代碼以供將來重用,以及輸出模型,生產工程師可以使用MLflow的部署工具進行部署。
Data Science Teams
數據科學團隊
Data science teams can deploy an MLflow Tracking server to log and compare results across multiple users working on the same problem (and experimenting with different models). Anyone can download and run another team member’s model.
數據科學團隊可以部署MLflow跟蹤服務器,以記錄和比較處理同一問題(并嘗試不同模型)的多個用戶的結果。 任何人都可以下載并運行其他團隊成員的模型。
Large Organizations
大型組織
Large organizations can share projects, models, and results. Any team can run another team’s code using MLflow Projects, so organizations can package useful training and data preparation steps that another team can use, or compare results from many teams on the same task. Engineering teams can easily move workflows from R&D to staging to production.
大型組織可以共享項目,模型和結果。 任何團隊都可以使用MLflow項目來運行另一個團隊的代碼,因此組織可以打包另一個團隊可以使用的有用的培訓和數據準備步驟,或者比較來自多個團隊在同一任務上的結果。 工程團隊可以輕松地將工作流程從研發轉移到生產到生產。
Production Engineers
生產工程師
Production engineers can deploy models from diverse ML libraries in the same way, store the models as files in a management system of their choice, and track which run a model came from.
生產工程師可以以相同的方式從各種ML庫中部署模型,將模型存儲為文件到他們選擇的管理系統中,并跟蹤運行模型的來源。
Researchers and Open Source Developers
研究人員和開源開發人員
Researchers and open source developers can publish code to GitHub in the MLflow project format, making it easy for anyone to run their code by pointing the mlflow run command directly to GitHub.
研究人員和開源開發人員可以以MLflow項目格式將代碼發布到GitHub,從而使任何人都可以通過將mlflow run命令直接指向GitHub來輕松運行其代碼。
ML Library Developers
ML庫開發人員
ML library developers can output models in the MLflow Model format to have them automatically support deployment using MLflow’s built in tools. Deployment tool developers (for example, a cloud vendor building a servicing platform) can automatically support a large variety of models.
ML庫開發人員可以使用MLflow Model格式輸出模型,以使其使用MLflow的內置工具自動支持部署。 部署工具開發人員(例如,構建服務平臺的云供應商)可以自動支持多種模型。
2.在Conda環境中使用MLflow (2. Using MLflow with a Conda Environment)
In this section we cover how to use the various features of MLflow with an Anaconda environment.
在本節中,我們介紹如何在Anaconda環境中使用MLflow的各種功能。
設置教程 (Setting up for the Tutorial)
- Make sure you have Anaconda installed 確保已安裝Anaconda
- Install a tool for installing programs (I use Homebrew) 安裝用于安裝程序的工具(我使用Homebrew)
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"3. Install Git
3.安裝Git
brew install git4. Clone the repository
4.克隆存儲庫
git clone https://github.com/Noodle-ai/mlflow_part1_condaEnv.git5. Create a conda environment from the conda.yaml file and activate
5.從conda.yaml文件創建一個conda.yaml環境并激活
conda env create --file conda.yaml
conda activate mlflow_demosIf, instead of using the conda.yaml to set up your environment, you wanted to create an environment from scratch use the following commands to create your own conda.yaml.
如果要從頭創建環境而不是使用conda.yaml來設置環境,請使用以下命令來創建自己的conda.yaml 。
conda create --name mlflow_demos python=3.8.3
conda activate mlflow_demos
conda install -c anaconda jupyter=1.0.0
conda install -c conda-forge mlflow=1.8.0
conda install scikit-learn=0.22.1
conda install -c anaconda psycopg2=2.8.5
conda install -c anaconda boto3=1.14.12
conda env export --name mlflow_demos > conda.yaml例子 (Examples)
Open experiment.ipynb and follow along. The notebook contains examples demonstrating how to use MLflow Tracking and MLflow Models. It also contains descriptions of how to use MLflow Projects.
打開experiment.ipynb然后繼續。 筆記本中包含一些示例,這些示例演示了如何使用MLflow跟蹤和MLflow模型。 它還包含有關如何使用MLflow項目的描述。
Using the Tracking API
使用Tracking API
The MLflow Tracking API lets you log metrics and artifacts (files from your data science code) in order to track a history of your runs.
MLflow Tracking API使您可以記錄指標和工件(數據科學代碼中的文件),以便跟蹤運行歷史。
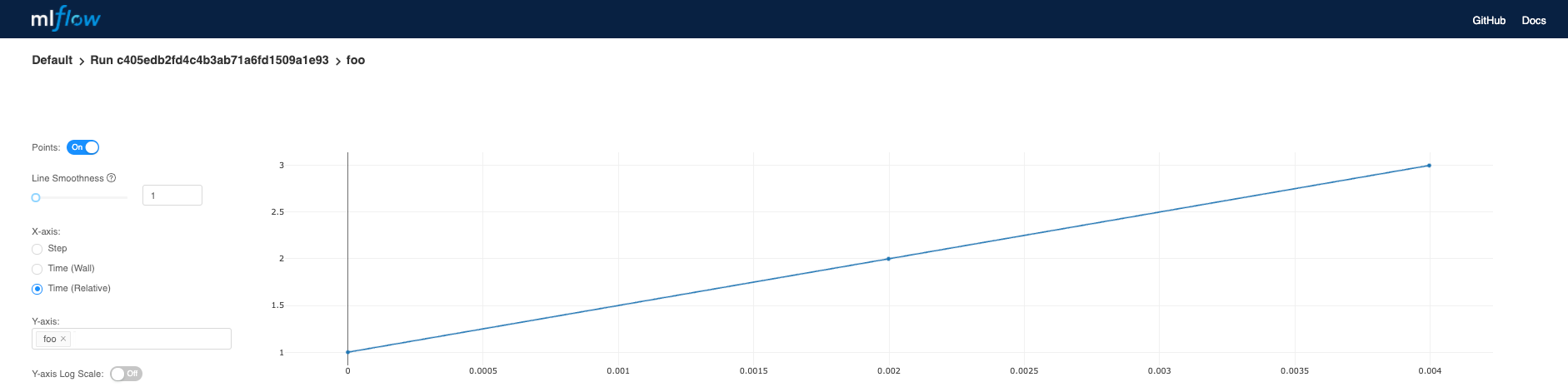
The code below logs a run with one parameter (param1), one metric (foo) with three values (1,2,3), and an artifact (a text file containing “Hello world!”).
下面的代碼使用一個參數(param1),一個帶有三個值(1,2,3)的度量(foo)和一個工件(一個包含“ Hello world!”的文本文件)記錄一次運行。
import mlflow
mlflow.start_run()
# Log a parameter (key-value pair)
mlflow.log_param("param1", 5)
# Log a metric; metrics can be updated throughout the run
mlflow.log_metric("foo", 1)
mlflow.log_metric("foo", 2)
mlflow.log_metric("foo", 3)
# Log an artifact (output file)
with open("output.txt", "w") as f:
f.write("Hello world!")
mlflow.log_artifact("output.txt")
mlflow.end_run()Viewing the Tracking UI
查看跟蹤界面
By default, wherever you run your program, the tracking API writes data into a local ./mlruns directory. You can then run MLflow’s Tracking UI.
默認情況下,無論您在哪里運行程序,跟蹤API都會將數據寫入本地./mlruns目錄。 然后,您可以運行MLflow的跟蹤UI。
Activate the MLflow Tracking UI by typing the following into the terminal. You must be in the same folder as mlruns.
通過在終端中輸入以下內容來激活MLflow跟蹤UI。 您必須與mlruns位于同一文件夾中。
mlflow uiView the tracking UI by visiting the URL returned by the previous command.
通過訪問上一個命令返回的URL來查看跟蹤UI。

Click on the run to see more details
單擊運行以查看更多詳細信息

Click on the metric to see more details.
單擊該指標以查看更多詳細信息。
合并MLflow跟蹤,MLflow模型和MLflow項目的示例 (Example Incorporating MLflow Tracking, MLflow Models, and MLflow Projects)
In this example MLflow Tracking is used to keep track of different hyperparameters, performance metrics, and artifacts of a linear regression model. MLflow Models is used to store the pickled trained model instance, a file describing the environment the model instance was created in, and a descriptor file that lists several “flavors” the model can be used in. MLflow Projects is used to package the training code. And lastly MLflow Models is used to deploy the model to a simple HTTP server.
在此示例中,MLflow跟蹤用于跟蹤線性回歸模型的不同超參數,性能指標和工件。 MLflow Models用于存儲腌制的經過訓練的模型實例,描述該模型實例在其中創建的環境的文件以及一個可以使用該模型的列出了幾種“風味”的描述符文件。MLflow Projects用于打包訓練代碼。 最后,MLflow模型用于將模型部署到簡單的HTTP服務器。
This tutorial uses a dataset to predict the quality of wine based on quantitative features like the wine’s “fixed acidity”, “pH”, “residual sugar”, and so on. The dataset is from UCI’s machine learning repository.
本教程使用數據集基于定量特征(如葡萄酒的“固定酸度”,“ pH”,“殘糖”等)來預測葡萄酒的質量。 數據集來自UCI的機器學習存儲庫。
Training the Model
訓練模型
First, we train the linear regression model that takes two hyperparameters: alpha and l1_ratio.
首先,我們訓練具有兩個超參數的線性回歸模型:alpha和l1_ratio。
This example uses the familiar pandas, numpy, and sklearn APIs to create a simple machine learning model. The MLflow Tracking APIs log information about each training run like hyperparameters (alpha and l1_ratio) used to train the model, and metrics (root mean square error, mean absolute error, and r2) used to evaluate the model. The example also serializes the model in a format that MLflow knows how to deploy.
本示例使用熟悉的pandas,numpy和sklearn API創建簡單的機器學習模型。 MLflow跟蹤API記錄有關每次訓練運行的信息,例如用于訓練模型的超參數(alpha和l1_ratio)以及用于評估模型的指標(均方根誤差,均值絕對誤差和r2)。 該示例還以MLflow知道如何部署的格式序列化了模型。
Each time you run the example MLflow logs information about your experiment runs in the directory mlruns.
每次運行示例MLflow時,都會在目錄mlruns記錄有關實驗運行的信息。
There is a script containing the training code called train.py. You can run the example through the .py script using the following command.
有一個包含訓練代碼的腳本,名為train.py 。 您可以使用以下命令通過.py腳本運行示例。
python train.py <alpha> <l1_ratio>There is also a notebook function of the training script. You can use the notebook to run the training (train() function shown below).
培訓腳本還具有筆記本功能。 您可以使用筆記本計算機運行訓練(如下所示的train()函數)。
# Wine Quality Sampledef train(in_alpha, in_l1_ratio):
import pandas as pd
import numpy as np
from sklearn.metrics import mean_squared_error, \
mean_absolute_error, r2_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import ElasticNet
import mlflow
import mlflow.sklearn def eval_metrics(actual, pred):
rmse = np.sqrt(mean_squared_error(actual, pred))
mae = mean_absolute_error(actual, pred)
r2 = r2_score(actual, pred)
return rmse, mae, r2 np.random.seed(40) # Read the wine-quality csv file from the URL
csv_url =\
'http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv'
data = pd.read_csv(csv_url, sep=';') # Split the data into training and test sets (0.75, 0.25) split
train, test = train_test_split(data)
# The predicted column is "quality" which is a scalar [3, 9]
train_x = train.drop(["quality"], axis=1)
test_x = test.drop(["quality"], axis=1)
train_y = train[["quality"]]
test_y = test[["quality"]]
# Set default values if no alpha is provided
if float(in_alpha) is None:
alpha = 0.5
else:
alpha = float(in_alpha)
# Set default values if no l1_ratio is provided
if float(in_l1_ratio) is None:
l1_ratio = 0.5
else:
l1_ratio = float(in_l1_ratio)
# Useful for multiple runs
with mlflow.start_run():
# Execute ElasticNet
lr = ElasticNet(
alpha=alpha,
l1_ratio=l1_ratio,
random_state=42
)
lr.fit(train_x, train_y)
# Evaluate Metrics
predicted_qualities = lr.predict(test_x)
(rmse, mae, r2) = eval_metrics(test_y, predicted_qualities)
# Print out metrics
print("Elasticnet model (alpha=%f, l1_ratio=%f):" % (alpha, l1_ratio))
print(" RMSE: %s" % rmse)
print(" MAE: %s" % mae)
print(" R2: %s" % r2)
# Log parameter, metrics, and model to MLflow
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
mlflow.sklearn.log_model(lr, "model")Comparing the Models
比較模型
Use the MLflow UI (as described above) to compare the models that you have produced.
使用MLflow UI(如上所述)比較您生成的模型。
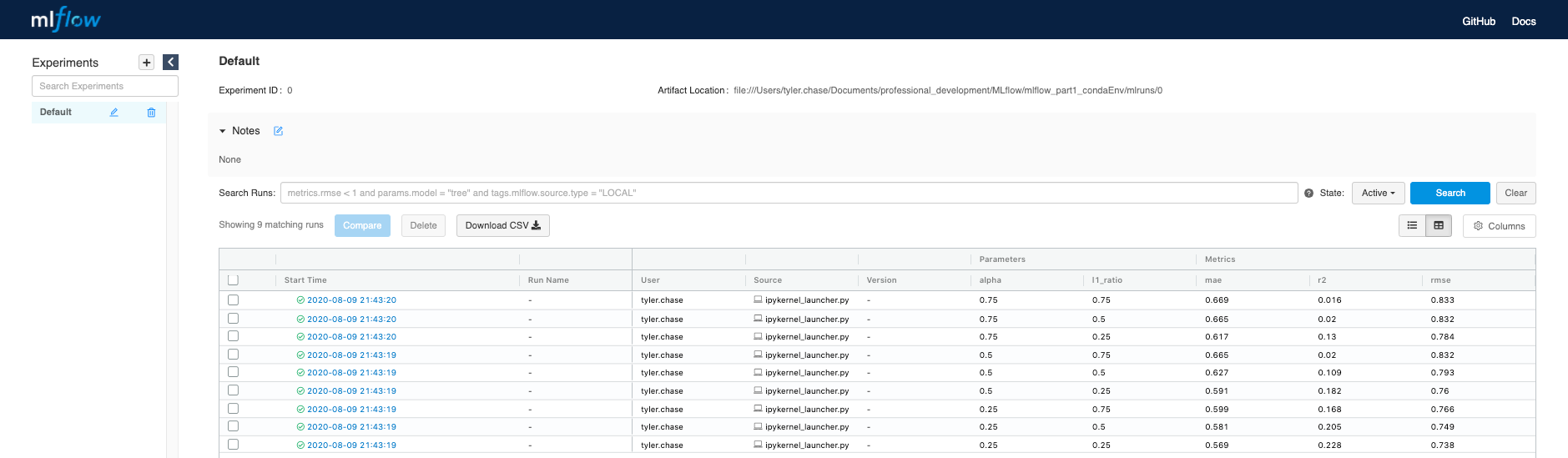
You can use the search feature to quickly filter out many models. For example the query (metrics.rmse < 0.8) returns all of the models with root mean square error less than 0.8. For more complex manipulations, you can download this table as a CSV and use your favorite data munging software to analyze it.
您可以使用搜索功能快速篩選出許多模型。 例如,查詢(metrics.rmse <0.8)返回均方根誤差小于0.8的所有模型。 對于更復雜的操作,您可以將該表下載為CSV,并使用自己喜歡的數據處理軟件對其進行分析。

Loading a Saved Model
加載保存的模型
After a model has been saved using MLflow Models within MLflow Tracking you can easily load the model in a variety of flavors (python_function, sklearn, etc.). We need to choose a model from the mlruns folder for the model path.
使用MLflow Tracking中的MLflow模型保存模型后,您可以輕松加載各種樣式的模型(python_function,sklearn等)。 我們需要從mlruns文件夾中選擇一個模型作為模型路徑。
model_path = './mlruns/0/<run_id>/artifacts/model'
mlflow.<model_flavor>.load_model(modelpath)Packaging the Training Code in a Conda Env with MLflow Projects
將培訓代碼與MLflow項目打包在Conda Env中
Now that you have your training code, you can package it so that other data scientists can easily reuse the training script, or so that you can run the training remotely.
現在您有了培訓代碼,可以打包它,以便其他數據科學家可以輕松地重用培訓腳本,或者可以遠程運行培訓。
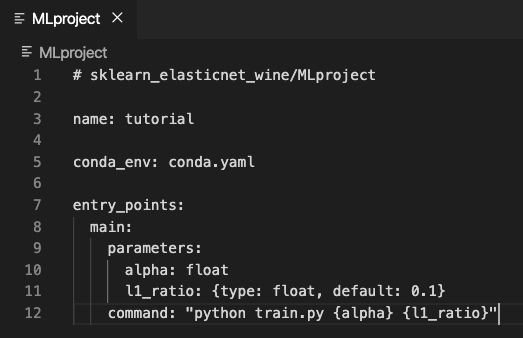
You do this by using MLflow Projects to specify the dependencies and entry points to your code. The MLproject file specifies the project has the dependencies located in a Conda environment (defined by conda.yaml) and has one entry point (train.py) that takes two parameters: alpha and l1_ratio.
您可以通過使用MLflow Projects指定代碼的依賴項和入口點來實現。 MLproject文件指定該項目具有位于Conda環境(由conda.yaml定義)中的依賴項,并具有一個入口點( train.py ),該入口點train.py兩個參數:alpha和l1_ratio。
To run this project use mlflow run on the folder containing the MLproject file.
要運行此項目,請在包含MLproject文件的文件夾上mlflow run mlflow。
mlflow run . -P alpha=1.0 -P l1_ratio=1.0After running this command, MLflow runs your training code in a new Conda environment with the dependencies specified in conda.yaml.
運行此命令后,MLflow運行在一個新conda環境中指定的依賴你的訓練碼conda.yaml 。
If a repository has an MLproject file you can also run a project directly from GitHub. This tutorial lives in the https://github.com/Noodle-ai/mlflow_part1_condaEnv repository which you can run with the following command. The symbol “#” can be used to move into a subdirectory of the repo. The “ — version” argument can be used to run code from a different branch.
如果存儲庫中有MLproject文件,您也可以直接從GitHub運行項目。 本教程位于https://github.com/Noodle-ai/mlflow_part1_condaEnv存儲庫中,您可以使用以下命令運行該存儲庫。 符號“#”可用于移至存儲庫的子目錄。 “ — version”自變量可用于從其他分支運行代碼。
mlflow run https://github.com/Noodle-ai/mlflow_part1_condaEnv -P alpha=1.0 -P l1_ratio=0.8Serving the Model
服務模型
Now that you have packaged your model using the MLproject convention and have identified the best model, it is time to deploy the model using MLflow Models. An MLflow Model is a standard format for packaging machine learning models that can be used in a variety of downstream tools — for example, real-time serving through a REST API or batch inference on Apache Spark.
既然您已經使用MLproject約定打包了模型并確定了最佳模型,那么現在該使用MLflow Models部署模型了。 MLflow模型是包裝機器學習模型的標準格式,可以在多種下游工具中使用,例如,通過REST API進行實時服務或在Apache Spark上進行批量推斷。
In the example training code above, after training the linear regression model, a function in MLflow saved the model as an artifact within the run.
在上面的示例訓練代碼中,在訓練了線性回歸模型之后,MLflow中的一個函數在運行中將模型另存為工件。
mlflow.sklearn.log_model(lr, "model")To view this artifact, you can use the UI again. When you click a date in the list of experiment runs you’ll see this page.
要查看此工件,可以再次使用UI。 當您點擊實驗運行列表中的日期時,您會看到此頁面。

At the bottom, you can see the call to mlflow.sklearn.log_model produced three files in ./mlruns/0/<run_id>/artifacts/model. The first file, MLmodel, is a metadata file that tells MLflow how to load the model. The second file is a conda.yaml that contains the model dependencies from the Conda environment. The third file, model.pkl, is a serialized version of the linear regression model that you trained.
在底部,你可以看到呼叫mlflow.sklearn.log_model中產生的三個文件./mlruns/0/<run_id>/artifacts/model 。 第一個文件MLmodel是元數據文件,它告訴MLflow如何加載模型。 第二個文件是conda.yaml ,其中包含來自Conda環境的模型依賴項。 第三個文件model.pkl是您訓練的線性回歸模型的序列化版本。
In this example, you can use this MLmodel format with MLflow to deploy a local REST server that can serve predictions.
在此示例中,您可以將此MLmodel格式與MLflow一起使用,以部署可以提供預測的本地REST服務器。
To deploy the server, run the following command.
要部署服務器,請運行以下命令。
mlflow models serve -m ./mlruns/0/<run_id>/artifacts/model -p 1234Note: The version of Python used to create the model must be the same as the one running mlflow models serve. If this is not the case, you may see the error UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0x9f in position 1: ordinal not in range(128) or raise ValueError, “unsupported pickle protocol: %d”.
注意:用于創建模型的Python版本必須與運行mlflow models serve的版本相同。 如果不是這種情況,您可能會看到錯誤UnicodeDecodeError: 'ascii' codec can't decode byte 0x9f in position 1: ordinal not in range(128) or raise ValueError, “unsupported pickle protocol: %d” 。
Once you have deployed the server, you can pass it some sample data and see the predictions. The following example uses curl to send a JSON-serialized pandas DataFrame with the split orientation to the model server. For more information about the input data formats accepted by the model server, see the MLflow deployment tools documentation.
部署服務器后,可以向其傳遞一些示例數據并查看預測。 以下示例使用curl將具有拆分方向的JSON序列化的熊貓DataFrame發送到模型服務器。 有關模型服務器接受的輸入數據格式的更多信息,請參閱MLflow部署工具文檔 。
curl -X POST -H "Content-Type:application/json; format=pandas-split" --data '{"columns":["alcohol", "chlorides", "citric acid", "density", "fixed acidity", "free sulfur dioxide", "pH", "residual sugar", "sulphates", "total sulfur dioxide", "volatile acidity"],"data":[[12.8, 0.029, 0.48, 0.98, 6.2, 29, 3.33, 1.2, 0.39, 75, 0.66]]}' http://127.0.0.1:1234/invocationsThe server should respond with output similar to:
服務器應使用類似于以下內容的輸出進行響應:
[3.7783608837127516]翻譯自: https://medium.com/noodle-labs-the-future-of-ai/introduction-to-mlflow-for-mlops-part-1-anaconda-environment-1fd9e299226f
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/391032.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/391032.shtml 英文地址,請注明出處:http://en.pswp.cn/news/391032.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
![[WCF] - 使用 [DataMember] 標記的數據契約需要聲明 Set 方法](http://pic.xiahunao.cn/[WCF] - 使用 [DataMember] 標記的數據契約需要聲明 Set 方法)
[WCF] - 使用 [DataMember] 標記的數據契約需要聲明 Set 方法

sql注入語句示例大全_SQL Group By語句用示例語法解釋
的區別是什么?)
ConcurrentHashMap和Collections.synchronizedMap(Map)的區別是什么?

pymc3 貝葉斯線性回歸_使用PyMC3估計的貝葉斯推理能力

Hadoop Streaming詳解

mongodb分布式集群搭建手記

歸約歸約沖突_JavaScript映射,歸約和過濾-帶有代碼示例的JS數組函數

為什么Java里面的靜態方法不能是抽象的

python16_day37【爬蟲2】

樸素貝葉斯實現分類_關于樸素貝葉斯分類及其實現的簡短教程

python:改良廖雪峰的使用元類自定義ORM
)
2019年度年中回顧總結_我的2019年回顧和我的2020年目標(包括數量和收入)

在Java里重寫equals和hashCode要注意什么問題

vray陰天室內_陰天有話:第1部分

【codevs2497】 Acting Cute

漸進式web應用程序_漸進式Web應用程序與加速的移動頁面:有什么區別,哪種最適合您?

高光譜圖像分類_高光譜圖像分析-分類

在Java里如何給一個日期增加一天

CentOS 7安裝和部署Docker
