knn 機器學習
Introduction
介紹
For this article, I’d like to introduce you to KNN with a practical example.
對于本文,我想通過一個實際的例子向您介紹KNN。
I will consider one of my project that you can find in my GitHub profile. For this project, I used a dataset from Kaggle.
我將考慮可以在我的GitHub個人資料中找到的我的項目之一。 對于這個項目,我使用了Kaggle的數據集。
The dataset is the result of a chemical analysis of wines grown in the same region in Italy but derived from three different cultivars organized in three classes. The analysis was done by considering the quantities of 13 constituents found in each of the three types of wines.
該數據集是對意大利同一地區種植的葡萄酒進行化學分析的結果,這些葡萄酒來自三個不同類別的三個品種。 通過考慮三種葡萄酒中每種葡萄酒中13種成分的數量來進行分析。
This article will be structured in three-part. In the first part, I will make a theoretical description of KNN, then I will focus on the part about exploratory data analysis in order to show you the insights that I found and at the end, I will show you the code that I used to prepare and evaluate the machine learning model.
本文將分為三部分。 在第一部分中,我將對KNN進行理論上的描述,然后,我將重點介紹探索性數據分析這一部分,以便向您展示我發現的見解,最后,我將向您展示我曾經使用過的代碼準備和評估機器學習模型。
Part I: What is KNN and how it works mathematically?
第一部分:什么是KNN及其在數學上的作用?
The k-nearest neighbour algorithm is not a complex algorithm. The approach of KNN to predict and classify data consists of looking through the training data and finds the k training points that are closest to the new point. Then it assigns to the new data the class label of the nearest training data.
k最近鄰居算法不是復雜的算法。 KNN預測和分類數據的方法包括瀏覽訓練數據并找到最接近新點的k個訓練點。 然后,它將新的訓練數據的類別標簽分配給新數據。
But how KNN works? To answer this question we have to refer to the formula of the euclidian distance between two points. Suppose you have to compute the distance between two points A(5,7) and B(1,4) in a Cartesian plane. The formula that you will apply is very simple:
但是KNN是如何工作的? 要回答這個問題,我們必須參考兩點之間的歐幾里得距離的公式。 假設您必須計算笛卡爾平面中兩個點A(5,7)和B(1,4)之間的距離。 您將應用的公式非常簡單:
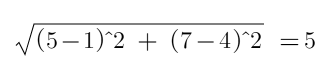
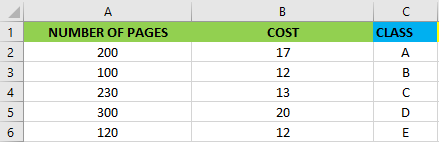
Okay, but how can we apply that in machine learning? Imagine to be a bookseller and you want to classify a new book called Ubick of Philip K. Dick with 240 pages which cost 14 euro. As you can see below there are 5 possible classes where to put our new book.
好的,但是我們如何將其應用到機器學習中呢? 想象成為一個書商,您想對一本名為Philip K. Dick的Ubick的新書進行分類,共有240頁,售價14歐元。 如您在下面看到的,有5種可能的類別可用于放置我們的新書。
To know which is the best class for Ubick we can use the euclidian formula in order to compute the distance with each observation in the dataset.
要知道哪個是Ubick的最佳分類,我們可以使用歐幾里得公式來計算數據集中每個觀測值的距離。
Formula:
式:

output:
輸出:
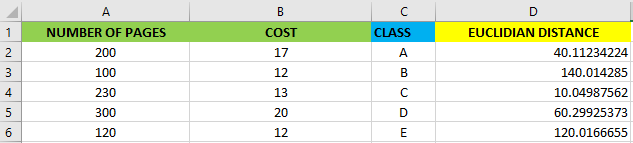
As you can see above the nearest class for Ubick is class C.
如您所見,Ubick最近的課程是C類 。
Part II: insights that I found to create the model
第二部分:我發現的創建模型的見解
Before to start to speak about the algorithm, that I used to create my model and predict the varieties of wine, let me show you briefly the main insights that I found.
在開始談論算法之前,我曾用它來創建模型并預測葡萄酒的種類,然后讓我簡要地向您展示我發現的主要見解。
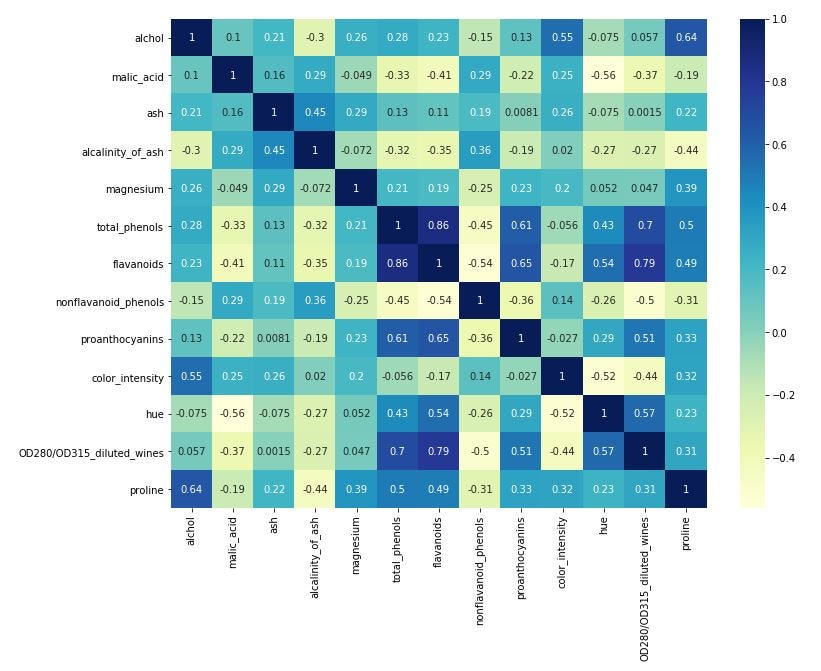
In the following heatmap, there are correlations between the different features. This is very useful to have a first look at the situation of our dataset and knowing if it is possible to apply a classification algorithm.
在下面的熱圖中,不同功能之間存在關聯。 首先了解一下數據集的情況,并了解是否有可能應用分類算法,這非常有用。
The heatmap is great for a first look but that is not enough. I’d like also to know if there are some elements whose absolute sum of correlations is low in order to delete them before to train the machine learning model. So, I construct a histogram as you can see below.
該熱圖乍一看很棒,但這還不夠。 我還想知道是否存在某些元素的相關絕對和很低,以便在訓練機器學習模型之前將其刪除。 因此,如下圖所示,我構建了一個直方圖。
You can see that there are three elements with low total absolute correlation. The elements are ash, magnesium and the color_intensity.
您會看到三個絕對絕對相關性較低的元素。 元素是灰,鎂和color_intensity。
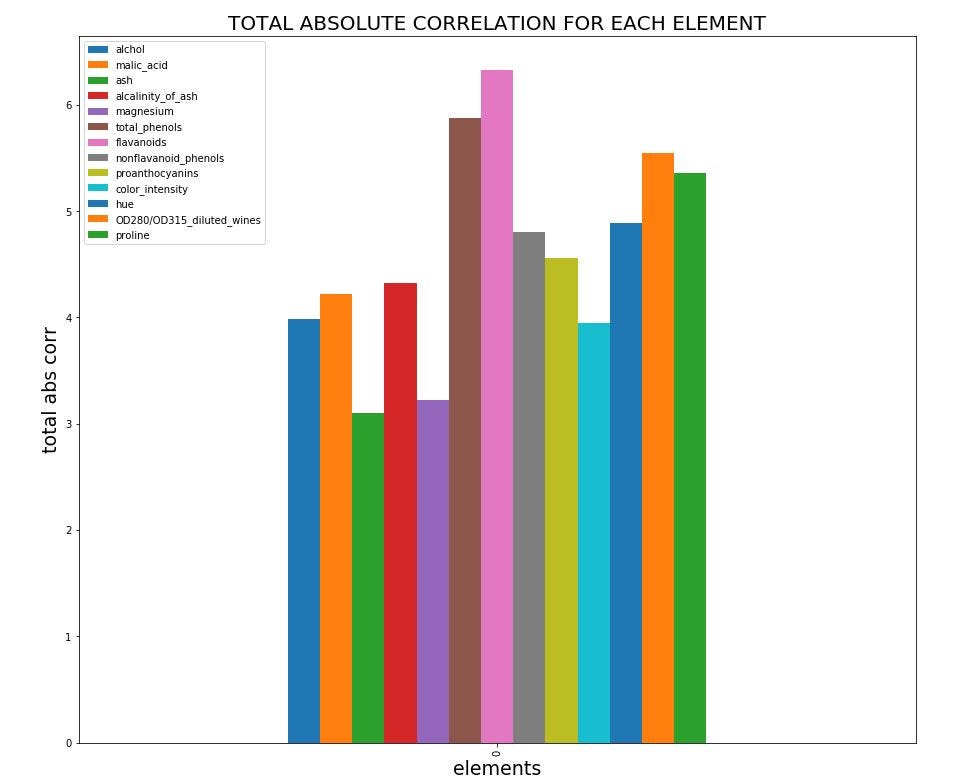
Thanks to these observations now we are sure that there is the possibility to apply a KNN algorithm to create a predictive model.
現在,由于這些觀察,我們確信可以應用KNN算法創建預測模型。
Part III: use scikit-learn to make predictions
第三部分:使用scikit-learn進行預測
In this part, we will see how to prepare the model and evaluate it thanks to scikit-learn.
在這一部分中,我們將借助scikit-learn了解如何準備模型并進行評估。
Below you can observe that I split the model into two parts: 80% for training and 20% for testing. I chose this proportion because the data set is not big.
在下面,您可以看到我將模型分為兩個部分:80%用于訓練,20%用于測試。 我選擇此比例是因為數據集不大。
# split data to train and test
y = df['class']
X = input_data.drop(columns=['ash','magnesium', 'color_intensity'])X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state=0)# to be sure that the data was split rightly (80% for train data and 20% for test data)print("X_train shape: {}".format(X_train.shape))
print("y_train shape: {}".format(y_train.shape))print("X_test shape: {}".format(X_test.shape))
print("y_test shape: {}".format(y_test.shape))out:
出:
X_train shape: (141, 10)
y_train shape: (141,)X_test shape: (36, 10)
y_test shape: (36,)You have to know that all machine learning models in scikit-learn are implemented in their own classes. For example, the k-nearest neighbors classification algorithm is implemented in the KNeighborsClassifier class.
您必須知道scikit-learn中的所有機器學習模型都是在各自的類中實現的。 例如,在KNeighborsClassifier類中實現了k最近鄰居分類算法。
The first step is to instantiate the class into an object that I called cli as you can see below. The object contains the algorithm that I will use to build the model from the training data and make predictions on new data points. It contains also the information that the algorithm has extracted from the training data.
第一步是將類實例化為一個我稱為cli的對象,如下所示。 該對象包含用于從訓練數據構建模型并對新數據點進行預測的算法。 它還包含算法已從訓練數據中提取的信息。
Finally, to build the model on the training set, we call the fit method of the cli object.
最后,要在訓練集上構建模型,我們調用cli對象的fit方法 。
from sklearn.neighbors import KNeighborsClassifiercli = KNeighborsClassifier(n_neighbors=1)
cli.fit(X_train, y_train)out:
出:
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',metric_params=None, n_jobs=None, n_neighbors=1, p=2,weights='uniform')In the output of the fit method, you can see the parameters used in creating the model.
在fit方法的輸出中,您可以看到用于創建模型的參數。
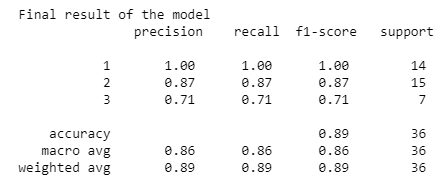
Now, it is time to evaluate the model. Below, the first output shows us that the model predict the 89% of the test data. Instead the second output give us a complete overview of the accuracy for each class.
現在,該評估模型了。 下面的第一個輸出向我們展示了該模型預測了89%的測試數據。 相反,第二個輸出為我們提供了每個類別的準確性的完整概述。
y_pred = cli.predict(X_test)
print("Test set score: {:.2f}".format(cli.score(X_test, y_test))) # below the values of the model
from sklearn.metrics import classification_report
print("Final result of the model \n {}".format(classification_report(y_test, y_pred)))out:
出:
Test set score: 0.89out:
出:
Conclusion
結論
I think that the best way to learn something is by practising. So in my case, I download the dataset from Kaggle which is one of the best places where to find a good dataset on which you can apply your machine learning algorithms and learn how they work.
我認為最好的學習方法是練習。 因此,就我而言,我是從Kaggle下載數據集的,這是找到良好數據集的最佳位置之一,您可以在該數據集上應用機器學習算法并了解它們的工作方式。
Thanks for reading this. There are some other ways you can keep in touch with me and follow my work:
感謝您閱讀本文。 您可以通過其他方法與我保持聯系并關注我的工作:
Subscribe to my newsletter.
訂閱我的時事通訊。
You can also get in touch via my Telegram group, Data Science for Beginners.
您也可以通過我的電報小組“ 面向初學者的數據科學”來聯系 。
翻譯自: https://towardsdatascience.com/machine-learning-observe-how-knn-works-by-predicting-the-varieties-of-italian-wines-a64960bb2dae
knn 機器學習
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/391041.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/391041.shtml 英文地址,請注明出處:http://en.pswp.cn/news/391041.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
)
MMU內存管理單元(看書筆記)

Java中如何讀取文件夾下的所有文件

github pages_如何使用GitHub Actions和Pages發布GitHub事件數據

c# .Net 緩存 使用System.Runtime.Caching 做緩存 平滑過期,絕對過期

python 實現分步累加_Python網頁爬取分步指南

Java 到底有沒有析構函數呢?

關于雙黑洞和引力波,LIGO科學家回答了這7個你可能會關心的問題

如何使用HTML,CSS和JavaScript構建技巧計算器

用于MLOps的MLflow簡介第1部分:Anaconda環境
![[WCF] - 使用 [DataMember] 標記的數據契約需要聲明 Set 方法](http://pic.xiahunao.cn/[WCF] - 使用 [DataMember] 標記的數據契約需要聲明 Set 方法)
[WCF] - 使用 [DataMember] 標記的數據契約需要聲明 Set 方法

sql注入語句示例大全_SQL Group By語句用示例語法解釋
的區別是什么?)
ConcurrentHashMap和Collections.synchronizedMap(Map)的區別是什么?

pymc3 貝葉斯線性回歸_使用PyMC3估計的貝葉斯推理能力

Hadoop Streaming詳解

mongodb分布式集群搭建手記

歸約歸約沖突_JavaScript映射,歸約和過濾-帶有代碼示例的JS數組函數

為什么Java里面的靜態方法不能是抽象的

python16_day37【爬蟲2】

樸素貝葉斯實現分類_關于樸素貝葉斯分類及其實現的簡短教程
