華盛頓特區與其他地區的差別
深度分析 (In-Depth Analysis)
Living in Washington DC for the past 1 year, I have come to realize how WMATA metro is the lifeline of this vibrant city. The metro network is enormous and well-connected throughout the DMV area. When I first moved to the Capital city with no car, I often used to hop on the metro to get around. I have always loved train journeys and therefore unsurprisingly, metro became my most favorite way to explore this beautiful city. On my travels, I often notice the product placements and advertisements on metro platforms, near escalators/elevators, inside the metro trains, etc. A good analysis of the metro rider data would help the advertisers to identify which metro stops are the busiest at what times so as to increase the ad exposure. I chanced upon this free dataset and decided to plunge deep into it. In this article, I’ll walk you through my analysis.
在過去的一年中,住在華盛頓特區,我逐漸意識到WMATA地鐵是這座充滿活力的城市的生命線。 地鐵網絡非常龐大,并且在DMV區域內連接良好。 當我第一次沒有汽車搬到首都時,我經常跳上地鐵到處走走。 我一直喜歡火車旅行,因此毫不奇怪,地鐵成為我探索這座美麗城市的最喜歡的方式。 在旅途中,我經常注意到地鐵站臺,自動扶梯/電梯附近,地鐵列車內等的產品位置和廣告。對地鐵乘客數據的良好分析將有助于廣告商確定哪些地鐵站最繁忙時間,以增加廣告曝光率。 我偶然發現了這個免費數據集,并決定深入其中。 在本文中,我將指導您進行分析。
Step 1: Importing necessary libraries
步驟1:導入必要的庫
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
from wordcloud import WordCloud, STOPWORDS
from nltk.corpus import stopwordsStep 2: Reading the data
步驟2:讀取資料
Let us call our pandas dataframe as ‘df_metro’ which will contain the original data.
讓我們將熊貓數據框稱為“ df_metro”,它將包含原始數據。
df_metro = pd.read_csv("DC MetroData.csv"Step 3: Eyeballing the data and length of the dataframe
步驟3:查看數據和數據幀的長度
df_metro.head()
df_metro.columnslen(df_metro)
Step 4: Checking distinct values under different columns
步驟4:檢查不同列下的不同值
Let us check what are the unique values in the column ‘Time’
讓我們檢查“時間”列中的唯一值是什么
df_metro['Time'].value_counts().sort_values()
Unique values in the column ‘Day’ are as follows:
“天”列中的唯一值如下:
df_metro['Day'].value_counts().sort_values()
Next step is to analyze few questions.
下一步是分析一些問題。
Q1。 什么是受歡迎的出入口? (Q1. What are the popular entrances and exits?)
The distinct count of records for each metro stop arranged in descending order will give us which are popular entrances and exits.
每個地鐵站按降序排列的獨特記錄數將為我們提供受歡迎的出入口。
df_metro['Entrance'].value_counts().sort_values(ascending=False).head()
df_metro['Exit'].value_counts().sort_values(ascending=False).head()
Popular locations seem to be
熱門地點似乎
Gallery Place-Chinatown: Major attractions are Capital One Arena (drawing big crowds for sporting events and music concerts), restaurants, bars, etc.
唐人街畫廊廣場:主要景點是首都一號競技場(吸引大量體育賽事和音樂會),餐館,酒吧等。
Foggy Bottom: Government offices in the area makes it a popular commute destination
有霧的底部:該地區的政府機關使其成為受歡迎的通勤目的地
Pentagon City: Its location just 2 miles away from the National Mall in downtown Washington makes the area a popular site for hotels and businesses.
五角大樓市:其位置距華盛頓市中心的國家購物中心僅2英里,使該地區成為酒店和企業的熱門地點。
Dupont Circle: International Embassies located in the area
杜邦環島:位于該地區的國際使館
Union Station: An important location for the long-distance travelers
聯合車站:長途旅行者的重要位置
Metro center: A popular downtown location
地鐵中心:市中心熱門地點
Fort Totten: Its Metro station serves as a popular transfer point for the Green, Yellow and Red lines
托滕堡(Fort Totten):其地鐵站是綠線,黃線和紅線的熱門換乘點
Takeaway: Advertisers should target the above popular metro stations that have the high rider footfall to grab maximum buyer attention.
要點:廣告商應該針對那些擁有較高人流的熱門地鐵站,以吸引最大的買家注意力。
Q2。 在一周的不同日期/時間,乘車情況如何? (Q2. What does the ridership look like during different days/times of the week?)
This can be answered by simply plotting the riders’ data across different days and times. We will make use of the seaborn library to create this viz.
只需繪制不同日期和時間的騎手數據即可解決。 我們將利用seaborn庫來創建此viz。
sns.set_style("whitegrid")
ax = sns.barplot(x="Day", y="Riders", hue="Time",
data = df_metro,
palette = "inferno_r")
ax.set(xlabel='Day', ylabel='# Riders')
plt.title("Rider Footfall on different Days/Times")
plt.show(ax)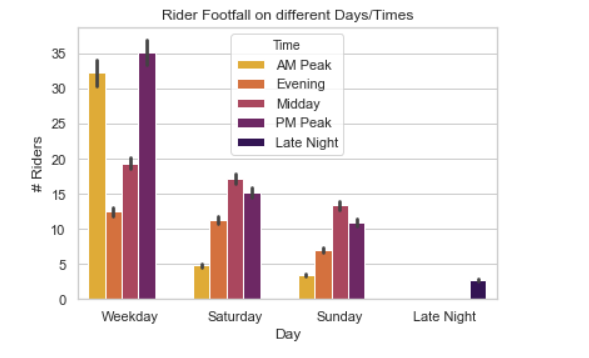
Takeaway: Metro is a popular choice of work commute in the city and therefore, as expected the rider footfall is the highest during the Weekday, particularly more so during AM Peak and PM Peak. Companies planning to roll out new products should target these slots to attract attention and generate interest in the consumers. For advertising opportunities during the weekend, the most attractive time slot seems to be Midday, closely followed by PM Peak.
要點:地鐵是城市通勤的一種流行選擇,因此,正如預期的那樣,乘客的人流量在工作日期間最高,尤其是在AM Peak和PM Peak。 計劃推出新產品的公司應針對這些廣告位,以吸引注意力并引起消費者的興趣。 對于周末的廣告機會而言,最吸引人的時間段似乎是中午,緊隨其后的是PM Peak。
Q3。 在典型的工作日中,哪些繁忙的路線? (Q3. What are the busy routes during a typical weekday?)
To analyze this question, we are going to consider a footfall of more than 500 riders at any given metro station. First, we will create a dataframe ‘busy_routes’ that contain data about routes with >500 riders. Second, we will filter this dataframe to contain data for only ‘AM Peak’. Third, we will sort this filtered output.
為了分析這個問題,我們將考慮在任何給定的地鐵站有500多名乘客的人流。 首先,我們將創建一個數據框“ busy_routes”,其中包含有關騎行人數超過500人的數據。 其次,我們將過濾此數據框以僅包含“ AM Peak”的數據。 第三,我們將對過濾后的輸出進行排序。
busy_routes = weekday[weekday['Riders']>500][['Merge', 'Time', 'Riders']]
peak_am = busy_routes.query('Time=="AM Peak"')
peak_am.sort_values('Riders').tail()
Repeating the same steps for ‘PM Peak’.
對“ PM Peak”重復相同的步驟。
peak_pm = busy_routes.query('Time=="PM Peak"')
len(peak_pm)
peak_pm.sort_values('Riders').tail()
Takeaway: We see that the routes with high footfall during AM Peak are the same with high footfall during the PM Peak such as West Falls Church — Farragut West, Vienna-Farragut West, Shady Grove — Farragut North. This tells us that these are the popular work commute routes as people going to work in Farragut during AM peak return to their homes in Vienna/Falls Church/Shady Grove during PM peak. Advertisers should target these high traffic commute routes to maximize on their advertisements and product placements.
要點:我們發現,在AM峰期間人流量大的路線與PM峰期間人流量大的路線相同,例如西瀑布教堂-西法拉格特,西維也納-法拉古特,謝迪格羅夫-北法拉格特。 這告訴我們,這是最受歡迎的工作通勤路線,因為人們在AM高峰期間在Farragut上班,而在PM高峰期間返回維也納/ Falls教堂/ Shady Grove的家中。 廣告商應針對這些高流量的通勤路線,以最大程度地利用其廣告和產品展示位置。
Q4。 周末有哪些熱門的地鐵路線? (Q4. What are the popular metro routes during the weekends?)
Let us perform a similar analysis as we did for the weekday. Since we are dealing with the weekend data here, we will consider metro stations with a footfall of more than 200 riders.
讓我們進行與工作日相似的分析。 由于我們在這里處理周末數據,因此我們將考慮擁有200多名乘客的地鐵站。
saturday = df_metro[df_metro['Day']=='Saturday']
busy_routes_sat = saturday[saturday['Riders']>200][['Merge', 'Time', 'Riders']]
busy_routes_sat.sort_values('Riders').tail()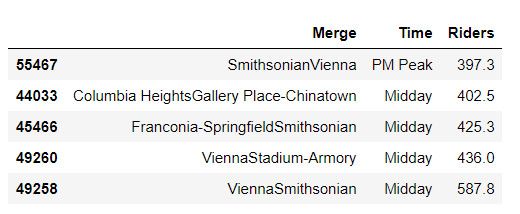
sunday = df_metro[df_metro['Day']=='Sunday']
busy_routes_sun = sunday[sunday['Riders']>200][['Merge', 'Time', 'Riders']]
busy_routes_sun.sort_values('Riders').tail()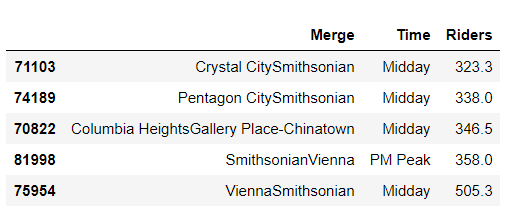
Takeaway: Smithsonian is an extremely popular destination with tourists as well as city-dwellers alike because of several museums and proximity to White House, The Capitol, national monuments, war memorials, etc. Our analysis tells us that the crowds head out from Crystal City, Pentagon City, Vienna, Franconia to the Smithsonian during the Midday, and return in the PM Peak. Most of these crowds are young families with kids which are an ideal audience for companies launching products meant for younger populations including children.
要點:史密森尼博物館是一個非常受游客和城市居民歡迎的目的地,因為它擁有數個博物館,而且鄰近白宮,國會大廈,國家古跡,戰爭紀念館等。我們的分析告訴我們,人群從水晶城出發,五角大樓市,維也納,弗蘭肯行政區到中午的史密森尼博物館,然后在PM山頂返回。 這些人群中大多數是有孩子的年輕家庭,這是公司推出針對包括兒童在內的年輕人口產品的理想受眾。
Q5。 作為廣告客戶,我應該在“深夜”中定位到哪些位置? (Q5. As an advertiser, which locations should I target during Late Night?)
We will do a similar analysis as above to identify which metro stations are ideal for putting out advertisements late in the night. For the ‘Late Night’, we will consider metro stations with a footfall of >50 riders.
我們將進行與上述類似的分析,以確定哪些地鐵站最適合在深夜發布廣告。 對于“深夜”,我們將考慮載客量超過50人的地鐵站。
late_night = df_metro[df_metro['Day']=='Late Night']
busy_routes_latenight = late_night[late_night['Riders']>50][['Merge', 'Time', 'Riders']]
busy_routes_latenight.sort_values('Riders').tail()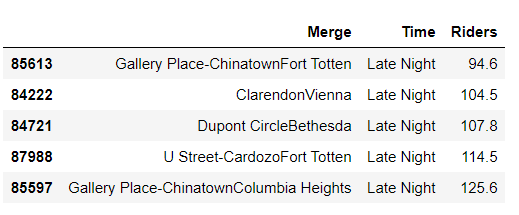
Takeaway: We see that late night the riders ride the metro from popular locations such as Gallery Place, Clarendon, Dupont Circle and U Street with a buzzing nightlife. Therefore, advertisers wanting to appeal to this section of the population (which normally would be a younger population) should potentially target these metro stations to grab maximum attention.
要點:我們看到深夜的時候,騎手們從熱門場所(如Gallery Place,Clarendon,Dupont Circle和U Street)乘坐地鐵,那里的夜生活很熱鬧。 因此,想要吸引這一部分人群(通常是較年輕的人群)的廣告商應該以這些地鐵站為目標,以吸引最大的關注。
Closing remarks: This dataset was fairly straightforward and hence, we did not spend a lot of time cleaning and wrangling the data. With the given data, we were able to find sweet spots that would ensure maximum moolah for advertisers’ money. Thanks for reading!
結束語:該數據集非常簡單,因此,我們沒有花費很多時間來清理和整理數據。 根據給定的數據,我們能夠找到最佳點,以確保最大程度地減少廣告客戶的收入。 謝謝閱讀!
翻譯自: https://medium.com/@tanmayee92/identify-profitable-advertising-locations-using-washington-dc-metro-data-a03c5c4fc18f
華盛頓特區與其他地區的差別
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/390882.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/390882.shtml 英文地址,請注明出處:http://en.pswp.cn/news/390882.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

Windows平臺下kafka環境的搭建

deeplearning.ai 改善深層神經網絡 week2 優化算法

gcc匯編匯編語言_什么是匯編語言?

鋪裝s路畫法_數據管道的鋪裝之路
)
leetcode421. 數組中兩個數的最大異或值(貪心算法)

IBM推全球首個5納米芯片:計劃2020年量產

drop sql語句_用于從表中刪除數據SQL Drop View語句
)
async 和 await的前世今生 (轉載)

項目案例:qq數據庫管理_2小時元項目:項目管理您的數據科學學習
)
react 示例_2020年的React Cheatsheet(+真實示例)

leetcode 993. 二叉樹的堂兄弟節點

Java之Set集合的怪

為mysql數據庫建立索引

查詢數據庫中有多少個數據表_您的數據中有多少汁?

記錄一個Python鼠標自動模塊用法和selenium加載網頁插件的設置

和css3實例教程_最好CSS和CSS3教程
)
leetcode 1442. 形成兩個異或相等數組的三元組數目(位運算)

數據科學與大數據技術的案例_作為數據科學家解決問題的案例研究

AJAX, callback,promise and generator
