數據科學與大數據技術的案例
There are two myths about how data scientists solve problems: one is that the problem naturally exists, hence the challenge for a data scientist is to use an algorithm and put it into production. Another myth considers data scientists always try leveraging the most advanced algorithms, the fancier model equals a better solution. While these are not fully groundless, they represent two common misunderstandings on how data scientists work: one emphasizes too much on the “execution” side, and the other overstate the “algorithm” part.
關于數據科學家如何解決問題有兩個神話:一個是問題自然存在,因此數據科學家面臨的挑戰是使用算法并將其投入生產。 另一個神話認為,數據科學家總是嘗試利用最先進的算法,更高級的模型等于更好的解決方案。 盡管這些并不是完全沒有根據的,但它們代表了關于數據科學家如何工作的兩個常見誤解:一個在“執行”方面過分強調,而另一個則夸大了“算法”部分。
Obviously, these myths are not how we actually solve problems. From my perspective, problem-solving for a data scientist is:
顯然,這些神話并不是我們實際解決問題的方式。 從我的角度來看,為數據科學家解決問題的方法是:
- more about “how to abstract the problem out of the business context”, not just “be handed with a specific task” 更多關于“如何從業務環境中抽象出問題”,而不僅僅是“處理特定任務”
- more about “solve the problem with an algorithm”, not just “use the best algorithm to solve a problem” 更多關于“使用算法解決問題”,而不僅僅是“使用最佳算法來解決問題”
- more about “iteratively deliver business value”, not just “implement the code and call it a day”. 更多關于“迭代地交付業務價值”,而不僅僅是“實施代碼并稱其為一天”。
With this said, I observe there are usually four stages involved in the problem-solving process, and I would like to share what are the four stages, and how it works in action with a case study, and then how can we get there with the right mindsets.
如此說來,我觀察到解決問題的過程通常涉及四個階段,我想分享這四個階段是什么,以及它如何與案例研究一起發揮作用,然后我們如何才能達到目標?正確的心態。
故事始于…… (The story starts with, once upon a time …)
My first job was in a company that operates an automotive pricing and information website and it went through the initial public offering (IPO) in May 2014. It was a great experience and I vividly remember everyone around was cheering on that day for the birth of a public company. As a public company, our revenue started to receive a lot of attention, especially with the first quarterly earnings report coming out in August. In early July, the director in the revenue department came to the Data Scientists' seating area, and it did not look like he got good news to share.
我的第一份工作是在一家經營汽車價格和信息網站的公司中,該公司于2014年5月進行了首次公開募股(IPO)。這是一次很棒的經歷,我生動地記得那天周圍的每個人都為該公司的誕生歡呼雀躍。上市公司。 作為一家上市公司,我們的收入開始受到廣泛關注,尤其是在八月份發布了第一份季度收益報告之后。 7月初,稅務部門的主管來到了數據科學家的辦公區,看來他沒有什么好消息可分享。
“We are in trouble, a percentage of the sales revenue cannot be credited appropriately; we need your help.”
“我們有麻煩,不能適當地記入一定比例的銷售收入; 我們需要您的幫助。”
Here are some relevant contexts: the company’s revenue is generated based on the fact that it introduces more sales to car dealers. To get the deserved commission, we need to match the sale of a vehicle to the correct customer. If our data providers can tell us which customer bought which vehicle, then the matching is done and no extra effort is needed; however, the problem is that one data provider decided to not provide the 1-to-1 sale record: it has to be done in a batch (visualization on what is a “batch” shown as below), then it is much harder and uncertain to know which customer bought which car.
以下是一些相關的上下文:公司的收入是基于這樣的事實而產生的:它為汽車經銷商帶來了更多的銷售。 為了獲得應得的傭金,我們需要將車輛的銷售與正確的客戶匹配。 如果我們的數據提供商可以告訴我們哪個客戶購買了哪輛汽車,那么匹配就完成了,不需要額外的工作; 但是,問題在于,一個數據提供者決定不提供一對一的銷售記錄:必須分批處理(可視化顯示如下所示的“批處理”),這會變得更加困難,并且不確定要知道哪個客戶買了哪輛車。

The revenue team was surprised by this change and after spending the past month trying to solve the problem, only 2% of sales from that data provider could be recovered manually. This would be bad news for the first earning call, so they came to seek help from Data Scientists. This is clearly an urgent problem that needs to be solved, so we jumped right on it.
收入團隊對此更改感到驚訝,在花費了過去一個月的時間來解決問題之后,只能手動恢復該數據提供商2%的銷售額。 這對于第一次打來的電話來說是個壞消息,因此他們來尋求數據科學家的幫助。 顯然,這是一個亟待解決的緊迫問題,因此我們跳過了。
階段1.了解問題,然后使用數學術語重新定義 (Stage 1. understand the problem, and then redefine it using mathematical terms)
This is the first stage of problem-solving in Data Science. Regarding “understand the problem” part, one needs to clearly identify the pain points so that once the pain point is resolved, the problem should be gone; regarding “redefine” the problem part, this is usually why a problem needs Data Scientist help.
這是數據科學中解決問題的第一步。 關于“理解問題”部分,需要清楚地識別痛點,以便一旦痛點得到解決,問題就應該消除。 關于“定義”問題部分,通常這就是為什么問題需要數據科學家的幫助。
For the specific one asked by our revenue team, the problem is: we cannot assign each sold vehicle to a customer, then we lose the revenue.
對于我們的收入團隊要求的特定問題,問題是:我們無法將每輛售出的車輛分配給客戶,然后我們損失了收入。
The pain point is: finding who purchased a vehicle in the given batch is manual and inaccurate, considering there are thousands of batches that need matching sales, it is very time-consuming and not sustainable.
痛點是:考慮到成千上萬的批次需要匹配的銷售,找到誰在給定的批次中購買了汽車是手動且不準確的,這非常耗時且不可持續。
The “redefined” problem in a mathematical term is: given a batch with customer C1, C2, .., Cn, along with the sold vehicle information, V1, V2, …, Vm, we need an automated solution to accurately identify the right matching pair (Ci, Vj) reflecting the actual purchasing event.
用數學術語來說,“重新定義”的問題是:給定一個具有客戶C1,C2,..,Cn的批次以及出售的車輛信息V1,V2,…,Vm,我們需要一個自動化的解決方案來準確地確定正確的反映實際購買事件的匹配對(Ci,Vj)。
第2階段。分解問題,確定邏輯算法解決方案,然后進行構建 (Stage 2. decompose the problem, identify a logical algorithm solution, and then build it out)
With the redefined problem, we can see this is a “matching” exercise under constraint, with given customers and vehicles in a batch. So I decomposed the problem further into two steps:
有了重新定義的問題,我們可以看到這是在給定的客戶和車輛成批的約束下的“匹配”練習。 因此,我將問題進一步分解為兩個步驟:
- Step 1. calculate the purchase likelihood for a customer given the vehicle P(C|V) 步驟1.計算給定車輛P(C | V)的客戶的購買可能性
- Step 2. based on the likelihood, attribute a car to the most likely customer in the batch 步驟2.根據可能性,將汽車分配給批次中最有可能的客戶
Now we can further identify the solution for each.
現在,我們可以進一步確定每種解決方案。
步驟1.概率計算 (Step 1. probability calculation)
For simplicity, let’s assume there are three customers (c1, c2, c3) in this batch, and one vehicle (v1) information is provided as a sale.
為簡單起見,我們假設此批次中有三個客戶(c1,c2,c3),并且提供了一輛汽車(v1)信息作為銷售。
- P(C=c1) represents the likelihood of c1 to buy any car. Assuming no prior knowledge about each customer, their likelihood of buying any car should be the same: P(C=c1) = P(C=c2) = P(C=c3), which equals a constant (e.g. 1/3 in this situation) P(C = c1)表示c1購買任何汽車的可能性。 假設沒有每個客戶的先驗知識,那么他們購買任何汽車的可能性應該是相同的:P(C = c1)= P(C = c2)= P(C = c3),它等于一個常數(例如1/3 in這個情況)
- P(V=v1) is the likelihood for v1 to be sold, given it is shown in this batch, this should be 1 (100% likelihood to be sold) P(V = v1)是v1被出售的可能性,鑒于此批次中顯示,該值應為1(100%的可能性出售)
Since there is only one customer making the purchase, this probability can be extended into:
由于只有一位客戶進行購買,因此可以將這種可能性擴展為:
P(V=v1) = P(C=c1, V=v1) + P(C=c2, V=v1) + P(C=c3, V=v1) = 1.0
P(V = v1)= P(C = c1,V = v1)+ P(C = c2,V = v1)+ P(C = c3,V = v1)= 1.0
For each of the item, given the following formula
對于每個項目,給定以下公式
P(C=c1, V=v1) = P(C=c1|V=v1) * P(V=v1) = P(V=v1|C=c1) * P(C=c1)
P(C = c1,V = v1)= P(C = c1 | V = v1)* P(V = v1)= P(V = v1 | C = c1)* P(C = c1)
We can see P(C=c1|V=v1) is proportional to P(V=v1|C=c1). So now, we can get the formula for the probability calculation:
我們可以看到P(C = c1 | V = v1)與P(V = v1 | C = c1)成正比。 現在,我們可以得出概率計算的公式:
P(C=c1|V=v1) = P(V=v1|C=c1) / (P(V=v1|C=c1) + P(V=v1|C=c2) + P(V=v1|C=c3))
P(C = c1 | V = v1)= P(V = v1 | C = c1)/(P(V = v1 | C = c1)+ P(V = v1 | C = c2)+ P(V = v1 | C = c3))
and the key is to get the probability for each P(V|C). Such a formula can be verbally explained as: the likelihood for a vehicle to be purchased by a specific customer is proportional to the likelihood for the customer to buy this specific vehicle.
關鍵是獲得每個P(V | C)的概率。 這樣的公式可以用語言來解釋為:特定顧客購買車輛的可能性與顧客購買該特定車輛的可能性成比例。
The above formula may look too “mathematical”, so let me put it into an intuitive context: assuming three people were in a room, one is a musician, one is an athlete, and one is a data scientist. You were told there is a violin in this room belong to one of them. Now guess, whom do you think is the owner of the violin? This is pretty straightforward, right? given the likelihood of musician to own a violin is high, and the likelihood of athlete and data scientists to own a violin is lower, it is much more likely for the violin to belong to the musician. The “mathematical” thinking process is illustrated below.
上面的公式看起來太“數學”了,因此讓我將其放在一個直觀的上下文中:假設三個人在一個房間里,一個是音樂家,一個是運動員,一個是數據科學家。 有人告訴您,這個房間里有一把小提琴屬于其中之一。 現在猜,您認為小提琴的所有者是誰? 這很簡單,對吧? 鑒于音樂家擁有小提琴的可能性較高,而運動員和數據科學家擁有小提琴的可能性較低,因此小提琴屬于音樂家的可能性更大。 下面說明了“數學”思維過程。

Now, let’s put the probabilities into a business context. As an online automotive pricing platform, each customer needs to generate at least one vehicle quote, hence, we assume the customer can be reasonably represented as the vehicles he/she quoted. Then such P(V|C) probability can be learned from existing data the company already accumulated in the history, including who generated a vehicle quote at when, and what vehicle they eventually bought. I would not further elaborate on the details, but the key point is that we can learn P(V|C), and then calculate the needed probability P(C|V) in each batch.
現在,讓我們將概率放入業務環境中。 作為一個在線汽車定價平臺,每個客戶都需要至少生成一個車輛報價,因此,我們假設該客戶可以合理地代表其報價的車輛。 然后,可以從公司在歷史記錄中已經積累的現有數據獲悉這種P(V | C)概率,包括誰在何時生成車輛報價以及他們最終購買了哪種車輛。 我不會進一步詳細說明,但是關鍵是我們可以學習P(V | C),然后計算每批中所需的概率P(C | V)。
步驟2.車輛歸屬 (Step 2. vehicle attribution)
Once we get the expected probability for each vehicle to be sold to customers, the second step is the attribution process. Assuming there is only one sold vehicle in the batch, such process is trivial; however, if there are multiple sold vehicles in the batch, either following approaches would work:
一旦我們獲得了每輛車出售給客戶的預期概率,第二步就是歸因過程。 假設批次中只有一輛售出的車輛,那么這個過程很簡單; 但是,如果批次中有多個售出的車輛,則可以使用以下兩種方法之一:
- (direct attribution) use only the calculated probability P(C|V), always attribute vehicle to customers with the highest likelihood. Under this approach, it is possible to attribute two vehicles to the same customer. (直接歸因)僅使用計算出的概率P(C | V),始終將車輛歸因于可能性最高的客戶。 在這種方法下,可以將兩輛車分配給同一客戶。
- (round-robin way) assume each customer buys at most one vehicle: once one vehicle is attributed to a customer, both are removed before the next round vehicle attribution. (輪循方式)假設每個客戶最多購買一輛車輛:一旦將一輛車輛歸于客戶,則在下一輪歸屬之前將兩者都移除。
Now we have designed a two-stepped algorithm to solve the key challenge, and it’s time to test the performance! Given there are historic quotes and sales data, it is straightforward to simulate the process of “creating random batches”, “attaching sales to the batch”, and try to “recover sales from the given batch information”. Such simulation provides a way to evaluate the model’s performance and we estimated more than 50% of sales can be recovered with high precision (>95%). We deployed the model for the real dataset, and the results matched our expectations well.
現在,我們設計了一個兩步算法來解決關鍵挑戰,現在該測試性能了! 鑒于有歷史報價和銷售數據,可以輕松地模擬“創建隨機批次”,“將銷售附加到批次”并嘗試“從給定的批次信息中恢復銷售”的過程。 這種模擬提供了一種評估模型性能的方法,我們估計可以以高精度(> 95%)收回超過50%的銷售額。 我們為實際數據集部署了該模型,結果與我們的預期非常吻合。
The revenue team was very happy with the above solution: comparing to the ~2% recovery rate, 50% is more than 25 X! From a business impact perspective, this revenue directly added to the bottom line for our first quarterly earnings report, and the contributed value from the Data Science team is significant.
收入團隊對上述解決方案感到非常滿意:與?2%的回收率相比,50%的回收率是25倍以上! 從業務影響的角度來看,該收入直接添加到了我們的第一季度收入報告的底線中,數據科學團隊的貢獻是巨大的。
階段3.深思熟慮,尋求機會進行進一步的改進 (Stage 3. Think deeper, and seek opportunities to make further improvement)
We run the above solution for an extra month and see the performance is pretty consistent, and now it is time to think about what’s next? We recovered 50% of sales, but how about the rest 50%? Is it possible to further improve the algorithm to get there?
我們將上述解決方案運行了一個多月,看到性能相當穩定,現在是時候考慮下一步了嗎? 我們收回了50%的銷售額,但其余50%呢? 是否有可能進一步改進算法以達到目標?
Usually, we, as data scientists, have a tendency to focus too much on the algorithm details; in this case, there were some discussions around how to better model the P(V|C): should we use a deep learning model to make this probability much better, etc. However, per my understanding, these pure algorithmic improvements usually result in just incremental performance, and it’s less likely we close the rest 50% gap.
通常,作為數據科學家,我們傾向于過多地關注算法細節。 在這種情況下,圍繞如何更好地對P(V | C)建模進行了一些討論:我們是否應使用深度學習模型來使這種概率更好,等等。但是,據我了解,這些純算法上的改進通常導致只是提高性能,而我們縮小50%的剩余差距的可能性較小。
Then I started a deeper conversation with the revenue team and trying to figure out what was missing in our understanding about the problem, turns out we can control how the customers are grouped into a batch! Although there are some restrictions (e.g. customers have to generate quotes from the same dealership), this gives us the freedom to further optimize, and I see this is the direction to close the gap of the rest 50% sales.
然后,我與收入團隊進行了更深入的對話,試圖找出我們對問題的了解中缺少的內容,結果我們可以控制將客戶分組的方式! 盡管存在一些限制(例如,客戶必須從同一個經銷商處生成報價),但是這給了我們進一步優化的自由,我認為這是縮小其余50%銷售差距的方向。
Why am I confident in this direction? Think about this situation: if you have 4 people to be batched, and each batch has 2 people. The best batching strategy is to put the most different people in the same batch so that once an item is returned, the attribution will be more accurate. The following visualization shows the concept. On the left side, if you put two musicians in the same batch, two athletes in the same batch, it’s very hard to know who owns the violin or basketball. While on the right side, if you have each batch with one musician and one athlete, it is much easier to tell Musician A owns the violin, and Athlete D owns the basketball, with high confidence.
我為什么對這個方向充滿信心? 考慮這種情況:如果要分批處理4個人,每批分2個人。 最佳的批處理策略是將最多的人放在同一批中,這樣一來,一旦退回貨品,歸因將更加準確。 以下可視化顯示了該概念。 在左側,如果將兩個音樂家放在同一批中,將兩個運動員放在同一批中,則很難知道誰擁有小提琴或籃球。 在右側,如果您每批都有一位音樂家和一位運動員,那么說出音樂家A擁有小提琴而運動員D擁有籃球則要容易得多。

To materialize the above concept, there are two steps required:
要實現上述概念,需要執行兩個步驟:
- (similarity definition) how to define customer to customer similarity? and then a batch’s entropy as the objective function to optimize for? (相似度定義)如何定義顧客與顧客之間的相似度? 然后將一批熵作為目標函數進行優化?
- (batch optimization) based on the above similarities, how to design an optimization strategy to achieve optimal batches? (批次優化)基于以上相似性,如何設計優化策略以實現最佳批次?
步驟1.相似性定義 (Step 1. similarity definition)
In the first stage solution, we already find a way to calculate P(V|C), here, I would make a direct generalization: the similarity between two customers is proportional to the average likelihood for both customers to purchase each other’s quoted vehicles. If each customer quoted only one vehicle (c1 quoted v1, and c2 quoted v2), then a simplified version looks as follows:
在第一階段的解決方案中,我們已經找到一種計算P(V | C)的方法 ,在這里,我將直接進行概括:兩個客戶之間的相似性與兩個客戶購買彼此報價的車輛的平均可能性成正比。 如果每個客戶僅報價一輛車(c1報價為v1,c2報價為v2),則簡化版本如下所示:
Similarity(C1, C2) = 0.5 * (P(V=v1|C=c2) + P(V=v2|C=c1))
相似度(C1,C2)= 0.5 *(P(V = v1 | C = c2)+ P(V = v2 | C = c1))
Once we have the pairwise similarity between two customers, we can define the entropy for a batch as the sum of mutual pairwise similarities between customers in the batch. Now, we have an objective function to optimize for: we want batches with maximum entropy
一旦我們有了兩個客戶之間的成對相似性,就可以將一個批次的熵定義為該批次中客戶之間相互成對相似性的總和。 現在,我們有一個優化的目標函數:我們想要具有最大熵的批次
步驟2.批次最佳化 (Step 2. batch optimization)
After reading some similar studies, I decided to use the 2-opt algorithm, which is a simple local search algorithm for solving the traveling salesman problem.
閱讀一些類似的研究后,我決定使用2-opt算法,這是一種用于解決旅行商問題的簡單本地搜索算法。
The basic concept of 2-opt algorithm is as follows: in every step, two edges are randomly picked and attempt to “swap”, if the objective function is better after the swap is done, then the swap will be executed; or else, re-pick two edges. The algorithm continues until the objective function is converged or the maximum iteration number is met. The following figure illustrates when two edges (red) are picked and swapped into new edges (blue), achieving a shorter distance.
2-opt算法的基本概念如下:在每個步驟中,隨機選擇兩個邊緣并嘗試“交換”,如果交換完成后目標函數更好,則將執行交換; 否則,重新拾取兩個邊緣。 該算法繼續進行,直到目標函數收斂或滿足最大迭代次數為止。 下圖說明了拾取兩個邊緣(紅色)并將其交換為新邊緣(藍色)時獲得的距離更短的情況。
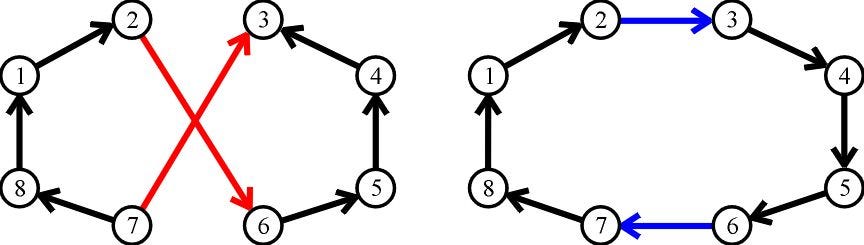
To apply the 2-opt algorithm in my case, I made analogies to the traveling salesman problem (TSP):
為了在我的情況下應用2-opt算法,我對旅行商問題(TSP)進行了類比:
- In TSP, two edges are randomly selected; in my cases, two batches are randomly selected, and then each batch randomly pick one customer inside to exchange 在TSP中,隨機選擇兩個邊; 在我的情況下,隨機選擇兩個批次,然后每個批次隨機選擇一個內部客戶進行交換
- In TSP, the total distance is used as the objective function, the shorter the better; in my case, the entropy of all batches is the objective function, the higher the better. 在TSP中,總距離用作目標函數,越短越好;反之亦然。 就我而言,所有批次的熵都是目標函數,越高越好。
Great, we have all the elements to optimize the batches! After implementing the algorithm, we further backtest over the existing data and found that: more than 85% of sales could be recovered. In the following month, when we apply this over the real dataset, the recovery rate is found at a similar level. This approach works, as expected!
太好了,我們擁有優化批次的所有要素! 實施該算法后,我們對現有數據進行了進一步的回測,發現:可以收回超過85%的銷售額。 在下個月,當我們將其應用于實際數據集時,發現恢復率處于相似的水平。 這種方法符合預期!
階段4.設計解決方案以使其可擴展和可維護 (Stage 4. Engineering the solution to make it extendable and maintainable)
What I described above is mainly the algorithm design part; and in parallel, there is the Engineering development part, and it is not easy to simply write the code and expect it to be extendable and maintainable.
我上面描述的主要是算法設計部分; 同時,還有工程開發部分,要簡單地編寫代碼并期望它具有可擴展性和可維護性并不容易。
During the project evolution, we gradually noticed there is a pattern of dependencies across the modules needed. The vehicle is represented by many features, and the customer is represented by a set of vehicles, and the batch is represented by a set of customers. With this high-level representation, we can build the dependency lineage as Vehicle -> Customer -> Batch.
在項目發展過程中,我們逐漸注意到,所需模塊之間存在某種依賴關系模式。 車輛由許多功能代表,客戶由一組車輛代表,批次由一組客戶代表。 通過這種高級表示,我們可以將依賴關系譜系構建為Vehicle-> Customer-> Batch。
Meanwhile, as a data product, we need to make sure the system can evolve to update the needed parameters and always evaluate the performance along the way. Hence the architecture was designed in the following way
同時,作為數據產品,我們需要確保系統可以發展以更新所需的參數,并始終評估性能。 因此,架構是通過以下方式設計的

With this architecture, what the Data Scientist need to do on a regular basis are:
使用這種架構,數據科學家需要定期進行以下操作:
- re-train model for the P(V|C) to ensure it incorporates the most recent customer purchasing behavior 對P(V | C)進行重新訓練模型,以確保它包含最新的客戶購買行為
- simulation over the whole process, including both batch optimization and sales attribution, to ensure the system performance is above a threshold 在整個過程中進行仿真,包括批次優化和銷售歸因,以確保系統性能超過閾值
- monthly batch optimization to prepare data for our revenue team and sales attribution to match a customer to the sales 每月批量優化,以為我們的收入團隊和銷售歸因準備數據,以使客戶與銷售匹配
Now we have built a sustainable data product that is maintainable. Given the data science team established a good reputation, in the next year, we heavily involved in the re-design of the sales matching system, which further expanded the data science footprint over the company. Because of this architecture’s operational excellence, it frees us more resources to seek the next challenge.
現在,我們已經構建了可維護的可持續數據產品。 鑒于數據科學團隊建立了良好的聲譽,明年,我們將大量參與銷售匹配系統的重新設計,從而進一步擴大了數據科學在公司的業務范圍。 由于該體系結構的卓越操作性,它使我們有更多的資源來尋求下一個挑戰。
正確心態的一般問題解決流程 (The general problem-solving flow with the right mindset)
The data science area is quite broad and designing algorithmic data products is only part of many potential projects. Other commonly-seen data science projects are experimentation design, causal inference, deep-dive analysis to drive strategic changes, etc. Although they may not strictly follow or even need all the stages I listed above, the four-stage flow still help to lay out a way to think about problem-solving in general:
數據科學領域非常廣泛,設計算法數據產品只是許多潛在項目的一部分。 其他常見的數據科學項目包括實驗設計,因果推斷,深入分析以推動戰略變革等。盡管它們可能并不嚴格遵循甚至需要上面列出的所有階段,但四階段流程仍然有助于奠定基礎提出一種思考解決問題的方法:
- Stage 1 (problem identification) is to help you focus on the key question and not loose track while diving deep into data 第1階段(問題識別)旨在幫助您專注于關鍵問題,而不會在深入研究數據時迷失方向
- Stage 2 (first logical solution) is to get you a quick win and keep the momentum to build trust with business partners 第2階段(第一個合乎邏輯的解決方案)是使您快速獲勝并保持與業務合作伙伴建立信任的動力
- Stage 3 (iterative improvement) is to help you move the solution further ahead and be the owner of the area 第3階段(迭代改進)旨在幫助您將解決方案向前推進并成為該區域的所有者
- Stage 4 (operational excellence) is to help you remove tech debt, to set you free from mundane maintenance works going forward 第4階段(卓越運營)旨在幫助您消除技術債務,使您免于日后的日常維護工作
The four-stage flow is not necessarily a strict rule one should follow, but it is more like a natural outcome if a data scientist has the right mindsets while facing any incoming challenge. In my opinion, these mindsets are:
四個階段的流程不一定是應該遵循的嚴格規則,但是如果數據科學家在面對任何即將來臨的挑戰時具有正確的心態,則它更像是自然的結果。 我認為這些心態是:
Business-driven, not algorithm-driven. Look at the big picture and see how data science fits in the business, understand why data science is needed and how it delivers value. Don’t be too attached to any specific algorithm: “if all you have is a hammer, everything looks like a nail".
業務驅動,而不是算法驅動 。 縱觀全局,了解數據科學如何適應業務,了解為什么需要數據科學以及它如何帶來價值。 不要太拘泥于任何特定的算法:“如果您只有錘子,那么一切看起來就像釘子”。
Owning the problem, not just taking orders. Being the owner of a problem means one will be proactive in thinking about how to solve it now, solve it better, and solve it with less effort. One would not stop at a sub-optimal solution and consider it done.
造成問題的,不僅是接單 。 成為問題的所有者,意味著人們將積極思考如何立即解決,更好地解決問題以及以更少的精力解決問題。 人們不會停在一個次優的解決方案上并認為它已經完成。
Open-minded, and always be learning. As an interdisciplinary field, data science overlaps with statistics, computer science, operational research, psychology, economics, marketing, sales, and more! It’s almost impossible to know all the areas ahead of time, so be open-minded and keep learning along the way. There could always be a better solution than the one you already knew.
胸襟開闊,永遠學習 。 作為一個跨學科領域,數據科學與統計,計算機科學,運籌學,心理學,經濟學,市場營銷,銷售等等重疊! 提前知道所有領域幾乎是不可能的,因此要胸襟開闊,并不斷學習。 總會有比您已經知道的更好的解決方案。
Hope you may find the above sharing helpful: happy problem solving, the data science way.
希望以上分享對您有所幫助:快樂的問題解決,數據科學的方式。
— — — — — — — — — — — — — —
— — — — — — — — — — — — — — — — —
If you enjoyed this article, help spread the word by liking, sharing, and commenting. Pan is currently a Data Science Manager at LinkedIn. You can read previous posts and follow him on LinkedIn.
如果您喜歡這篇文章,請通過喜歡,共享和評論來傳播這個詞。 Pan目前是LinkedIn的數據科學經理。 您可以閱讀以前的帖子并在 LinkedIn 上關注他 。
Here are two previous articles sharing Pan’s Data Science experience:
這是分享Pan的Data Science經驗的前兩篇文章:
My First Data Science Project
我的第一個數據科學項目
How to innovate in Data Science
如何在數據科學中創新
翻譯自: https://towardsdatascience.com/problem-solving-as-data-scientist-a-case-study-49296d8cd7b7
數據科學與大數據技術的案例
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/390864.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/390864.shtml 英文地址,請注明出處:http://en.pswp.cn/news/390864.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

AJAX, callback,promise and generator

Spring-Boot + AOP實現多數據源動態切換

css 幻燈片_如何使用HTML,CSS和JavaScript創建幻燈片

leetcode 1738. 找出第 K 大的異或坐標值

【數據庫】Oracle用戶、授權、角色管理


為什么游戲開發者不玩游戲_什么是游戲開發?

leetcode 692. 前K個高頻單詞

數據顯示,中國近一半的獨角獸企業由“BATJ”四巨頭投資

Java的Servlet、Filter、Interceptor、Listener

html5教程_最好HTML和HTML5教程
)
leetcode 1035. 不相交的線(dp)

SPI和RAM IP核

個人技術博客Alpha----Android Studio UI學習

數據科學家數據分析師_站出來! 分析人員,數據科學家和其他所有人的領導和溝通技巧...

leetcode 810. 黑板異或游戲

react-hooks_在5分鐘內學習React Hooks-初學者教程

分析工作試用期收獲_免費使用零編碼技能探索數據分析

select的一些問題。
