泰坦尼克:機器從災難中學習
For the first time in 2021, a major Machine Learning conference will have a track devoted to disaster response. The 16th Conference of the European Chapter of the Association for Computational Linguistics (EACL 2021) has a track on “NLP Applications for Emergency Situations and Crisis Management”.
2021年第一次,大型機器學習會議將專門討論災難響應。 計算語言學協會歐洲分會第 16屆會議(EACL 2021)的主題為“ NLP在緊急情況和危機管理中的應用”。
I am delighted to be the Senior Area Chair for this track! I’ve worked in machine learning and disaster response for 20 years and I’m glad that more people are now looking into how machine learning can help people at the most critical times.
我很高興成為該曲目的高級區域主席! 我從事機器學習和災難響應工作已有20年了,我很高興看到越來越多的人開始研究機器學習如何在最關鍵的時刻幫助人們。
The majority of what goes into a paper on machine learning for disaster response should be the same as any other paper in applied science: reproducible methods that clearly advance our knowledge of how to deploy and evaluate machine learning technologies.
關于機器學習以應對災難的論文的大部分內容應與應用科學領域的其他論文相同:可重現的方法明顯提高了我們對如何部署和評估機器學習技術的認識。
However, there are aspects of disaster response that make some aspects of the science more important and a few aspects that are unique to disaster response. Some will be familiar to researchers who have worked in healthcare, but some are drawn from international development. Here’s a summary of important points that are covered in this article:
但是,災難響應的某些方面使科學的某些方面更加重要,而災難響應所獨有的一些方面。 一些從事醫療保健工作的研究人員會很熟悉,但是有些來自國際發展。 這是本文涵蓋的重要點的摘要:
- The majority of disaster response is helping the crisis-affected community help themselves. Therefore, tools that empower disaster-affected communities are most valuable, especially speakers of low resource languages. 大部分災難響應都在幫助受危機影響的社區自我救助。 因此,增強受災社區能力的工具尤其是使用低資源語言的人最為有價值。
- Information management is a much bigger problem than information discovery for professional disaster responders. 對于專業的災難響應者而言,信息管理比信息發現要大得多。
- Papers focused on machine learning for disaster response should not cut corners on the science. 專注于機器學習以應對災難的論文不應在科學上走捷徑。
- Papers promoting system built by research labs have no place in disaster response. 研究實驗室建立的論文推廣系統在災難響應中沒有地位。
- It is not possible to fully evaluate the sensitivity of data during a disaster, so responses to ongoing disasters should default to private data practices. 無法完全評估災難期間數據的敏感性,因此對正在進行的災難的響應應默認為私有數據做法。
- Disaster response is often used as a cover for human rights violations, especially under authoritarian regimes, so research from authoritarian regimes that can violate human rights should be rejected. 災害響應常常被用作侵犯人權的掩護,尤其是在專制政權下,因此,應拒絕來自專制政權可能侵犯人權的研究。
- Researchers should not partner with non-operational aid organizations and should know how to spot the difference between operational and non-operational organizations. 研究人員不應與非運營援助組織合作,并且應該知道如何發現運營組織與非運營組織之間的差異。
- English social media processing is not interesting or useful for disaster responders. 英語社會媒體處理對于災難響應者來說并不有趣或沒有用。
- Ignore anything that relies on research published in “ISCRAM”. 忽略任何依賴于“ ISCRAM”中發表的研究的內容。
- Apply the “Do no harm” principle to evaluating impact. 將“請勿傷害”原則應用于評估影響。
I’ll share examples from my own experience as I expand on each one.
我將分享自己的經驗,并逐一舉例說明。
1.災害應對主要是社區自救 (1. Disaster response is mostly communities helping themselves)
For any large disaster, we simply don’t have the resources to help most people directly. In the lead up to a forest fire, your own preparation for your property will probably have a bigger impact than any preparation that professional firefighter has time to provide. During a pandemic, you will be directly responsible for social distancing and sanitation. After an earthquake, your neighbors are much more likely to pull you from your collapsed house than a professional search & rescue team.
對于任何大災難,我們根本沒有資源來直接幫助大多數人。 在導致森林大火之前,您自己準備的財產可能會比專業消防員有時間提供的任何準備產生更大的影響。 在大流行期間,您將直接與社會隔離和環境衛生負責。 地震后,與專業的搜救團隊相比,鄰居更容易將您從倒塌的房屋中拉出來。
The most important way to support these communities is with clear communication. Speakers of low resource languages are more likely to be the victims of natural and man-made disasters. Therefore, any technology that helps get information to linguistically diverse communities will be help them in disasters. In fact, I believe that the work I have done helping large companies deploy technology in more languages has had a bigger impact on disaster response than the time I spent working in refugee camps for the UN.
支持這些社區的最重要方法是清晰的溝通。 使用低資源語言的人更有可能成為自然和人為災難的受害者。 因此,任何有助于在語言上多樣化的社區中獲取信息的技術都將在災難中幫助他們。 實際上,我相信,與我在聯合國難民營工作的時間相比,我幫助大型公司以更多語言部署技術的工作對災難響應的影響更大。
So, if you are improving the machine translation or the language support of devices and applications like search engines and online stores, then you are already working on the single most important problem for machine learning in disaster response. It helps disaster responders communicate with the affected community and it helps the community search for the right resources online to help themselves.
因此,如果您要改善機器翻譯或對設備和應用程序(例如搜索引擎和在線商店)的語言支持,那么您已經在研究災難響應中機器學習的一個最重要的問題。 它可以幫助災難響應者與受影響的社區進行通信,還可以幫助社區在線搜索合適的資源以幫助自己。
Like I shared in Gretchen McCulloh’s recent Wired article, “Covid-19 Is History’s Biggest Translation Challenge”, I’ve seen the downsides of getting this wrong many times. For example, in Sierra Leone during the Ebola crisis, an international news agency broadcast Mande-language announcements in a Temne-speaking area, creating distrust because Mande was seen as the language of the political party who were in power at the time. As a result, Temne-speakers were more likely to avoid healthcare clinics.
就像我在Gretchen McCulloh在《 連線 》 雜志上發表的文章“ Covid-19是歷史上最大的翻譯挑戰 ”中所分享的一樣,我已經多次看到犯錯的弊端。 例如,在埃博拉危機期間的塞拉利昂,一家國際新聞社在泰姆語地區廣播曼德語的公告,造成不信任,因為曼德被視為當時執政的政黨的語言。 結果,講特姆語的人更可能避開醫療診所。
I worked with aid agencies to come up with the shocking conclusion that for every person who contracts Ebola, ten people died nearby from other preventable conditions because they were avoiding clinics. The amplification of wealthy nations’ fears into the local media, with too little attention to local languages, killed more people than Ebola itself.
我與援助機構合作得出了一個令人震驚的結論,即每感染埃博拉病毒的人中就有十人死于附近其他可預防的疾病,因為他們避開了診所。 富裕國家對當地媒體的恐懼加劇,而對當地語言的關注卻很少,比埃博拉病毒本身造成的死亡人數更多。
On the positive side, getting it right can make a big impact. For example, I recruited and managed 2,000 Haitian Kreyol speakers following the 2010 earthquake to translate emergency messages. The translators’ work saved many lives. It also supported machine learning research for disaster response, with the data used in the Workshop on Machine Translation shared task in 2011 (WMT11) and as part of a multilingual disaster response dataset that is now widely used.
從積極的一面來看,正確處理可能會產生重大影響。 例如,在2010年地震后,我招募和管理了2,000名海地克雷奧爾語發言人 ,以翻譯緊急信息。 譯者的工作挽救了許多生命。 它還通過2011 年機器翻譯研討會共享任務(WMT11)中使用的數據以及現在已被廣泛使用的多語言災難響應數據集的一部分,為災難響應的機器學習研究提供了支持。
Any paper focused on low resource languages can make the argument that it will be useful for disaster response, because it can be part of the foundational technology that allows disaster-affected populations to more easily communicate and access information and services.
任何針對低資源語言的論文都可以提出這樣的論點,即它對于災難響應將是有用的,因為它可以成為基礎技術的一部分,該基礎技術使受災人群能夠更輕松地交流和訪問信息與服務。
2.信息管理是專業災難響應者面臨的最大問題。 (2. Information management is the biggest problem for professional disaster responders.)
Most of the work that goes into disaster response is logistics and most disaster response professionals share information via spreadsheets and unstructured documents. It is a myth (from too many movies) that analytics and machine learning during a disaster is primarily focused on predicting where the next “hot-spot” will be. These use cases exist, but they are rare.
災難響應中的大部分工作是物流,大多數災難響應專業人員通過電子表格和非結構化文檔共享信息。 一個神話(從太多的電影中得出)是災難期間的分析和機器學習主要專注于預測下一個“熱點”的位置。 這些用例存在,但很少見。
For example, a disaster response leader in charge of planning drinking water distributions might get 100s of reports from the different agencies or regions, each one with pieces of information needed to estimate the overall need. The information needs to be extracted from each of those reports reliably.
例如,負責規劃飲用水分配的災難響應負責人可能會從不同機構或地區獲得100份報告,每份報告都帶有估計總體需求所需的信息。 需要可靠地從每個報告中提取信息。
So, if you can develop machine learning systems that can extract information from semi-structured tables and forms in spreadsheets and PDF documents, then you are working on one of the most important problems for supporting disaster response professionals.
因此,如果您可以開發能夠從電子表格和PDF文檔中的半結構化表格和表格中提取信息的機器學習系統,那么您正在研究支持災難響應專業人員的最重要問題之一。
A good example from 10 years ago that is still relevant is “Designing Adaptive Feedback for Improving Data Entry Accuracy”, by Kuang Chen, Joseph M. Hellerstein, and Tapan S. Parikh. The paper evaluates machine learning-assisted technologies to help professional data entry clerks digitize patient data from clinics in rural Uganda, supporting a large population of Congolese refugees.
10年前仍然有用的一個很好的例子是Kuang Chen,Joseph M. Hellerstein和Tapan S. Parikh撰寫的“ 設計自適應反饋以提高數據輸入的準確性 ”。 本文評估了機器學習輔助技術,以幫助專業數據錄入員對烏干達農村診所的患者數據進行數字化處理,為大量剛果難民提供支持。
3.不要在科學上走捷徑 (3. Don’t cut corners on the science)
You have probably seen in the COVID-19 news that infectious disease professionals are opposed to the wide-spread use of vaccines that have not gone through appropriate testing. If vaccines for the most widespread pandemic in living memory can wait for the science, so can your machine learning research.
您可能已經在COVID-19新聞中看到,傳染病專業人士反對尚未通過適當測試的疫苗的廣泛使用。 如果針對生命記憶中最廣泛流行的疫苗可以等待科學,那么您的機器學習研究也可以等待科學。
But we can speed up the review process. For example, at the recent ACL 2020 Workshop on Natural Language Processing for COVID-19 (NLP-COVID), we reviewed papers as they were submitted instead of waiting for the final deadline. However, we did not drop the standard for acceptance in any way.
但是我們可以加快審核過程。 例如,在最近的ACL 2020 COVID-19自然語言處理(NLP-COVID)研討會上 ,我們審查了提交的論文,而不是等待最終截止日期。 但是,我們沒有以任何方式放棄接受標準。
4.研究實驗室的系統演示論文在災難響應研究中沒有位置 (4. System demonstration papers from research labs have no place in disaster response research)
Toyota Land Cruisers are a cliche in the aid world: they have been the majority of vehicles that I have seen in some response situations.
豐田陸地巡洋艦是救援界的老牌車隊:在某些情況下,它們是我所見過的大多數車輛。

Land Cruisers are not necessarily the most perfect vehicle for aid, but they are the most reliable and predictable. When they do have problems, there will be many people who know how to repair them and many suitable replacement parts available.
陸地巡洋艦不一定是最理想的援助工具,但它們是最可靠和可預測的。 當它們確實有問題時,將有很多人知道如何維修它們以及許多合適的替換零件。
Could an academic research lab design a vehicle more suitable for disaster response? No doubt. Should those vehicles actually be deployed in a critical situation? Absolutely not. Spare parts would be hard to come by and the only experts would be a small number of academics who would quickly move onto other work and not be available to help with mechanical issues. So, the science from that lab might inform future development, but they should not build the actual vehicles.
學術研究實驗室可以設計一種更適合災難響應的車輛嗎? 毫無疑問。 這些車輛是否真的應該在緊急情況下部署? 絕對不。 備件將很難獲得,唯一的專家就是少數學者,他們將Swift轉移到其他工作上,而又無法解決機械問題。 因此,該實驗室的科學知識可能會為將來的發展提供信息,但他們不應制造實際的車輛。
The same applies to any software. Software can inform the science and be used in controlled environments during non-critical periods, especially if there are human-computer interaction (HCI) components that are important to test. However, machine learning researchers do not have the skills to create scalable technology or the ability to continue to support that software for years to come. Aid agencies don’t have the engineering capacity take an academic system and make it scalable and reliable through extensive development and testing. There is simply no use for academic demos where the authors claim that their technology should be used for actual critical data.
這同樣適用于任何軟件。 軟件可以為科學提供參考,并可以在非關鍵時期在受控環境中使用,尤其是在存在對測試很重要的人機交互(HCI)組件的情況下。 但是,機器學習研究人員沒有創造可擴展技術的技能,也沒有能力在未來幾年繼續支持該軟件。 援助機構不具備具備學術能力的工程能力,無法通過廣泛的開發和測試使其具有可擴展性和可靠性。 作者聲稱需要將其技術用于實際關鍵數據的學術演示完全沒有用。
Even when I was at Stanford, arguably the most industry-focused technical university, I did not work with colleagues there when I needed to develop tools quickly as a disaster responder. I worked with commercial software solutions, because reliability was more important than innovation, and it was only after the response that I led research on how machine learning could improve future responses.
即使在斯坦福大學(可以說是最專注于行業的技術大學)時,當我需要作為災難響應者快速開發工具時,也沒有與那里的同事一起工作。 我從事商業軟件解決方案的工作,是因為可靠性比創新更重要,而且只有在做出回應之后,我才開始研究機器學習如何改善未來的響應。
5.默認為私有數據慣例。 (5. Default to private data practices.)
During an ongoing disaster, it is not possible to determine whether data that seems non-sensitive today will in fact become sensitive later. So, don’t publish any personal data, including already open social media, as part of a paper during a disaster. Instead, wait until the affected population are no longer at risk and then engage privacy professionals to help decide what can and cannot be shared.
在持續的災難中,無法確定今天似乎不敏感的數據是否實際上會在以后變得敏感。 因此,在災難期間,請勿發布任何個人數據(包括已經開放的社交媒體)作為論文的一部分。 取而代之的是,等到受影響的人群不再處于危險之中,然后聘請隱私專業人員來幫助確定可以共享和不能共享的內容。
Even for data that is seen as open, re-publishing that data can become sensitive if you republish it in new contexts, and aggregated data (including Machine Learning models) can become more sensitive than its individual data points.
即使對于被視為開放的數據,如果您在新的上下文中重新發布該數據,則重新發布該數據也會變得敏感,并且聚合數據(包括機器學習模型)可能會比其單個數據點更加敏感。
For example, during the Arab Spring, I saw a lot of people tweeting about their local conditions: road closures, refugees, etc. While they were “public” tweets, the tweets were clearly written with only a handful of followers in mind, and they didn’t realize that reporting road closures would also help paint a picture of troop movements. As an example of what not to do, some of these tweets were copied to UN-controlled websites and re-published, with no mechanism for the original authors to remove them from the UN sites. Many actors within the Middle East and North Africa saw the UN as a negative foreign influence (or invader) and the people tweeting were therefore seen as collaborators — they didn’t care if these people only intended to be sharing information with a small number of followers.
例如,在“阿拉伯之春”期間,我看到很多人在發布有關當地情況的推文:封路,難民等。雖然它們是“公共”推文,但這些推文顯然只在少數追隨者的心目中撰寫,他們沒有意識到報告封路也不會有助于描繪部隊的動向。 作為不采取行動的一個例子,這些推文中的一些被復制到聯合國控制的網站上并重新發布,而原始作者沒有任何機制將其從聯合國站點中刪除。 中東和北非的許多參與者都將聯合國視為負面的外國影響(或侵略者),因此發推文的人被視為合作者–他們不在乎這些人是否只打算與少數人分享信息追隨者。
So, you need to ask yourself: what is the effect of recontextualizing the data or model so that it is now published by myself or my organization?
因此,您需要自問:重新對數據或模型進行上下文化以使其現在由本人或我的組織發布會產生什么影響?
6.災害應對經常被用作侵犯人權的掩護 (6. Disaster response is often used as a cover for human rights violations)
While crime typically goes down overall following disasters, a small number of predators and opportunists will try to gain advantage from the chaos. This is especially true in oppressive governments who use disasters as a cover to identify and silence their critics.
盡管災難通常會在整個災難之后使犯罪率下降 ,但少數掠食者和機會主義者會設法從混亂中獲得好處。 在壓迫性政府中尤其如此,這些政府利用災難作為掩飾來識別和壓制批評家。
If you are a reviewer or a researcher considering research into personal information including ethnicity, religion, gender, or political preferences, then you should take into consideration the use case and whether it can be used for human rights violations, especially by Authoritarian Regimes. As a guide, look at the Democracy Index compiled by the Economist Intelligence Unit (EIU): https://en.wikipedia.org/wiki/Democracy_Index.
如果您是考慮對包括種族,宗教,性別或政治偏好在內的個人信息進行研究的審稿人或研究人員,則應考慮用例,以及該用例是否可用于侵犯人權的行為,特別是在專制制度下。 作為指南,請查看經濟學人智庫(EIU)編制的民主指數: https : //en.wikipedia.org/wiki/Democracy_Index 。
They rank countries and put them into four buckets: Full Democracies, Flawed Democracies, Hybrid Regimes, and Authoritarian Regimes. This is important because: independent research institutions cannot exist in Authoritarian Regimes.
他們對國家進行排名,并將其劃分為四個部分:完全民主制,有缺陷的民主制,混合政權和專制政權。 這很重要,因為: 在威權主義體制下不能存在獨立的研究機構 。
If there are sensitive use cases, like identifying people complaining about the government on social media or expressing political preferences, then research in this area cannot be trusted. This happens very frequently. In my presentation at KDD last year I talk about how countries used the last COVID outbreak (SARS-CoV-1) as a cover to identify dissidents.
如果存在敏感的用例,例如在社交媒體上識別抱怨政府的人或表達政治偏愛,則該領域的研究將不可信。 這經常發生。 在去年在KDD上的演講中,我談到了國家如何利用上一次COVID爆發(SARS-CoV-1)作為掩蓋身份差異的標識。
A researcher working for an authoritarian regime is not independent of their government in the same way that a researcher at a public institution in a democracy is independent of their government. The researcher’s identity or nationality is not the problem: their employer or funder is the problem. Research that has human rights implications which is funded by authoritarian regimes should therefore be immediately rejected by the program chairs of machine learning conferences. Those researchers do not have the independence to prevent the negative use cases, no matter what their personal intentions are.
在專制政權下工作的研究人員并不像在民主國家的公共機構中的研究人員獨立于他們的政府那樣獨立于其政府。 研究人員的身份或國籍不是問題:他們的雇主或資助者是問題。 因此,由專制政權資助的具有人權影響的研究應立即被機器學習會議的計劃主席拒絕。 那些研究人員,無論他們的個人意圖是什么,都沒有獨立性來防止否定用例。
There are plenty of use cases that can help with disaster response and the most important ones do not require sensitive data: general research into low resource languages and information extraction from semi-structured documents. So, there is nothing stopping a researcher who was born into an authoritarian regime, or who choses to be employed by one, from contributing to disaster response machine learning research.
有很多用例可以幫助應對災難,最重要的用例不需要敏感數據:對低資源語言的常規研究以及從半結構化文檔中提取信息。 因此,沒有阻止一位專制政權或選擇受雇于獨裁政權的研究人員為災難響應機器學習研究做出貢獻的機會。
Note that countries high on democracy index can still commit human right’s abuses, so this does not give a free pass to research from those countries. EIU’s democracy index is heavily focused on country-internal factors. A good example of a grey area for any country is the military. The world’s militaries are also the largest disaster response organizations, so this makes for complicated evaluations that typically have to be investigated on a per-case basis.
請注意,民主指數高的國家仍會犯下侵犯人權的行為,因此這不能免費獲得這些國家的研究成果。 EIU的民主指數主要關注國家內部因素。 對于任何國家來說,灰色地區都是一個很好的例子。 世界上的軍事力量也是最大的災難響應組織,因此,這使得評估工作很復雜,通常需要根據具體情況進行調查。
Some cases are unequivocally positive. For example, in 2012 a small group of us (non-military disaster responders) took part in exercises hosted by the Naval Post Graduate School where we aimed to discover better ways to make damage assessments from aerial imagery following a disaster. We worked with Civil Air Patrol (part of the US Military) who fly over disasters to take images and FEMA (part of the Department of Homeland Security) who use damage assessments from those images to help with the response. Just a few months later we used our new techniques to help respond to Hurricane Sandy. There is little doubt that this was completely positive.
有些情況無疑是積極的。 例如,2012年我們中的一小部分人(非軍事災難響應者)參加了海軍研究生院舉辦的演習,我們的目的是發現更好的方法,以從災難后的航空影像進行損壞評估。 我們與民航巡邏隊(美國軍方的一部分)合作,后者飛越災難以拍攝圖像,而FEMA(國土安全部的一部分)與FEMA(使用這些圖像的損害評估來幫助做出響應)合作。 僅僅幾個月后, 我們就使用新技術來應對颶風桑迪 。 毫無疑問,這完全是積極的。
However, like I said in my after-action report for the earthquake in Haiti in 2010, there was an uneasy tension because many people in Haiti saw the US Military as former occupiers. In other cases, like working with UNICEF to support maternal health in West Africa, we chose not to work with any US government organization, because that would be perceived as lacking independence when helping other nations. So, regardless of the employer of the researchers, the ethics of government involvement need to be considered on a per case basis for every paper, especially when the disaster and responders are from multiple different nations.
但是,就像我在2010年海地地震的行動后報告中所說的那樣,緊張局勢令人不安,因為海地許多人都將美軍視為前占領者 。 在其他情況下, 例如與聯合國兒童基金會合作以支持西非的孕產婦健康 ,我們選擇不與任何美國政府組織合作,因為在幫助其他國家時,這被認為缺乏獨立性。 因此,無論研究人員的雇主如何,都需要針對每篇論文逐案考慮政府參與的道德規范,尤其是在災難和響應者來自多個不同國家的情況下。
7.不要與非行動援助組織合作 (7. Don’t partner with non-operational aid organizations)
Most international development organizations that will reach out to research institutions for help will not actually be doing disaster response work. To give a very high-level introduction to the aid industry, here’s a graphic showing how a lot of aid organization work in disaster response:
大多數國際發展組織將接觸到研究機構的幫助實際上不會做救災工作。 為了從總體上介紹援助行業,下面的圖形顯示了許多援助組織在災難響應中的工作方式:
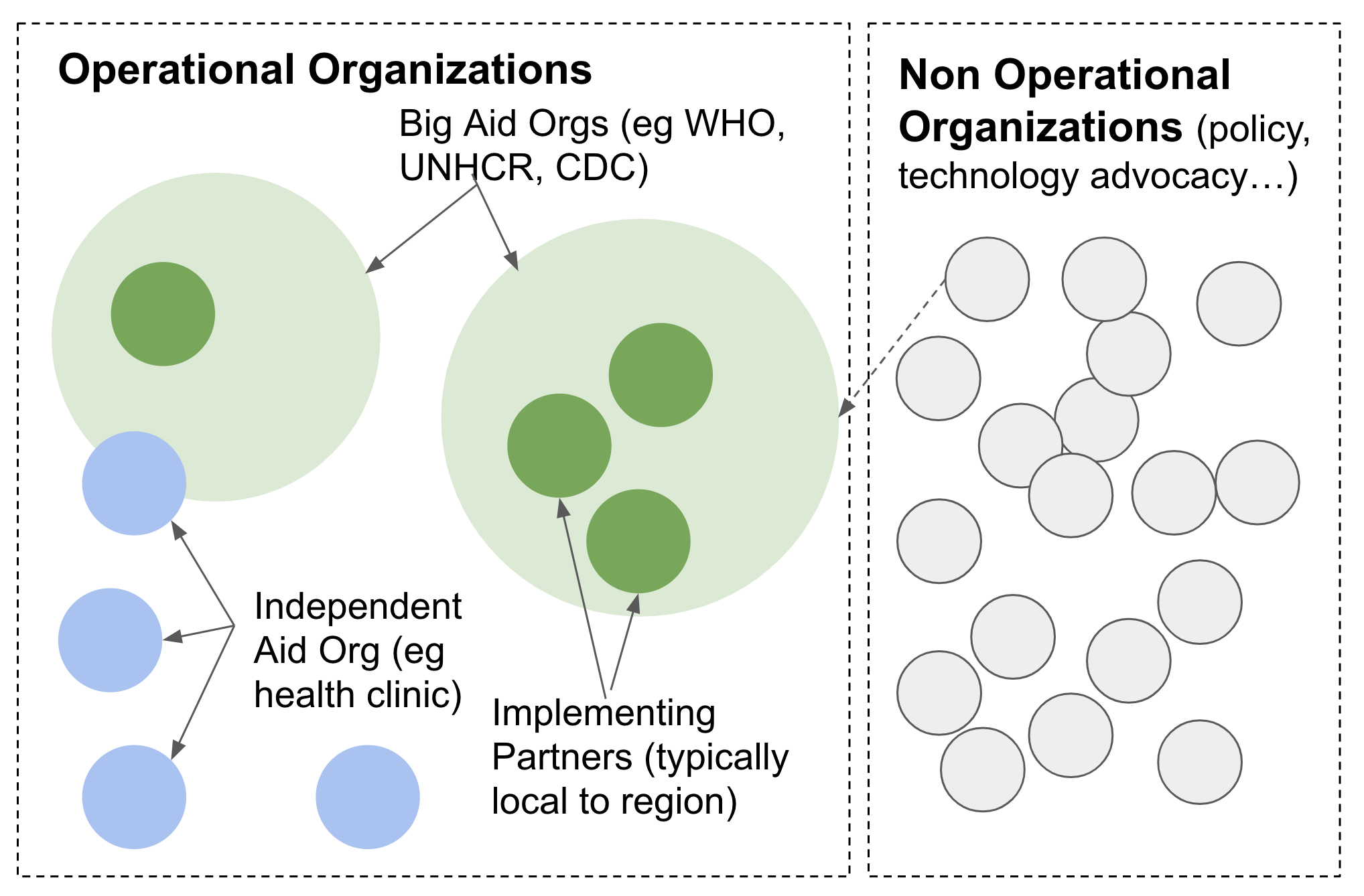
If someone is asking you to help, how do you know if they are actually responding? The best organization to help is one operating locally. Does your local hospital or food distribution center for refugees need help? Start with them.
如果有人要您提供幫助,您如何知道他們是否真的在響應? 最好的幫助組織是在本地運營的組織。 您當地的難民醫院或食物分配中心需要幫助嗎? 從他們開始。
The non-operational organizations are typically small and use disasters as funding and publicity opportunities. Look for them talking about “partnerships” with bigger organizations like the WHO, but nowhere saying that they are an “implementing partner”. This is typically code for “not actually part of the response”. If they reach out to you, chances are that you are the product and they are telling potential funders something like “look, we have researchers from a prominent university bringing innovation to disaster response.”
非運營組織通常規模較小,并利用災難作為資金和宣傳機會。 尋找他們談論與世界衛生組織等較大組織的“伙伴關系”,卻無處說他們是“實施伙伴”。 這通常是“實際上不是響應的一部分”的代碼。 如果他們伸出援手,您很有可能是您的產品,他們會告訴潛在的資助者諸如“看,我們有來自著名大學的研究人員,他們將創新應用于災難應對。”
The operational organizations like UNHCR, UNICEF, Red Cross, Doctors Without Borders all have their own technology innovation teams, so there is no need to partner with non-operational organizations. Non-operational organizations’ incentives are not aligned with privacy as they need publicity to continue to attract funding. For an example, see how a non-operational UN organization edited a video interview with me following an Ebola outbreak in Uganda in 2011: they edited my statement that more privacy was needed to instead say that we needed less privacy, so that they could access that data:
難民專員辦事處,兒童基金會,紅十字會,無國界醫生組織等業務組織都有自己的技術創新團隊,因此無需與非業務組織建立伙伴關系。 非運營組織的激勵機制與隱私不符,因為它們需要宣傳以繼續吸引資金。 例如,看看在2011年烏干達埃博拉疫情爆發后,一個非運作性的聯合國組織如何編輯了對我的視頻采訪:他們編輯了我的聲明,即需要更多的隱私,而不是說我們需要更少的隱私,以便他們可以訪問該數據:
If there are no operational aid agencies or implementing partners that need your help, then I recommend researching the fundamental building blocks of disaster response like supporting low-resource languages and information extraction from semi-structured documents.
如果沒有運營援助機構或執行合作伙伴需要您的幫助,那么我建議您研究災難響應的基本組成部分,例如支持低資源語言和從半結構化文檔中提取信息。
Just like countries with “Democratic” in their name tend not to be democracies, a similar rule-of-thumb applies to organizations with “Disaster” in their title. Operational organizations are named after the people they help or the service they are providing: Médecins Sans Frontières, World Health Organization, United Nations Children’s Fund, etc. If an organization has the words “Crisis”, “Disaster” or “Humanitarian” in its title, it probably doesn’t do disaster response: nobody wants to get aid from an organization who’s name reminds of them of their trauma and these organizations are named to maximize publicity and funding, not response.
就像名稱中帶有“民主”的國家往往不是民主國家一樣,類似的經驗法則也適用于名稱中帶有“災難”的組織。 運營組織的名稱以其提供幫助的人員或所提供的服務為依據: 無國界醫生,世界衛生組織,聯合國兒童基金會等。如果組織的名稱中包含“危機”,“災難”或“人道主義”字樣標題,它可能并沒有做出災難響應:沒有人希望從一個名稱使他們想起他們的創傷的組織那里獲得援助,而這些組織的名字是為了最大程度地宣傳和籌集資金,而不是響應。
8.英語社交媒體處理對救災人員沒有幫助 (8. English social media processing is not useful for disaster responders)
In NLP more broadly, we know that English-only results for our models rarely tell us how well other languages work. English-speaking countries tend to have the most well-funded disaster response organizations already, so this is one area where English’s irrelevance is amplified.
在更廣泛的NLP中,我們知道模型的僅英語結果很少能告訴我們其他語言的運行情況。 講英語的國家往往已經擁有資金最充足的救災組織,因此這是英語無關緊要的地區之一。
Best practice is to use social media as a broadcast medium for disaster response organizations to communicate to crisis-affect populations and that open social media should not be used as a direct communications channel for disaster-affected populations. This conclusion was reached in the disaster response community after incidents in Libya mentioned above, a response to floods in Pakistan in 2010 where publicly discussed aid camps were threatened by terrorists, and an analysis for the response to Haiti where it was found that despite many media articles praising social media, open social media was not a significant factor in the response.
最佳做法是使用社交媒體作為一種廣播媒介的救災組織溝通危機影響的人群和開放的社會化媒體不應該被用來作為受災人口的直接通信信道。 在上述利比亞事件,2010年針對巴基斯坦洪災的應對行動中得出的這一結論是在災難響應界做出的,巴基斯坦在該地的公開討論的援助營受到恐怖分子的威脅,并分析了對海地的應對措施,發現盡管有許多媒體,贊美社交媒體的文章,開放的社交媒體并不是回應的重要因素。
There is an intersectional problem with English and Authoritarian Regimes, too. Oppressive regimes frequently target intellectuals who are seen as political opponents. Speaking English often marks someone as being more educated and as someone speaking to international audiences. The inability to respond to a disaster makes a government look weak and this especially exposes an authoritarian leader who leads by projecting strength. For example, in 2013 when Typhoon Haiyan hit the Philippines, a small number of English-speaking people there who were critical of the response were seen as in danger of reprisals from the government. So, we decided it was unethical to ever release English-language social media data as part of disaster response datasets.
英文和威權政體也存在交叉問題。 壓迫政權經常針對被視為政治對手的知識分子。 說英語常常標志著一個人受過更高的教育,并且代表了一個與國際聽眾交談的人。 無能為力的災難使政府顯得軟弱無力,這尤其暴露了一個以投射力量為首的專制領導人。 例如,在2013年臺風“海鹽”襲擊菲律賓時,那里的少數說英語的人對該React持批評態度,被視為有遭到政府報復的危險。 因此,我們認為發布英語社交媒體數據作為災難響應數據集的一部分是不道德的。
My PhD showed how hard it is to adapt English social media communications to other domains in disasters, which was also summarized for the international development community in a paper coauthored by my PhD advisor, Christopher Manning. So, there is no excuse for ignoring this and conducting English-only research.
我的博士展示了使英語社交媒體交流適應災難中其他領域的艱辛,我的博士顧問克里斯托弗·曼寧(Christopher Manning)合著的一篇論文也為國際發展界總結了這一點 。 因此,沒有任何借口可以忽略這一點并進行僅英語的研究。
If the research is not for disaster responders, but aimed at supporting related professionals, then there is a stronger argument to be made. For example, there is interesting research in using machine learning to help mental-health professionals understand social reactions to disasters on online forums.
如果這項研究不是針對災難響應者的,而是旨在為相關專業人士提供支持的,那么就需要進行更強有力的論證。 例如,在使用機器學習來幫助心理健康專業人員在在線論壇上了解社會對災難的社會React方面,存在有趣的研究。
9.忽略任何依賴“ ISCRAM”的研究 (9. Ignore anything relying on research from “ISCRAM”)
Every scientific subfield has a venue where rejected papers get accepted by a pseudo-anonymized set of researchers accepting each other’s work. For machine learning work applied to disaster response, this is “Information Systems for Crisis Response and Management” (ISCRAM, pronounced “I-SCAM” by those of us who actually work in disaster response).
每個科學子領域都有一個場所,被拒絕的論文會被一組偽匿名的接受彼此工作的研究人員所接受。 對于應用于災難響應的機器學習工作,這就是“用于危機響應和管理的信息系統”(ISCRAM,在我們那些實際從事災難響應的人中被稱為“ I-SCAM”)。
In 2013 I wrote about “The Top NLP Conferences”, using disaster response research as an example:
2013年,我以災難響應研究為例,撰寫了“ The Top NLP Conferences”:
In that article I noted that ISCRAM publishes junk science articles that have been rejected by mainstream NLP conferences. Every paper I have published on actual disaster response efforts has been plagiarized a year or so later in ISCRAM as a “simulation” by an authoritarian regime’s paper-mill, as part of their attempts to whitewash their systems that are actually built for uses cases that violate human rights.
在那篇文章中,我指出ISCRAM發表了被主流NLP會議拒絕的垃圾科學文章。 我發表的每篇有關實際災難響應工作的論文都在一年左右的時間里被ISCRAM pla竊,作為專制政權的造紙廠的“模擬”,作為他們試圖粉刷其實際為用例構建的系統的一部分侵犯人權。
Papers that rely on ISCRAM-published research alone cannot be trusted and should not be accepted to mainstream scientific venues.
僅僅依靠ISCRAM發表的研究論文就不能令人信服,也不應被主流科學機構所接受。
10.評估影響時應用“無害”原則 (10. Apply the “Do No Harm” principle when evaluating impact)
The “Do No Harm” principle from medicine and disaster response circles should be applied to evaluating machine learning research. Organizations wouldn’t deploy a vaccine that killed 50% as many people as it saves, if the people killed wouldn’t have otherwise died. The same is true for most use cases with personal data, even if already public: are there use cases that can be used to harm people who would not otherwise be harmed?
醫學和災難響應界的“請勿傷害”原則應應用于評估機器學習研究。 如果被殺死的人不會因此喪生,組織將不會部署一種疫苗,該疫苗殺死的人數量應達到其挽救的50%。 對于大多數具有個人數據的用例,即使已經是公開的,也是如此: 是否存在可以用來傷害原本不會受到傷害的人的用例?
Machine learning researchers shouldn’t be making the case that there is a net benefit to their research, which they are probably not qualified to evaluate, in any case. If there is a clear negative use case from the research that would negatively impact people who would not otherwise be harmed, then that paper should be rejected on ethical grounds.
機器學習研究人員不應該證明自己的研究有凈收益 ,無論如何他們都沒有資格進行評估。 如果研究中有明確的消極用例會對其他方面不會受到傷害的人產生消極影響,則該論文應基于道德理由予以拒絕。
我應該如何開始研究機器學習以應對災難? (How should I get started on researching machine learning for disaster response?)
If you want to help in an ongoing disaster and you don’t have experience, remember that people will have the least time to train you during a disaster. Don’t be surprised if your most valuable skill is in data cleaning or other skills that won’t result in research papers. If you turned up to a hospital to help without any medical training, you shouldn’t complain if they put a mop and bucket in your hands. The same applies to disaster response. See my recent KDNuggets article for more information on how you can help and what to avoid: 5 Ways Data Scientists Can Help Respond to COVID-19 and 5 Actions to Avoid.
如果您想在正在進行的災難中提供幫助而又沒有經驗,請記住,人們在災難期間最沒有時間培訓您。 如果您最有價值的技能是數據清理或其他不會產生研究論文的技能,不要感到驚訝。 如果您未經任何醫學培訓就去醫院尋求幫助,則不要抱怨他們把手拖把拖了水桶。 災難響應也是如此。 請參閱我最近的KDNuggets文章,以獲取有關如何幫助和避免的更多信息: 數據科學家可以幫助應對COVID-19的5種方法和5種避免的行動 。
If you don’t have experience and want to work on something that can be published at a scientific venue, consider use cases like supporting low resource languages and information extraction from semi-structured text. These use cases can also help with other areas of impact, like healthcare and the environment. So, there is great potential impact with much less chance of inadvertently causing harm.
如果您沒有經驗并且想從事可以在科學場所發布的內容,請考慮使用案例,例如支持低資源語言和從半結構化文本中提取信息。 這些用例還可以幫助影響其他方面,例如醫療保健和環境。 因此,潛在的影響很大,而無意間造成傷害的機會則要少得多。
翻譯自: https://towardsdatascience.com/research-on-machine-learning-for-disaster-response-b65f3e97c018
泰坦尼克:機器從災難中學習
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/390725.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/390725.shtml 英文地址,請注明出處:http://en.pswp.cn/news/390725.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

github持續集成的設置_如何使用GitHub Actions和Puppeteer建立持續集成管道

shell與常用命令

C中的malloc:C中的動態內存分配

Linux文本編輯器


Streamlit —使用數據應用程序更好地測試模型
)
Spring MVC Boot Cloud 技術教程匯總(長期更新)

X Window系統

冒名頂替上大學羅彩霞_什么是冒名頂替綜合癥,您如何克服?

Linux命令----用戶管理

lasso回歸和嶺回歸_如何計劃新產品和服務機會的回歸


Linux 設備管理和進程管理
)
樂高ev3涉及到的一些賽事_使您成為英雄的前五名開發者技能(提示:涉及LEGO)

貝葉斯 定理_貝葉斯定理實際上是一個直觀的分數

winfrom 點擊按鈕button彈框顯示顏色集

JavaScript時間事件:setTimeout和setInterval

webservice 基本要點

