文本數據可視化
自然語言處理 (Natural Language Processing)
When we are working on any NLP project or competition, we spend most of our time on preprocessing the text such as removing digits, punctuations, stopwords, whitespaces, etc and sometimes visualization too. After experimenting TextHero on a couple of NLP datasets I found this library to be extremely useful for preprocessing and visualization. This will save us some time writing custom functions. Aren’t you excited!!? So let’s dive in.
在進行任何NLP項目或競賽時,我們將大部分時間用于預處理文本,例如刪除數字,標點符號,停用詞,空白等,有時還會進行可視化處理。 在幾個NLP數據集上試驗TextHero之后,我發現此庫對于預處理和可視化非常有用。 這將節省我們一些編寫自定義函數的時間。 你不興奮!!? 因此,讓我們開始吧。
We will apply techniques that we are going to learn in this article to Kaggle’s Spooky Author Identification dataset. You can find the dataset here. The complete code is given at the end of the article.
我們將把本文中要學習的技術應用于Kaggle的Spooky Author Identification數據集。 您可以在此處找到數據集。 完整的代碼在文章末尾給出。
Note: TextHero is still in beta. The library may undergo major changes. So some of the code snippets or functionalities below might get changed.
注意:TextHero仍處于測試版。 圖書館可能會發生重大變化。 因此,下面的某些代碼段或功能可能會更改。
安裝 (Installation)
pip install texthero前處理 (Preprocessing)
As the name itself says clean method is used to clean the text. By default, the clean method applies 7 default pipelines to the text.
顧名思義, clean方法用于清理文本。 默認情況下, clean方法將7個default pipelines應用于文本。
from texthero import preprocessing
df[‘clean_text’] = preprocessing.clean(df[‘text’])fillna(s)fillna(s)lowercase(s)lowercase(s)remove_digits()remove_digits()remove_punctuation()remove_punctuation()remove_diacritics()remove_diacritics()remove_stopwords()remove_stopwords()remove_whitespace()remove_whitespace()
We can confirm the default pipelines used with below code:
我們可以確認以下代碼使用的默認管道:

Apart from the above 7 default pipelines, TextHero provides many more pipelines that we can use. See the complete list here with descriptions. These are very useful as we deal with all these during text preprocessing.
除了上述7個默認管道之外, TextHero還提供了更多可以使用的管道。 請參閱此處的完整列表及其說明。 這些非常有用,因為我們在文本預處理期間會處理所有這些問題。
Based on our requirements, we can also have our custom pipelines as shown below. Here in this example, we are using two pipelines. However, we can use as many pipelines as we want.
根據我們的要求,我們還可以具有如下所示的自定義管道。 在此示例中,我們使用兩個管道。 但是,我們可以使用任意數量的管道。
from texthero import preprocessing custom_pipeline = [preprocessing.fillna, preprocessing.lowercase] df[‘clean_text’] = preprocessing.clean(df[‘text’], custom_pipeline)自然語言處理 (NLP)
As of now, this NLP functionality provides only named_entity and noun_phrases methods. See the sample code below. Since TextHero is still in beta, I believe, more functionalities will be added later.
到目前為止,此NLP功能僅提供named_entity和noun_phrases方法。 請參見下面的示例代碼。 由于TextHero仍處于測試階段,我相信以后會添加更多功能。
named entity
命名實體
s = pd.Series(“Narendra Damodardas Modi is an Indian politician serving as the 14th and current Prime Minister of India since 2014”)print(nlp.named_entities(s)[0])Output:
[('Narendra Damodardas Modi', 'PERSON', 0, 24),
('Indian', 'NORP', 31, 37),
('14th', 'ORDINAL', 64, 68),
('India', 'GPE', 99, 104),
('2014', 'DATE', 111, 115)]noun phrases
名詞短語
s = pd.Series(“Narendra Damodardas Modi is an Indian politician serving as the 14th and current Prime Minister of India since 2014”)print(nlp.noun_chunks(s)[0])Output:
[(‘Narendra Damodardas Modi’, ‘NP’, 0, 24),
(‘an Indian politician’, ‘NP’, 28, 48),
(‘the 14th and current Prime Minister’, ‘NP’, 60, 95),
(‘India’, ‘NP’, 99, 104)]表示 (Representation)
This functionality is used to map text data into vectors (Term Frequency, TF-IDF), for clustering (kmeans, dbscan, meanshift) and also for dimensionality reduction (PCA, t-SNE, NMF).
此功能用于將文本數據映射到vectors (術語頻率,TF-IDF), clustering (kmeans,dbscan,meanshift)以及降dimensionality reduction (PCA,t-SNE,NMF)。
Let’s look at an example with TF-TDF and PCA on the Spooky author identification train dataset.
讓我們看一下Spooky作者標識訓練數據集中的TF-TDF和PCA的示例。
train['pca'] = (
train['text']
.pipe(preprocessing.clean)
.pipe(representation.tfidf, max_features=1000)
.pipe(representation.pca)
)visualization.scatterplot(train, 'pca', color='author', title="Spooky Author identification")
可視化 (Visualization)
This functionality is used to plotting Scatter-plot, word cloud, and also used to get top n words from the text. Refer to the examples below.
此功能用于繪制Scatter-plot ,詞云,還用于從文本中獲取top n words 。 請參考以下示例。
Scatter-plot example
散點圖示例
train['tfidf'] = (
train['text']
.pipe(preprocessing.clean)
.pipe(representation.tfidf, max_features=1000)
)train['kmeans_labels'] = (
train['tfidf']
.pipe(representation.kmeans, n_clusters=3)
.astype(str)
)train['pca'] = train['tfidf'].pipe(representation.pca)visualization.scatterplot(train, 'pca', color='kmeans_labels', title="K-means Spooky author")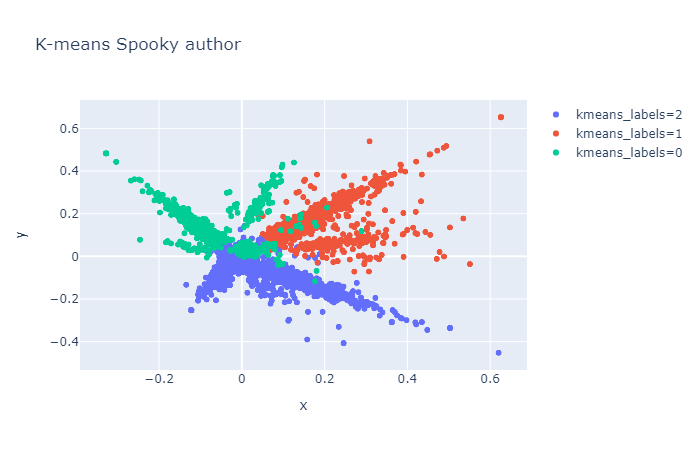
Wordcloud示例 (Wordcloud example)
from texthero import visualization
visualization.wordcloud(train[‘clean_text’])
熱門單詞示例 (Top words example)
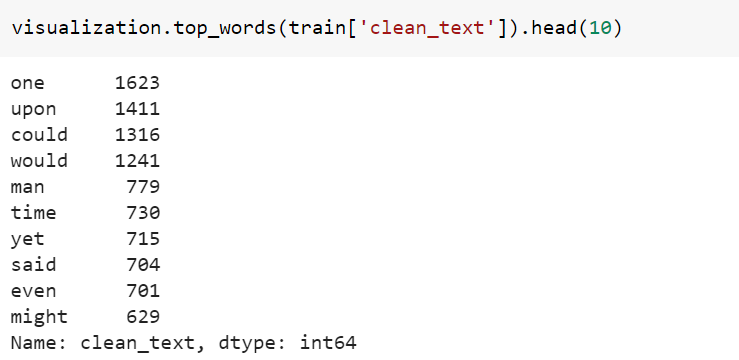
完整的代碼 (Complete Code)
結論 (Conclusion)
We have gone thru most of the functionalities provided by TextHero. Except for the NLP functionality, I found that rest of the features are really useful which we can try to use it for the next NLP project.
我們已經通過了TextHero提供的大多數功能。 除了NLP功能以外,我發現其余功能確實有用,我們可以嘗試將其用于下一個NLP項目。
Thank you so much for taking out time to read this article. You can reach me at https://www.linkedin.com/in/chetanambi/
非常感謝您抽出寶貴的時間閱讀本文。 您可以通過https://www.linkedin.com/in/chetanambi/與我聯系
翻譯自: https://medium.com/towards-artificial-intelligence/how-to-quickly-preprocess-and-visualize-text-data-with-texthero-c86957452824
文本數據可視化
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/390706.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/390706.shtml 英文地址,請注明出處:http://en.pswp.cn/news/390706.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章


漸進式web應用程序_如何在漸進式Web應用程序中添加到主屏幕

linux shell 編程
)
Leetcode之javascript解題(No33-34)

真實感人故事_您的數據可以告訴您真實故事嗎?

轉:防止跨站攻擊,安全過濾


html怎么注釋掉代碼_HTML注釋:如何注釋掉您HTML代碼

k均值算法 二分k均值算法_使用K均值對加勒比珊瑚礁進行分類

)
08_MySQL DQL_SQL99標準中的多表查詢(內連接)

java中抽象類繼承抽象類_Java中的抽象類用示例解釋


衡量試卷難度信度_我們可以通過數字來衡量語言難度嗎?

Linux 題目總結

《精通Spring4.X企業應用開發實戰》讀后感第二章

換了電腦如何使用hexo繼續寫博客

leetcode 525. 連續數組
每日任務記錄1)
實踐作業2:黑盒測試實踐(小組作業)每日任務記錄1
