邊緣計算 ai
介紹 (Introduction)
What is Edge (or Fog) Computing?
什么是邊緣(或霧)計算?
Gartner defines edge computing as: “a part of a distributed computing topology in which information processing is located close to the edge — where things and people produce or consume that information.”
Gartner將邊緣計算定義為:“分布式計算拓撲的一部分,其中信息處理位于邊緣附近-事物和人在此處生成或消費該信息。”
In other words, edge computing brings computation (and some data storage) closer to the devices where it’s data are being generated or consumed (especially in real-time), rather than relying on a cloud-based central system far away. With this approach, data does not suffer latency issues, reducing the amount of cost in transmission and processing. In a way, it is a kind of “return to the recent past,” where all the computational work was done locally on a desktop and not in the cloud.
換句話說,邊緣計算使計算(和一些數據存儲)更靠近要生成或使用其數據(特別是實時)的設備,而不是依賴于遙遠的基于云的中央系統。 使用這種方法,數據不會出現延遲問題,從而減少了傳輸和處理的成本。 從某種意義上說,這是一種“回到最近的過去”,其中所有計算工作都在桌面上而不是在云中本地完成。
Edge computing was developed due to the exponential growth of IoT devices connected to the internet for either receiving information from the cloud or delivering data back to the cloud. And many Internet of Things (IoT) devices generate enormous amounts of data during their operations.
邊緣計算的開發是由于連接到Internet的IoT設備呈指數級增長,以便從云中接收信息或將數據傳遞回云中。 許多物聯網(IoT)設備在其運行期間會生成大量數據。
Edge computing provides new possibilities in IoT applications, particularly for those relying on machine learning (ML) for tasks such as object and pose detection, image (and face) recognition, language processing, and obstacle avoidance. Image data is an excellent addition to IoT, but also a significant resource consumer (as power, memory, and processing). Image processing “at the Edge”, running classics AI/ML models, is a great leap!
邊緣計算為物聯網應用提供了新的可能性,尤其是對于那些依靠機器學習(ML)完成諸如對象和姿態檢測,圖像(和面部)識別,語言處理以及避障等任務的應用。 圖像數據是IoT的絕佳補充,同時也是重要的資源消耗者(如電源,內存和處理)。 運行經典AI / ML模型的“邊緣”圖像處理是一個巨大的飛躍!
Tensorflow Lite-機器學習(ML)處于邊緣!! (Tensorflow Lite - Machine Learning (ML) at the edge!!)
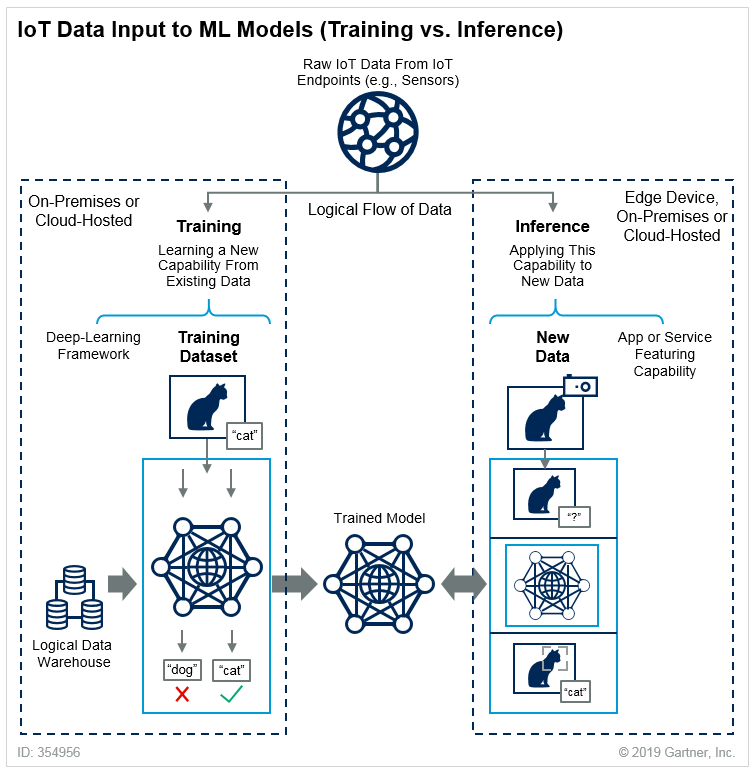
Machine Learning can be divided into two separated process: Training and Inference, as explained in Gartner Blog:
機器學習可以分為兩個獨立的過程:訓練和推理,如Gartner Blog中所述 :
Training: Training refers to the process of creating a machine learning algorithm. Training involves using a deep-learning framework (e.g., TensorFlow) and training dataset (see the left-hand side of the above figure). IoT data provides a source of training data that data scientists and engineers can use to train machine learning models for various cases, from failure detection to consumer intelligence.
培訓:培訓是指創建機器學習算法的過程。 培訓涉及使用深度學習框架(例如TensorFlow)和培訓數據集(請參見上圖的左側)。 物聯網數據提供了訓練數據的來源,數據科學家和工程師可以使用該數據來訓練從故障檢測到消費者智能的各種情況下的機器學習模型。
Inference: Inference refers to the process of using a trained machine-learning algorithm to make a prediction. IoT data can be used as the input to a trained machine learning model, enabling predictions that can guide decision logic on the device, at the edge gateway, or elsewhere in the IoT system (see the right-hand side of the above figure).
推論:推論是指使用經過訓練的機器學習算法進行預測的過程。 IoT數據可以用作訓練有素的機器學習模型的輸入,從而啟用可以指導設備,邊緣網關或IoT系統中其他位置的決策邏輯的預測(請參見上圖的右側)。
TensorFlow Lite is an open-source deep learning framework that enables on-device machine learning inference with low latency and small binary size. It is designed to make it easy to perform machine learning on devices, “at the edge” of the network, instead of sending data back and forth from a server.
TensorFlow Lite是一個開源深度學習框架,可實現低延遲和小二進制大小的設備上機器學習推理 。 它旨在簡化在“網絡邊緣”的設備上執行機器學習的過程,而不是從服務器來回發送數據。
Performing machine learning on-device can help to improve:
在設備上執行機器學習可以幫助改善:
Latency: there’s no round-trip to a server
延遲:服務器之間沒有往返
Privacy: no data needs to leave the device
隱私權:無需任何數據即可離開設備
Connectivity: an Internet connection isn’t required
連接性:不需要Internet連接
Power consumption: network connections are power-hungry
功耗:網絡連接耗電
TensorFlow Lite (TFLite) consists of two main components:
TensorFlow Lite(TFLite)包含兩個主要組件:
The TFLite converter, which converts TensorFlow models into an efficient form for use by the interpreter, and can introduce optimizations to improve binary size and performance.
TFLite轉換器將TensorFlow模型轉換為供解釋器使用的有效形式,并且可以引入優化以改善二進制大小和性能。
The TFLite interpreter runs with specially optimized models on many different hardware types, including mobile phones, embedded Linux devices, and microcontrollers.
TFLite解釋器在許多不同的硬件類型(包括移動電話,嵌入式Linux設備和微控制器)上以經過特殊優化的模型運行。

In summary, a trained and saved TensorFlow model (like model.h5) can be converted using TFLite Converter in a TFLite FlatBuffer (like model.tflite) that will be used by TF Lite Interpreter inside the Edge device (as a Raspberry Pi), to perform inference on a new data.
總之,可以在TFLite FlatBuffer(例如model.tflite )中使用TFLite Converter轉換經過訓練并保存的TensorFlow模型(例如model.h5 ),該工具將由Edge設備(作為Raspberry Pi)中的TF Lite Interpreter使用,對新數據進行推斷。
For example, I trained from scratch a simple CNN Image Classification model in my Mac (the “Server” on the above figure). The final model had 225,610 parameters to be trained, using as input the CIFAR10 dataset: 60,000 images (shape: 32, 32, 3). The trained model (cifar10_model.h5) had a size of 2.7Mb. Using the TFLite Converter, the model used on Raspberry Pi (model_cifar10.tflite) became with 905Kb (around 1/3 of original size). Making inference with both models (.h5 at Mac and .tflite at RPi) leaves the same results. Both notebooks can be found at GitHub.
例如,我從頭開始在Mac中訓練了一個簡單的CNN圖像分類模型(上圖為“服務器”)。 最終模型具有225,610個要訓練的參數,使用CIFAR10數據集作為輸入:60,000張圖像(形狀:32、32、3)。 經過訓練的模型( cifar10_model.h5 )的大小為2.7Mb。 使用TFLite Converter,在Raspberry Pi上使用的模型( model_cifar10.tflite )變為905Kb(約為原始大小的1/3)。 兩種模型(Mac上為.h5,RPi上為.tflite)進行推斷,結果相同。 這兩個筆記本都可以在GitHub上找到 。

Raspberry Pi — TFLite安裝 (Raspberry Pi — TFLite Installation)
It is also possible to train models from scratch at Raspberry Pi, and for that, the full TensorFlow package is needed. But once what we will do is only the inference part, we will install just the TensorFlow Lite interpreter.
還可以在Raspberry Pi上從頭開始訓練模型,為此,需要完整的TensorFlow軟件包。 但是一旦我們要做的只是推理部分,我們將僅安裝TensorFlow Lite解釋器。
The interpreter-only package is a fraction the size of the full TensorFlow package and includes the bare minimum code required to run inferences with TensorFlow Lite. It includes only the
tf.lite.InterpreterPython class, used to execute.tflitemodels.僅限解釋器的軟件包僅是完整TensorFlow軟件包的一小部分,并且包括使用TensorFlow Lite進行推理所需的最少代碼。 它僅包含用于執行
.tflite模型的tf.lite.InterpreterPython類。
Let’s open the terminal at Raspberry Pi and install the Python wheel needed for your specific system configuration. The options can be found on this link: Python Quickstart. For example, in my case, I am running Linux ARM32 (Raspbian Buster — Python 3.7), so the command line is:
讓我們在Raspberry Pi上打開終端并安裝特定系統配置所需的Python輪子 。 可在以下鏈接上找到這些選項: Python Quickstart 。 例如,以我為例,我正在運行Linux ARM32(Raspbian Buster-Python 3.7),因此命令行為:
$ sudo pip3 install https://dl.google.com/coral/python/tflite_runtime-2.1.0.post1-cp37-cp37m-linux_armv7l.whlIf you want to double-check what OS version you have in your Raspberry Pi, run the command:
如果要仔細檢查Raspberry Pi中的操作系統版本,請運行以下命令:
$ uname -As shown on image below, if you get …arm7l…, the operating system is a 32bits Linux.
如下圖所示,如果得到… arm7l… ,則操作系統是32位Linux。

Installing the Python wheel is the only requirement for having TFLite interpreter working in a Raspberry Pi. It is possible to double-check if the installation is OK, calling the TFLite interpreter at the terminal, as below. If no errors appear, we are good.
在Raspberry Pi中運行TFLite解釋器是安裝Python輪子的唯一要求。 如下所示,可以在終端上調用TFLite解釋器來仔細檢查安裝是否正常。 如果沒有錯誤出現,那就很好。

影像分類 (Image Classification)
介紹 (Introduction)
One of the more classic tasks of IA applied to Computer Vision (CV) is Image Classification. Starting on 2012, IA and Deep Learning (DL) changed forever, when a convolutional neural network (CNN) called AlexNet (in honor of its leading developer, Alex Krizhevsky), achieved a top-5 error of 15.3% in the ImageNet 2012 Challenge. According to The Economist, “Suddenly people started to pay attention (in DL), not just within the AI community but across the technology industry as a whole
IA應用于計算機視覺(CV)的最經典的任務之一是圖像分類。 從2012年開始,IA和深度學習(DL)發生了翻天覆地的變化,當時稱為AlexNet的卷積神經網絡 (CNN)(以其領先的開發人員Alex Krizhevsky表示敬意)在ImageNet 2012挑戰賽中獲得前5名錯誤,錯誤率達15.??3% 。 根據《經濟學人 》雜志的說法,“突然之間,人們開始關注(DL),不僅是在AI社區內部,而且是整個技術行業
This project, almost eight years after Alex Krizhevsk, a more modern architecture (MobileNet), was also pre-trained over millions of images, using the same dataset ImageNet, resulting in 1,000 different classes. This pre-trained and quantized model was so, converted in a .tflite and used here.
這個項目比Alex Krizhevsk(一種更現代的體系結構,即MobileNet )落后了將近八年,它使用相同的數據集ImageNet對數百萬張圖像進行了預訓練,產生了1,000個不同的類。 這樣就對這個經過預先訓練和量化的模型進行了轉換,將其轉換為.tflite并在此處使用。

First, let’s on Raspberry Pi move to a working directory (for example, Image_Recognition). Next, it is essential to create two subdirectories, one for models and another for images:
首先,讓我們在Raspberry Pi上移動到工作目錄(例如Image_Recognition )。 接下來,必須創建兩個子目錄,一個用于模型,另一個用于圖像:
$ mkdir images
$ mkdir modelsOnce inside the model’s directory, let’s download the pre-trained model (in this link, it is possible to download several different models). We will use a quantized Mobilenet V1 model, pre-trained with images of 224x224 pixels. The zip file that can be downloaded from TensorFlow Lite Image classification, using wget:
進入模型目錄后,讓我們下載預先訓練的模型(在此鏈接中 ,可以下載幾個不同的模型)。 我們將使用量化的Mobilenet V1模型,該模型預先訓練有224x224像素的圖像。 可以使用wget從TensorFlow Lite圖像分類下載的zip文件:
$ cd models
$ wget https://storage.googleapis.com/download.tensorflow.org/models/tflite/mobilenet_v1_1.0_224_quant_and_labels.zipNext, unzip the file:
接下來,解壓縮文件:
$ unzip mobilenet_v1_1.0_224_quant_and_labelsTwo files are downloaded:
已下載兩個文件:
mobilenet_v1_1.0_224_quant.tflite: TensorFlow-Lite transformed model
mobilenet_v1_1.0_224_quant.tflite :TensorFlow-Lite轉換模型
labels_mobilenet_quant_v1_224.txt: The ImageNet dataset 1,000 Classes Labels
labels_mobilenet_quant_v1_224.txt :ImageNet數據集1,000個類的標簽
Now, get some images (for example, .png, .jpg) and save them on the created images subdirectory.
現在,獲取一些圖像(例如,.png,.jpg)并將其保存在創建的圖像子目錄中。
On GitHub, it is possible to find the images used on this tutorial.
在GitHub上 ,可以找到本教程中使用的圖像。
Raspberry Pi OpenCV和Jupyter Notebook安裝 (Raspberry Pi OpenCV and Jupyter Notebook installation)
OpenCV (Open Source Computer Vision Library) is an open-source computer vision and machine learning software library. It is beneficial as a support when working with images. If very simple to install it on a Mac or PC is a little bit “trick” to do it on a Raspberry Pi, but I recommend to use it.
OpenCV(開源計算機視覺庫)是一個開源計算機視覺和機器學習軟件庫。 在處理圖像時作為支持很有用。 如果在Mac或PC上安裝它非常簡單,那么在Raspberry Pi上安裝它有點“技巧”,但是我建議您使用它。
Please follow this great tutorial from Q-Engineering to install OpenCV on your Raspberry Pi: Install OpenCV 4.4.0 on Raspberry Pi 4. Although written for the Raspberry Pi 4, the guide can also be used without any change for the Raspberry 3 or 2.
請按照Q-Engineering的出色教程在Raspberry Pi上安裝OpenCV:在Raspberry Pi 4上安裝OpenCV 4.4.0。盡管是為Raspberry Pi 4編寫的,但該指南也可用于Raspberry 3或2而無需做任何更改。 。
Next, Install Jupyter Notebook. It will be our development platform.
接下來,安裝Jupyter Notebook。 這將是我們的發展平臺。
$ sudo pip3 install jupyter
$ jupyter notebookAlso, during OpenCV installation, NumPy should have been installed, if not do it now, same with MatPlotLib.
另外,在OpenCV安裝過程中,應該立即安裝NumPy(如果現在不這樣做),與MatPlotLib相同。
$ sudo pip3 install numpy
$ sudo apt-get install python3-matplotlibAnd it is done! We have everything in place to start our AI journey to the Edge!
完成了! 我們擁有一切準備就緒,可以開始我們的AI邊緣之旅!
圖像分類推論 (Image Classification Inference)
Create a fresh Jupyter Notebook and follow bellow steps, or download the complete notebook from GitHub.
創建一個新的Jupyter Notebook,并按照以下步驟操作,或者從GitHub下載完整的筆記本。
Import Libraries:
導入庫:
import numpy as np
import matplotlib.pyplot as plt
import cv2
import tflite_runtime.interpreter as tfliteLoad TFLite model and allocate tensors:
加載TFLite模型并分配張量:
interpreter = tflite.Interpreter(model_path=’./models/mobilenet_v1_1.0_224_quant.tflite’)
interpreter.allocate_tensors()Get input and output tensors:
獲取輸入和輸出張量:
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()input details will give you the info needed about how the model should be feed with an image:
輸入詳細信息將為您提供有關應如何向模型中添加圖像的信息:

The shape of (1, 224x224x3), informs that an image with dimensions: (224x224x3) should be input one by one (Batch Dimension: 1). The dtype uint8, tells that the values are 8bits integers
形狀為(1,224x224x3)的圖像應尺寸為(224x224x3)的圖像一一輸入(批尺寸:1)。 dtype uint8告訴值是8位整數

The output details show that the inference will result in an array of 1,001 integer values (8 bits). Those values are the result of the image classification, where each value is the probability of that specific label be related to the image.
輸出詳細信息顯示,推斷將導致包含1,001個整數值(8位)的數組。 這些值是圖像分類的結果,其中每個值都是特定標簽與圖像相關的概率。
For example, suppose that we want to classify an image wich shape is (1220, 1200, 3). First, we will need to reshape it to (224, 224, 3) and add a batch dimension of 1, as defined on input details: (1, 224, 224, 3). The inference result will be an array with 1001 size, as shown below:
例如,假設我們要對形狀為(1220,1200,3)的圖像進行分類。 首先,我們將需要將其重塑為(224,224,3)并添加批處理尺寸1(根據輸入詳細信息定義:(1,2,224,224,3))。 推斷結果將是一個大小為1001的數組,如下所示:

The steps to code those operations are:
對這些操作進行編碼的步驟是:
- Input image and convert it to RGB (OpenCV reads an image as BGR): 輸入圖像并將其轉換為RGB(OpenCV將圖像讀取為BGR):
image_path = './images/cat_2.jpg'
image = cv2.imread(image_path)
img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)2. Pre-process the image, reshaping and adding batch dimension:
2.預處理圖像,重塑形狀并添加批次尺寸:
img = cv2.resize(img, (224, 224))
input_data = np.expand_dims(img, axis=0)3. Point the data to be used for testing and run the interpreter:
3.指向要用于測試的數據并運行解釋器:
interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()4. Obtain results and map them to the classes:
4.獲得結果并將其映射到類:
predictions = interpreter.get_tensor(output_details[0][‘index’])[0]
The output values (predictions) varies from 0 to 255 (max value of an 8bit integer). To obtain a prediction that will range from 0 to 1, the output value should be divided by 255. The array’s index, related to the highest value, is the most probable classification of such an image.
輸出值(預測值)從0到255(8位整數的最大值)變化。 要獲得范圍從0到1的預測,應將輸出值除以255。與最大值相關的數組索引是此類圖像最可能的分類。
Having the index, we must find to what class it appoint (such as car, cat, or dog). The text file downloaded with the model has a label associated with each index that goes from 0 to 1,000.
有了索引,我們必須找到它指定的類別(例如汽車,貓或狗)。 與模型一起下載的文本文件具有與每個索引相關聯的標簽,范圍從0到1,000。
Let’s first create a function to load the .txt file as a dictionary:
讓我們首先創建一個函數以將.txt文件加載為字典:
def load_labels(path):
with open(path, 'r') as f:
return {i: line.strip() for i, line in enumerate(f.readlines())}And create a dictionary named labels and inspecting some of them:
并創建一個名為標簽的字典并檢查其中的一些標簽 :
labels = load_labels('./models/labels_mobilenet_quant_v1_224.txt')
Returning to our example, let’s get the top 3 results (highest probabilities):
回到我們的示例,讓我們獲得前3個結果(最高概率):
top_k_indices = 3
top_k_indices = np.argsort(predictions)[::-1][:top_k_results]
We can see that the 3 top indices are related to cats. The prediction content is the probability associated with each one of the labels. As explained before, dividing by 255., we can get a value from 0 to 1. Let’s create a loop to go over the top results, printing label and probabilities:
我們可以看到3個頂級指數與貓有關。 預測內容是與每個標簽關聯的概率。 如前所述,除以255,我們可以得到一個0到1的值。讓我們創建一個循環以遍歷頂部結果,打印標簽和概率:
for i in range(top_k_results):
print("\t{:20}: {}%".format(
labels[top_k_indices[i]],
int((predictions[top_k_indices[i]] / 255.0) * 100)))
Let’s create a function, to perform inference on different images smoothly:
讓我們創建一個函數,以平滑地對不同的圖像進行推斷:
def image_classification(image_path, labels, top_k_results=3):
image = cv2.imread(image_path)
img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.imshow(img)img = cv2.resize(img, (w, h))
input_data = np.expand_dims(img, axis=0)interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()
predictions = interpreter.get_tensor(output_details[0]['index'])[0]top_k_indices = np.argsort(predictions)[::-1][:top_k_results]print("\n\t[PREDICTION] [Prob]\n")
for i in range(top_k_results):
print("\t{:20}: {}%".format(
labels[top_k_indices[i]],
int((predictions[top_k_indices[i]] / 255.0) * 100)))The figure below shows some tests using the function:
下圖顯示了使用該功能的一些測試:

The overall performance is astonishing! From the instant that you enter with the image path in the memory card, until the time that that result is printed out, all process took less than half a second, with high precision!
整體表現驚人! 從您輸入存儲卡中的圖像路徑的那一刻起,直到打印出該結果為止,所有過程都花費了不到半秒的時間,而且非常精確!
The function can be easily applied to frames on videos or live camera. The notebook for that and the complete code discussed in this section can be downloaded from GitHub.
該功能可輕松應用于視頻或實時攝像機上的幀。 可以從GitHub下載該筆記本以及本節中討論的完整代碼。
物體檢測 (Object Detection)
With Image Classification, we can detect what the dominant subject of such an image is. But what happens if several objects are dominant and of interest on the same image? To solve it, we can use an Object Detection model!
通過圖像分類,我們可以檢測出此類圖像的主要主題。 但是,如果幾個對象在同一圖像上占主導地位并且感興趣,會發生什么? 為了解決這個問題,我們可以使用對象檢測模型!
Given an image or a video stream, an object detection model can identify which of a known set of objects might be present and provide information about their positions within the image.
給定圖像或視頻流,對象檢測模型可以識別可能存在的一組已知對象,并提供有關它們在圖像中位置的信息。
For this task, we will download a Mobilenet V1 model pre-trained using the COCO (Common Objects in Context) dataset. This dataset has more than 200,000 labeled images, in 91 categories.
對于此任務,我們將下載使用COCO(上下文中的公共對象)數據集進行預訓練的Mobilenet V1模型。 該數據集有91個類別的200,000多張帶標簽的圖像。

下載型號和標簽 (Downloading model and labels)
On Raspberry terminal run the commands:
在Raspberry終端上,運行以下命令:
$ cd ./models
$ curl -O http://storage.googleapis.com/download.tensorflow.org/models/tflite/coco_ssd_mobilenet_v1_1.0_quant_2018_06_29.zip
$ unzip coco_ssd_mobilenet_v1_1.0_quant_2018_06_29.zip
$ curl -O https://dl.google.com/coral/canned_models/coco_labels.txt$ rm coco_ssd_mobilenet_v1_1.0_quant_2018_06_29.zip
$ rm labelmap.txtOn models subdirectory, we should end with 2 new files:
在models子目錄上,我們應該以2個新文件結尾:
coco_labels.txt
detect.tfliteThe steps to perform inference on a new image, are very similar to those done with Image Classification, except that:
對新圖像執行推理的步驟與“圖像分類”所執行的步驟非常相似,不同之處在于:
- input: image must have a shape of 300x300 pixels 輸入:圖片的形狀必須為300x300像素
- output: include not only label and probability (“score”), but also the relative window position (“ Bounding Box”) about where the object is located on the image. 輸出:不僅包括標簽和概率(“分數”),還包括有關對象在圖像上的位置的相對窗口位置(“邊界框”)。
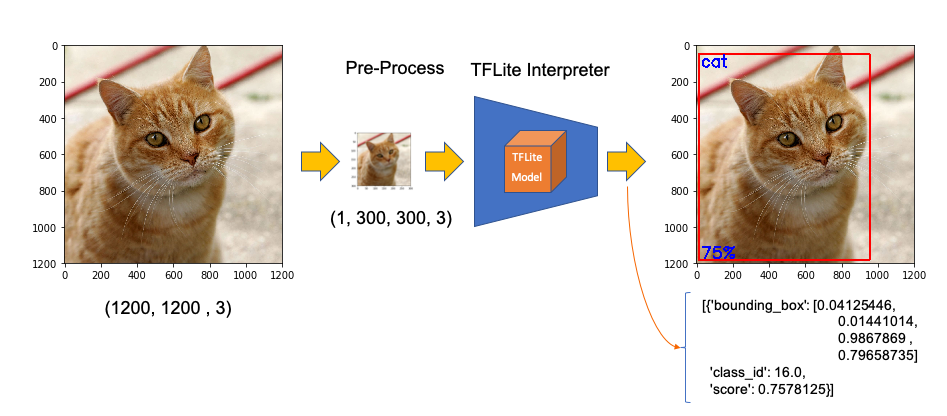
Now, we must load the labels and model, allocating tensors.
現在,我們必須加載標簽和模型,并分配張量。
labels = load_labels('./models/coco_labels.txt')
interpreter = Interpreter('./models/detect.tflite')
interpreter.allocate_tensors()The input pre-process is the same as we did before, but the output should be worked to get a more readable output. The functions below will help with that:
輸入的預處理與我們之前的相同,但是應該對輸出進行處理以獲得更易讀的輸出。 以下功能將幫助您:
def set_input_tensor(interpreter, image):
"""Sets the input tensor."""
tensor_index = interpreter.get_input_details()[0]['index']
input_tensor = interpreter.tensor(tensor_index)()[0]
input_tensor[:, :] = imagedef get_output_tensor(interpreter, index):
"""Returns the output tensor at the given index."""
output_details = interpreter.get_output_details()[index]
tensor = np.squeeze(interpreter.get_tensor(output_details['index']))
return tensorWith the help of the above functions, detect_objects() will return the inference results:
借助以上功能,detect_objects()將返回推斷結果:
- object label id 對象標簽ID
- score 得分
- the bounding box, that will show where the object is located. 邊界框,它將顯示對象的位置。
We have included a ‘threshold’ to avoid objects with a low probability of being correct. Usually, we should consider a score above 50%.
我們包含了一個“閾值”,以避免物體正確的可能性很小。 通常,我們應該考慮分數高于50%。
def detect_objects(interpreter, image, threshold):
set_input_tensor(interpreter, image)
interpreter.invoke()
# Get all output details
boxes = get_output_tensor(interpreter, 0)
classes = get_output_tensor(interpreter, 1)
scores = get_output_tensor(interpreter, 2)
count = int(get_output_tensor(interpreter, 3)) results = []
for i in range(count):
if scores[i] >= threshold:
result = {
'bounding_box': boxes[i],
'class_id': classes[i],
'score': scores[i]
}
results.append(result)
return resultsIf we apply the above function to a reshaped image (same as used on classification example), we should get:
如果將上述功能應用于重塑圖像(與分類示例相同),則應獲得:

Great! In less than 200ms with 77% probability, an object with id 16 was detected on an area delimited by a ‘bounding box’: (0.028011084, 0.020121813, 0.9886069, 0.802299). Those four numbers are respectively related to ymin, xmin, ymax and xmax.
大! 在不到200毫秒的時間內以77%的概率在由“邊界框”界定的區域上檢測到ID為16的對象:(0.028011084、0.020121813、0.9886069、0.802299)。 這四個數字分別與ymin,xmin,ymax和xmax有關。
Take into consideration that y goes from the top (ymin) to bottom (ymax) and x goes from left (xmin) to the right (xmax) as shown in figure below:
考慮到y從頂部(ymin)到底部(ymax),x從左側(xmin)到右側(xmax),如下圖所示:

Having the bounding box four values, we have, in fact, the coordinates of the top/left corner and the bottom/right one. With both edges and knowing the shape of the picture, it is possible to draw the rectangle around the object.
邊界框有四個值,實際上,我們有上/左角和下/右角的坐標。 有了兩條邊緣并知道圖片的形狀,就可以在對象周圍繪制矩形。
Next, we should find what class_id equal to 16 means. Opening the file coco_labels.txt, as a dictionary, each of its elements has an index associated, and inspecting index 16, we get as expected, ‘cat.’ The probability is the value returning from the score.
接下來,我們應該找到等于16的class_id。 打開文件coco_labels.txt作為字典,它的每個元素都有一個關聯的索引,并檢查索引16,我們得到的是預期的“貓”。 概率是從分數返回的值。
Let’s create a general function to detect multiple objects on a single picture. The first function, starting from an image path, will execute the inference, returning the resized image and the results (multiples ids, each one with its scores and bounding boxes:
讓我們創建一個常規功能來檢測單個圖片上的多個對象。 第一個函數從圖像路徑開始,將執行推理,返回調整大小的圖像和結果(多個id,每個id都有其得分和邊界框:
def detectObjImg_2(image_path, threshold = 0.51):img = cv2.imread(image_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
image = cv2.resize(img, (width, height),
fx=0.5,
fy=0.5,
interpolation=cv2.INTER_AREA)
results = detect_objects(interpreter, image, threshold)return img, resultsHaving the reshaped image, and inference results, the below function can be used to draw a rectangle around the objects, specifying for each one, its label and probability:
具有重塑的圖像和推斷結果后,以下功能可用于在對象周圍繪制一個矩形,并為每個對象指定其標簽和概率:
def detect_mult_object_picture(img, results): HEIGHT, WIDTH, _ = img.shape
aspect = WIDTH / HEIGHT
WIDTH = 640
HEIGHT = int(640 / aspect)
dim = (WIDTH, HEIGHT) img = cv2.resize(img, dim, interpolation=cv2.INTER_AREA) for i in range(len(results)):
id = int(results[i]['class_id'])
prob = int(round(results[i]['score'], 2) * 100)
ymin, xmin, ymax, xmax = results[i]['bounding_box']
xmin = int(xmin * WIDTH)
xmax = int(xmax * WIDTH)
ymin = int(ymin * HEIGHT)
ymax = int(ymax * HEIGHT) text = "{}: {}%".format(labels[id], prob) if ymin > 10: ytxt = ymin - 10
else: ytxt = ymin + 15 img = cv2.rectangle(img, (xmin, ymin), (xmax, ymax),
COLORS[id],
thickness=2)
img = cv2.putText(img, text, (xmin + 3, ytxt), FONT, 0.5, COLORS[id],
2) return imgBelow some results:
下面是一些結果:

The complete code can be found at GitHub.
完整的代碼可以在GitHub上找到 。
使用相機進行物體檢測 (Object Detection using Camera)

If you have a PiCam connected to Raspberry Pi, it is possible to capture a video and perform object recognition, frame by frame, using the same functions defined before. Please follow this tutorial if you do not have a working camera in your Pi: Getting started with the Camera Module.
如果您將PiCam連接到Raspberry Pi,則可以使用之前定義的相同功能來捕獲視頻并逐幀執行對象識別。 如果您的Pi中沒有可使用的相機,請按照本教程進行操作: 相機模塊入門 。
First, it is essential to define the size of the frame to be captured by the camera. We will use 640x480.
首先,必須定義相機要拍攝的畫面尺寸。 我們將使用640x480。
WIDTH = 640
HEIGHT = 480Next, you must iniciate the camera:
接下來,您必須啟動攝像頭:
cap = cv2.VideoCapture(0)
cap.set(3, WIDTH)
cap.set(4, HEIGHT)And run the below code in a loop. Until the key ‘q’ is pressed, the camera will capture the video, frame by frame, drawing the bounding box with its respective labels and probabilities.
并循環運行以下代碼。 在按下鍵“ q”之前,攝像機將逐幀捕獲視頻,并繪制帶有相應標簽和概率的邊界框。
while True: timer = cv2.getTickCount()
success, img = cap.read()
img = cv2.flip(img, 0)
img = cv2.flip(img, 1) fps = cv2.getTickFrequency() / (cv2.getTickCount() - timer)
cv2.putText(img, "FPS: " + str(int(fps)), (10, 470),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2) image = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (width, height),
fx=0.5,
fy=0.5,
interpolation=cv2.INTER_AREA)
start_time = time.time()
results = detect_objects(interpreter, image, 0.55)
elapsed_ms = (time.time() - start_time) * 1000 img = detect_mult_object_picture(img, results)
cv2.imshow("Image Recognition ==> Press [q] to Exit", img)if cv2.waitKey(1) & 0xFF == ord('q'):
breakcap.release()
cv2.destroyAllWindows()Below is possible to see the video running in real-time on the Raspberry Pi screen. Note that the video runs around 60 FPS (frames per second), which is pretty good!.
下面可以在Raspberry Pi屏幕上實時觀看視頻。 請注意,視頻的運行速度約為60 FPS(每秒幀數),非常好!
演示地址
Here one screen-shot of the above video:
以下是上述視頻的屏幕截圖:

The complete code is available on GitHub.
完整的代碼可在GitHub上獲得。
姿勢估計 (Pose Estimation)
One of the more exciting and critical areas of AI is to estimate a person’s real-time pose, enabling machines to understand what people are doing in images and videos. Pose estimation was deeply explored in my article Realtime Multiple Person 2D Pose Estimation using TensorFlow2.x, but here at the Edge, with a Raspberry Pi and with the help of TensorFlow Lite, it is possible to easily replicate almost the same that was done on a Mac.
AI的一個更令人激動和關鍵的領域之一是估計一個人的實時姿勢,使機器能夠了解人們在圖像和視頻中正在做什么。 在我的文章中使用TensorFlow2.x進行了實時多人2D姿勢估計,對姿勢估計進行了深入探討,但是在Edge上,借助Raspberry Pi和TensorFlow Lite的幫助,可以輕松地復制幾乎與以前相同的姿勢 Mac。
The model that we will use in this project is the PoseNet. We will do inference the same way done for Image Classification and Object Detection, where an image is fed through a pre-trained model. PoseNet comes with a few different versions of the model, corresponding to variances of MobileNet v1 architecture and ResNet50 architecture. In this project, the version pre-trained is the MobileNet V1, which is smaller, faster, but less accurate than ResNet. Also, there are separate models for single and multiple person pose detection. We will explore the model trained for a single person.
我們將在此項目中使用的模型是PoseNet 。 我們將以與圖像分類和對象檢測相同的方式進行推理,其中圖像通過預訓練的模型進行饋送。 PoseNet帶有一些模型的不同版本,對應于MobileNet v1架構和ResNet50架構的差異。 在此項目中,預培訓的版本是MobileNet V1,它比ResNet較小,更快,但準確性較低。 此外,還有用于單人和多人姿勢檢測的單獨模型。 我們將探索為一個人訓練的模型。
In this site is possible to explore in real time and using a live camera, several PoseNet models and configurations.
在此站點中,可以使用實時攝像機實時瀏覽多種PoseNet模型和配置。

The libraries to execute Pose Estimation on a Raspberry Pi are the same used before. NumPy, MatPlotLib, OpenCV and TensorFlow Lite Interpreter.
在Raspberry Pi上執行姿勢估計的庫與以前使用的庫相同。 NumPy,MatPlotLib,OpenCV和TensorFlow Lite解釋器。
The pre-trained model is the posenet_mobilenet_v1_100_257x257_multi_kpt_stripped.tflite, which can be downloaded from the above link or the TensorFlow Lite — Pose Estimation Overview website. The model should be saved in the models subdirectory.
預先訓練的模型是posenet_mobilenet_v1_100_257x257_multi_kpt_stripped.tflite ,可以從上面的鏈接或TensorFlow Lite- 姿勢估計概述網站下載 。 該模型應保存在models子目錄中。
Start loading TFLite model and allocating tensors:
開始加載TFLite模型并分配張量:
interpreter = tflite.Interpreter(model_path='./models/posenet_mobilenet_v1_100_257x257_multi_kpt_stripped.tflite')
interpreter.allocate_tensors()Get input and output tensors:
獲取輸入和輸出張量:
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()Same as we did before, looking into the input_details, it is possible to see that the image to be used to pose estimation should be (1, 257, 257, 3), which means that images must be reshaped to 257x257 pixels.
與我們之前所做的一樣,查看input_details,可以看到用于姿勢估計的圖像應為(1,257,257,3),這意味著必須將圖像重塑為257x257像素。
Let’s take as input a simple human figure, that will help us to analyze it:
讓我們以一個簡單的人物作為輸入,這將幫助我們對其進行分析:

The first step is to pre-process the image. This particular model was not quantized, which means that the dtype is float32. This information is essential to pre-process the input image, as shown with the below code
第一步是預處理圖像。 此特定模型未量化,這意味著dtype為float32。 此信息對于預處理輸入圖像至關重要,如以下代碼所示
image = cv2.resize(image, size)
input_data = np.expand_dims(image, axis=0)
input_data = input_data.astype(np.float32)
input_data = (np.float32(input_data) - 127.5) / 127.5Having the image pre-processed, now it is time to perform the inference, feeding the tensor with the image and invoking the interpreter:
對圖像進行預處理后,現在該執行推理了,向張量提供圖像并調用解釋器:
interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()An article that helps a lot to understand how to work with PoseNet is the Ivan Kunyakin tutorial’s Pose estimation and matching with TensorFlow lite. There Ivan comments that on the output vector, what matters to find the key points, are:
Ivan Kunyakin教程的Pose估計以及與TensorFlow lite的匹配,對幫助您理解如何使用PoseNet 很有幫助 。 Ivan評論說,在輸出向量上,找到關鍵點很重要:
Heatmaps 3D tensor of size (9,9,17), that corresponds to the probability of appearance of each one of the 17 keypoints (body joints) in the particular part of the image (9,9). It is used to locate the approximate position of the joint.
熱圖大小為(9,9,17)的3D張量,它對應于圖像的特定部分(9,9)中17個關鍵點(身體關節)中的每一個出現的概率。 用于定位關節的大致位置。
Offset Vectors: 3D tensor of size (9,9,34) that is called offset vectors. It is used for more exact calculation of the keypoint’s position. The First 17 of the third dimension correspond to the x coordinates and the second 17 of them to the y coordinates.
偏移向量:大小為(9,9,34)的3D張量,稱為偏移向量。 它用于更精確地計算關鍵點的位置。 三維的第一個17對應于x坐標,第二個17對應于y坐標。
output_details = interpreter.get_output_details()[0]
heatmaps = np.squeeze(interpreter.get_tensor(output_details['index']))output_details = interpreter.get_output_details()[1]
offsets = np.squeeze(interpreter.get_tensor(output_details['index']))Let’s create a function that will return an array with all 17 keypoints (or person's joints) based on heatmaps and offsets.
讓我們創建一個函數,該函數將根據熱圖和偏移量返回一個包含所有17個關鍵點(或人的關節)的數組。
def get_keypoints(heatmaps, offsets): joint_num = heatmaps.shape[-1]
pose_kps = np.zeros((joint_num, 2), np.uint32)
max_prob = np.zeros((joint_num, 1)) for i in range(joint_num):
joint_heatmap = heatmaps[:,:,i]
max_val_pos = np.squeeze(
np.argwhere(joint_heatmap == np.max(joint_heatmap)))
remap_pos = np.array(max_val_pos / 8 * 257, dtype=np.int32)
pose_kps[i, 0] = int(remap_pos[0] +
offsets[max_val_pos[0], max_val_pos[1], i])
pose_kps[i, 1] = int(remap_pos[1] +
offsets[max_val_pos[0], max_val_pos[1],
i + joint_num])
max_prob[i] = np.amax(joint_heatmap) return pose_kps, max_probUsing the above function with the heatmaps and offset vectors that were extracted from the output tensor, resultant of the image inference, we get:
使用上面的函數和從輸出張量提取的熱圖和偏移矢量,即圖像推斷的結果,我們得到:

The resultant array shows all 17 coordinates (y, x) regarding where the joints are located on an image of 257 x 257 pixels. Using the code below. It is possible to plot each one of the joints over the resized image. For reference, the array index is annotated, so it is easy to identify each joint:
所得數組顯示有關關節在257 x 257像素的圖像上的位置的所有17個坐標(y,x)。 使用下面的代碼。 可以在調整大小后的圖像上繪制每個關節。 作為參考,對數組索引進行了注釋,因此很容易識別每個關節:
y,x = zip(*keypts_array)
plt.figure(figsize=(10,10))
plt.axis([0, image.shape[1], 0, image.shape[0]])
plt.scatter(x,y, s=300, color='orange', alpha=0.6)
img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.imshow(img)
ax=plt.gca()
ax.set_ylim(ax.get_ylim()[::-1])
ax.xaxis.tick_top()
plt.grid();for i, txt in enumerate(keypts_array):
ax.annotate(i, (keypts_array[i][1]-3, keypts_array[i][0]+1))As a result, we get the picure:
結果,我們得到如下圖:

Great, now it is time to create a general function to draw “the bones”, which is the joints’ connection. The bones will be drawn as lines, which are the connections among keypoints 5 to 16, as shown in the above figure. Independent circles will be used for keypoints 0 to 4, related to head:
太好了,現在是時候創建繪制“骨骼”的通用功能了,這是關節的連接。 骨骼將繪制為線,即關鍵點5到16之間的連接,如上圖所示。 獨立的圓圈將用于與頭部相關的關鍵點0到4:
def join_point(img, kps, color='white', bone_size=1):
if color == 'blue' : color=(255, 0, 0)
elif color == 'green': color=(0, 255, 0)
elif color == 'red': color=(0, 0, 255)
elif color == 'white': color=(255, 255, 255)
else: color=(0, 0, 0) body_parts = [(5, 6), (5, 7), (6, 8), (7, 9), (8, 10), (11, 12), (5, 11),
(6, 12), (11, 13), (12, 14), (13, 15), (14, 16)] for part in body_parts:
cv2.line(img, (kps[part[0]][1], kps[part[0]][0]),
(kps[part[1]][1], kps[part[1]][0]),
color=color,
lineType=cv2.LINE_AA,
thickness=bone_size)
for i in range(0,len(kps)):
cv2.circle(img,(kps[i,1],kps[i,0]),2,(255,0,0),-1)Calling the function, we have the estimated pose of the body in the image:
調用該函數,我們可以在圖像中獲得人體的估計姿勢:
join_point(img, keypts_array, bone_size=2)
plt.figure(figsize=(10,10))
plt.imshow(img);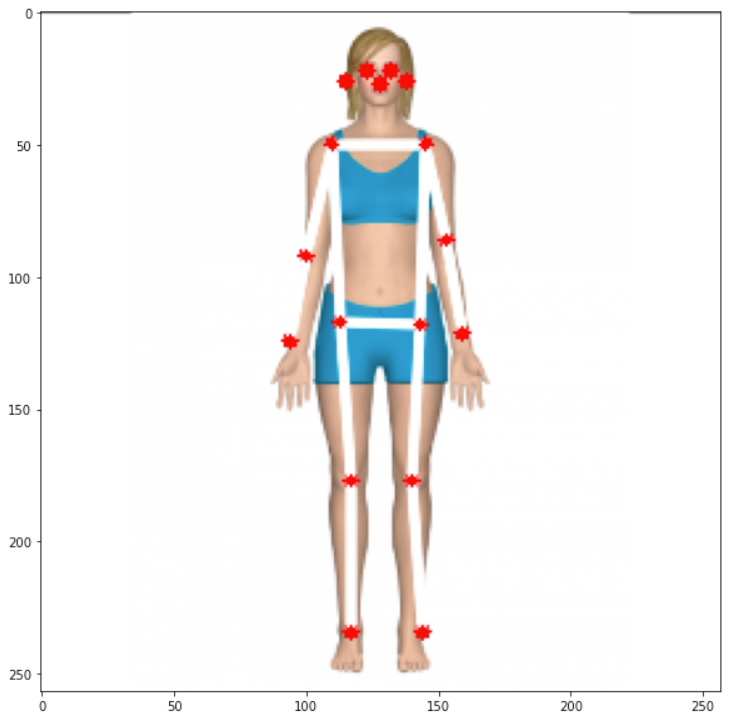
And last but not least, let’s create a general function to estimate posture having an image path as a start:
最后但并非最不重要的一點,我們創建一個通用函數來估計以圖像路徑作為起點的姿勢:
def plot_pose(img, keypts_array, joint_color='red', bone_color='blue', bone_size=1):
join_point(img, keypts_array, bone_color, bone_size)
y,x = zip(*keypts_array)
plt.figure(figsize=(10,10))
plt.axis([0, img.shape[1], 0, img.shape[0]])
plt.scatter(x,y, s=100, color=joint_color)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) plt.imshow(img)
ax=plt.gca()
ax.set_ylim(ax.get_ylim()[::-1])
ax.xaxis.tick_top()
plt.grid();
return img
def get_plot_pose(image_path, size, joint_color='red', bone_color='blue', bone_size=1):
image_original = cv2.imread(image_path)
image = cv2.resize(image_original, size)
input_data = np.expand_dims(image, axis=0)
input_data = input_data.astype(np.float32)
input_data = (np.float32(input_data) - 127.5) / 127.5 interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()
output_details = interpreter.get_output_details()[0]
heatmaps = np.squeeze(interpreter.get_tensor(output_details['index'])) output_details = interpreter.get_output_details()[1]
offsets = np.squeeze(interpreter.get_tensor(output_details['index'])) keypts_array, max_prob = get_keypoints(heatmaps,offsets)
orig_kps = get_original_pose_keypoints(image_original, keypts_array, size) img = plot_pose(image_original, orig_kps, joint_color, bone_color, bone_size)
return orig_kps, max_prob, imgAt this point with only one line of code, it is possible to detect pose on images:
此時,僅需一行代碼,就可以檢測圖像上的姿勢:
keypts_array, max_prob, img = get_plot_pose(image_path, size, bone_size=3)
All code developed on this section is available on GitHub.
在本節中開發的所有代碼都可以在GitHub上找到 。
Another easy step is to apply the function to frames from videos and live camera. I will leave it for you! ;-)
另一個簡單的步驟是將功能應用于視頻和實時攝像機的幀。 我會留給你的! ;-)
結論 (Conclusion)
TensorFlow Lite is a great framework to implement Artificial Intelligence (more precisely, ML) at the Edge. Here we explored ML models working on a Raspberry Pi, but TFLite is now more and more used at the "edge of the edge", on very small microcontrollers, in what has been called TinyML.
TensorFlow Lite是在Edge上實施人工智能(更準確地說是ML)的絕佳框架。 在這里,我們探索了在Raspberry Pi上運行的ML模型,但是現在TFLite越來越多地在稱為TinyML的非常小的微控制器上的“邊緣邊緣” 使用 。
As always, I hope this article can inspire others to find their way in the fantastic world of AI!
與往常一樣,我希望本文能夠激發其他人在夢幻般的AI世界中找到自己的路!
All the codes used in this article are available for download on project GitHub: TFLite_IA_at_the_Edge.
本文中使用的所有代碼都可以在GitHub項目TFLite_IA_at_the_Edge上下載。
Regards from the South of the World!
南方的問候!
See you in my next article!
下一篇再見!
Thank you
謝謝
Marcelo
馬塞洛

翻譯自: https://towardsdatascience.com/exploring-ia-at-the-edge-b30a550456db
邊緣計算 ai
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/390670.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/390670.shtml 英文地址,請注明出處:http://en.pswp.cn/news/390670.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

JavaScript中的全局變量介紹

初識spring-boot
)
leetcode 879. 盈利計劃(dp)

區塊鏈101:區塊鏈的應用和用例是什么?

java請求接口示例_用示例解釋Java接口

如何建立搜索引擎_如何建立搜尋引擎

用Docker自動構建紙殼CMS

Linux學習筆記15—RPM包的安裝OR源碼包的安裝

leetcode 518. 零錢兌換 II

軟件測試中什么是正交實驗法_軟件工程中的正交性
)
leetcode 279. 完全平方數(dp)

github代碼_GitHub啟動代碼空間


js將base64做UrlEncode轉碼

引用自己創建的css樣式表_如何使用CSS創建聯系表
)
leetcode 1449. 數位成本和為目標值的最大數字(dp)

風能matlab仿真_風能產量預測—深度學習項目
(轉))
android JNI調用(Android Studio 3.0.1)(轉)

安卓源碼 代號,標簽和內部版本號
