r軟件時間序列分析論文
數據科學 , 機器學習 (Data Science, Machine Learning)
In machine learning with time series, using features extracted from series is more powerful than simply treating a time series in a tabular form, with each date/timestamp in a separate column. Such features can capture the characteristics of series, such as trend and autocorrelations.
在具有時間序列的機器學習中,使用從序列中提取的特征比僅以表格形式處理時間序列(每個日期/時間戳在單獨的列中)更強大。 這些特征可以捕獲序列的特征,例如趨勢和自相關。
But… what sorts of features can you extract and how do you select among them?
但是……您可以提取哪些類型的特征,以及如何在其中進行選擇?
In this article, I discuss the findings of two papers that analyze feature-based representations of time series. The papers conduct comprehensive work to collect thousands of time series feature extractors and evaluate which features capture the most useful information from a series.
在本文中,我討論了兩篇分析基于特征的時間序列表示的論文的發現。 這些論文進行了全面的工作,以收集成千上萬個時間序列特征提取器,并評估哪些特征捕獲了序列中最有用的信息。
Highly comparative time-series analysis: the empirical structure of time series and their methods. (Fulcher, et al 2013)
高度比較的時間序列分析:時間序列的經驗結構及其方法 。 (Fulcher等,2013)
catch22: CAnonical Time-series CHaracteristics (Lubba, et al 2019)
catch22 :CAnonical時間序列特征 ( Lubba等,2019)
The papers show how to compare time series by extracting features that describe the series behavior and suggest a pipeline for identifying an “optimal” subset of time series features.
這些論文展示了如何通過提取描述序列行為的特征并建議用于識別時間序列特征的“最佳”子集的管道來比較時間序列。
為什么這很重要? (Why Is This Important?)
There are two basic ways to compare time series:
有兩種比較時間序列的基本方法:
A similarity measure that quantifies whether two-time series are close (on average) across time, such as Dynamic Time Warping. These measures are typically best for short, aligned series of equal length. They tend to have poor scalability, with quadratic computation in both the number of time series and series length because distances must be computed between all pairs.
一種用于量化兩個時間序列在整個時間上是否接近(平均)的相似性度量 ,例如Dynamic Time Warping 。 這些措施通常最適合短而對齊的等長序列。 它們往往具有較差的可伸縮性,因為在時間序列的數量和序列長度上都需要進行二次計算,因為必須在所有對之間計算距離。
Define similarity between series in terms of features extracted from time series using time series analysis algorithms. Feature extractors do not require series to be of equal length. The result is an interpretable summary of the dynamical characteristics of each series. These features can then be used for machine learning.
使用時間序列分析算法從時間序列提取的特征方面定義序列之間的相似性。 特征提取器不需要序列的長度相等。 結果是每個系列動力學特性的可解釋性總結。 這些功能可以用于機器學習。
Interpretability is another key: time series features can capture complex, time-varying patterns in a set of interpretable characteristics.
可解釋性是另一個關鍵:時間序列特征可以以一組可解釋的特征捕獲復雜的時變模式。
Problematically, there are a vast number of methods to extract interpretable features from time series. Further, feature selection is often done manually and subjectively.
有問題的是,有很多方法可以從時間序列中提取可解釋的特征。 此外,特征選擇通常是手動和主觀地完成的。
What sort of features can be extracted from series and how could you select among them?
可以從系列中提取什么樣的特征,如何從中選擇?
高度比較的時間序列分析:時間序列的經驗結構及其方法 (Highly comparative time-series analysis: the empirical structure of time series and their methods)
Paper motivation: although time series are studied across scientific disciplines (e.g. stock prices in finance, human heartbeats in medicine), different methods for time series analysis have been developed separately in different disciplines.
論文動機:盡管跨學科研究了時間序列(例如金融中的股票價格,醫學上的人的心跳),但在不同學科中分別開發了不同的時間序列分析方法 。
Given the great number of methods, it is difficult to determine how methods developed by different disciplines are related. As a result, how can a practitioner select the optimal method for their data?
鑒于方法眾多,因此很難確定不同學科開發的方法之間的關系。 結果,從業者如何為他們的數據選擇最佳方法?
To address this challenge, the HCTSA paper…
為了應對這一挑戰,HCTSA論文…
- Assembles an extensive annotated library of time series data and methods for time series analysis. 組裝了一個廣泛的帶注釋的時間序列數據庫和時間序列分析方法。
- Models time series methods according to their behavior on the data and group time series by their measured properties. 根據時間序列方法在數據上的行為對時間序列方法進行建模,并通過其測量屬性將時間序列分組。
- Introduces a range of comparative analysis techniques for series and their methods. First, the ability to link given time series to similar real-world and model-generated series. Second, the ability to link specific time series analysis methods to a range of alternatives across the literature. 介紹了一系列用于系列及其方法的比較分析技術。 首先,可以將給定的時間序列鏈接到類似的真實世界和模型生成的序列。 其次,將特定的時間序列分析方法鏈接到整個文獻中的其他方法的能力。
HCTSA框架和范圍 (HCTSA Framework and Scope)
The paper is scope extensive: the authors annotated a library of 38,190 univariate time series and 9,613 time series analysis algorithms.
本文涉及面很廣:作者注釋了38,190個單變量時間序列和9,613個時間序列分析算法的庫。
The time series analysis methods vary in form, ranging from summary statistics to statistical model fits. Each transformation summarizes an input series with a single real number.
時間序列分析方法的形式各不相同,從匯總統計信息到統計模型擬合不等。 每個轉換都會匯總一個具有單個實數的輸入序列。
The library of time series transformations cover a wide range of time series properties:
時間序列轉換庫涵蓋了廣泛的時間序列屬性:
- basic statistics of the distribution (e.g. location, spread, outlier properties) 分布的基本統計信息(例如位置,分布,離群值屬性)
- linear correlations (e.g. autocorrelations, features of the power spectrum) 線性相關(例如,自相關,功率譜的特征)
- stationarity (e.g. sliding window measures, unit root tests) 平穩性(例如,滑動窗口度量,單位根檢驗)
- information-theoretic and entropy measures (e.g. auto-mutual information, Approximate Entropy) 信息理論和熵測度(例如,自動互信息,近似熵)
- methods from the physical nonlinear time-series analysis literature (e.g. correlation dimension) 物理非線性時間序列分析文獻中的方法(例如,相關維)
- linear and nonlinear model fits (e.g. goodness of fit and parameters from autoregressive models) 線性和非線性模型擬合(例如擬合優度和自回歸模型的參數)
- others (e.g. wavelet methods) 其他(例如小波方法)
For transformations that require parameter values, the transformation is repeated for multiple parameters. A single “operation” is considered a transformation plus a single parameter value. Of the 9k operations evaluated in the paper, a single transformation might be counted multiple times, once for each parameter value. The paper evaluates approximately 1k unique transformations.
對于需要參數值的轉換,將對多個參數重復該轉換。 單個“操作”被視為轉換加上單個參數值。 在本文評估的9k運算中,單個轉換可能會被計數多次,每個參數值一次。 本文評估了大約1k個唯一轉換。
HCTSA:時間序列分析方法的經驗結構 (HCTSA: Empirical structure of time series analysis methods)
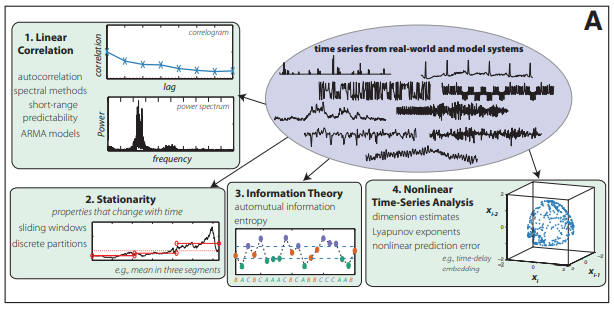
The authors used k-medoids clustering to identify four broad categories of time series analysis operations:
作者使用k-medoids聚類來識別時間序列分析操作的四大類:
- Linear correlation 線性相關
- Stationarity (Properties that change with time) 平穩性(隨時間變化的屬性)
- Information theory 信息論
- Nonlinear time series analysis 非線性時間序列分析
The clustering analysis revealed that a subset of 200 time series operations, or an empirical fingerprint of a series’ behavior, can approximate the 8,651 operations considered. The 200 operations summarize different behaviors of time series analysis methods. These operations include techniques developed in a variety of disciplines.
聚類分析表明,200個時間序列操作的子集或序列行為的經驗指紋可以近似考慮所考慮的8,651個操作。 這200個操作總結了時間序列分析方法的不同行為。 這些操作包括在各種學科中開發的技術。
Further, the analysis uncovered a local structure surrounding each target operation. For a given operation, they were able to identify alternative operations with similar behavior.
此外,分析發現了圍繞每個目標操作的局部結構。 對于給定的操作,他們能夠識別行為相似的替代操作。
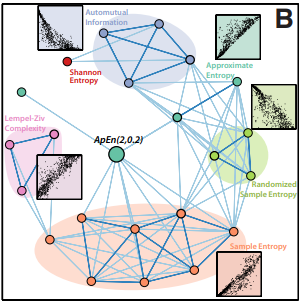
“By comparing their empirical behaviour, the techniques demonstrated above can be used to connect new methods to alternatives developed in other fields in a way that encourages interdisciplinary collaboration on the development of novel methods for time-series analysis that do not simply reproduce the behaviour of existing methods” [1]
“通過比較他們的經驗行為,上面展示的技術可以用于將新方法與其他領域開發的替代方法聯系起來,從而鼓勵跨學科合作,開發時間序列分析的新方法,而不僅僅是再現行為的行為。現有方法” [1]
HCTSA:時間序列的經驗結構 (HCTSA: Empirical structure of time series)
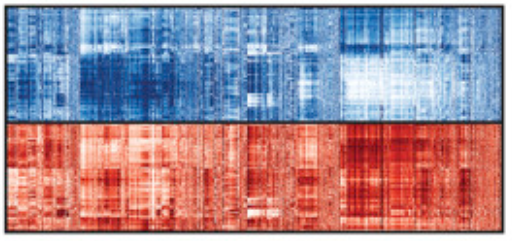
Time series can be represented by properties that capture important dynamical behavior of the series. The authors use 200 representative operations to compare 24,577 time series from different systems and of varying lengths.
時間序列可以由捕獲序列的重要動力學行為的屬性表示。 作者使用200個代表性操作來比較來自不同系統和不同長度的24,577個時間序列。
This empirical fingerprint of 200 diverse time-series analysis operations facilitates a meaningful comparison of scientific time series.
200種不同時間序列分析操作的經驗指紋有助于對科學時間序列進行有意義的比較。
To group their library of 24k time series, the authors used complete linkage clustering to form 2,000 clusters. Due to the wide range of time series properties used, the clusters grouped series according to dynamics, even when the lengths differ.
為了將他們的24k時間序列庫分組,作者使用了完整的鏈接聚類來形成2,000個聚類。 由于使用了廣泛的時間序列屬性,因此即使長度不同,聚類也會根據動力學將序列分組。
Most clusters grouped time series measured from the same system:
大多數群集將從同一系統測得的時間序列分組:
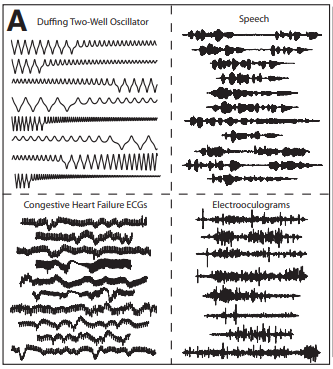
Some clusters contained series generated by different systems:
一些集群包含由不同系統生成的序列:
The reduced representation of time series allows you to retrieve a local neighborhood of series with similar properties. This allows you to automatically relate real-world time series to similar, model-generated time series.
時間序列的簡化表示使您可以檢索具有相似屬性的序列的局部鄰域。 這使您可以自動將現實世界的時間序列與模型生成的類似時間序列相關聯。
Thus, the transformations can be used to suggest suitable families of models for use in real-world systems.
因此,這些轉換可用于建議適用于實際系統的模型族。
HCTSA守則 (HCTSA Code)
The code for Highly Comparative Time Series Analysis can be found on GitHub; however, it is written in Matlab. (You can use the hctsa package from python using the pyopy package). The hctsa package allows thousands of features to be extracted from a time series. The software also has an accompanying paper.
可在GitHub上找到高度比較時間序列分析的代碼; 但是,它是用Matlab編寫的。 (您可以使用pyopy包從python使用pyopy包)。 hctsa包允許從一個時間序列中提取成千上萬個功能。 該軟件還附有論文 。
Of important note, it is slow to run. Reducing the full set of HCTSA operations to even 200 of the thousands of candidate features is computationally expensive. This approach is infeasible for some applications, especially those with large training data.
重要的是,它運行緩慢。 將全套HCTSA操作減少到數千個候選特征中的200個在計算上是昂貴的。 對于某些應用程序,尤其是具有大量訓練數據的應用程序,這種方法是不可行的。
HCTSA also has a web platform, CompEngine. CompEngine “is a self-organizing database of time-series data that allows users to upload, explore, and compare thousands of diverse types of time-series data.” [4]
HCTSA還具有一個Web平臺CompEngine 。 CompEngine“是一個時間序列數據的自組織數據庫,允許用戶上載,瀏覽和比較數千種不同類型的時間序列數據。” [4]

catch22,CAnonical時間序列特征 (catch22, CAnonical Time-series CHaracteristics)
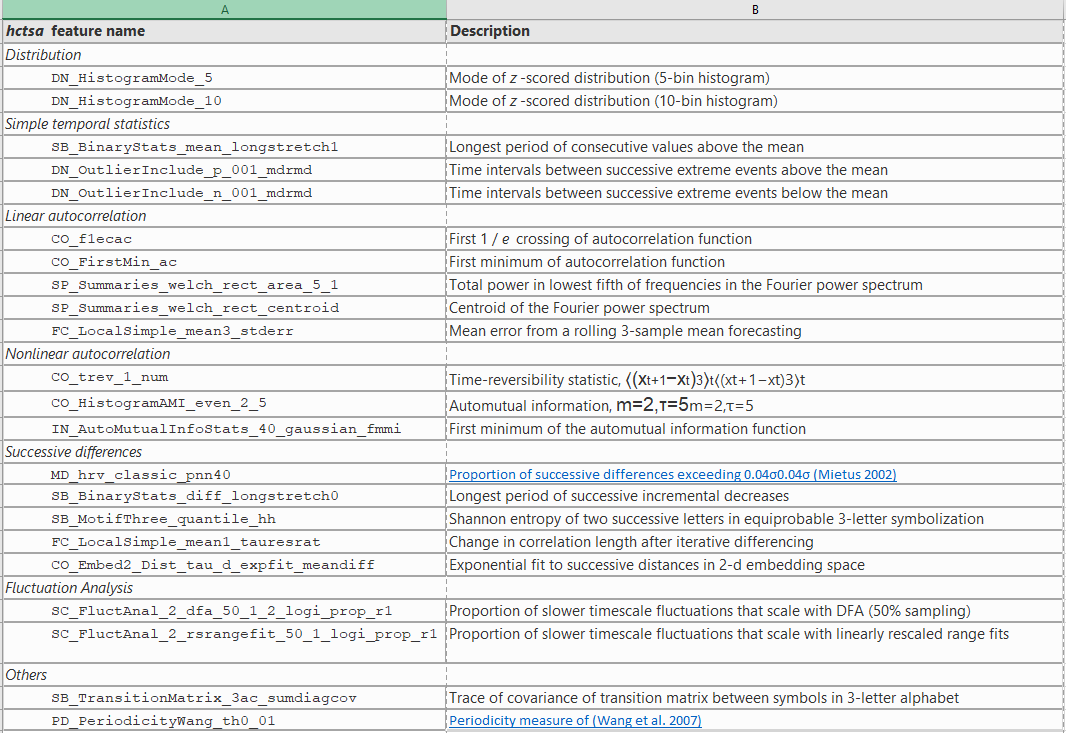
The subsequent catch22: CAnonical Time-series CHaracteristics paper (2019) builds on HCTSA by reducing the set of representative features to 22 time series features that:
隨后的內容22:CAnonical時間序列Characteristics論文(2019)建立在HCTSA的基礎上, 將代表性特征的集合減少到22個時間序列特征 ,這些特征包括:
- exhibit strong classification performance across a given collection of time-series problems, and 在給定的時間序列問題集合中表現出強大的分類性能,并且
- are minimally redundant, and 最少冗余,并且
- capture the diversity of analysis contained in HCTSA. 捕獲HCTSA中包含的分析多樣性。
The paper creates a data-driven subset of the most useful features extracted from a time series. The authors compare across a diverse set of time series analysis algorithms, starting with the features in the HCTSA toolbox.
本文創建了從時間序列中提取的最有用功能的數據驅動子集。 作者從HCTSA工具箱中的功能開始,對各種時間序列分析算法進行了比較。
The catch22 time series characteristics capture a diverse and interpretable time series “signature” based on their properties.
catch22時間序列特征基于其特性捕獲了多種且可解釋的時間序列“簽名”。
This signature includes linear and non-linear temporal auto-correlation, successive differences, value distributions and outliers, and fluctuation scaling properties.
該簽名包括線性和非線性時間自相關,連續差異,值分布和離群值以及波動比例屬性。
catch22功能的好處 (Benefits of catch22 features)
- Fast computation (~1000x faster than full HCTSA feature set in Matlab) 快速計算(比Matlab中完整的HCTSA功能集快1000倍)
- Provides low dimensional summary of time series 提供時間序列的低維摘要
- Interpretable characteristics that are useful for classification and clustering. 可解釋的特征,對分類和聚類很有用。
Further, if the catch22 features are not appropriate for your problem, the feature selection pipeline is general. The pipeline can be used to select informative subsets of features new or more complex problems.
此外,如果catch22功能不適合您的問題,則功能選擇管道很通用。 管道可用于選擇新的或更復雜問題的特征性信息子集。
Catch22功能評分 (Catch22 feature scoring)
The authors score features by evaluating decision tree classification accuracy across a set of 93 classification problems from the Time Series Classification Repository. Performance with 4791 features from HCTSA has 77.2% mean class-balanced accuracy across all tasks. Performance with smaller set of 22 features is 71.7% mean class-balanced accuracy.
作者通過評估時間序列分類庫中的93個分類問題的決策樹分類準確性來為特征評分。 HCTSA具有4791功能的性能在所有任務中具有77.2%的平均班級平衡準確性。 具有22個功能的較小集合的性能為71.7%的平均類平衡準確性。
Catch22功能選擇管道 (Catch22 feature selection pipeline)
For all data sets, each time series feature was linearly rescaled to unit 0–1 interval. This scaling may not be appropriate for some real-world applications.
對于所有數據集,每個時間序列特征均線性調整為單位0–1間隔。 這種縮放可能不適用于某些實際應用。
First, the authors excluded features sensitive to mean and variance of distribution of values because the majority of series were normalized.
首先,作者排除了對值的均值和方差敏感的特征,因為大多數序列都已歸一化。
For some applications, this preselection is not desirable. If working with non-normalized series, you should consider including the distributional features, such as mean and standard deviation. These can lead to significant performance gains.
對于某些應用,這種預選擇是不希望的。 如果使用非歸一化序列,則應考慮包括分布特征,例如均值和標準差。 這些可以導致顯著的性能提升。
Next, the authors excluded the transformations that frequently output special values. Special values indicate that an algorithm is not suitable for the input data, or that it did not evaluate successfully.
接下來,作者排除了經常輸出特殊值的轉換。 特殊值表示算法不適合輸入數據,或者評估失敗。
Last, the authors created a pipeline to filter for features that can individually discriminate across a range of real-world data. The pipeline then filtered for those that have complementary behavior.
最后,作者創建了一個管道,以篩選可分別區分一系列實際數據的功能。 然后,管道會篩選出具有互補行為的管道。
The feature selection pipeline had 3 rounds:
功能選擇管道進行了三輪:
- Statistical pre-filtering: filter out features whose performance were statistically insignificant on the given learning tasks. 統計預過濾:過濾掉在??給定學習任務中性能在統計上不重要的特征。
- Performance filtering: select features that perform best across all tests. “Performance” is the ability to distinguish between labeled classes in 93 classification tasks with a decision tree classifier. 性能過濾:選擇在所有測試中性能最好的功能。 “性能”是使用決策樹分類器區分93個分類任務中標記的類的能力。
- Redundancy minimization. The top features were clustered (hierarchical clustering with complete linkage) into groups according to performance scores across tasks. From each cluster, a single representative feature was selected for the feature set. The representative feature selected as the one with highest score across tasks — unless it was computationally intensive, in which case another high-accuracy feature with greater interpretability and efficiency was manually selected. 冗余最小化。 根據任務之間的性能得分,將主要功能(通過完全鏈接的層次化群集)進行分組。 從每個群集中,為功能集選擇一個代表性功能。 代表性特征被選為在所有任務中得分最高的特征-除非計算量大,否則將手動選擇另一種具有更高可解釋性和效率的高精度特征。
準確性/可解釋性的權衡 (Accuracy / Interpretability Trade-off)
The authors compared classification performance using the catch22 features with a wide variety of time series classification algorithms, such as those implemented in sktime.
作者將使用catch22功能的分類性能與各種時間序列分類算法(例如在sktime實現的算法)進行了sktime 。
The classification of time series with catch22 features, despite large dimensionality reduction, results in “similar” performance to alternative methods. The authors admit that majority of datasets exhibit better performance using existing algorithms than catch22.
盡管具有較大的降維效果,但具有catch22特征的時間序列分類卻導致與替代方法“相似”的性能。 作者承認, 使用現有算法 , 大多數數據集表現出比catch22更好的性能。
The paper often claims that catch22 only has a “small’ reduction in accuracy. (The authors did not publish the performance of classifiers with catch22 features). In one instance, they called a decrease from 99.2% to 89.5% “small”, but in my opinion, this is not small for many applications.
該論文經常聲稱catch22的準確性僅“小”降低。 (作者未發布具有catch22功能的分類器的性能)。 在一種情況下,他們稱從99.2%降低到89.5%是“小”,但在我看來,這對于許多應用程序來說并不小。
While the authors failed to prove, in my view, that a classification model built with the catch22 features could outperform a native time series classifier, catch22 does offer interpretable features for model explanation.
在我看來,盡管作者未能證明使用catch22特征構建的分類模型可以勝過本機時間序列分類器, 但是catch22確實提供了可解釋的特征用于模型解釋 。
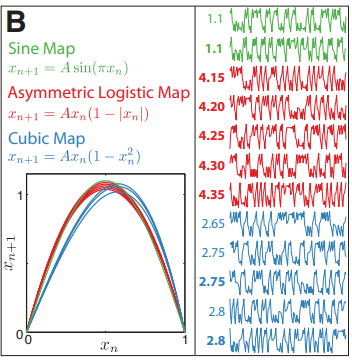
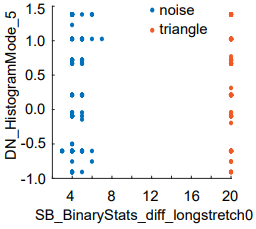
In particular, the authors highlighted one classifier where a single feature was able to perfectly separate two classes (series = triangle or noise). The feature “quantifies the length of the longest continued descending increments in the data”. Clearly, this is simple to explain.
尤其是,作者強調了一個分類器,其中一個功能可以完美地將兩個分類(序列=三角形或噪聲)分開。 該功能“量化數據中最長的連續下降增量的長度”。 顯然,這很容易解釋。
備用時間序列功能集 (Alternative Time Series Feature Sets)
The authors noted that “There is no single representation that is best for all time-series datasets.” Instead, “the optimal representation depends on the structure of the dataset and the questions being asked of it.” [3]
作者們指出:“沒有一種最適合所有時間序列數據集的表示形式。” 相反,“最佳表示形式取決于數據集的結構和所要提出的問題。” [3]
Thus, the catch22 features may not be the optimal features for all time series datasets and tasks.
因此,catch22特征可能不是所有時間序列數據集和任務的最佳特征。
The catch22 feature representation often outperforms datasets that do not have “reliable shape differences between classes” relative to classifiers based on time-domain distance metrics.
catch22特征表示相對于基于時域距離度量的分類器,其性能通常優于沒有“可靠的類間形狀差異”的數據集。
The authors compared performance of catch22 features to the time series features available in the tsfeatures R package. On the same set of classification tasks, tsfeatures features had a 69.4% mean accuracy, compared to catch22’s 71.7% accuracy.
作者將catch22功能的性能與tsfeatures R軟件包中可用的時間序列功能進行了tsfeatures 。 在同一組分類任務中, tsfeatures特征的平均準確度為69.4%,而catch22的平均準確度為71.7%。
實作 (Implementation)
Extraction of the catch22 features has been implemented in C, with wrappers in Python, R, Matlab. An open-source implementation of catch22 can be found on GitHub.
catch22功能的提取已在C中實現,并在Python,R,Matlab中使用了包裝器。 catch22的開源實現可以在GitHub上找到 。
The C version of catch22 exhibits near-linear computational complexity, O(N1.16) for time series length. For a time series with 10,000 observations, the catch22 can be computed in 0.5 seconds.
catch22的C版本顯示時間序列長度的近似線性計算復雜度O(N1.16)。 對于具有10,000個觀測值的時間序列,可以在0.5秒內計算catch22。
The code for the feature selection pipeline that produced the 22 features is available on GitHub at https://github.com/chlubba/op_importance.
GitHub上的https://github.com/chlubba/op_importance上提供了用于生成22個功能的功能選擇管道的代碼。
適用于實際問題 (Application to real problems)
A wide range of features can be extracted from time series that describe the many properties and dynamics of a series.
可以從時間序列中提取各種各樣的特征,這些特征描述了序列的許多特性和動力學。
The features analyzed in the HCTSA paper and are available on GitHub are comprehensive and informative. The key challenge is that there are “too many” features for most applications.
HCTSA論文中分析的功能以及可以在GitHub上獲得的功能都是全面且信息豐富的。 關鍵的挑戰是大多數應用程序的功能太多。
The catch22 features are tailored to capture key properties of the UCR/UEA datasets, which are short and phase aligned. The feature selection method could be rerun to generate reduced feature sets tailored to other applications.
catch22的功能經過定制,可以捕獲UCR / UEA數據集的關鍵屬性,這些屬性很短且相位對齊。 可以重新運行功能選擇方法以生成適合其他應用程序的精簡功能集。
Indeed, new feature selection may be necessary in many applications where the series have different properties, such as those where location and variance of a data distribution are highly relevant. Distributional features were excluded from the catch22 analysis because the data considered were normalized. (Normalization removes location and shift).
確實,在一系列具有不同屬性的應用程序中,例如在數據分布的位置和方差高度相關的那些應用程序中,可能需要新的特征選擇。 catch22分析排除了分布特征,因為考慮的數據已標準化。 (歸一化刪除位置和移位)。
最后的話 (A Final Word)
If you enjoyed this article, please follow me for more content about time series machine learning. Articles on time series classification and a taxonomy of time series features are in the works.
如果您喜歡本文,請關注我以獲取有關時間序列機器學習的更多內容。 有關時間序列分類和時間序列特征分類的文章正在撰寫中。
翻譯自: https://medium.com/towards-artificial-intelligence/highly-comparative-time-series-analysis-a-paper-review-5b51d14a291c
r軟件時間序列分析論文
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/390577.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/390577.shtml 英文地址,請注明出處:http://en.pswp.cn/news/390577.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

leetcode 168. Excel表列名稱


解決Mac10.13 Pod報錯 -bash: /usr/local/bin/pod: /System/Library/Frameworks/Ruby.fram

angular示例_用示例解釋Angular動畫

selenium抓取_使用Selenium的網絡抓取電子商務網站

劍指 Offer 37. 序列化二叉樹

ie8 ajaxSubmit 上傳文件提示下載

一個簡單的 js 時間對象創建

裁判打分_內在的裁判偏見

數據庫sql課程設計_SQL和數據庫-初學者完整課程

LCP 07. 傳遞信息

微信公眾號自動回復加超鏈接最新可用實現方案

devops開發模式流程圖_2020 Web開發人員路線圖–成為前端,后端或DevOps開發人員的視覺指南

從Jupyter Notebook切換到腳本的5個理由

leetcode 1833. 雪糕的最大數量

MVC架構 -- 初學試水選課管理系統

rest api 示例2_REST API教程– REST Client,REST Service和API調用通過代碼示例進行了解釋

win10子系統linux編譯ffmpeg

ip登錄打印機怎么打印_不要打印,登錄。
