在ES的倒排索引機制中有四個重要的名詞:Term、Term Dictionary、Term Index、Posting List。
-
Term(詞條):詞條是索引里面最小的存儲和查詢單元。一段文本經過分析器分析以后就會輸出一串詞條。一般來說英文語境中詞條是一個單詞,中文語境中一個詞條是分詞后的一個詞組。
此處涉及到分詞器,分詞器的作用是將一段文字分解為若干個詞組,不同的分詞器使用的分詞算法不同,得到的分詞結果也不同。
-
Term Dictionary(詞典):詞典是詞條的集合,顧名思義,詞典中維護的是Term。詞典一般是由文本集合中出現過的所有詞條所組成的集合。
-
Term Index(詞條索引):由于詞典中維護著文本中所有的詞條,為了在其中更快的找到某個詞條,我們為詞條建立索引。通過壓縮算法,詞條索引的大小只有所有詞條的幾十分之一,因此詞條索引可以存儲在內存中,因此可以提供更快的查找速度。
-
Posting List(倒排表):倒排表記錄的是詞條出現在哪些文檔里,以及出現的位置和頻率等信息。倒排表中的每條記錄稱為一個倒排項(posting)。
將以上概念類比到詞典中,Term相當于詞典中的詞語,Term Dictionary相當于詞典本身,Term Index相當于詞典的目錄。
舉個栗子,假設現在我們輸入系統多段文本,經過分詞器分詞后得到以下詞條:
- elastic
- flink
- hadoop
- kafka
- spark
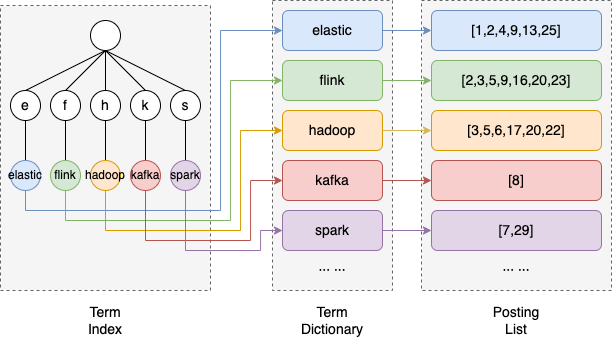
我們使用ES進行全文搜索時,如圖所示,系統首先會通過Term Index找到該Term在Term Dictionary中的位置,再通過倒排索引結構找到對應的Posting,從而定位到該詞組在文本中的位置,完成一次搜索。
?



)
【綠城杯2021】babyvxworks(淺談花指令))

—— nn.Linear)
全局的bean懶加載是怎么實現的?)











