背景
目前clickhouse社區對于數據的寫入主要基于文件本地表、分布式表方式為主,但缺乏大批量快速寫入場景下的數據寫入方式,本文提供了一種基于clickhouse local 客戶端工具分布式處理hdfs數據表文件,并將clickhouse以文件復制的方式完成寫入clickhouse的方法。該方案通過spark程序實現,經測試:
(1)在相同資源下,與傳統的寫clickhouse基于http/tcp的方式,可提供3倍左右的性能。
(2)傳統數據寫過程中,clickhouse-server需要處理寫入的數據,寫性能主要受clickhouse集群網絡、cpu、內存限制,無法通過擴展寫入客戶端端并發來提高寫入性能,本方案將數據處理端放在了插入客戶端,寫入性能理論上可以線性擴展提升。
方案
傳統基于http/tcp寫方案
目前clickhouse 官方推介3種數據寫入方式
- official JDBC driver
- ClickHouse-Native-JDBC
- clickhouse4j
jdbc主要基于如下形式進行:
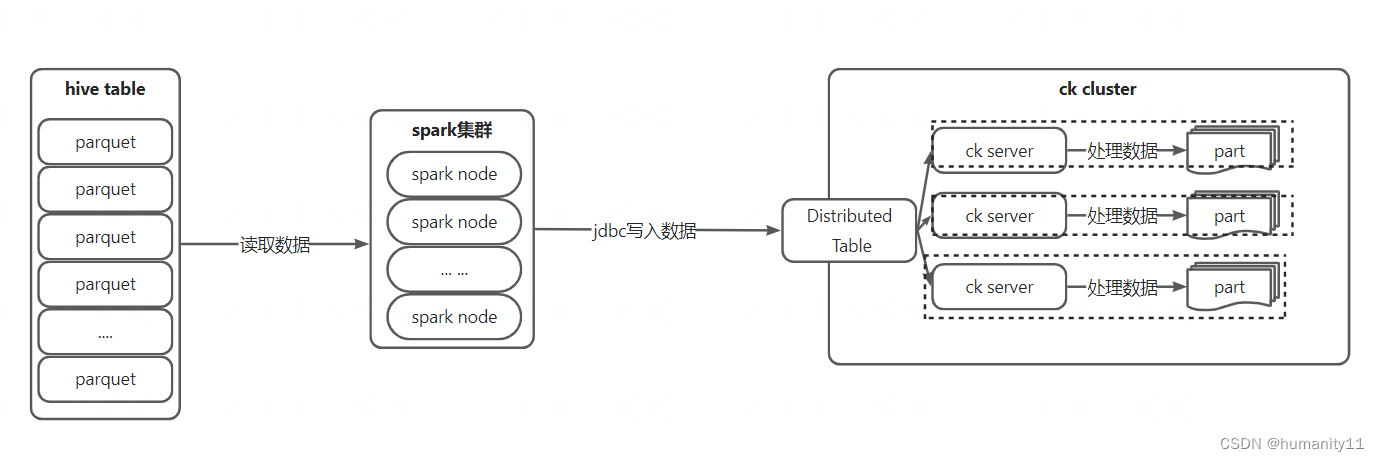
?基于jdbc寫入的基本流程是spark集群(分布式計算引擎)讀取hdfs文件,轉換為dataframe后通過調用clickhouse jdbc方式,將數據寫入至clickhouse服務端,clickhouse服務端完成本批次數據的生成。
clickhouse server端具體生成文件的流程為:
(1)ck集群分布式表接收到spark發送的寫請求后,會更加分片鍵進行數據劃分,對于數據屬于本地分片分片的數據,直接寫入本地表。對于數據屬于其他分片的數據會先寫入至臨時目錄下。
(2)對于clickhouse集群,數據的讀寫DDL都是依賴于zookeeper進行的,會將操作的日志寫入至zk的/log下,并形成相應的task
(3)當數據寫入本地表后,會將操作日志寫入zk /log中,集群其他ck節點監聽到/log變化后,會觸發相應的ck節點拉去log操作并轉換成task放入自身對應節點下的/queue中,其他節點將開始拉去該分片數據,并寫入自身本地表中,同時對于分片副本原理類似。
(4)完成本次數據的拉取復制后,將移除/queue中對應的task,完成本次數據的寫入。
從上面的流程中我們知道,數據的寫入都是先將數據寫入至分片表的本地然后復制至其他集群節點實現的,因此,clickhouse的分片表所在的機器常常負載比較大;數據的同步依賴zk進行的,zk壓力也較大。
基于文件復制寫方式
為了解決上述批量數據數據寫入場景下的問題,社區提出了一種新的思路,即使用clickhouse local將先將數據處理成clickhouse 文件,完成后直接復制至clickhouse集群,這樣大大減輕了clickhouse集群處理數據的壓力,同時數據寫入性能理論上可以與客戶端并發寫入線性增長。當前大多數公司使用clickhouse分析的數據不會在原始數據集上進行,常常是數倉加工后的明細數據,通常流程是原始數據集導入至數倉,輸出加工處理,處理后的數據導出至clickhouse用于OLAP分析。本文針對這樣的場景,提供了一種直接讀取數倉加工生成的parquet等文件,使用spark、clickhouse-local分布式處理ck文件格式,并導入至clickhouse中,具體如下圖所示:
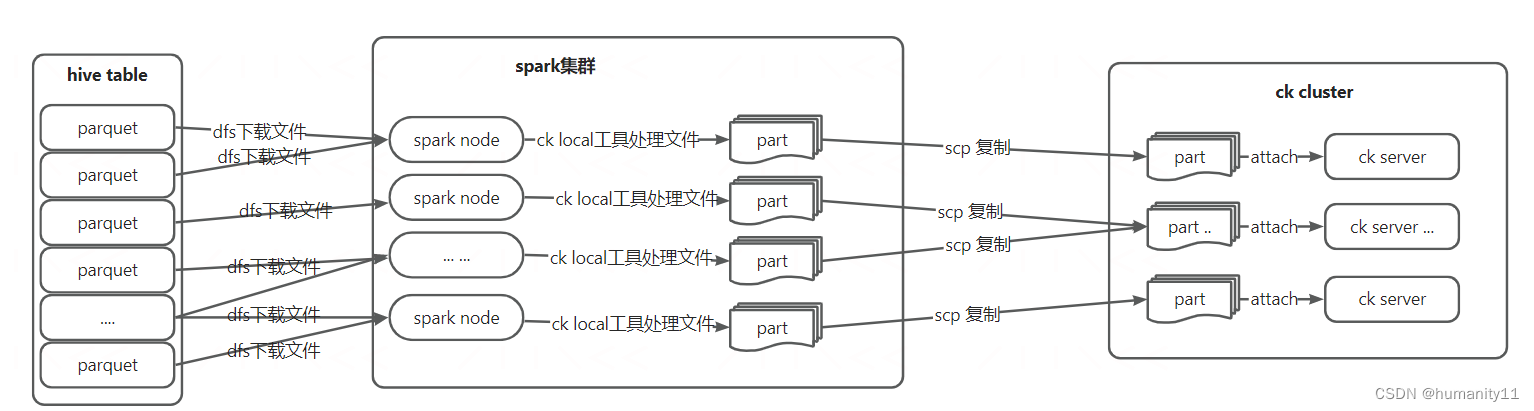
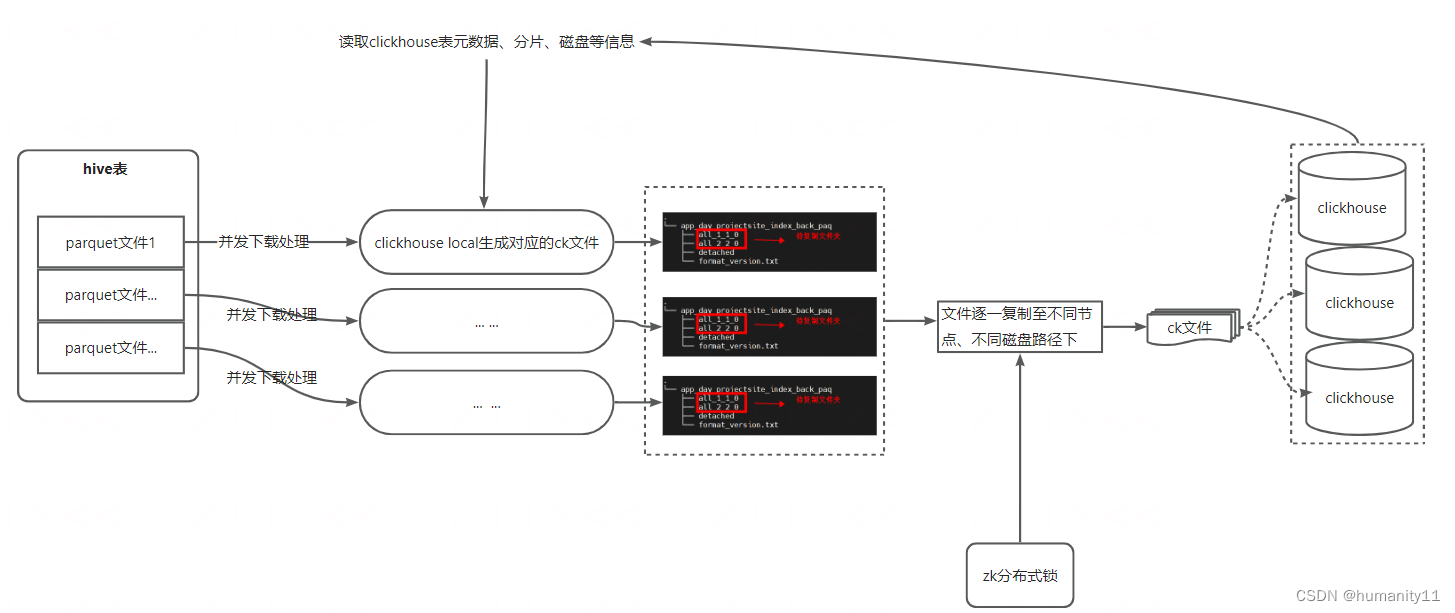
?其中,spark集群中的spark node并不會讀寫hive表數據,而只是依賴spark分布程序將hive表所在hdfs上的文件分布式的方式下載至yarn node本地機器,然后調用本地機上的clickhouse local 命名,將不同文件格式的文件(parquet\orc\text\csv等)生成為clickhouse 文件塊,最后通過直接通過ssh命令的方式將加工處理好的cickhouse數據復制clickhouse集群,并調用clickhouse attach part命令將數據塊merge至表中,期間clickhouse表數據的所有處理動作執行端放在了spark node中進行,ck集群只負責數據的接收,大大提高了數據批量寫入性能,sparknode具體處理過程如下圖所示:
?
性能測試
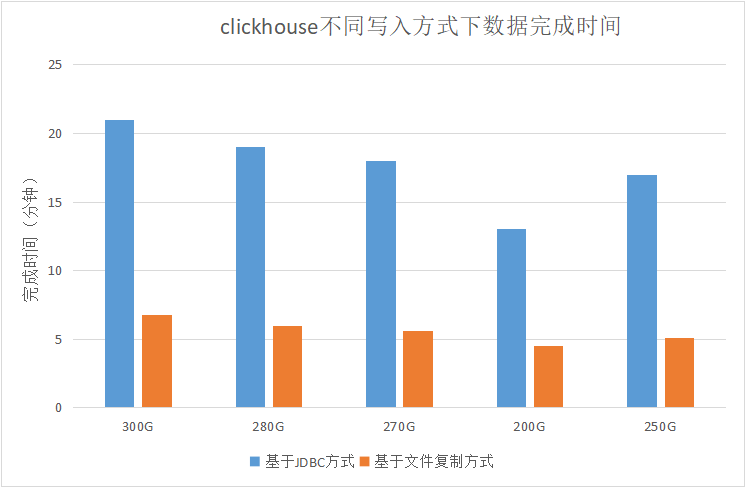
經測試,在相同spark資源情況下,基于文件復制寫入clickhouse的方式比jdbc方式寫入性能有2~3倍的性能提升,且理論上文件復制方式寫入可以伴隨spark node增加而線性增長,在parquet格式的數據表上,不同寫入方式下clickhouse完成時間對比結果如下圖所示:














)




