機器學習解決什么問題
According to Water.org and Lifewater International, out of 57 million people in Tanzania, 25 million do not have access to safe water. Women and children must travel each day multiple times to gather water when the safety of that water source is not even guaranteed. In 2004, 12% of all deaths in Tanzania were due to water-borne illnesses.
根據Water.org和Lifewater International的數據 ,坦桑尼亞的5700萬人中,有2500萬人無法獲得安全的水。 婦女和兒童必須每天多次旅行以收集水,甚至不能保證該水源的安全。 2004年,坦桑尼亞所有死亡中有12%是由于水傳播疾病造成的。
Despite years of effort and large amounts of funding to resolve the water crisis in Tanzania, the problem remains. The ability to predict the condition of water points in Tanzania using collectible data will allow us to build plans to efficiently utilize resources to develop a sustainable infrastructure that will affect many lives.
盡管為解決坦桑尼亞的水危機付出了多年的努力和大量資金,但問題仍然存在。 利用可收集的數據預測坦桑尼亞水位狀況的能力將使我們能夠制定計劃,以有效利用資源來開發將影響許多生命的可持續基礎設施。
數據 (Data)
As an initiative to resolve this issue, DrivenData started an exploration-based competition using data from the Tanzania Ministry of Water gathered by Taarifa, an open-source platform. The goal of the project is to predict the status of each water point in three different classes: functional, not functional and needs repair.
為了解決這個問題, DrivenData使用開放源代碼平臺Taarifa收集的坦桑尼亞水利部的數據,開始了基于勘探的競賽。 該項目的目標是預測三個不同類別中每個供水點的狀態:功能性,非功能性和需要維修。
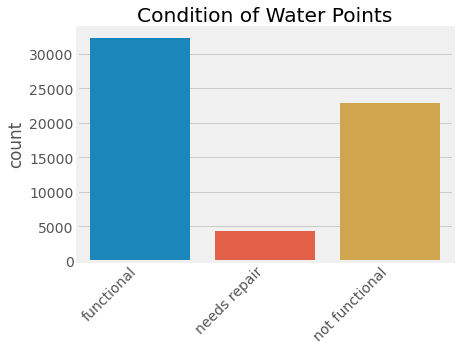
Our dataset showed that 62% of the 59,400 water points were functional while 38% were not. Out of these functional water points, 12% of them needed repairs.
我們的數據集顯示,在59,400個供水點中,有62%可以正常工作,而38%則沒有。 在這些功能性供水點中,有12%需要維修。
探索性數據分析 (Exploratory Data Analysis)
After cleaning the data and dealing with missing values and abnormalities, we’ve looked at how individual features may relate to the condition of water points. Here are a few observations from our exploratory data analysis.
清理數據并處理缺失值和異常之后,我們研究了各個特征如何與水位狀況相關。 以下是我們探索性數據分析的一些觀察結果。
不維護較舊的水位 (Older Water Points Are Not Maintained)
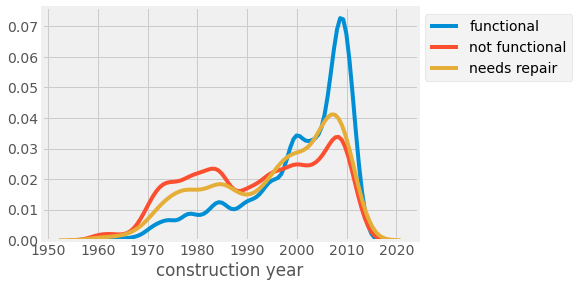
Here is the distribution of water points across different years of construction. We can see that most water points that are functional were built recently, which is perhaps due to the large funding that has gone in recent years. But the fact that even the ones that were built recently are as likely to be not functional as older ones is quite alarming.
這是不同施工年份的水位分布。 我們可以看到,大多數具有功能的供水點都是在最近建造的,這可能是由于近年來已投入大量資金。 但是,即使是最近制造的設備也無法像舊設備一樣運行,這一事實令人震驚。
付款事宜。 (Payment Matters.)
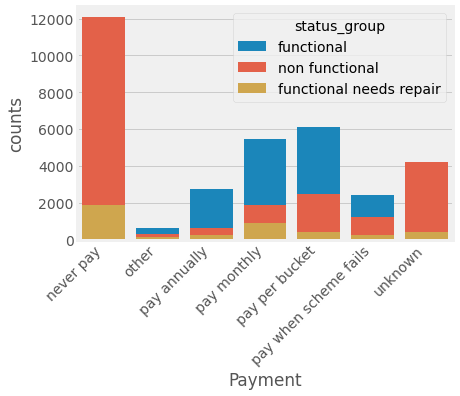
Steady payment plans seem to be a strong indicator of whether the water points would be maintained or not. The problem is that while the responsibility to maintain the water points is left to each community, most communities in Tanzania do not make enough money to upkeep these water points.
穩定的付款計劃似乎是水位是否得以維持的有力指標。 問題是,維護水位的責任留給每個社區,但坦桑尼亞的大多數社區沒有賺到足夠的錢來養護??這些水位。
位置事項 (Location Matters)
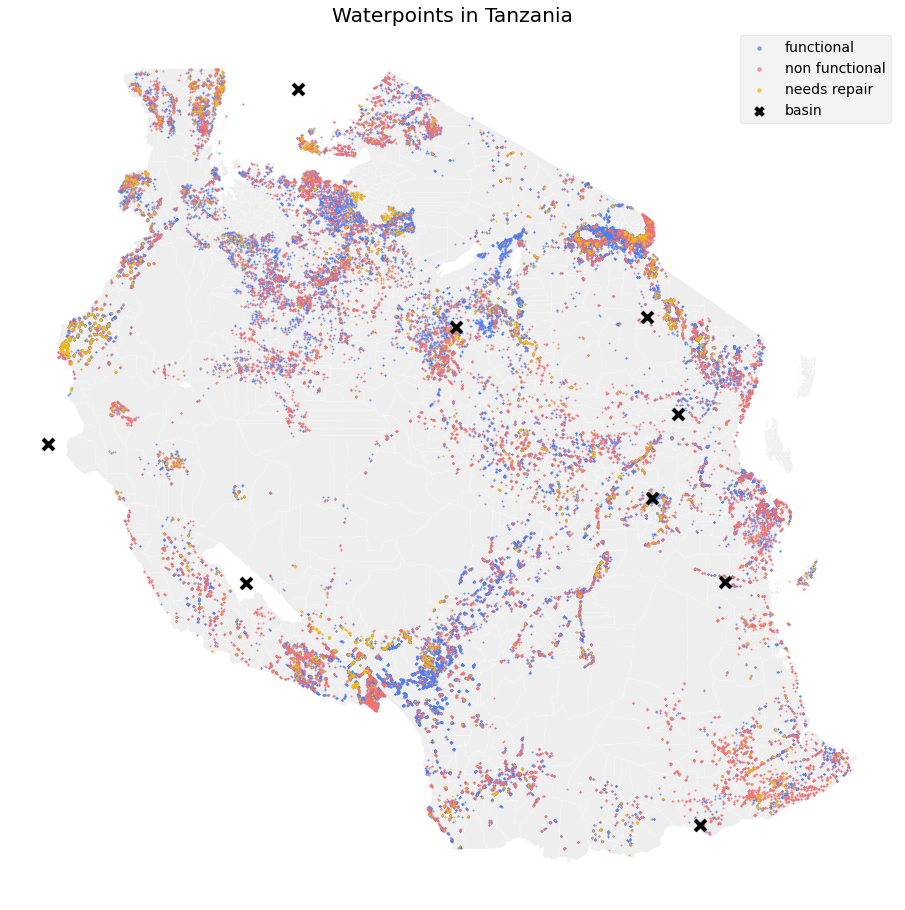
Based on this map of Tanzania, we can see that water point conditions tend to cluster around different areas. This tells us that location is an important predictor of this problem.
根據坦桑尼亞的這張地圖,我們可以看到水位狀況傾向于聚集在不同地區。 這告訴我們位置是此問題的重要預測因素。
特征工程 (Feature Engineering)
Based on our exploratory data analysis, we decided to expand on the features containing location information. First, we found the location of the basin based on its name and calculated the distance to the basin from the water points.
根據我們的探索性數據分析,我們決定擴展包含位置信息的功能。 首先,我們根據其名稱找到盆地的位置,并計算出從水位到盆地的距離。
Finding the location is done using Geopy’s Nominatim package, which uses the OpenStreetMap data.
使用Geopy的Nominatim包來查找位置,該包使用OpenStreetMap數據。
from geopy.geocoders import Nominatimdef get_lat_long(location):# takes location string and return its longitude and latitudegeolocator = Nominatim(user_agent = "Tanzania_water")location = geolocator.geocode(location)return (location.longitude, location.latitude)# all unique basin from df basin column
basins = set(df.basin)
# turn them into a dictionary
allbasins = dict.fromkeys(basins, ()) # for each basin, get long/lat and put in allbasins,
# otherwise throw an error
for bas in basins:if allbasins[bas] != (): continuetry:allbasins[bas] = get_lat_long(bas)except AttributeError:print(f"error: {bas}")Then we calculated the distance using the geodesic distance from Geopy.
然后,我們使用距Geopy的測地線距離來計算距離。
from geopy.distance import geodesicdef get_dist(crd1, crd2): # take two tuples of lat, long # and return distance in milesreturn geodesic(crd1, crd2).miles# apply it to the dataframe
df['dist_to_basin'] = df.apply(lambda x: get_dist((x.latitude, x.longitude), (x.basin_lat, x.basin_long)), axis = 1)Also, we engineered several other features including whether the location is in the urban or rural area and the total number of other wells in the village.
此外,我們還設計了其他幾個功能,包括該位置在城市還是農村地區以及該村中其他水井的總數。
前處理 (Preprocessing)
重采樣 (Resampling)
Our data has a class imbalance issue, meaning that there are way more functional water points than the water points needing repairs. This can bias the prediction towards the majority class, so we used the SMOTE (synthetic minority oversampling technique) to resample our data. Simply put, SMOTE oversamples by synthesizing new samples that are close in distance to existing ones within the same class.
我們的數據存在類不平衡問題,這意味著功能上的供水點比需要維修的供水點還多。 這可能會使預測偏向多數類,因此我們使用SMOTE(合成少數過采樣技術)對數據進行了重新采樣。 簡而言之,SMOTE通過合成與同一類別中現有樣本距離最近的新樣本來進行過采樣。
from imblearn.over_sampling import SMOTEsmote = SMOTE() # initializing
X_train, y_train = smote.fit_sample(X_train, y_train)In addition to resampling, we also converted the categorical features into binary dummies and standardized all features.
除了重新采樣外,我們還將分類特征轉換為二進制虛擬變量并標準化了所有特征。
功能選擇 (Feature Selection)
Our original data had many categorical features, which resulted in a relatively large number of features after one-hot-encoding of categorical features. To optimize computation, we decided to run a tree-based feature selection.
我們的原始數據具有許多分類特征,在對分類特征進行一次熱編碼之后,導致了相對大量的特征。 為了優化計算,我們決定運行基于樹的特征選擇。
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.feature_selection import SelectFromModel# fit to a few random decision trees
etc = ExtraTreesClassifier(n_estimators=100, class_weight='balanced', n_jobs=-1)
etc = etc.fit(X_train, y_train)
# select ones with feature importance less than 0.0001
model = SelectFromModel(etc, prefit=True, threshold = 1e-4)
# tranform the data
X_train_new = model.transform(X_train)
# return the list of new features
new_feats = original_feats[model.get_support()]模型評估 (Model Evaluation)
評估指標 (Evaluation Metrics)
Deciding on the evaluation metrics that align with the project goal is very important (if you need a refresher, see HERE). We approached this problem with two primary purposes, one is to build a model with the highest overall accuracy and another is to build a model that successfully predicts the needs repair cases. The latter was important because predicting the needs repair cases accurately is directly related to changes that affect many people’s lives in Tanzania. But for this post, I will evaluate models in terms of overall accuracy.
確定與項目目標保持一致的評估指標非常重要(如果需要復習,請參閱此處 )。 我們通過兩個主要目的解決了這個問題,一個目的是建立具有最高總體準確性的模型,另一個目的是建立一個能夠成功預測需求修復案例的模型。 后者之所以重要,是因為準確預測需求修復案例與影響坦桑尼亞許多人生活的變化直接相關。 但是對于這篇文章,我將根據整體準確性評估模型。
虛擬分類器 (Dummy Classifier)
First, we started by fitting a dummy classifier as our baseline model. Our dummy classifier used the stratified approach, meaning it made predictions based on the proportion of each class.
首先,我們首先將虛擬分類器擬合為基線模型。 我們的虛擬分類器使用分層方法,這意味著它根據每個類的比例進行預測。
from sklearn.metrics import accuracy_score
from sklearn.dummy import DummyClassifier# dummy using the default stratified strategy
dummyc = DummyClassifier(strategy = 'stratified')
dummyc.fit(X_train, y_train)
y_pred = dummyc.predict(X_test)# report scores!
def scoring (y_test, y_pred):accuracy = round(accuracy_score(y_test, y_pred), 3)print('Accuracy: ', accuracy)scoring(y_test, y_pred)Please note that the X_test in this code refers to our validation set. We have set aside the holdout set to test the final model at the end.
請注意,此代碼中的X_test是指我們的驗證集。 我們預留了保留集,以在最后測試最終模型。
# Dummy result: Accuracy: 0.33Our dummy showed approximately 33% accuracy, which is an expected performance of a dummy for classifying three classes.
我們的假人顯示出約33%的準確性,這是假人對三類進行分類的預期性能。
K最近鄰居 (K-Nearest Neighbors)
The first model we tested was the K-Nearest Neighbors (KNN). The KNN classifies based on the classes of the k number of closest observations. The hyperparameter tuning was achieved by the Optuna. We tested the performance of both GridSearchCV and Optuna and found Optuna to be much more versatile and efficient.
我們測試的第一個模型是K最近鄰居(KNN)。 KNN基于k個最接近的觀測值的類別進行分類。 超參數調整是通過Optuna實現的。 我們測試了GridSearchCV和Optuna的性能,發現Optuna更具通用性和效率。
from sklearn.neighbors import KNeighborsClassifier
import optuna
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_scoredef find_hyperp_KNN(trial):## Setting parameter n_neighbors = trial.suggest_int('n_neighbors', 1, 31)algorithm = trial.suggest_categorical('algorithm', ['ball_tree', 'kd_tree'])p = trial.suggest_categorical('p', [1, 2])## initialize the modelknc = KNeighborsClassifier(weights = 'distance', n_neighbors = n_neighbors, algorithm = algorithm, p = p)## assigning K-fold cross validationcv = KFold(n_splits = 5, shuffle = True, random_state = 20)## calculate the average accuracy score on 5-folds cross validationsscore = np.mean(cross_val_score(knc, X_train, y_train, scoring = 'accuracy', cv = cv, n_jobs = -1))return (score)# initiating the optuna study, maximize accuracy
knn_study = optuna.create_study(direction='maximize')# run optimization for 100 trials
knn_study.optimize(find_hyperp_KNN, n_trials = 100) # use timeout to set the timer# Testing the best params on the test set
knc_opt = KNeighborsClassifier(**knn_study.best_params)
knc_opt.fit(X_train, y_train)
y_pred = knc_opt.predict(X_test)
scoring(y_test, y_pred)# KNN Result - Accuracy: 0.752隨機森林分類器 (Random Forest Classifier)
Next, we tested the random forest classifier with Optuna hyper-tuning. The random forest simultaneously fits multiple decision trees on a subset of the data then aggregates the results.
接下來,我們使用Optuna超調測試了隨機森林分類器。 隨機森林同時將多個決策樹適合數據的子集,然后匯總結果。
from sklearn.ensemble import RandomForestClassifierdef find_hyperparam_rf(trial):### Setting hyperparameter options ###n_estimators = trial.suggest_int('n_estimators', 100, 700)min_samples_split = trial.suggest_int('min_samples_split', 2, 10)min_samples_leaf = trial.suggest_int('min_samples_leaf', 1, 10)criterion = trial.suggest_categorical('criterion', ['gini', 'entropy'])class_weight = trial.suggest_categorical('class_weight', ['balanced', 'balanced_subsample'])max_features = trial.suggest_int('max_features', 2, X_train.shape[1]) # consider using float insteadmin_weight_fraction_leaf = trial.suggest_loguniform('min_weight_fraction_leaf', 1e-7, 0.1)max_leaf_nodes = trial.suggest_int('max_leaf_nodes', 10, 200)### Initializingrfc = RandomForestClassifier(oob_score = True, n_estimators = n_estimators,min_samples_split = min_samples_split,min_samples_leaf = min_samples_leaf,criterion = criterion,class_weight = class_weight, max_features = max_features,min_weight_fraction_leaf=min_weight_fraction_leaf, max_leaf_nodes = max_leaf_nodes)### Setting KFolds Crossvalidationcv = KFold(n_splits = 5, shuffle = True, random_state = 20)### get the average accuracy score of 5 foldsscore = np.mean(cross_val_score(rfc, X_train, y_train,scoring = 'accuracy', cv = cv, n_jobs = -1))return (score)# initialize the study
rfc_study = optuna.create_study(direction='maximize')
# run it for 3 hours or for 100 trials
rfc_study.optimize(find_hyperparam_rf, timeout = 3*60*60, n_trials = 100)# fit the model
rf = RandomForestClassifier(oob_score = True, **rfc_study.best_params)
rf.fit(X_train, y_train)
y_pred_rf = rf.predict(X_test)
scoring(y_test, y_pred_rf)# Random Forest Results - Accuracy : 0.74The performance of KNN was better than the random forest classifier for this problem. But even though not reported here, the random forest classifier did a much better job at classifying the minority class than the KNN.
對于該問題,KNN的性能優于隨機森林分類器。 但是,盡管這里沒有報告,但隨機森林分類器在分類少數族群方面比KNN的工作要好得多。
XGBoost (XGBoost)
Since we tested a bagging method, we also tried a boosting method, using the XGBoost. It’s an implementation of a gradient boosting model, which iteratively trains the weak learners based on the prediction errors it makes.
由于我們測試了裝袋方法,因此我們也嘗試了使用XGBoost的加強方法。 它是梯度提升模型的實現,該模型根據其產生的預測誤差迭代地訓練弱學習者。
import xgboost as xgbdef find_hyperparam(trial):### Setting hyperparameter range ###eta = trial.suggest_loguniform('eta', 0.001, 1)max_depth = trial.suggest_int('max_depth', 1, 50)subsample = trial.suggest_loguniform('subsample', 0.4, 1.0)colsample_bytree = trial.suggest_loguniform('colsample_bytree', 0.01, 1.0)colsample_bylevel = trial.suggest_loguniform('colsample_bylevel', 0.01, 1.0)colsample_bynode = trial.suggest_loguniform('colsample_bynode', 0.01, 1.0)# Initializing the modelxgbc = xgb.XGBClassifier(objective = 'multi:softmax', eta = eta, max_depth = max_depth, subsample = subsample, colsample_bytree = colsample_bytree, colsample_bynode = colsample_bynode, colsample_bylevel = colsample_bylevel)# Setting up k-fold crossvalidationcv = KFold(n_splits = 5, shuffle = True, random_state = 20)# evaluate using accuracyscore = np.mean(cross_val_score(xgbc, X_train, y_train, scoring = 'accuracy', cv = cv, n_jobs = -1))return (score)# initializing optuna study
xgb_study = optuna.create_study(direction='maximize')
# run optimization for 3 hours or for 100 trials
xgb_study.optimize(find_hyperparam, timeout = 3*60*60, n_trials = 100)# testing on the test set
xgbc = xgb.XGBClassifier(**xgb_study.best_params, verbosity=1, tree_method = 'gpu_hist')
xgbc.fit(X_train, y_train)
y_pred = xgbc.predict(X_test)
scoring(y_test, y_pred, 'xgboost')# XGBoost Results - Accuracy: 0.78XGboost showed improvement in the accuracy score, and its sensitivity in predicting minority class was also higher than the other two models.
XGboost的準確性得分有所提高,并且其預測少數族裔類別的敏感性也高于其他兩個模型。
投票分類器 (Voting Classifier)
Lastly, we took all the previous models and put them to vote. When using a voting classifier, we can either combine each model’s prediction on the probability of each class (soft) or use its binary choice of each class (hard). Here, we used soft voting.
最后,我們采用了所有以前的模型并將它們投票。 使用投票分類器時,我們可以結合每個模型對每個類別的概率的預測(軟),也可以使用其對每個類別的二進制選擇(困難)。 在這里,我們使用了軟投票。
from sklearn.ensemble import VotingClassifiervoting_c_soft = VotingClassifier(estimators = [('knc_opt', knc_opt),('rf', rf),('xgbc', xgbc)], voting = 'soft', n_jobs = -1)
# fit on training, test on testing set
voting_c_soft.fit(X_train, y_train)
y_pred = voting_c_soft.predict(X_test)
scoring(y_test, y_pred, 'voting')# Voting Classifier - Accuracy: 0.79Voting classifier returns slightly higher accuracy and similar recall for the minority class. We decided to continue with the voting classifier as our final model and test the holdout test set.
投票分類器返回的準確性略高,而少數民族分類的召回率相似。 我們決定繼續使用投票分類器作為最終模型,并測試保留測試集。
最終模型表現 (Final Model Performance)
Our final model showed 80% prediction accuracy on the holdout set (baseline 45%), and close to 50% recall on the minority class, which is a significant improvement from 6% recall by the baseline model.
我們的最終模型在保留集上具有80%的預測準確度 (基線45%),而在少數群體上的召回率接近50%,與基線模型的6%召回率相比有顯著改善。
獎金:口譯 (Bonus: Interpretation)
Because our final model involved voting between a distance algorithm and tree-based ensembles, it’s difficult to interpret the feature importance of our model. But additional analysis using a logic regression with the Elastic Net regularization and SGD training showed that enough quantity of water, use of communal standpipes, and being recently built were the important predictors of the functional water points.
由于我們的最終模型涉及距離算法和基于樹的集成體之間的投票,因此很難解釋模型的特征重要性。 但是,使用帶有Elastic Net正則化和SGD訓練的邏輯回歸進行的其他分析表明,充足的水量,公用豎管的使用和近期興建的水是功能性水位的重要預測指標。
On the other hand, the location was an important predictor of non-functional water points. Especially some of the northern regions closer to Lake Victoria were highly related to the non-functioning water points. Lastly, GPS heights of water point showed different patterns between the non-functional and ones that need repair. Further investigation is necessary to find the significance of GPS heights whether it’s related to the specific government area, or the difference in accessibility, or whether it has any technical implication to some of the extraction types.
另一方面,該位置是非功能水位的重要預測指標。 尤其是靠近維多利亞湖的一些北部地區與無法正常工作的水位高度相關。 最后,GPS的水位高度在非功能性和需要修復的位置之間顯示出不同的模式。 無論是與特定的政府區域有關,還是在可達性方面的差異,或者對某些提取類型有任何技術影響,都必須進行進一步的調查來確定GPS高度的重要性。
This project was done in collaboration with my colleague dolcikey.
這個項目是與我的同事dolcikey合作完成的。
翻譯自: https://towardsdatascience.com/machine-learning-to-help-water-crisis-24f40b628531
機器學習解決什么問題
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389166.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389166.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389166.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
)
遞歸原來可以so easy|-連載(3)

Viewport3D 類Viewport3D 類Viewport3D 類

升級android 6.0系統

AGC 022 B - GCD Sequence

最接近原點的 k 個點_第K個最接近原點的位置


讓自己的頭腦極度開放

簡介DOTNET 編譯原理 簡介DOTNET 編譯原理 簡介DOTNET 編譯原理

RecyclerView詳細了解

案例與案例之間的非常規排版

熊貓分發_熊貓新手:第二部分

淺析微信支付:申請退款、退款回調接口、查詢退款
)
view工作原理-計算視圖大小的過程(onMeasure)
![[轉載]使用.net 2003中的ngen.exe編譯.net程序](http://pic.xiahunao.cn/[轉載]使用.net 2003中的ngen.exe編譯.net程序)
[轉載]使用.net 2003中的ngen.exe編譯.net程序

基于Redis實現分布式鎖實戰

數據分析 績效_如何在績效改善中使用數據分析



您一直在尋找5+個簡單的一線工具來提升Python可視化效果
