aws spark
技術提示 (TECHNICAL TIPS)
介紹 (Introduction)
At first, it seemed to be quite easy to write down and run a Spark application. If you are experienced with data frame manipulation using pandas, numpy and other packages in Python, and/or the SQL language, creating an ETL pipeline for our data using Spark is quite similar, even much easier than I thought. And comparing to other database (such as Postgres, Cassandra, AWS DWH on Redshift), creating a Data Lake database using Spark appears to be a carefree project.
最初,寫下并運行一個Spark應用程序似乎很容易。 如果您熟悉使用Python和/或SQL語言中的pandas,numpy和其他軟件包進行數據幀操作的經驗,那么使用Spark為我們的數據創建ETL管道非常相似,甚至比我想象的要容易得多。 與其他數據庫(例如Postgres,Cassandra,Redshift上的AWS DWH)相比,使用Spark創建Data Lake數據庫似乎是一個輕松的項目。
But then, when you deployed Spark application on the cloud service AWS with your full dataset, the application started to slow down and fail. Your application ran forever, you even didn’t know if it was running or not when observing the AWS EMR console. You might not know where it was failed: It was difficult to debug. The Spark application behaved differently between the local mode and stand alone mode, between the test set — a small portion of dataset — and full dataset. The list of problems went on and on. You felt frustrated. Really, you realized that you knew nothing about Spark. Well, optimistically, then it was indeed a very good opportunity to learn more about Spark. Running into issues is the normal thing in programming anyway. But, how to solve problems quickly? Where to start?
但是,當您將具有完整數據集的Spark應用程序部署到云服務AWS上時,該應用程序開始運行緩慢并失敗。 您的應用程序永遠運行,在觀察AWS EMR控制臺時,您甚至都不知道它是否正在運行。 您可能不知道它在哪里失敗:這很難調試。 在局部模式和獨立模式之間,測試集(數據集的一小部分)和完整數據集之間,Spark應用程序的行為有所不同。 問題的清單還在不斷。 你感到沮喪。 確實,您意識到自己對Spark一無所知。 好吧,樂觀的話,那確實是一個很好的機會,更多地了解Spark。 無論如何,遇到問題是編程中的正常現象。 但是,如何快速解決問題? 從哪兒開始?
After struggling with creating a Data Lake database using Spark, I feel the urge to share what I have encountered and how I solved these issues. I hope it is helpful for some of you. And please, correct me if I am wrong. I am still a newbie in Spark anyway. Now, let’s dive in!
在努力使用Spark創建Data Lake數據庫之后,我感到有分享自己遇到的問題以及如何解決這些問題的渴望。 希望對您中的某些人有所幫助。 如果我錯了,請糾正我。 無論如何,我還是Spark的新手。 現在,讓我們開始吧!
Cautions
注意事項
1. This article assumes that you already have some working knowledge of Spark, especially PySpark, command line environment, Jupyter notebook and AWS. For more about Spark, please read the reference here.
1.本文假設您 已經具備一些Spark的工作知識,尤其是PySpark,命令行環境,Jupyter Notebook和AWS。 有關Spark的更多信息,請在此處閱讀參考。
2. This is your responsibility for monitoring usage charges on the AWS account you use. Remember to terminate the cluster and other related resources each time you finish working. The EMR cluster is costly.
2.這是您負責監視所使用的AWS賬戶的使用費用的責任。 請記住,每次完成工作時都要終止集群和其他相關資源。 EMR集群的成本很高。
3. This is one of the accessing projects for the Data Engineering nanodegree on Udacity. So to respect the Udacity Honor Code, I would not include the full notebook with the workflow to explore and build the ETL pipeline for the project. Part of the Jupyter notebook version of this tutorial, together with other tutorials on Spark and many more data science tutorials could be found on my github.
3.這是Udacity上的數據工程納米學位的訪問項目之一。 因此,為了遵守Udacity榮譽守則,我不會在工作流程中包括完整的筆記本來探索和構建該項目的ETL管道。 本教程的Jupyter筆記本版本的一部分,以及Spark上的其他教程以及更多數據科學教程,都可以在我的github上找到。
項目介紹 (Project Introduction)
項目目標 (Project Goal)
Sparkify is a startup company working on a music streaming app. Through the app, Sparkify has collected information about user activity and songs, which is stored as a directory of JSON logs (log-data - user activity) and a directory of JSON metadata files (song_data - song information). These data resides in a public S3 bucket on AWS.
Sparkify是一家致力于音樂流應用程序的新興公司。 通過該應用程序,Sparkify收集了有關用戶活動和歌曲的信息,這些信息存儲為JSON日志的目錄( log-data -用戶活動)和JSON元數據文件的目錄( song_data歌曲信息)。 這些數據位于AWS上的公共S3存儲桶中。
In order to improve the business growth, Sparkify wants to move their processes and data onto the data lake on the cloud.
為了提高業務增長,Sparkify希望將其流程和數據移至云上的數據湖中。
This project would be a workflow to explore and build an ETL (Extract — Transform — Load) pipeline that:
該項目將是一個工作流程,用于探索和構建ETL(提取-轉換-加載)管道 ,該管道包括:
- Extracts data from S3 從S3提取數據
- Processes data into analytics tables using Spark on an AWS cluster 在AWS集群上使用Spark將數據處理到分析表中
- Loads the data back into S3 as a set of dimensional and fact tables for the Sparkify analytics team to continue finding insights in what songs their users are listening to. 將數據作為一組維度表和事實表加載到S3中,以供Sparkify分析團隊繼續查找其用戶正在收聽的歌曲的見解。
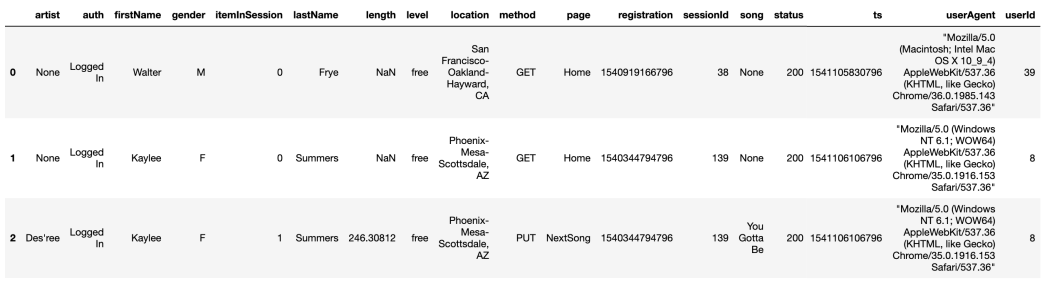
Below are the sample from JSON log file and JSON song file:
以下是JSON日志文件和JSON歌曲文件的示例:

The dimension and fact tables for this database were designed as followed: Fields in bold: partition keys.
此數據庫的維和事實表的設計如下: 粗體字的字段:分區鍵。

(ERD diagram was made using https://dbdiagram.io/)
(ERD圖是使用https://dbdiagram.io/制作的 )
Project Workflow
項目工作流程
This is my workflow for the project. An experienced data engineer might skip many of these steps, but for me, I would rather go slowly and learn more:
這是我的項目工作流程。 經驗豐富的數據工程師可能會跳過許多步驟,但是對我來說,我寧愿慢慢學習并了解更多信息:
- Build the ETL process step-by-step using Jupyter notebook on sample data in local directory; write output to local directory. 使用Jupyter Notebook在本地目錄中的示例數據上逐步構建ETL流程; 將輸出寫入本地目錄。
- Validate the ETL Process using the sub-dataset on AWS S3; write output to AWS S3. 使用AWS S3上的子數據集驗證ETL流程; 將輸出寫入AWS S3。
Put all the codes together to build the script
etl.pyand run on Spark local mode, testing both the local data and a subset of data ons3//udacity-den. The output result from the task could be test using a jupyter notebooktest_data_lake.ipynb.將所有代碼放在一起以構建腳本
etl.py并在Spark本地模式下運行,在s3//udacity-den上測試本地數據和數據子集。 可以使用Jupyter筆記本test_data_lake.ipynb測試該任務的輸出結果。- Build and launch an EMR cluster. As what I know, you could submit the project on Udacity without using EMR, but I highly recommend you to run it on the Spark stand alone mode on AWS to see how it works. You definitely will learn a lot more. 構建并啟動EMR集群。 據我所知,您可以在不使用EMR的情況下在Udacity上提交項目,但是我強烈建議您在AWS的Spark獨立模式下運行它,以查看其工作方式。 您肯定會學到更多。
Submit a Spark job for
etl.pyon EMR cluster, using a subset of data ons3//udacity-den.使用
s3//udacity-den上的數據子集為EMR集群上的etl.py提交Spark作業。Finally, submit a Spark job for
etl.pyon EMR cluster, using a full dataset ons3//udacity-den.最后,使用
s3//udacity-den上的完整數據集為EMR集群上的etl.py提交Spark作業。- Try to optimize the Spark performance using various options. 嘗試使用各種選項來優化Spark性能。
Provide example queries and results for song play analysis. This part was described in another jupyter notebook called
sparkifydb_data_lake_demo.ipynb.提供示例查詢和結果以進行歌曲播放分析。 在另一個名為
sparkifydb_data_lake_demo.ipynbjupyter筆記本中描述了此部分。
The validation and demo part could be found on my github. Other script file etl.py and my detailed sparkifydb_data_lake_etl.ipynb are not available in respect of Udacity Honor Code.
驗證和演示部分可以在我的github上找到。 關于Udacity Honor Code,其他腳本文件etl.py和我詳細的sparkifydb_data_lake_etl.ipynb不可用。
項目中的一些技巧和問題 (Some Tips and Issues in The Project)
技巧1-在建立ETL管道以使用腳本處理整個數據集之前,先在Jupyter筆記本中逐步建立ETL流程。 (Tip 1 — Build the ETL process incrementally in Jupyter notebook before building ETL pipeline to process a whole dataset with scripts.)
Jupyter notebook is a great environment for exploratory data analysis (EDA), testing things out and promptly validating the results. Since debugging and optimizing the Spark application is quite challenging, it is highly recommended to build the ETL process step by step before putting all the codes together. You will see how advantage it is when we come to other tips.
Jupyter Notebook是探索性數據分析(EDA),測試事物并及時驗證結果的絕佳環境 。 由于調試和優化Spark應用程序非常困難,因此強烈建議在將所有代碼放在一起之前逐步構建ETL過程。 當我們介紹其他技巧時,您將看到它的優勢。
- Another important reason for using notebook: It is impractical to create etl.py script and then try to debug it since you would have to create a spark session each time you run etl.py file. With notebook, the spark session is always available. 使用筆記本的另一個重要原因:創建etl.py腳本然后嘗試對其進行調試是不切實際的,因為每次運行etl.py文件時都必須創建一個spark會話。 使用筆記本電腦,火花會話始終可用。
技巧2-仔細瀏覽數據集。 如果數據集“很大”,則從一個小的子集開始項目。 (Tip 2— Carefully explore the dataset. If the dataset is “big”, start the project with a small subset.)
In order to work on the project, first, we need to know the overview about the dataset, such as the number of files, number of lines in each file, total size of the dataset, the structure of the file, etc. It is especially crucial if we work on the cloud, where requests could cost so much time and money.
為了進行該項目,首先,我們需要了解有關數據集的概述 ,例如文件數,每個文件中的行數,數據集的總大小,文件的結構等。如果我們在云上工作尤其重要,因為云上的請求可能會花費大量時間和金錢。
To do that, we can use boto3, the Amazon Web Services (AWS) SDK for Python. boto3 allows us to access AWS via an IAM user. The detail on how to create an IAM user can be found in here, Step 2: Create an IAM user.
為此,我們可以使用 boto3 ,適用于Python的Amazon Web Services(AWS)SDK 。 boto3允許我們通過IAM用戶訪問AWS。 有關如何創建IAM用戶的詳細信息,請參見此處的步驟2:創建IAM用戶。
Below is the way to set up the client for S3 on Jupyter notebook:
下面是在Jupyter筆記本上為S3設置客戶端的方法:
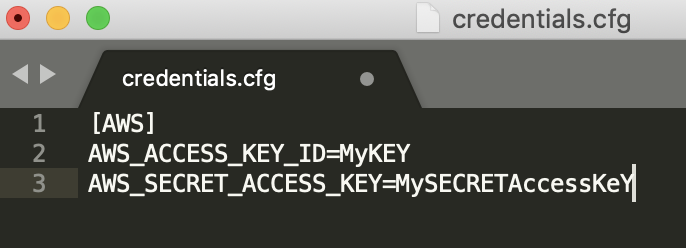
The key and access key obtained from an IAM user could be save to the file credentials.cfg at local directory as below. Note that you may run into “configure file parsing error” if you put your key and secrete key inside “ ” or ‘ ’, or if the file does not have the header such as [AWS]
可以將從IAM用戶獲得的密鑰和訪問密鑰保存到本地目錄中的certificate.cfg文件中,如下所示。 請注意,如果將密鑰和秘密密鑰放在“”或“'”中,或者文件沒有??諸如[AWS]的標題,則可能會遇到“配置文件解析錯誤”
With this client for S3 created by boto3, we can access the dataset for the project and look at the file structures of log-data and song_data:
使用由boto3創建的S3客戶端,我們可以訪問項目的數據集并查看log-data和song_dat a的文件結構:
The ouputs of the exploration process are:
勘探過程的輸出是:


The dataset is not big, ~3.6MB. However, the song_data has ~15,000 files. It is better to use a subset of song_data, such as ‘song_data/A/A/A/’ or ‘song_data/A/’ for exploring/creating/debugging the ETL pipeline first.
數據集不大,約為3.6MB。 但是,song_data具有約15,000個文件。 最好使用song_data的子集(例如“ song_data / A / A / A /”或“ song_data / A /”)先探索/創建/調試ETL管道。
技巧3 —在Spark中將文件讀取到數據幀時包括定義的架構 (Tip 3— Include defined schema when reading files to data frame in Spark)
My ETL pipeline worked very well on the subset of the data. However, when I run it on the whole dataset, the Spark application kept freezing without any error notice. I had to reduce/increase the sub dataset to actually see the error and fix the problem, for example changing from ‘song_data/A/A/A’ to ‘song_data/A/’ and vice versa. So what is the problem here?
我的ETL管道在數據子集上工作得很好。 但是,當我在整個數據集上運行它時,Spark應用程序保持凍結,而沒有任何錯誤通知。 我必須減少/增加子數據集才能真正看到錯誤并解決問題,例如從'song_data / A / A / A'更改 至 'song_data / A /' ,反之亦然。 那么這是什么問題呢?
- It turned out that on this specific data, on the small dataset, my Spark application could automatically figure out the schema. But it could not on bigger dataset, perhaps due to inconsistency among the files and/or incompatible data types. 事實證明,在此特定數據上,在小型數據集上,我的Spark應用程序可以自動找出模式。 但是它可能無法在更大的數據集上使用,可能是由于文件之間的不一致和/或數據類型不兼容。
- Moreover, the loading would take less time with a defined schema. 而且,使用定義的架構,加載將花費更少的時間。
How to design a correct schema:
如何設計正確的架構:
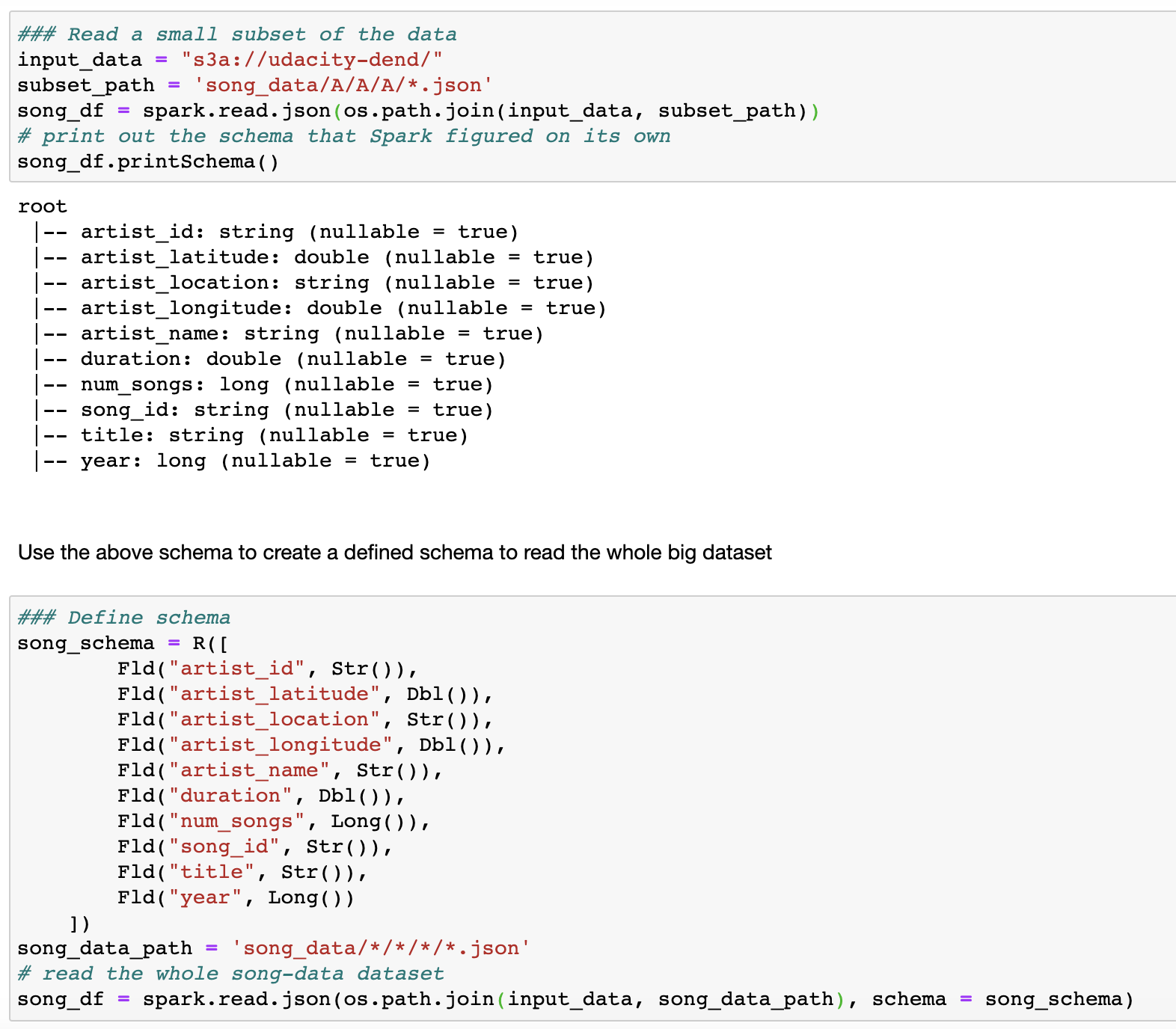
- You can manually create schema by looking at the structure of the log_data json files and the song_data json files. For simple visualization, I generated the view using pandas data fram as below 您可以通過查看log_data json文件和song_data json文件的結構來手動創建架構。 為了進行簡單的可視化,我使用pandas數據框架生成了如下視圖
For me, the trick is letting Spark read and figure out the schema on its own by reading the small subset of files into data frame, and then use it to create the right schema. With that, we don’t need to guess any kind of datatypes, whether it is string or double or long, etc. The demonstration for this trick is as followed:
對我來說,訣竅是讓Spark通過將文件的一小部分讀取到數據幀中來自行讀取并找出模式,然后使用它來創建正確的模式。 這樣,我們就不必猜測任何類型的數據類型,無論它是字符串,雙精度還是長整數等。此技巧的演示如下:
提示4 —打印出任務并記錄每個任務的時間 (Tip 4— Print out the task and record the time of each task)
Although it is the best practice in programming, we sometimes forget to do that. For big dataset, observing the time for each task is very important for debugging and optimizing Spark application.
盡管這是編程中的最佳做法,但有時我們卻忘記這樣做。 對于大型數據集,觀察每個任務的時間對于調試和優化Spark應用程序非常重要。

Unless you turn off INFO logging in Spark, it is very difficult, if not impossible, to know the progress of the Spark application on the terminal, which is overwhelming with INFO logging. By printing out the task name and recording the time, everything is better:
除非您在Spark中關閉INFO日志記錄,否則很難(即使不是不可能)知道終端上Spark應用程序的進度,這對于INFO日志記錄來說是不知所措的。 通過打印任務名稱并記錄時間,一切都會變得更好:
提示5 —在pyspark軟件包中導入和使用函數的最佳方法是什么? (Tip 5 — What is the best way to import and use a function in pyspark package?)
There are at least 2 ways to import and use a function, for example:
至少有2種方式導入和使用函數,例如:
from pyspark.sql.functions import maxfrom pyspark.sql.functions import maxor
import pyspark.sql.functions as Fand then useF.max或
import pyspark.sql.functions as F,然后使用F.max
Either is fine. I prefer the second approach since I don’t need to list all the function on the top of my script etl.py.
都可以。 我更喜歡第二種方法,因為我不需要在腳本etl.py的頂部列出所有功能。
Notice that max function is an exception since it is also a built-in max function in Python. To use max function from the pyspark.sql.functions module, you have to use F.max or using alias, such asfrom pyspark.sql.functions import max as max_
請注意, max函數是一個例外,因為它也是Python中的內置max函數。 要從pyspark.sql.functions模塊使用max函數,您必須使用F.max或使用別名,例如from pyspark.sql.functions import max as max_
提示6 –當我的Spark應用程序凍結時,怎么了? (Tip 6 — What is wrong when my Spark application freezes?)
There could be many problems with it. I got some myself:
可能有很多問題。 我有一些自己:
Difference in AWS region: Please make sure to use us-west-2 when setting up boto3/EMR cluster/S3 output bucket, etc. since the available dataset is on that AWS region.
AWS區域的差異:設置boto3 / EMR群集/ S3輸出存儲桶等時,請確保使用us-west-2 ,因為可用的數據集在該AWS區域上。
Didn’t include defined schema when reading files to data frame: Fix using Tip 3.
在將文件讀取到數據幀時未包含已定義的架構:使用提示3進行修復。
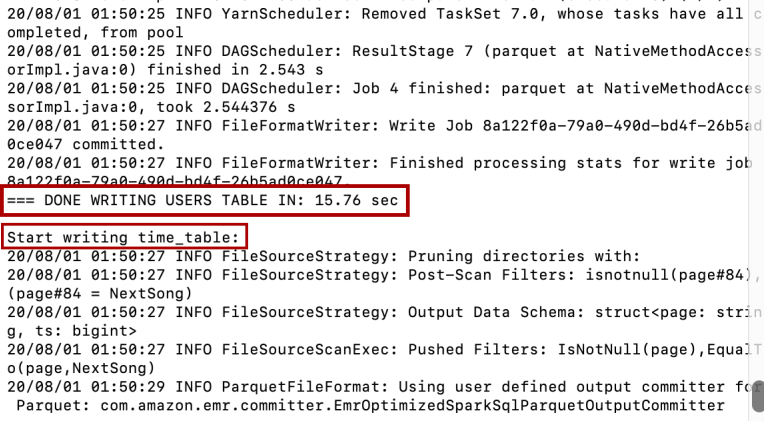
It takes such a long time to run the ETL pipeline on the whole dataset: The project is quite impractical because reading and writing to S3 from EMR/Spark are extremely slow. When running the ETL pipeline on a small sub dataset, you can see the same pattern of INFO logging repeats again and again on the terminal, such as the one below:
在整個數據集上運行ETL管道需要花費很長時間:該項目非常不切實際,因為從EMR / Spark讀取和寫入S3的速度非常慢 。 在小的子數據集上運行ETL管道時,您可以看到相同的INFO日志記錄模式在終端上一次又一次地重復,例如以下示例:
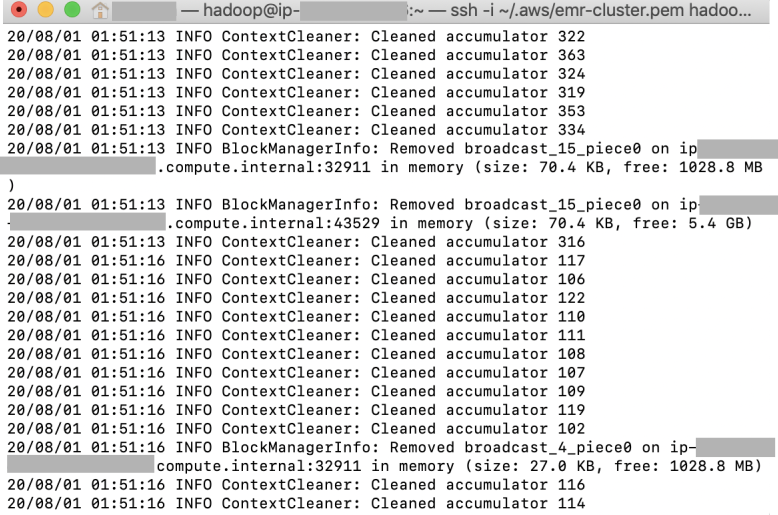
This is on the “INFO ContextCleaner: Cleaned accumulator xxx” where I found my Spark application appeared to be freezing again and again. It’s expected to be a long running job, which took me ~115 min to write only the songs table into the s3 bucket. So if you are sure that your end-to-end process works perfectly, then be patient for 2 hours to see how it works. The process could be speeded up, check out on Tip 9 below.
這是在“ INFO ContextCleaner:清理的累加器xxx”上 ,我發現我的Spark應用程序似乎一次又一次地凍結。 預計這將是一項長期工作,花了我約115分鐘才能將Songs表僅寫入s3存儲桶。 因此,如果您確定端到端流程可以完美運行,請耐心等待2個小時,看看其工作原理。 可以加快該過程,請查看下面的提示9 。
4. Checking the running time on AWS EMR console: You can see how long your Spark application ran when choose the Application user interfaces tab on your cluster on EMR console. The list of application can be found at the end of the page:
4.檢查AWS EMR控制臺上的運行時間:在EMR控制臺上的集群上選擇Application User Interfaces選項卡時,您可以看到Spark應用程序運行了多長時間。 您可以在頁面末尾找到應用程序列表:
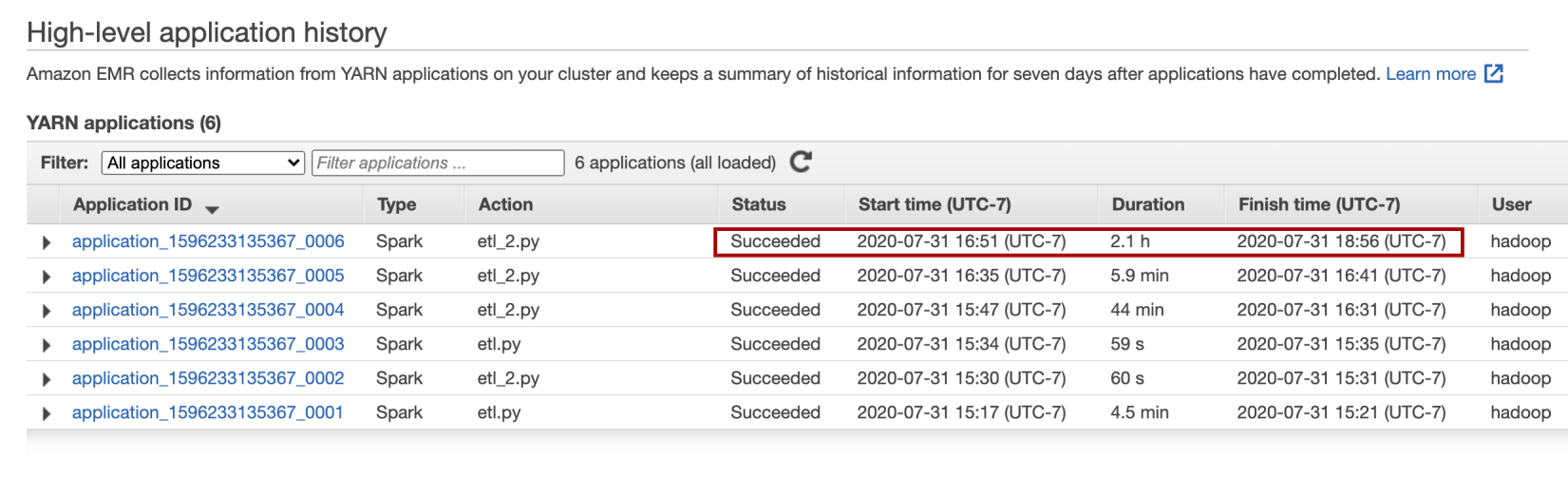
My ETL pipeline on the whole dataset took ~2.1 hrs to finished on the EMR cluster (1 Master node and 2 Core nodes of type m5.xlarge).
我在整個數據集上的ETL管道在EMR集群(1個主節點和2個m5.xlarge類型的核心節點)上花費了大約2.1小時。
技巧7-使用Spark自動增加songplays_id的問題-這不是一個小問題。 (Tip 7 — Auto-increment for songplays_id using Spark— It is not a trivial issue.)
This issue is trivial in other database: In Postgres, we can use SERIAL to auto-increment a column, such as songplays_id SERIAL PRIMARY KEY. In AWS Redshift, we can use IDENTITY(seed, step).
這個問題在其他數據庫中是微不足道的:在Postgres中,我們可以使用SERIAL自動增加一列,例如songplays_id SERIAL PRIMARY KEY 。 在AWS Redshift中,我們可以使用IDENTITY(seed, step) 。
It is not trivial to perform auto-increment for table using Spark, at least when you try to understand it deeply and in consideration of Spark performance. Here is one of the good references to understand auto-increment in Spark.
使用Spark對表執行自動遞增并非易事,至少在您嘗試深入了解并考慮Spark性能的情況下。 這是了解Spark中自動遞增的很好的參考之一 。
There are 3 methods for this task:
此任務有3種方法 :
- Using row_number() function using SparkSQL 使用SparkSQL使用row_number()函數
- Using rdds to create indexes and then convert it back to data frame using the rdd.zipWithIndex() function 使用rdds創建索引,然后使用rdd.zipWithIndex()函數將其轉換回數據幀
- Using the monotonically_increasing_id() 使用monotonically_increasing_id()
I prefer the rdd.zipWithIndex() function:
我更喜歡rdd.zipWithIndex()函數:
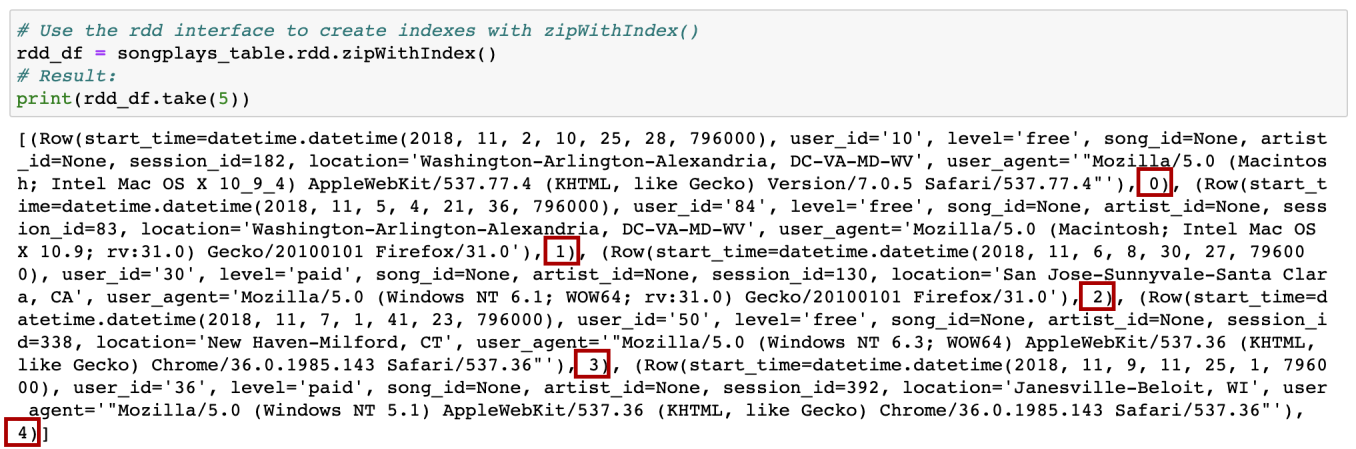
Step 1: From the songplays_table data frame, use the rdd interface to create indexes with zipWithIndex(). The result is a list of rows, each row contains 2 elements: (i) all the columns from the old data frame zipped into a “row”, and (ii) the auto-increment indexes:
步驟1:從songplays_table數據框中,使用rdd接口使用zipWithIndex()創建索引。 結果是一個行列表,每行包含2個元素:(i)舊數據幀中的所有列都壓縮為“行”,并且(ii)自動增量索引:
Step 2: Return it back to data frame — we need to write a lambda function for it.
第2步:將其返回數據框-我們需要為其編寫一個lambda函數。
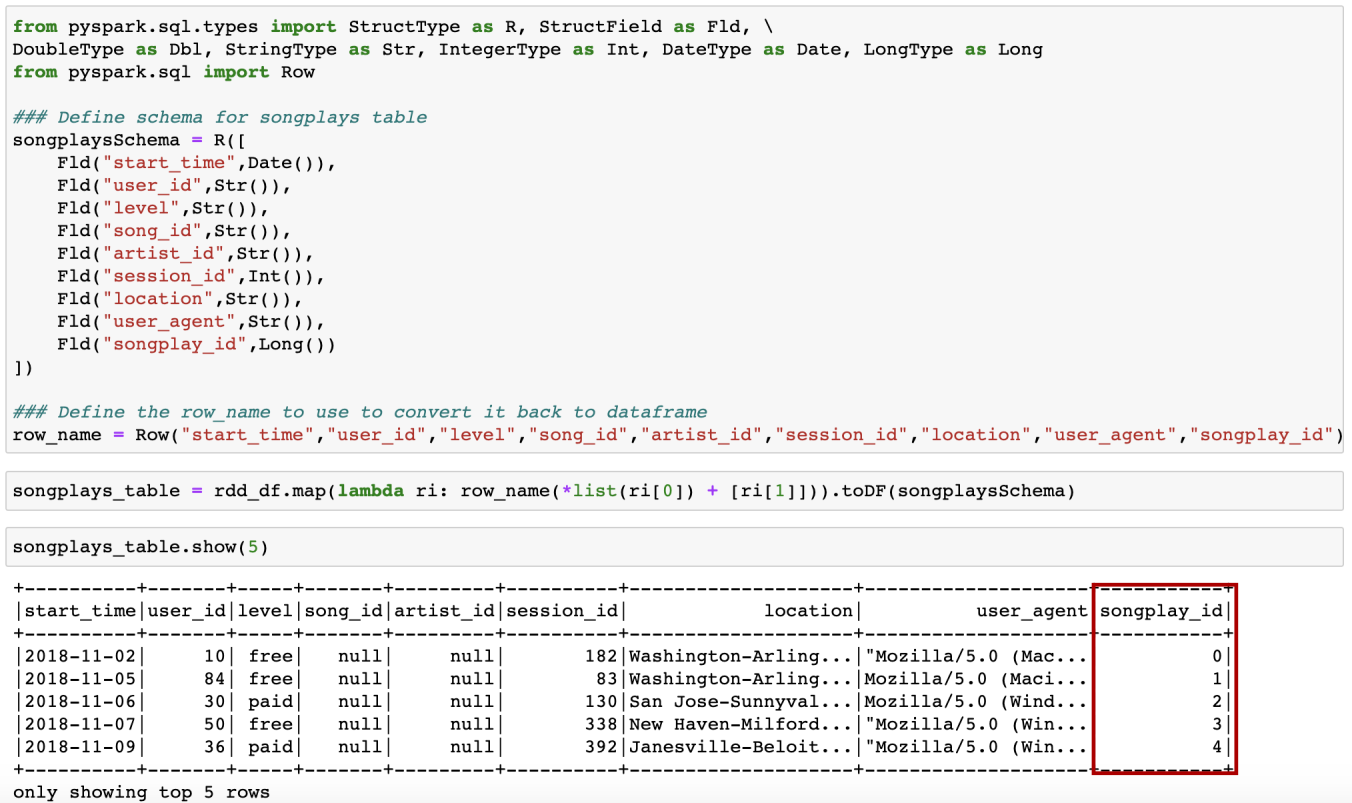
技巧8:談論時間,加載和寫入每個表需要多長時間? (Tip 8— Talking about time, how long does it take to load and write each table?)
Below is the time for running the Spark application on AWS EMR cluster, reading from and writing to S3:
下面是在AWS EMR集群上運行Spark應用程序,讀取和寫入S3的時間:

My EMR cluster had 1 Master node and 2 Core nodes of type m5.xlarge, as shown below:
我的EMR群集具有1個主節點和2個m5.xlarge類型的核心節點,如下所示:
aws emr create-cluster --name test-emr-cluster --use-default-roles --release-label emr-5.28.0 --instance-count 3 --instance-type m5.xlarge --applications Name=JupyterHub Name=Spark Name=Hadoop --ec2-attributes KeyName=emr-cluster --log-uri s3://s3-for-emr-cluster/技巧9-如何加快ETL流程? (Tip 9 —How to speed up the ETL pipeline?)
We definitely love to optimize the Spark application since reading and writing into S3 take a long time. Here is some optimizations that I have tried:
我們絕對喜歡優化Spark應用程序,因為對S3的讀寫需要很長時間。 這是我嘗試過的一些優化:
Set spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version to 2
將 spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version 設置 為2
You can read in detail about it here. It can be done simply by adding spark.conf.set("mapreduce.fileoutputcommitter.algorithm.version", "2") into spark session.
您可以在此處詳細閱讀。 只需在spark會話中添加spark.conf.set("mapreduce.fileoutputcommitter.algorithm.version", "2")即可完成此操作。
With this optimization, the total ETL time reduced dramatically from ~2.1hr to only 30 min.
通過這種優化,總的ETL時間從?2.1hr大大減少到只有30分鐘。
Use HDFS to speed up the process
使用HDFS加快過程
- “On a per node basis, HDFS can yield 6X higher read throughput than S3”. So we can save the analytics tables to HDFS, then copy from HDFS to S3. We could use s3-dist-cp to copy from HDFS to S3.
- “在每個節點上,HDFS可以產生比S3高6倍的讀取吞吐量”。 因此,我們可以將分析表保存到HDFS,然后從HDFS復制到S3。 我們可以使用s3-dist-cp從HDFS復制到S3。
技巧10-輸出如何? 如何在S3上顯示分析表? (Tip 10 — How is the output? How do the analytics tables turn out on S3?)
This ETL pipeline is a long running job, in which the task writing the song table took most of the time. The songs table was partitioned by “year” and “artist”, which could produce skew data where some early years (1961 to 199x) don’t contain many songs comparing to the years 200x.
此ETL管道是一項長期運行的工作,其中大部分時間都在編寫song表的任務中。 歌曲表按“年”和“藝術家”劃分,這可能會產生歪斜的數據,其中某些早期年份(1961年至199x)與200x年相比并不包含很多歌曲。
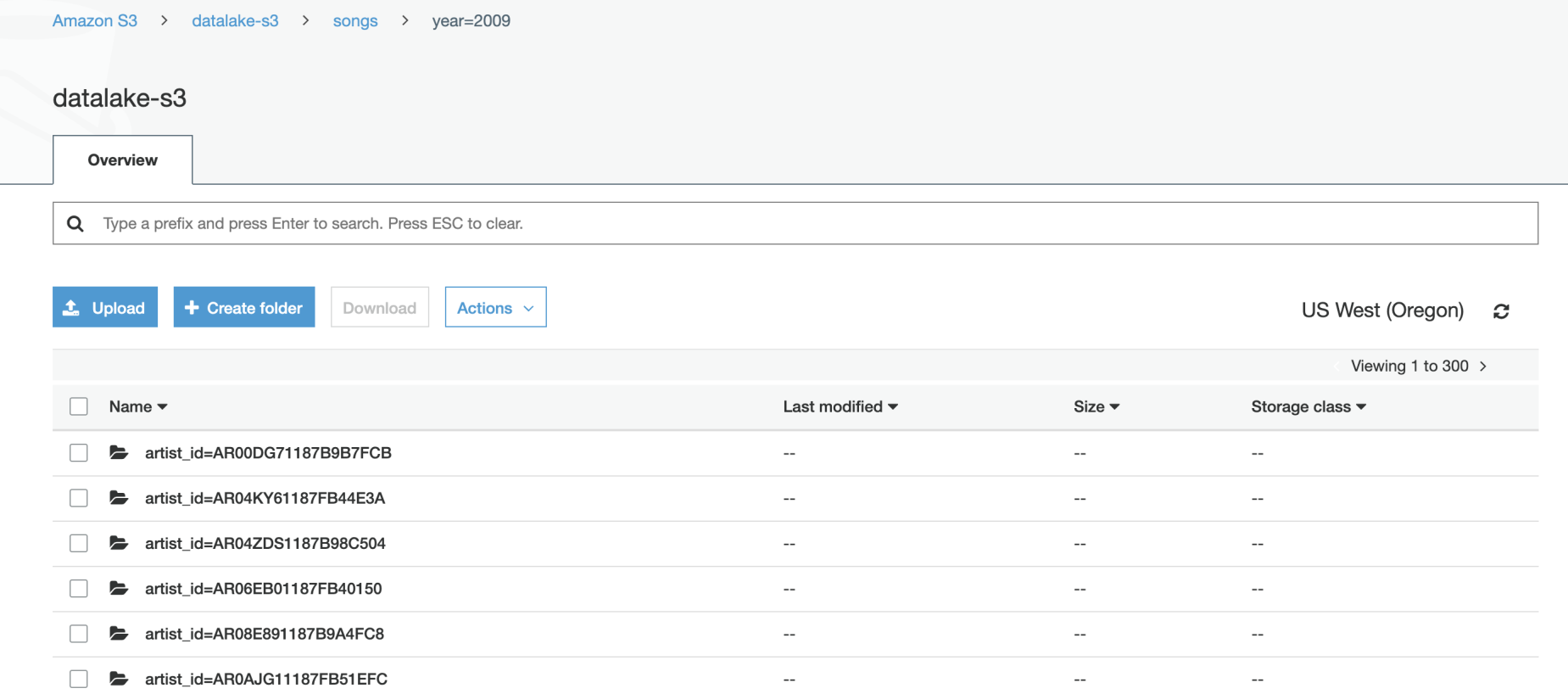
The data quality check result to make sure if the ETL pipeline successfully added all the records to the tables, together with some example queries and results for song play analysis could be found on my notebook on github.
可以在我的github筆記本上找到數據質量檢查結果 ,以確保ETL管道是否成功將所有記錄添加到表中,以及一些示例查詢和歌曲播放分析結果 。
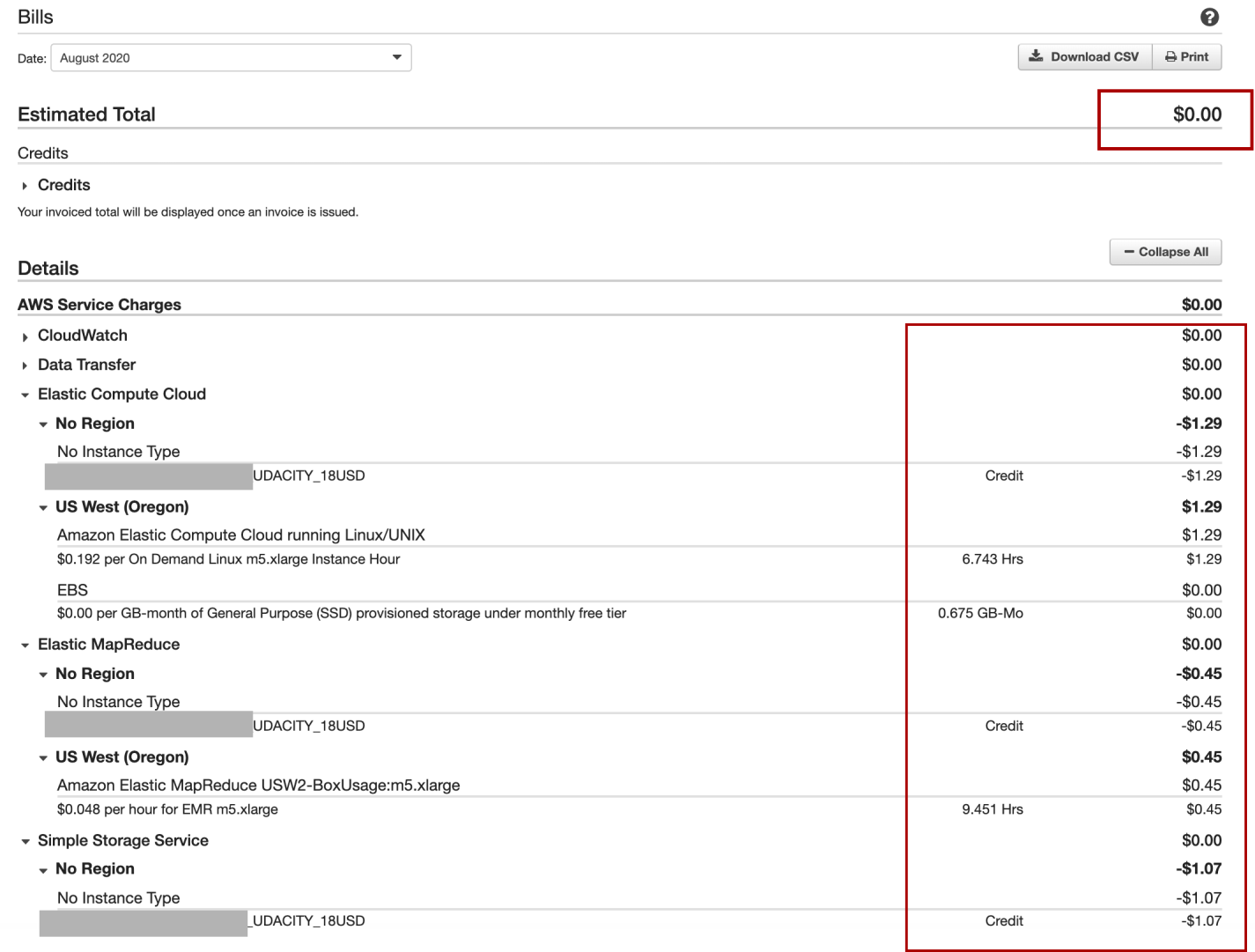
技巧11 –不要讓AWS Billing Dashboard混淆您 (Tip 11 — Don’t let AWS Billing Dashboard confuse you)
Although I have used AWS “quite a lot” and already reached the Free Tier usage limit with this account, whenever I came to the Billing Dashboard, the total amount due is 0.
盡管我已經“大量使用” AWS,并且已經使用此帳戶達到了免費套餐使用限制,但是每當我來到Billing Dashboard時, 應付的總金額為0。
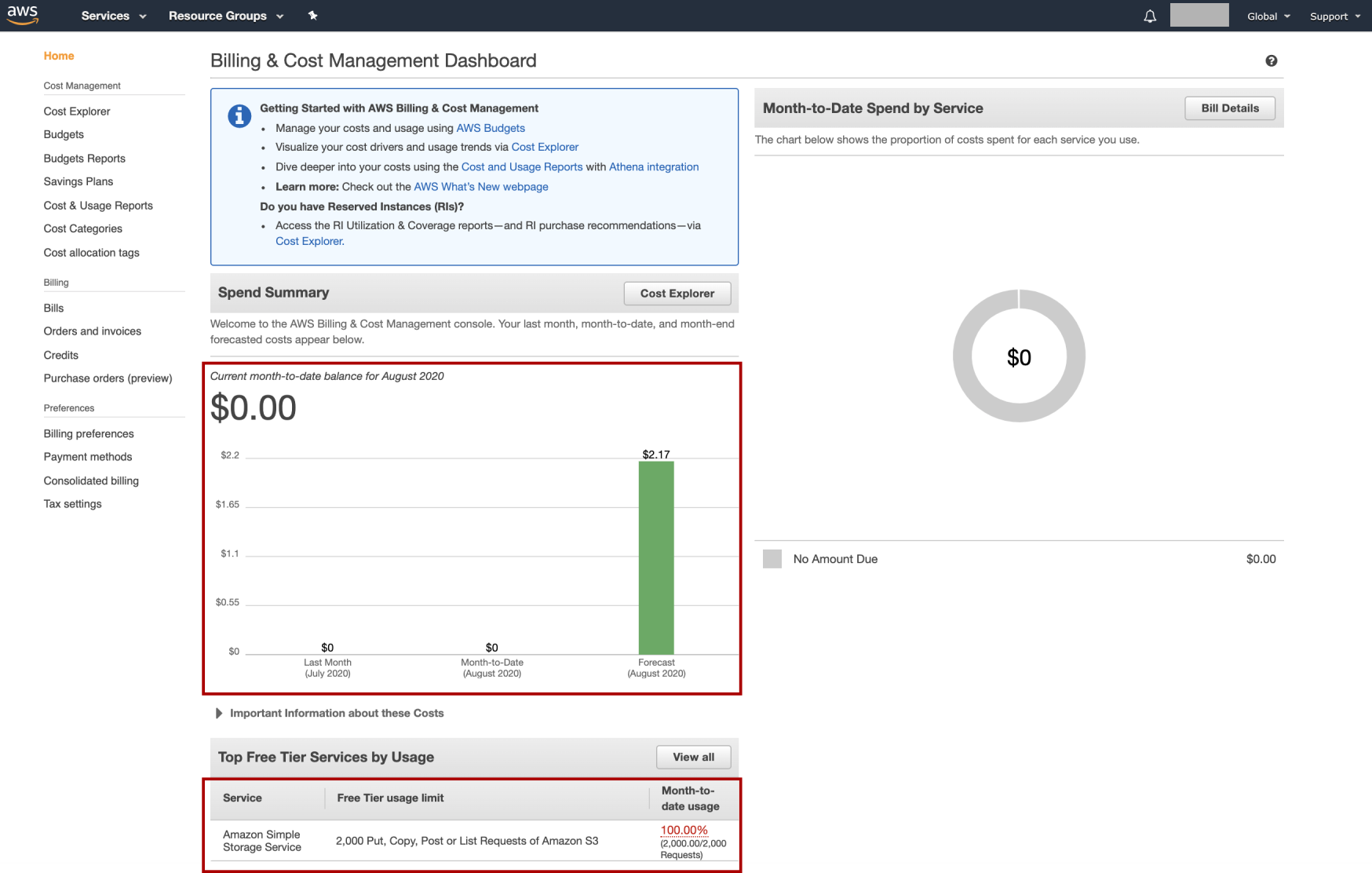
Don’t let AWS Billing Dashboard confuse you. What it shows is the total balance, not your AWS expense. It is the balance which — according to Wikipedia — is “the difference between the sum of debit entries and the sum of credit entries entered into an account during a financial period.”
不要讓AWS Billing Dashboard混淆您。 它顯示的是總余額,而不是您的AWS費用。 平衡是-根據 維基百科 -是“借記項之和在財政期間進入賬戶貸方的總和之間的差異。”
I thought when looking at the AWS Billing Dashboard, I would see the amount I had spent so far, my AWS expense. But no. Even when click on the Bill Details, everything is 0. And so I thought that I didn’t use AWS that much. My promo credit was still safe.
我以為,在查看AWS Billing Dashboard時,我會看到到目前為止已花費的金額,即我的AWS費用。 但不是。 即使單擊“賬單明細”,所有內容都為0。所以我認為我使用的AWS并不多。 我的促銷信用仍然很安全。
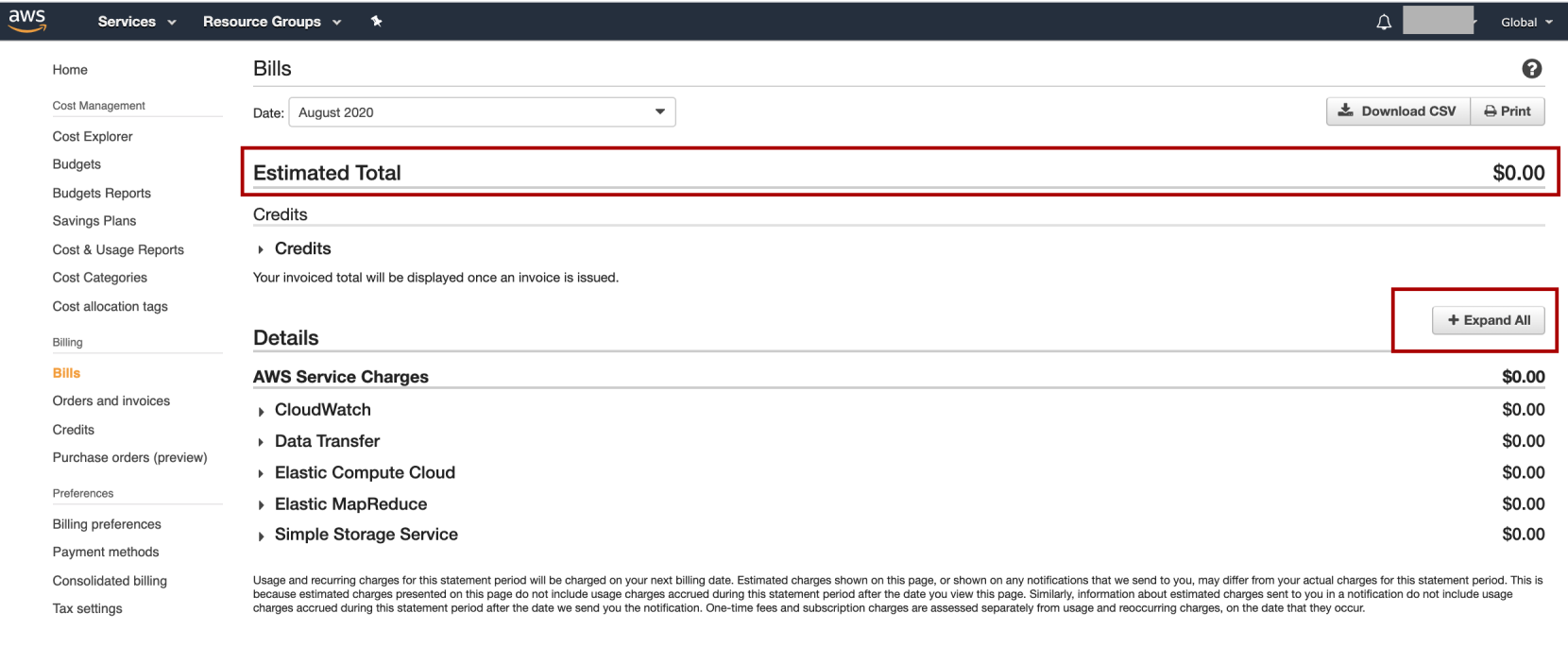
Only when one day, I click on the Expand All button, and I was in big surprise realizing my promo credit had almost gone!!! So again, what you see on the Dashboard is the balance, not the expense. Be careful when using your EMR and EC clusters. It may cost you more money than you thought. (Well, although I admit that gaining AWS experience is so worth it).
僅在一天之內,我單擊“ Expand All 按鈕,我感到驚訝的是,我的促銷信用幾乎消失了!!! 同樣,您在儀表板上看到的是余額,而不是費用。 使用EMR和EC群集時請小心。 它可能會花費您比您想象的更多的錢。 (嗯,盡管我承認獲得AWS經驗非常值得)。
Thank you so much for reading this lengthy post. I do aware that people get discouraged easily with long post, but I want to have a consolidated report for you. Good luck with your project, and I am more than happy for any discussion.
非常感謝您閱讀這篇冗長的文章。 我知道,長期任職的人很容易灰心,但我想為您提供一份綜合報告。 祝您的項目好運,對于任何討論我都非常滿意。
The Jupyter notebook version of this post, together with other tutorials on Spark and many more data science tutorials could be found on my github.
這篇文章的Jupyter筆記本版本以及Spark上的其他教程以及更多數據科學教程都可以在 我的github 上找到 。
翻譯自: https://towardsdatascience.com/some-issues-when-building-an-aws-data-lake-using-spark-and-how-to-deal-with-these-issues-529ce246ba59
aws spark
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389065.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389065.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389065.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

沖刺第三天 11.27 TUE

鎖是網絡數據庫中的一個非常重要的概念

DPDK+Pktgen 高速發包測試

python 商城api編寫_Python實現簡單的API接口
 學習通過OpenCV圖形界面及基礎)
opencv (一) 學習通過OpenCV圖形界面及基礎

python精進之路 -- open函數

數據科學家編程能力需要多好_我們不需要這么多的數據科學家
)
基于xtrabackup GDIT方式不鎖庫作主從同步(主主同步同理,反向及可)

excel表格行列顯示十字定位_WPS表格:Excel表格打印時,如何每頁都顯示標題行?...
 圖片處理)
opencv(二) 圖片處理

【NLP】語言模型和遷移學習


sql優化技巧_使用這些查詢優化技巧成為SQL向導

Day 4:集合——迭代器與List接口

oem是代工還是貼牌_代加工和貼牌加工的區別是什么

KNN 算法--圖像分類算法

java核心技術-NIO

物種分布模型_減少物種分布建模中的空間自相關
![BZOJ1014: [JSOI2008]火星人prefix](http://pic.xiahunao.cn/BZOJ1014: [JSOI2008]火星人prefix)
BZOJ1014: [JSOI2008]火星人prefix
