回歸分析預測
As per the Centers for Disease Control and Prevention report, heart disease is the prime killer of both men and women in the United States and around the globe. There are several data mining techniques that can be leveraged by researchers/ statisticians to help health care professionals determine heart disease and its potential causes. Some of the significant risk factors associated with heart disease are age, blood pressure, total cholesterol, diabetes, hypertension, family history of heart disease, obesity, lack of physical exercise, etc.
根據美國疾病控制與預防中心的報告,心臟病是美國乃至全球男女的主要殺手。 研究人員/統計人員可以利用多種數據挖掘技術來幫助醫療保健專業人員確定心臟病及其潛在原因。 與心臟病有關的一些重要危險因素是年齡,血壓,總膽固醇,糖尿病,高血壓,心臟病家族史,肥胖癥,缺乏體育鍛煉等。
In this project from Data Camp, the objective of my project is to build a regression model and run statistical tests to assess how strongly are the clinical factors associated with heart disease and how it is related to the higher probability of getting a heart disease. I shall be implementing Multiple and Logistic Regression approaches together with data explorations in ggplot and dplyr. This project uses the Cleveland heart disease dataset.
在這個來自Data Camp的項目中,我的目標是建立一個回歸模型并運行統計測試,以評估與心臟病相關的臨床因素有多強烈,以及它與患心臟病可能性更高的相關性。 我將在ggplot和dplyr中實現多元和邏輯回歸方法以及數據探索。 該項目使用克利夫蘭心臟病數據集。
Here’s a glimpse of the dataset in hand -
這是現有數據集的一瞥-
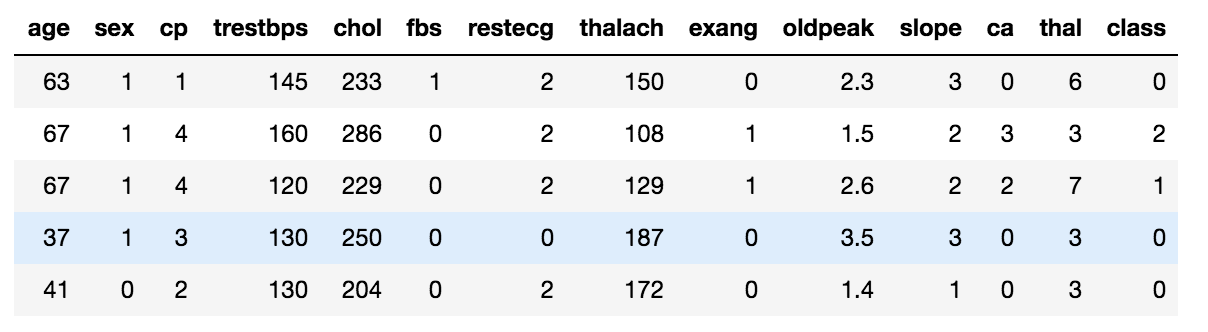
數據字典 (Data Dictionary)
There are 14 columns in the dataset which are set out as mentioned below -
數據集中有14列,其內容如下所述-
a. Age : It is a continuous data type which describes the age of the person in years.
一個。 年齡 :這是一個連續的數據類型,描述了人的年齡(以年為單位)。
b. Sex: It is a discrete data type that describes the gender of the person. Here 0 = Female and 1 = Male
b。 性別:這是描述人的性別的離散數據類型。 0 =女性,1 =男性
c. CP(Chest Pain type): It is a discrete data type that describes the chest pain type with following parameters- 1 = Typical angina; 2 = Atypical angina; 3 = Non-anginal pain ; 4 = Asymptotic
C。 CP(Chest Pain type) :這是一種離散數據類型,描述了具有以下參數的胸痛類型-1 =典型心絞痛; 2 =非典型心絞痛; 3 =非心絞痛; 4 =漸近的
d. Trestbps : It is a continuous data type which describes resting blood pressure in mm Hg
d。 Trestbps:這是一個連續數據類型,以mm Hg表示靜息血壓
e. Cholesterol: It is a continuous data type that describes the serum cholesterol in mg/dl
e。 膽固醇:這是一個連續的數據類型,以mg / dl的形式描述血清膽固醇
f. FBS: It is a discrete data type that compares the fasting blood sugar of the person with 120 mg/dl. If FBS >120 then 1 = true else 0 = false
F。 FBS:這是一種離散數據類型,用于將人的空腹血糖與120 mg / dl進行比較。 如果FBS> 120,則1 = true,否則0 = false
g. RestECG: It is a discrete data type that shows the resting ECG results where 0 = normal; 1 = ST-T wave abnormality; 2 = left ventricular hypertrophy
G。 RestECG:這是一種離散數據類型,顯示靜態 ECG結果,其中0 =正常; 1 = ST-T波異常; 2 =左心室肥大
h. Thalach: It is a continuous data type that describes the max heart rate achieved.
H。 Thalach :這是一個連續的數據類型,描述了達到的最大心率。
i. Exang: It is a discrete data type where exercise induced angina is shown by 1 = Yes and 0 = No
一世。 Exang:這是一種離散的數據類型,其中運動誘發的心絞痛顯示為1 =是和0 =否
j. Oldpeak: It is a continuous data type that shows the depression induced by exercise relative to weight
j。 Oldpeak:這是一個連續的數據類型,顯示了運動引起的相對于體重的壓抑
k. Slope: It is a discrete data type that shows us the slope of the peak exercise segment where 1= up-sloping; 2 = flat; 3 = down-sloping
k。 斜率:這是一種離散的數據類型,向我們顯示了峰值運動段的斜率,其中1 =向上傾斜; 2 =平坦; 3 =向下傾斜
l.ca: It is a continuous data type that shows us the number of major vessels colored by fluoroscopy that ranges from 0 to 3.
l。 ca:這是一個連續的數據類型,向我們顯示了通過熒光檢查顯色的主要血管數量,范圍為0到3。
m. Thal: It is a discrete data type that shows us Thalassemia where 3 = normal ; 6 = fixed defect ; 7 = reversible defect.
米 Thal:這是一種離散的數據類型,向我們顯示地中海貧血,其中3 =正常; 6 =固定缺陷; 7 =可逆缺陷。
n. Class: It is a discrete data type where diagnose class 0 = No Presence and 1 -4 is range for the person to have the heart disease from least likely to most likely, 1 being least likely.
。 類別:它是一種離散的數據類型,其中診斷類別0 =無狀態,而1 -4是該人患心臟病的范圍,從最不可能到最可能,從1到最不可能。
數據整理 (Data Wrangling)
Since the outcome variable class has more than 2 levels; I created a new variable hd using mutate() to represent binary 0/1 outcome where any value > 0 shall be 1 and all 0 values will stay 0. Also, I renamed sex levels (originally 1 and 0) as Male/ Female for better clarity.
由于結果變量類具有兩個以上的級別; 我使用mutate()創建了一個新變量hd來表示二進制0/1結果,其中任何值> 0都應為1,所有0值都將保持為0。此外,我將性別級別(最初為1和0)重命名為Male / Female更好的清晰度。
統計檢驗 (Statistical Tests)
I ran statistical tests to check which predictor variables are closely related to heart disease. Depending on the data type (continuous/ discrete), I implemented t-test and chi-squared test to derive p-values.
我進行了統計測試,以檢查哪些預測變量與心臟病密切相關。 根據數據類型(連續/離散),我實施了t檢驗和卡方檢驗以得出p值。
In this project, I examined how sex, age and thalach are related to heart disease which is as shown below -
在這個專案中,我檢查了性別,年齡和下丘腦與心臟病的關系,如下所示-
→ Sex: Since sex is a binary variable in this dataset, chi-squared test will be the appropriate test for this variable. Here’s the output on using chisq.test() to assess the relationship between sex and hd(outcome variable)
→Sex :由于sex是此數據集中的二進制變量,因此卡方檢驗將是此變量的適當檢驗。 這是使用chisq.test()評估性別和hd(結果變量)之間關系的輸出
data: hd_data$sex and hd_data$hd
X-squared = 22.043, df = 1, p-value = 2.667e-06→ Age: Since age is a continuous variable, I used t.test() to determine relationship between age and hd.
→ 年齡:由于年齡是一個連續變量,因此我使用t.test()來確定年齡和高清之間的關系。
data: hd_data$age by hd_data$hd
t = -4.0303, df = 300.93, p-value = 7.061e-05→ Thalach: Using t.test() again to assess relationship between thalach and hd.
→ Thalach :再次使用t.test()來評估thalach和hd之間的關系。
data: hd_data$thalach by hd_data$hd
t = 7.8579, df = 272.27, p-value = 9.106e-14圖形化的關聯顯示(因為每張圖片都講述了一個更好的故事!) (Graphical visualization of the associations (Because every picture tells a better story!))
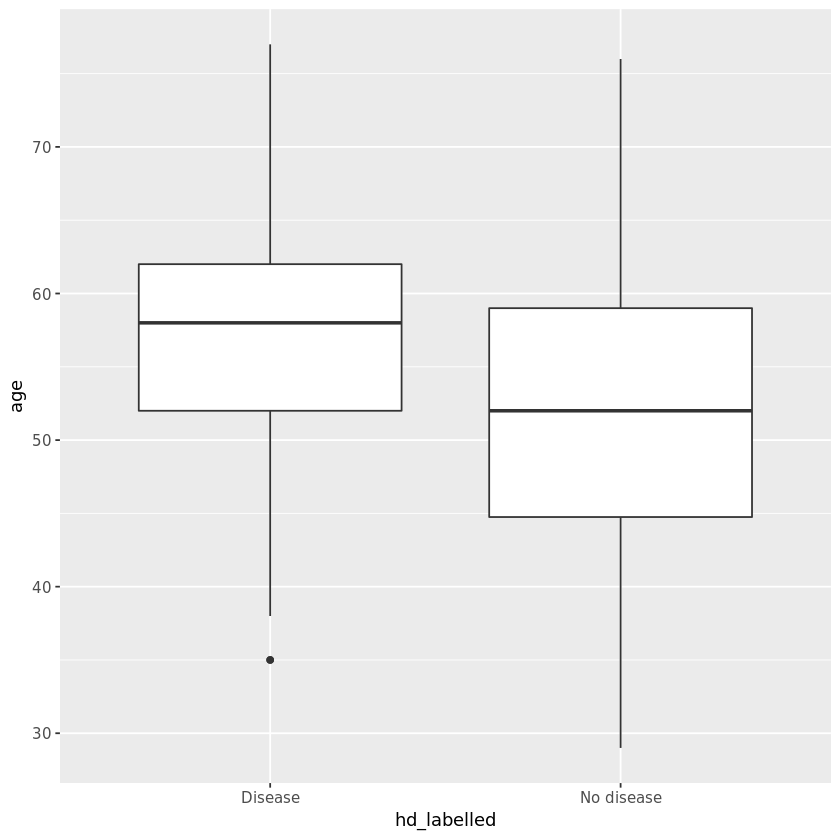
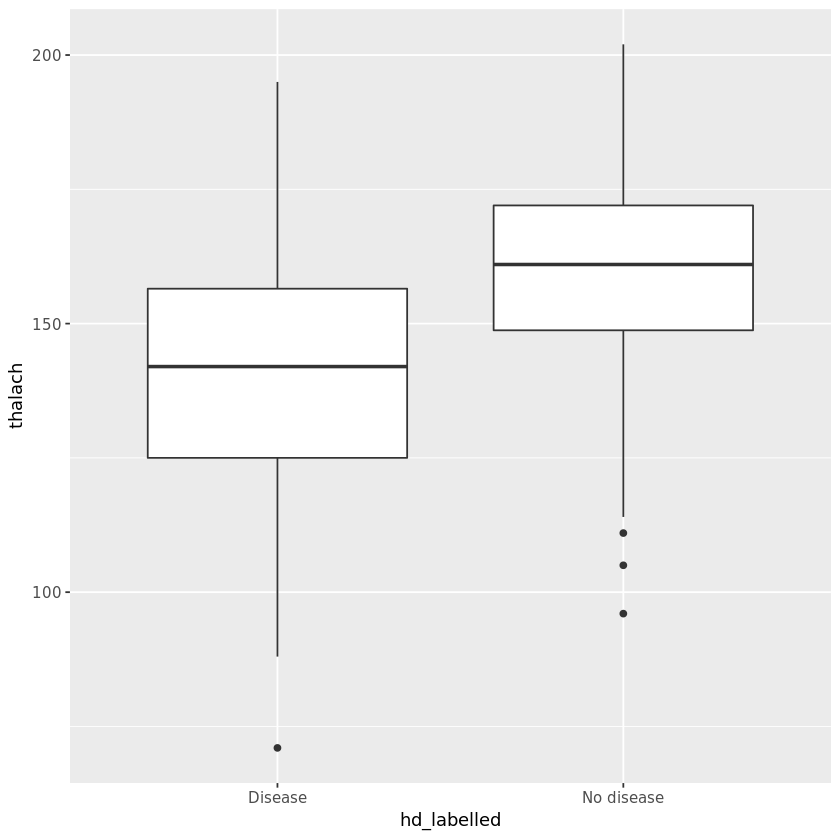
I have plotted boxplot for continuous variables like Age and Thalach (max heart rate).
我為連續變量(例如Age和Thalach(最大心率))繪制了箱線圖 。
Plotted Barplot for sex since it’s a binary variable in this dataset.
為性別繪制Barplot,因為它是此數據集中的二進制變量。
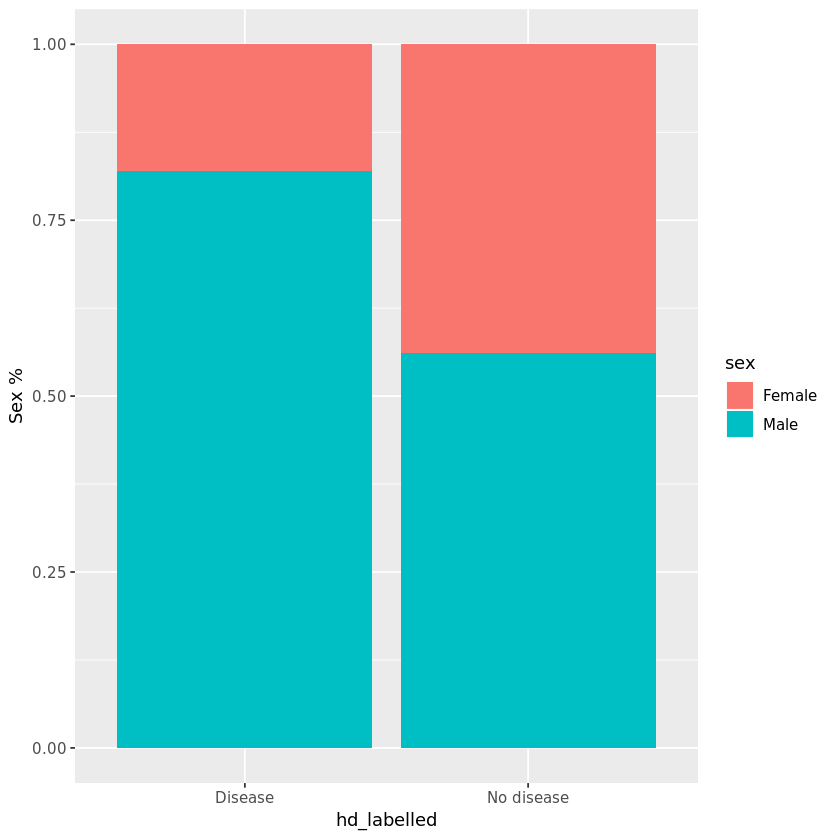
→ The graphical plots above and statistical tests clearly show us that all the three clinical variables (Age, Sex, Thalach) that were chosen are significantly associated with our outcome since p-value < 0.001 for all the tests.
→上面的圖形圖和統計測試清楚地向我們表明,選擇的所有三個臨床變量(年齡,性別,Thalach)均與我們的結果顯著相關,因為所有測試的p值<0.001。
用所有3個變量擬合Logistic回歸模型 (Fitting Logistic Regression Model with all 3 variables)
I have fitted a Logistic Regression model here since there are two predicting variables and one binary outcome variable. This model will help us determine the effect that a max heart rate (thalach), age and sex can have on the likelihood that an individual will have a heart disease.
由于這里有兩個預測變量和一個二進制結果變量,因此我在這里擬合了Logistic回歸模型。 該模型將幫助我們確定最大心率(thalach),年齡和性別對個人患心臟病的可能性的影響。
model <- glm(data = hd_data, hd ~ age + sex + thalach, family = “binomial” )
模型<-glm(數據= hd_data,hd?年齡+性別+觸角,家庭=“二項式”)
# extract the model summarysummary(model)
#提取模型summarysummary(model)
Here’s the output as shown below after implementing the model -
實施模型后,輸出如下所示-
Call:
glm(formula = hd ~ age + sex + thalach, family = "binomial",
data = hd_data)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.2250 -0.8486 -0.4570 0.9043 2.1156
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.111610 1.607466 1.936 0.0529 .
age 0.031886 0.016440 1.940 0.0524 .
sexMale 1.491902 0.307193 4.857 1.19e-06 ***
thalach -0.040541 0.007073 -5.732 9.93e-09 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)This logistic regression model can be used to predict the probability of a person having heart disease given his/her age, sex and max heart rate. Additionally, we can translate the predicted probability into a decision rule for clinical use by defining cutoff value on the probability scale. For instance- if a 45 year old female patient with a max heart rate = 150 walks in, we can find out the predicted probability of the heart disease by creating a new data frame called newdata.
鑒于年齡,性別和最大心率,該邏輯回歸模型可用于預測某人患心臟病的可能性。 此外,我們可以通過在概率標度上定義臨界值將預測的概率轉換為臨床使用的決策規則。 例如,如果一名最大心率= 150的45歲女性患者走進來,我們可以通過創建一個稱為newdata的新數據框來找到心臟病的預測概率。

We can see that the model generated a heart disease probability of 0.177 for a 45 year old female with a max heart rate of 150 which indicates a low risk of heart disease.
我們可以看到,該模型為45歲女性,最大心率150產生的心臟病概率為0.177 ,這表明患心臟病的風險較低。
評估模型性能 (Evaluating model performance)
While these predictive models can be used to predict the probability of an event occurring, it is vital to check the accuracy of any model before computing the predicted values. Some of the core metrics that can be used to evaluate this model are as described below-
盡管這些預測模型可用于預測事件發生的可能性,但在計算預測值之前檢查任何模型的準確性至關重要。 可以用來評估該模型的一些核心指標如下所述:
Accuracy : It is one of the most straightforward metric which tells us the proportion of total number of predictions being correct
準確性 :這是最直接的指標之一,它告訴我們正確的預測總數中所占的比例
Classification Error Rate : This can be calculated using 1-Accuracy
分類錯誤率:可以使用1-Accuracy計算
Area under the ROC curve (AUC): This is one of the most sought after metrics used for evaluation. It is popular since it is independent of the change in proportion of responders. It ranges from 0–1. The closer it gets to 1, the better is the model performance
ROC曲線下的面積(AUC):這是用于評估的最受歡迎的指標之一。 它之所以受歡迎是因為它與響應者比例的變化無關。 取值范圍是0-1。 越接近1,模型性能越好
Confusion Matrix: It is a N*N matrix where N is the level of outcome.This metric reports the the number of false positives, false negatives, true positives, and true negatives.
混淆矩陣:這是一個N * N矩陣,其中N是結果水平。此度量標準報告誤報,誤報,真報和真報錯的數量。
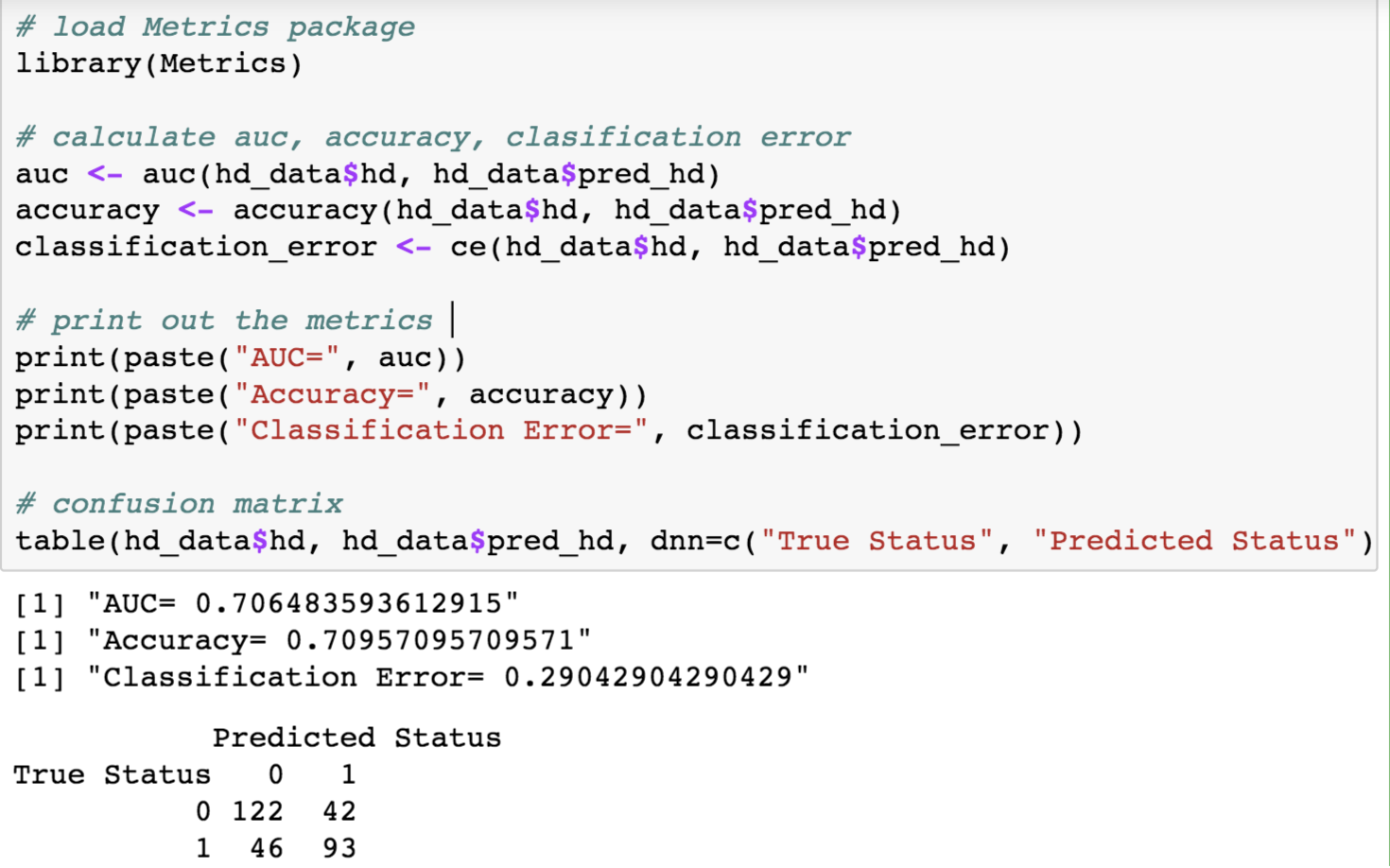
結果 (Result)
From the above output, we can see that the model has an overall accuracy of 0.71. Also, there are cases that were misclassified as shown in the confusion matrix. We can improve the existing model by including other relevant predictors from the dataset into our model.
從上面的輸出中,我們可以看到該模型的整體精度為0.71。 而且,有些情況下分類錯誤,如混淆矩陣中所示。 我們可以通過將數據集中的其他相關預測變量納入模型來改善現有模型。
You can find the entire code of this project on my Github.
您可以在我的Github上找到該項目的全部代碼。
Disclaimer: This project has been done solely for educational motives and to solidify my understanding of data mining techniques. It is not intended to be used for diagnosis of actual heart patients. Please consult your healthcare practitioner for professional advice.
免責聲明:此項目僅出于教育目的而進行,目的是鞏固我對數據挖掘技術的理解。 它不能用于診斷實際的心臟病患者。 請咨詢您的醫療保健從業人員以獲取專業建議。
翻譯自: https://medium.com/swlh/predicting-heart-disease-using-regression-analysis-486401cd0a47
回歸分析預測
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389072.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389072.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389072.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

)

UDP打洞程序包的源碼

NLPPython筆記——WordNet

crc16的c語言函數 計算ccitt_C語言為何如此重要

毫米波雷達與激光雷達的初探

aws spark_使用Spark構建AWS數據湖時的一些問題以及如何處理這些問題

沖刺第三天 11.27 TUE

鎖是網絡數據庫中的一個非常重要的概念

DPDK+Pktgen 高速發包測試

python 商城api編寫_Python實現簡單的API接口
 學習通過OpenCV圖形界面及基礎)
opencv (一) 學習通過OpenCV圖形界面及基礎

python精進之路 -- open函數

數據科學家編程能力需要多好_我們不需要這么多的數據科學家
)
基于xtrabackup GDIT方式不鎖庫作主從同步(主主同步同理,反向及可)

excel表格行列顯示十字定位_WPS表格:Excel表格打印時,如何每頁都顯示標題行?...
 圖片處理)
opencv(二) 圖片處理

【NLP】語言模型和遷移學習

