圖卷積 節點分類
This article goes through the implementation of Graph Convolution Networks (GCN) using Spektral API, which is a Python library for graph deep learning based on Tensorflow 2. We are going to perform Semi-Supervised Node Classification using CORA dataset, similar to the work presented in the original GCN paper by Thomas Kipf and Max Welling (2017).
本文介紹了使用 Spektral API 實現圖卷積網絡(GCN)的情況 ,這是一個基于Tensorflow 2的用于圖深度學習的Python庫。我們將使用CORA數據集執行半監督節點分類,與所介紹的工作類似在 Thomas Kipf和Max Welling(2017) 的原始GCN論文中 。
If you want to get basic understanding on Graph Convolutional Networks, it is recommended to read the first and the second parts of this series beforehand.
如果您想對圖卷積網絡有基本的了解,建議您 事先 閱讀 本系列 的 第一 和 第二 部分。
數據集概述 (Dataset Overview)
CORA citation network dataset consists of 2708 nodes, where each node represents a document or a technical paper. The node features are bag-of-words representation that indicates the presence of a word in the document. The vocabulary — hence, also the node features — contains 1433 words.
CORA引用網絡數據集由2708個節點組成,其中每個節點代表一個文檔或技術論文。 節點特征是詞袋表示,指示文檔中單詞的存在。 詞匯表-因此,還有節點特征-包含1433個單詞。

We will treat the dataset as an undirected graph where the edge represents whether one document cites the other or vice versa. There is no edge feature in this dataset. The goal of this task is to classify the nodes (or the documents) into 7 different classes which correspond to the papers’ research areas. This is a single-label multi-class classification problem with Single Mode data representation setting.
我們將數據集視為無向圖 ,其中邊表示一個文檔引用了另一文檔,反之亦然。 該數據集中沒有邊緣特征。 此任務的目標是將節點(或文檔)分類為7種不同的類別,分別對應于論文的研究領域。 這是一個單標簽多類別分類問題 單模式數據表示設置。
This implementation is also an example of Transductive Learning, where the neural network sees all data, including the test dataset, during the training. This is contrast to Inductive Learning — which is the typical Supervised Learning — where the test data is kept separate during the training.
此實現方式也是Transductive Learning的示例,在訓練過程中,神經網絡可以查看所有數據,包括測試數據集。 這與歸納學習(典型的監督學習)相反,歸納學習在訓練過程中將測試數據保持獨立。
文字分類問題 (Text Classification Problem)
Since we are going to classify documents based on their textual features, a common machine learning way to look at this problem is by seeing it as a supervised text classification problem. Using this approach, the machine learning model will learn each document’s hidden representation only based on its own features.
由于我們將根據文檔的文本特征對文檔進行分類,因此,解決此問題的一種常見的機器學習方法是將其視為有監督的文本分類問題。 使用這種方法,機器學習模型將僅基于自身的功能來學習每個文檔的隱藏表示。
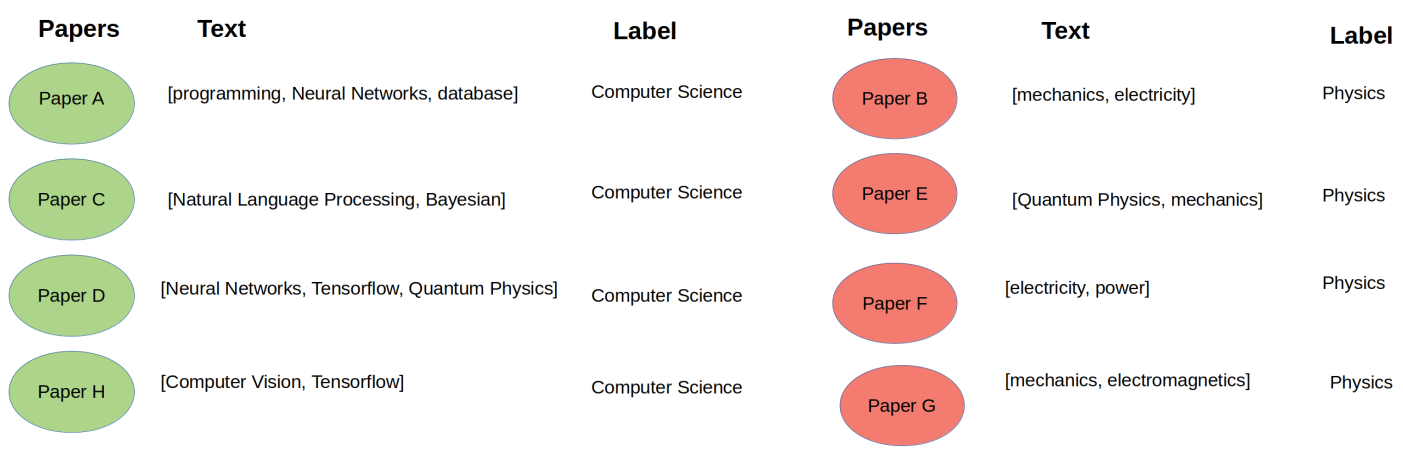
This approach might work well if there are enough labeled examples for each class. Unfortunately, in real world cases, labeling data might be expensive.
如果每個類都有足夠的帶標簽的示例,則此方法可能會很好用。 不幸的是,在現實情況下,標記數據可能會很昂貴。
What is another approach to solve this problem?
解決此問題的另一種方法是什么?
Besides its own text content, normally, a technical paper also cites other related papers. Intuitively, the cited papers are likely to belong to similar research area.
除了自身的文本內容外,技術論文通常還會引用其他相關論文。 從直覺上講,被引論文可能屬于相似的研究領域。
In this citation network dataset, we want to leverage the citation information from each paper in addition to its own textual content. Hence, the dataset has now turned into a network of papers.
在這個引文網絡數據集中,我們希望利用每篇論文的引文信息以及自己的文本內容。 因此,數據集現在變成了論文網絡。
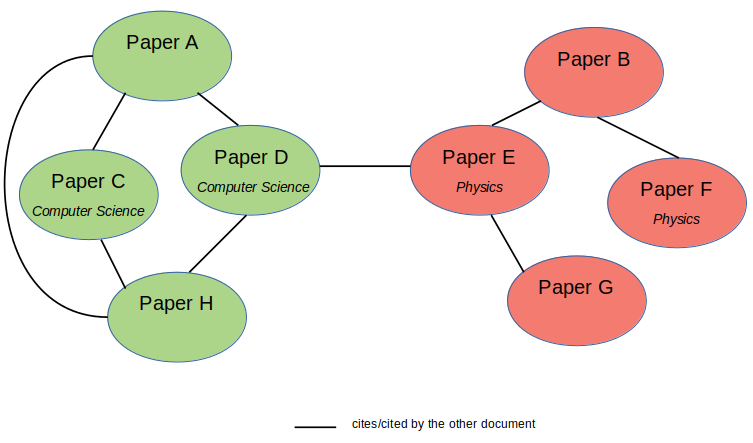
Using this configuration, we can utilize Graph Neural Networks, such as Graph Convolutional Networks (GCNs), to build a model that learns the documents interconnection in addition to their own textual features. The GCN model will learn the nodes (or documents) hidden representation not only based on its own features, but also its neighboring nodes’ features. Hence, we can reduce the number of necessary labeled examples and implement semi-supervised learning utilizing the Adjacency Matrix (A) or the nodes connectivity within a graph.
使用此配置,我們可以利用諸如圖卷積網絡(GCN)之類的圖神經網絡來構建一個模型,該模型除了學習其自身的文本特征外,還可以學習文檔的互連。 GCN模型將不僅基于其自身的特征,而且還基于其鄰近節點的特征,來學習節點(或文檔)的隱藏表示。 因此,我們可以減少必要的帶標簽示例的數量,并利用鄰接矩陣(A)進行半監督學習 或圖中的節點連通性。
Another case where Graph Neural Networks might be useful is when each example does not have distinct features on its own, but the relations between the examples can enrich the feature representations.
圖神經網絡可能有用的另一種情況是,每個示例自身都不具有明顯的特征,但是示例之間的關系可以豐富特征表示。
圖卷積網絡的實現 (Implementation of Graph Convolutional Networks)
加載和解析數據集 (Loading and Parsing the Dataset)
In this experiment, we are going to build and train a GCN model using Spektral API that is built on Tensorflow 2. Although Spektral provides built-in functions to load and preprocess CORA dataset, in this article we are going to download the raw dataset from here in order to gain deeper understanding on the data preprocessing and configuration. The complete code of the whole exercise in this article can be found on GitHub.
在此實驗中,我們將使用基于Tensorflow 2構建的Spektral API來構建和訓練GCN模型。盡管Spektral提供了內置功能來加載和預處理CORA數據集,但在本文中,我們將從以下位置下載原始數據集: 在這里 ,以獲得對數據預處理和配置更深入的了解。 本文整個練習的完整代碼可以在GitHub上找到 。
We use cora.content and cora.cites files in the respective data directory. After loading the files, we will randomly shuffle the data.
我們在各自的數據目錄中使用cora.content和cora.cites文件。 加載文件后,我們將隨機重新整理數據。
In cora.content file, each line consists of several elements:the first element indicates the document (or node) ID,the second until the last second elements indicate the node features,the last element indicates the label of that particular node.
在cora.content文件中,每一行包含幾個元素:第一個元素指示文檔(或節點)ID, 第二個直到最后一個第二元素指示節點特征, 最后一個元素指示該特定節點的標簽。
In cora.cites file, each line contains a tuple of documents (or nodes) IDs. The first element of the tuple indicates the ID of the paper being cited, while the second element indicates the paper containing the citation. Although this configuration represents a directed graph, in this approach we treat the dataset as an undirected graph.
在cora.cites文件中,每行包含一個文檔(或節點)ID的元組。 元組的第一個元素指示被引用論文的ID ,而第二個元素指示包含被引用論文 。 盡管此配置表示有向圖,但是在這種方法中,我們將數據集視為無向圖 。
After loading the data, we build Node Features Matrix (X) and a list containing tuples of adjacent nodes. This edges list will be used to build a graph from where we can obtain the Adjacency Matrix (A).
加載數據后,我們構建節點特征矩陣( X )和一個包含相鄰節點元組的列表。 此邊緣列表將用于構建圖,從中可以獲取鄰接矩陣( A )。
Output:
輸出:

設置訓練,驗證和測試掩碼 (Setting the Train, Validation, and Test Mask)
We will feed in the Node Features Matrix (X) and Adjacency Matrix (A) to the neural networks. We are also going to set Boolean masks with a length of N for each training, validation, and testing dataset. The elements of those masks are True when they belong to corresponding training, validation, or test dataset. For example, the elements of train mask are True for those which belong to training data.
我們將節點特征矩陣( X )和鄰接矩陣( A )饋入神經網絡。 我們還將為每個設置長度為N的 布爾掩碼 訓練,驗證和測試數據集。 這些遮罩的元素屬于相應的訓練,驗證或測試數據集時,它們為True 。 例如,對于屬于訓練數據的那些元素,訓練蒙版的元素為True 。
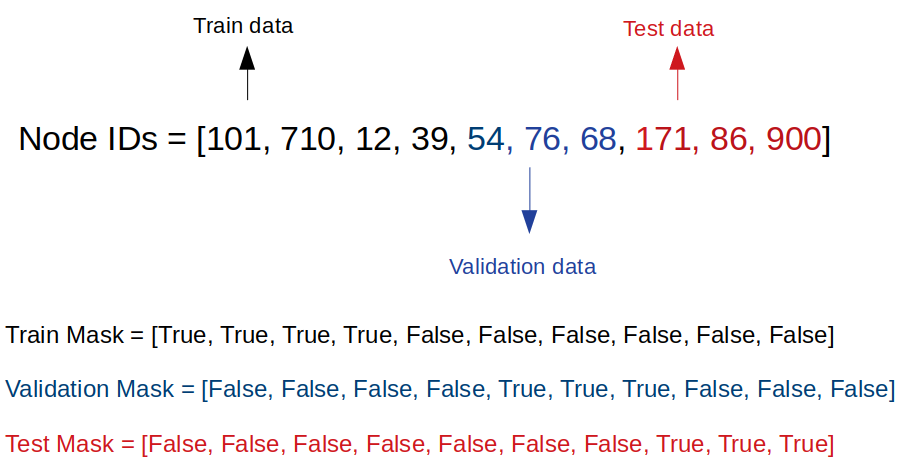
In the paper, they pick 20 labeled examples for each class. Hence, with 7 classes, we will have a total of 140 labeled training examples. We will also use 500 labeled validation examples and 1000 labeled testing examples.
在本文中,他們為每個班級選取20個帶有標簽的示例。 因此,通過7個課程,我們將總共有140個帶有標簽的培訓示例。 我們還將使用500個帶標簽的驗證示例和1000個帶標簽的測試示例。
獲取鄰接矩陣 (Obtaining the Adjacency Matrix)
The next step is to obtain the Adjacency Matrix (A) of the graph. We use NetworkX to help us do this. We will initialize a graph and then add the nodes and edges lists to the graph.
下一步是獲取圖的鄰接矩陣( A )。 我們使用NetworkX來幫助我們做到這一點。 我們將初始化一個圖,然后將節點和邊列表添加到圖中。
Output:
輸出:

將標簽轉換為一鍵編碼 (Converting the label to one-hot encoding)
The last step before building our GCN is, just like any other machine learning model, encoding the labels and then converting them to one-hot encoding.
與其他任何機器學習模型一樣,構建GCN之前的最后一步是對標簽進行編碼,然后將其轉換為一次性編碼。
We are now done with data preprocessing and ready to build our GCN!
現在,我們已經完成了數據預處理,并準備構建我們的GCN!
建立圖卷積網絡 (Build the Graph Convolutional Networks)
The GCN model architectures and hyperparameters follow the design from GCN original paper. The GCN model will take 2 inputs, the Node Features Matrix (X) and Adjacency Matrix (A). We are going to implement 2-layer GCN with Dropout layers and L2 regularization. We are also going to set the maximum training epochs to be 200 and implement Early Stopping with patience of 10. It means that the training will be stopped once the validation loss does not decrease for 10 consecutive epochs. To monitor the training and validation accuracy and loss, we are also going to call TensorBoard in the callbacks.
GCN模型的體系結構和超參數遵循GCN原始論文的設計。 GCN模型將采用2個輸入,即節點特征矩陣( X )和鄰接矩陣( A )。 我們將使用 Dropout層和 L2正則化實現2層GCN 。 我們還將最大訓練時間設為200,并以10的耐心實施“ 提前停止” 。 這意味著一旦驗證損失連續10個周期沒有減少,訓練就會停止。 為了監控訓練和驗證的準確性和損失,我們還將在回調中調用TensorBoard 。
Before feeding in the Adjacency Matrix (A) to the GCN, we need to do extra preprocessing by performing renormalization trick according to the original paper. You can also read about how renormalization trick affects GCN forward propagation calculation here.
在將鄰接矩陣( A )輸入到GCN之前,我們需要根據原始論文通過執行重新規范化技巧來進行額外的預處理。 您還可以閱讀有關重歸一化技巧如何影響GCN前向傳播計算的信息 在這里 。
The code to train GCN below was originally obtained from Spektral GitHub page.
下面訓練GCN的代碼最初是從Spektral GitHub頁面獲得的。
訓練圖卷積網絡 (Train the Graph Convolutional Networks)
We are implementing Transductive Learning, which means we will feed the whole graph to both training and testing. We separate the training, validation, and testing data using the Boolean masks we have constructed before. These masks will be passed to sample_weight argument. We set the batch_size to be the whole graph size, otherwise the graph will be shuffled.
我們正在實施“歸納式學習”,這意味著我們將把整個圖表饋送給培訓和測試。 我們使用之前構造的布爾掩碼將訓練,驗證和測試數據分開。 這些掩碼將傳遞給sample_weight參數。 我們將batch_size設置為整個圖的大小,否則該圖將被重新排序。
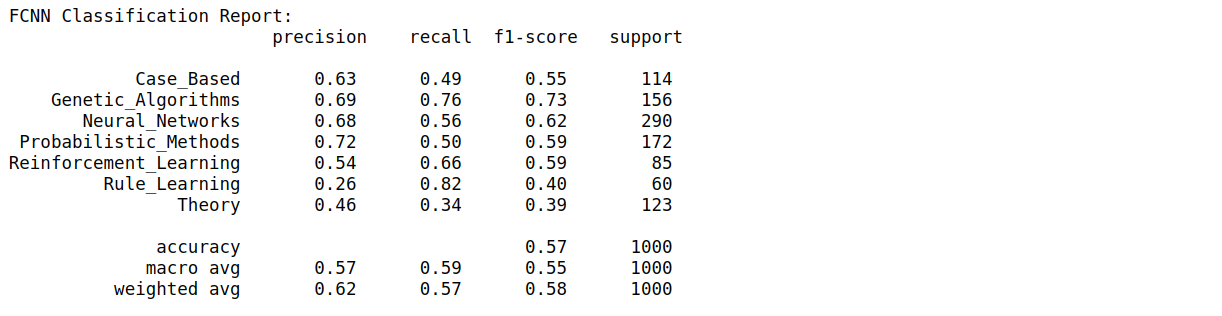
To better evaluate the model performance for each class, we use F1-score instead of accuracy and loss metrics.
為了更好地評估每個類別的模型性能,我們使用F1評分而不是準確性和損失指標。
Training done!
培訓完成!
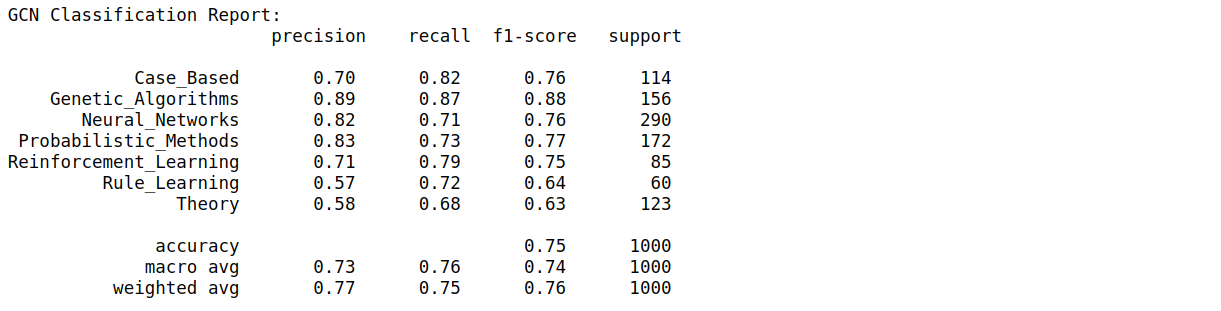
From the classification report, we obtain macro average F1-score of 74%.
從分類報告中,我們獲得74%的宏觀平均F1得分。
使用t-SNE的隱藏層激活可視化 (Hidden Layers Activation Visualization using t-SNE)
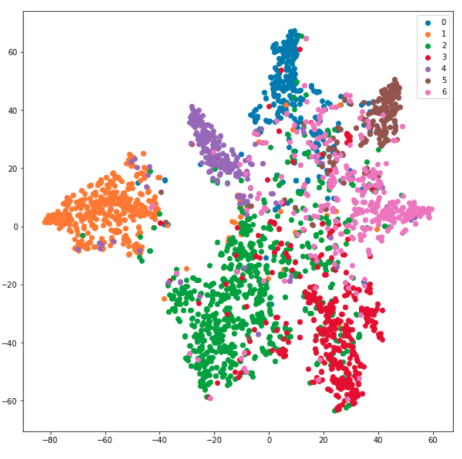
Let’s now use t-SNE to visualize the hidden layer representations. We use t-SNE to reduce the dimension of the hidden representations to 2-D. Each point in the plot represents each node (or document), while each color represents each class.
現在讓我們使用t-SNE可視化隱藏層表示。 我們使用t-SNE將隱藏表示的尺寸減小為2D。 圖中的每個點代表每個節點(或文檔),而每種顏色代表每個類別。
Output:
輸出:
與完全連接的神經網絡的比較 (Comparison to Fully Connected Neural Networks)
As a benchmark, I also trained a 2-layer Fully Connected Neural Networks (FCNN) and plot the t-SNE visualization of hidden layer representations. The results are shown below:
作為基準,我還訓練了2層全連接神經網絡(FCNN),并繪制了隱藏層表示的t-SNE可視化。 結果如下所示:
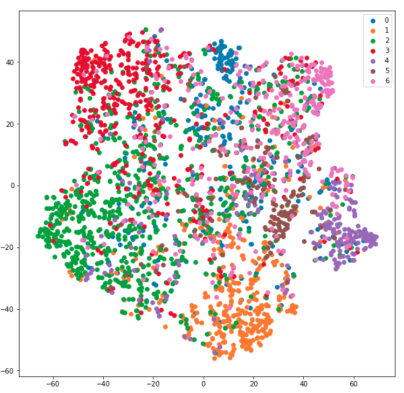
From the results above, it is clear that GCN significantly outperforms FCNN with macro average F1-score is only 55%. The t-SNE visualization plot of FCNN hidden layer representations is scattered, which means that FCNN can’t learn the features representations as well as GCN.
從以上結果可以明顯看出,GCN的性能明顯優于FCNN,宏觀平均F1得分僅為55%。 FCNN隱藏層表示的t-SNE可視化圖是分散的,這意味著FCNN無法像GCN一樣學習特征表示。
結論 (Conclusion)
The conventional machine learning approach to perform document classification, for example CORA dataset, is to use supervised text classification approach. Graph Convolutional Networks (GCNs) is an alternative semi-supervised approach to solve this problem by seeing the documents as a network of related papers. Using only 20 labeled examples for each class, GCNs outperform Fully-Connected Neural Networks on this task by around 20%.
執行文檔分類的常規機器學習方法(例如CORA數據集)是使用監督文本分類方法。 圖卷積網絡(GCN)是通過將文檔視為相關論文的網絡來解決此問題的另一種半監督方法。 對于每個類別,僅使用20個帶有標簽的示例,GCN在此任務上的性能就比全連接神經網絡高出約20%。
Thanks for reading! I hope this article helps you implement Graph Convolutional Networks (GCNs) on your own problems.
謝謝閱讀! 我希望本文能幫助您針對自己的問題實現圖卷積網絡(GCN)。
Any comment, feedback, or want to discuss? Just drop me a message. You can reach me on LinkedIn.
有任何意見,反饋或要討論嗎? 請給我留言。 您可以在 LinkedIn上與 我聯系 。
You can find the full code on GitHub.
您可以在 GitHub上 找到完整的代碼 。
翻譯自: https://towardsdatascience.com/graph-convolutional-networks-on-node-classification-2b6bbec1d042
圖卷積 節點分類
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389076.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389076.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389076.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
![[微信小程序] 當動畫(animation)遇上延時執行函數(setTimeout)出現的問題](http://pic.xiahunao.cn/[微信小程序] 當動畫(animation)遇上延時執行函數(setTimeout)出現的問題)
[微信小程序] 當動畫(animation)遇上延時執行函數(setTimeout)出現的問題

關于使用pdf.js預覽pdf的一些問題

SqlHelper改造版本

回歸分析預測_使用回歸分析預測心臟病。

)

UDP打洞程序包的源碼

NLPPython筆記——WordNet

crc16的c語言函數 計算ccitt_C語言為何如此重要

毫米波雷達與激光雷達的初探

aws spark_使用Spark構建AWS數據湖時的一些問題以及如何處理這些問題

沖刺第三天 11.27 TUE

鎖是網絡數據庫中的一個非常重要的概念

DPDK+Pktgen 高速發包測試

python 商城api編寫_Python實現簡單的API接口
 學習通過OpenCV圖形界面及基礎)
opencv (一) 學習通過OpenCV圖形界面及基礎

python精進之路 -- open函數

數據科學家編程能力需要多好_我們不需要這么多的數據科學家
)
基于xtrabackup GDIT方式不鎖庫作主從同步(主主同步同理,反向及可)
