tidb數據庫
This article is based on a talk given by Tianshuang Qin at TiDB DevCon 2020.
本文基于Tianshuang Qin在 TiDB DevCon 2020 上的演講 。
When we convert from a standalone system to a distributed one, one of the challenges is migrating the database. We’re faced with questions such as:
當我們從獨立系統轉換為分布式系統時,挑戰之一就是遷移數據庫。 我們面臨的問題包括:
- Should I migrate full or incremental data? 我應該遷移完整數據還是增量數據?
- Should I perform an online or offline migration? 我應該執行在線還是離線遷移?
- Should I use a ready-made data replication tool or develop a new one? 我應該使用現成的數據復制工具還是開發新工具?
When it comes to data migration, users are often faced with many options. At PingCAP, we’ve probably tried most of them. Over the years, we’ve migrated many heterogeneous databases between different database platforms and application scenarios. Today, I’ll save you some time by sharing with you the approaches that worked best.
當涉及數據遷移時,用戶通常面臨許多選擇。 在PingCAP,我們可能已經嘗試了大多數。 多年來,我們已經在不同的數據庫平臺和應用程序場景之間遷移了許多異構數據庫。 今天,我將與您分享最有效的方法,為您節省一些時間。
典型的數據庫遷移過程 (A typical database migration process)
1.應用適應開發 (1. Application adaptation development)
Almost all early TiDB users have gone through this step. In version 3.0 or earlier, TiDB supports optimistic concurrency control and Repeatable Read (RR) isolation level, and its transaction size is limited to about 100 MB. Given these features and capacity, users need to put a lot of effort into adapting their applications. In contrast, TiDB 4.0 supports pessimistic concurrency control, Read Committed (RC) isolation, and large transactions with a maximum size of 10 GB. Users can adapt their applications to TiDB at a much lower cost.
幾乎所有早期的TiDB用戶都經歷了這一步驟。 在版本3.0或更早版本中,TiDB支持開放式并發控制和可重復讀取(RR)隔離級別,并且其事務大小限制為大約100 MB。 鑒于這些功能和功能,用戶需要花很多精力來適應他們的應用程序。 相比之下,TiDB 4.0支持悲觀并發控制,讀取提交(RC)隔離和最大10 GB的大型事務。 用戶可以以更低的成本使其應用程序適應TiDB。
2.應用驗證測試 (2. Application verification testing)
There are two ways to perform application verification testing. You can combine the two methods to effectively verify your application.
有兩種執行應用程序驗證測試的方法。 您可以結合使用這兩種方法來有效地驗證您的應用程序。
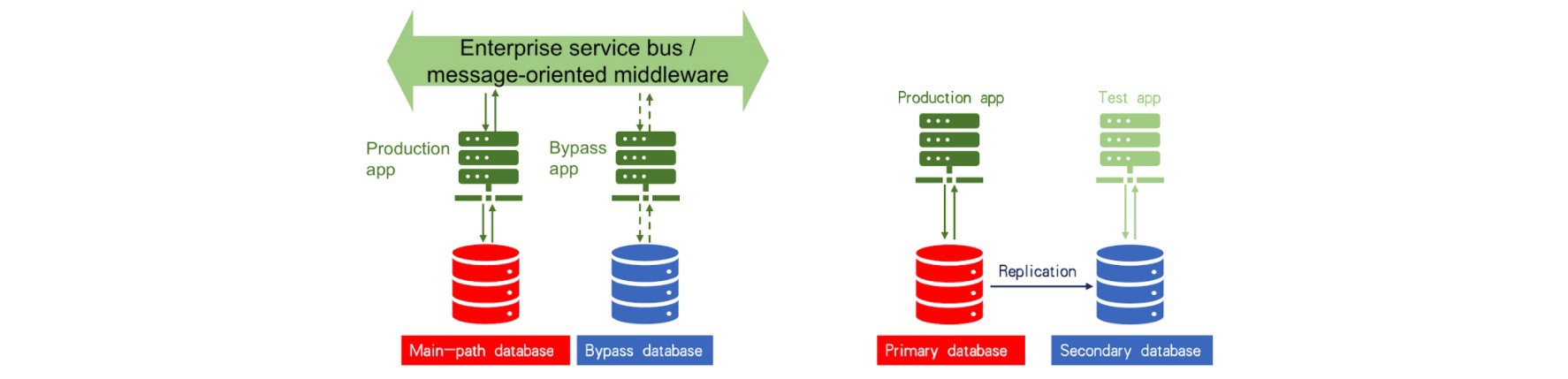
The first method is to test your application with production data. To do this, you must first use database replication technology to replicate the data from the production database to TiDB. Then, you use a testing application to perform a stress test. To stress TiDB and ensure that it will be stable in your production environment, apply a workload 10 to 20 times higher than your real production traffic. One of the advantages of replicating data from the production database to TiDB is that you avoid wide variations between test data and production data, which may cause many problems. For example, an SQL query, which has been tuned in the testing environment to achieve its highest performance, may become a slow SQL query in the production environment if the data is not replicated to TiDB for testing.
第一種方法是使用生產數據測試您的應用程序。 為此,您必須首先使用數據庫復制技術將數據從生產數據庫復制到TiDB。 然后,使用測試應用程序執行壓力測試。 為了給TiDB施加壓力并確保它在生產環境中穩定,請施加比實際生產流量高10到20倍的工作負載。 將數據從生產數據庫復制到TiDB的優點之一是,避免了測試數據和生產數據之間的巨大差異,這可能會引起許多問題。 例如,如果未將數據復制到TiDB進行測試,則已在測試環境中進行了調整以實現其最高性能SQL查詢在生產環境中可能會成為緩慢SQL查詢。
The second way to verify your application is to test it with production traffic. In this case, you must adopt a service bus similar to the enterprise service bus (ESB) for banks or message queuing technology. For example, you can use the Kafka message queuing mechanism to implement the multi-path replication of production traffic. Whether an application can successfully run in the production environment depends on the main path of the existing production database. There is also a bypass for the application. We can load an application that has been adapted to TiDB on the bypass and connect the application to TiDB for application verification.
驗證應用程序的第二種方法是使用生產流量對其進行測試。 在這種情況下,您必須為銀行或消息排隊技術采用類似于企業服務總線(ESB)的服務總線。 例如,您可以使用Kafka消息排隊機制來實現生產流量的多路徑復制。 應用程序能否在生產環境中成功運行取決于現有生產數據庫的主要路徑。 該應用程序還有一個旁路。 我們可以在旁路上加載適合TiDB的應用程序,并將該應用程序連接到TiDB以進行應用程序驗證。
3.遷移測試 (3. Migration testing)
Migration testing mainly involves verifying operations completed during the maintenance window. For example, you must follow the migration activity specified in the migration manual in advance to verify that the manual is correct and to determine whether the migration maintenance window is long enough to perform the migration. You also need to perform rollback testing, because if your deployment to production fails, you may need to roll back to the previous database.
遷移測試主要涉及驗證在維護時段內完成的操作。 例如,您必須事先遵循遷移手冊中指定的遷移活動,以驗證該手冊是否正確,并確定遷移維護窗口是否足夠長以執行遷移。 您還需要執行回滾測試,因為如果到生產的部署失敗,則可能需要回滾到先前的數據庫。
4.數據遷移和生產數據庫切換 (4. Data migration and production database switch)
Your applications may run 24/7 or you may only have a short maintenance window to switch over databases, so you must migrate your data before the maintenance window ends. To do that, you must use heterogeneous database replication technology. During the maintenance window, you can stop all running applications, replicate incremental data to the secondary database, perform a comparison to ensure that the secondary database is synchronized with the primary database, and then verify applications. Once the application verification testing is completed, database switchover starts. If the switchover is successful, TiDB will run as a primary database in the production environment.
您的應用程序可能運行24/7,或者您只有一個短暫的維護窗口來切換數據庫,因此您必須在維護窗口結束之前遷移數據。 為此,您必須使用異構數據庫復制技術。 在維護窗口期間,您可以停止所有正在運行的應用程序,將增量數據復制到輔助數據庫,進行比較以確保輔助數據庫與主數據庫同步,然后驗證應用程序。 一旦完成應用程序驗證測試,就將開始數據庫切換。 如果切換成功,則TiDB將在生產環境中作為主數據庫運行。
數據庫復制的應用場景 (Application scenarios of database replication)
遷移資料 (Migrating data)
We’ve talked about this application scenario in the previous section.
在上一節中,我們已經討論了此應用程序場景。
創建災難恢復數據庫 (Creating a disaster recovery database)
If you use Oracle as the primary database, you can use TiDB as its disaster recovery database. If you’ve just deployed a TiDB database in the production environment without sufficient verification, you can use an Oracle database as the disaster recovery database for TiDB. That way, if the TiDB database suddenly crashes, you can promptly migrate the data back to the original production database.
如果將Oracle用作主數據庫,則可以將TiDB用作其災難恢復數據庫。 如果您只是在生產環境中部署TiDB數據庫而沒有足夠的驗證,則可以將Oracle數據庫用作TiDB的災難恢復數據庫。 這樣,如果TiDB數據庫突然崩潰,則可以立即將數據遷移回原始生產數據庫。
創建只讀或存檔數據庫 (Creating a read-only or archive database)
First, let’s look at the application scenario of building a read-only database. This is applicable to some bank clients. A bank’s core services run in a closed system, and it may be impossible to migrate them to an open platform or a distributed database in a short time. However, some read-only applications, such as querying account details, bills, or monthly statements on the app client, can be completed without accessing the core production database, which only processes real transactions. Therefore, we can use database replication technology to replicate such read-only application data from the production database to the TiDB database and perform the read-only operations only in the TiDB database.
首先,讓我們看一下構建只讀數據庫的應用場景。 這適用于某些銀行客戶。 銀行的核心服務在封閉的系統中運行,因此可能無法在短時間內將其遷移到開放平臺或分布式數據庫。 但是,某些只讀應用程序(例如查詢應用程序客戶端上的帳戶明細,賬單或月結單)可以完成,而無需訪問僅處理真實交易的核心生產數據庫。 因此,我們可以使用數據庫復制技術將此類只讀應用程序數據從生產數據庫復制到TiDB數據庫,并僅在TiDB數據庫中執行只讀操作。
Another scenario is building an archive database. If you use a traditional standalone database for production and its capacity is limited, but your application data is growing quickly, the data cannot be migrated to a distributed database in a short time. A solution is to save data in the production database for a specific period (for example, 30 or 40 days), delete expired data from the production database, and store the deleted data in TiDB. That is, the deletion operation is performed only in the production database, and TiDB is used as an archive database.
另一種情況是建立檔案數據庫。 如果您使用傳統的獨立數據庫進行生產并且其容量有限,但是您的應用程序數據正在快速增長,則無法在短時間內將數據遷移到分布式數據庫。 一種解決方案是在生產數據庫中保存特定時間段(例如30或40天)的數據,從生產數據庫中刪除過期的數據,然后將已刪除的數據存儲在TiDB中。 即,僅在生產數據庫中執行刪除操作,并且TiDB用作存檔數據庫。
匯總來自多個來源的數據 (Aggregating data from multiple sources)
You can use TiDB as a data hub. You might run multiple applications in Online Transactional Processing (OLTP) databases and want to use the database replication technology to aggregate data from multiple sources to one TiDB database. Then, you can perform in-depth analysis on or read-only queries in the TiDB database. The main challenge for multi-source aggregation lies in the cross-database query after data is successfully aggregated to the TiDB database. The data may come from heterogeneous databases. It is impossible to create database links among them as database links can only be created among Oracle databases. To solve this problem, you can use heterogeneous database replication and use the TiDB database in a role similar to a widely deployed operational data store (ODS) for aggregating data.
您可以將TiDB用作數據中心。 您可能在在線事務處理(OLTP)數據庫中運行多個應用程序,并希望使用數據庫復制技術將數據從多個來源聚合到一個TiDB數據庫。 然后,您可以對TiDB數據庫中的只讀查詢執行深入分析。 多源聚合的主要挑戰在于將數據成功聚合到TiDB數據庫后的跨數據庫查詢。 數據可能來自異構數據庫。 由于只能在Oracle數據庫之間創建數據庫鏈接,因此無法在它們之間創建數據庫鏈接。 要解決此問題,您可以使用異構數據庫復制并以類似于廣泛部署的操作數據存儲(ODS)的角色使用TiDB數據庫來聚合數據。
復制異構數據庫 (Replicating heterogeneous databases)
This section discusses some commonly used heterogeneous database replication methods.
本節討論一些常用的異構數據庫復制方法。
通過接口文件進行數據傳輸 (Data transfer via interface files)
This method is widely used when transferring data between OLTP and Online Analytical Processing (OLAP) systems. As the data transfer involves two different systems, it’s difficult to connect two database networks. Databases belong to backend systems. For security reasons, it is not suitable to directly connect them.
在OLTP和聯機分析處理(OLAP)系統之間傳輸數據時,此方法被廣泛使用。 由于數據傳輸涉及兩個不同的系統,因此很難連接兩個數據庫網絡。 數據庫屬于后端系統。 出于安全原因,不適合直接連接它們。
A comma-separated values (CSV) file is a typical interface file. The interface file here refers to the file generated by an application, based on the predefined format and rules for adding delimiters and line breaks. After receiving a generated interface file, the receiving end parses the interface file based on the agreed format, converts the file into an INSERT statement, and inserts it into the target database.
逗號分隔值(CSV)文件是典型的接口文件。 此處的接口文件是指由應用程序根據預定義的格式以及添加定界符和換行符的規則生成的文件。 接收到生成的接口文件后,接收端會根據約定的格式解析接口文件,然后將其轉換為INSERT語句,然后將其插入目標數據庫。
The advantage of this method is that it applies to any database. As long as the upstream and downstream databases support standard SQL interfaces, you can transfer data through an interface file.
這種方法的優點是它適用于任何數據庫。 只要上游和下游數據庫支持標準SQL接口,您就可以通過接口文件傳輸數據。
However, this approach has several disadvantages:
但是,這種方法有幾個缺點:
- It requires additional development in your application code. For example, if the application was originally developed in Java, you need to add more programming logic. If you add logic to the upstream database code that generates an interface file, you also need to add logic to the downstream database code that imports the interface file. Moreover, to improve performance, you may need to control the concurrency of the file import. 它需要在應用程序代碼中進行其他開發。 例如,如果應用程序最初是用Java開發的,則需要添加更多的編程邏輯。 如果將邏輯添加到生成接口文件的上游數據庫代碼中,則還需要將邏輯添加到導入接口文件的下游數據庫代碼中。 此外,為了提高性能,您可能需要控制文件導入的并發性。
Interface files are only useful for full refresh and append write operations. It is difficult to obtain data changes generated by
UPDATEandDELETEoperations through an interface file.接口文件僅對完全刷新和追加寫入操作有用。 通過接口文件很難獲得由
UPDATE和DELETE操作生成的數據更改。Data may not be timely. As 5G technology gradually rolls out, terminal devices require lower latency. For example, banks are gradually changing from the traditional T+1 analytics to T+0 or even near real-time analytics. When you transfer data using an interface file, it’s hard to ensure that the data is timely. This is because the interface file triggers file loading at a specific time with low frequency and efficiency.
數據可能不及時。 隨著5G技術的逐步推出,終端設備需要更低的延遲。 例如,銀行正在逐漸從傳統的T + 1分析變為T + 0甚至接近實時分析。 使用接口文件傳輸數據時,很難確保數據及時。 這是因為接口文件在特定時間以較低的頻率和效率觸發文件加載。
- When data is exported, the upstream database must be scanned extensively to access the data through the SQL interface. This may affect performance. Therefore, as a common practice, the upstream application will open an SQL interface in the secondary database for exporting a read-only file to the downstream database. 導出數據時,必須對上游數據庫進行全面掃描以通過SQL界面訪問數據。 這可能會影響性能。 因此,通常的做法是,上游應用程序將在輔助數據庫中打開一個SQL接口,以將只讀文件導出到下游數據庫。
開發ETL作業并安排該作業以進行數據傳輸 (Developing an ETL job and scheduling the job for data transfer)
You can develop an extract, transform, load (ETL) job and schedule the job on a regular basis to transfer data. This method is commonly applied to data transfer and processing between OLTP and OLAP systems.
您可以開發提取,轉換,加載(ETL)作業并定期計劃該作業以傳輸數據。 此方法通常應用于OLTP和OLAP系統之間的數據傳輸和處理。
If you need to run ETL jobs for a long time, you may take a long time to obtain the incremental data and write it to the target database. This requires the ability to schedule ETL jobs, which involves additional development.
如果需要長時間運行ETL作業,則可能需要很長時間才能獲取增量數據并將其寫入目標數據庫。 這要求能夠安排ETL作業,這涉及其他開發。
Using an ETL job has the following advantages:
使用ETL作業具有以下優點:
- Just like an interface file, an ETL job uses SQL interfaces and is applicable to any database. As long as the upstream and downstream databases support SQL standards, you can use ETL jobs. 就像接口文件一樣,ETL作業使用SQL接口,并且適用于任何數據庫。 只要上游和下游數據庫都支持SQL標準,就可以使用ETL作業。
- Additionally, you can process data during the ETL job. If the upstream and downstream databases have different table schemas, or if you need to add logic to the table schema, ETL jobs are the best choice. 此外,您可以在ETL作業期間處理數據。 如果上游數據庫和下游數據庫具有不同的表架構,或者需要在表架構中添加邏輯,則ETL作業是最佳選擇。
The disadvantages of an ETL job are similar to those of using an interface file:
ETL作業的缺點類似于使用接口文件的缺點:
- An ETL job requires additional development. You need to create a set of independent SQL jobs and build up a scheduling system. ETL作業需要額外的開發。 您需要創建一組獨立SQL作業并建立調度系統。
The data changes incurred by
UPDATEandDELETEoperations are difficult to obtain via ETL jobs. Compared to using an interface file, the timeliness of ETL may be slightly better, but it depends on the scheduling frequency. However, the scheduling frequency is actually related to the processing time required by the job after each scheduling. For example, when data is imported each time, if a job requires 5 minutes for processing, the delay may be as long as 5 to 10 minutes.UPDATE和DELETE操作引起的數據更改很難通過ETL作業獲得。 與使用接口文件相比,ETL的及時性可能會稍好一些,但它取決于調度頻率。 但是,調度頻率實際上與每次調度后作業所需的處理時間有關。 例如,每次導入數據時,如果作業需要5分鐘進行處理,則延遲可能長達5到10分鐘。- To access the data through the SQL interface, extensive scanning of the upstream database is required. This may affect performance. 要通過SQL界面訪問數據,需要對上游數據庫進行全面掃描。 這可能會影響性能。
使用CDC工具 (Using a CDC tool)
We recommend that you use change data capture (CDC) tools to replicate heterogeneous databases. There are many CDC tools, such as Oracle GoldenGate (OGG), IBM InfoSphere CDC, and TiDB Data Migration (DM).
我們建議您使用更改數據捕獲(CDC)工具來復制異構數據庫。 有許多CDC工具,例如Oracle GoldenGate(OGG),IBM InfoSphere CDC和TiDB Data Migration (DM)。
The following table summarizes the advantages and disadvantages of using CDC tools. As you can see, there are far more advantages.
下表總結了使用CDC工具的優缺點。 如您所見,還有更多優勢。
AdvantagesDisadvantagesYour application requires no additional development.
優點缺點您的應用程序不需要其他開發。
CDC tools can obtain all DML changes, like DELETE and UPDATE.
CDC工具可以獲取所有DML更改,例如DELETE和UPDATE 。
Because the workload is distributed through the day, these tools have higher performance.
由于工作量是全天分配的,因此這些工具具有更高的性能。
CDC tools bring low latency and near real-time replication.
CDC工具帶來低延遲和近乎實時的復制。
Upstream data is obtained by reading redo logs, which does not impact the SQL performance.
通過讀取重做日志可以獲取上游數據,這不會影響SQL性能。
CDC tools are mostly commercial products, and you need to purchase them.
CDC工具大部分是商業產品,您需要購買它們。
Most CDC tools only allow a specific database as an upstream database. If you have multiple types of upstream databases, you need to use multiple CDC tools.
大多數CDC工具僅允許將特定數據庫作為上游數據庫。 如果您有多種類型的上游數據庫,則需要使用多個CDC工具。
TiDB中異構數據庫復制的最佳實踐 (Best practices for heterogeneous database replication in TiDB)
I’d like to offer some best practice tips for heterogeneous database replication in TiDB:
我想為TiDB中的異構數據庫復制提供一些最佳實踐提示:
Tips based on replication tasks:
根據復制任務的提示:
If you want to replicate incremental changes incurred by operations such as
UPDATEandDELETE, a CDC tool is your best choice.如果要復制由
UPDATE和DELETE等操作引起的增量更改,則CDC工具是最佳選擇。- If you want full data replication, you can use lightweight ETL tools dedicated to data migration such as Kettle or DataX. You do not need to purchase CDC tools or build other architectures to complete the replication. Instead, you only need to ensure that the ETL tool can access the upstream and downstream databases simultaneously and perform ETL jobs to do the full data replication. 如果要進行完整的數據復制,則可以使用專用于數據遷移的輕型ETL工具,例如Kettle或DataX。 您無需購買CDC工具或構建其他體系結構即可完成復制。 相反,您只需要確保ETL工具可以同時訪問上游和下游數據庫并執行ETL作業即可進行完整的數據復制。
Tips based on scenarios:
根據方案的提示:
If you are creating a disaster recovery database, creating a read-only or archive database, or aggregating data from multiple sources, we recommend that you use a CDC tool for data replication. If you use ETL jobs in these scenarios to obtain all DML changes, the development costs will be very high.
如果要創建災難恢復數據庫 , 創建只讀數據庫或存檔數據庫 ,或者聚合來自多個源的數據 ,建議您使用CDC工具進行數據復制。 如果在這些情況下使用ETL作業來獲取所有DML更改,則開發成本將非常高。
If your upstream database is a MySQL-like database or a MySQL-based database (such as Amazon RDS on the public cloud, including Aurora and some sharding products developed based on MySQL), you can use the TiDB DM tool for data transfer. For more information about DM, see TiDB Data Migration Overview.
如果上游數據庫是類似MySQL的數據庫或基于MySQL的數據庫(例如公共云上的Amazon RDS,包括Aurora和一些基于MySQL開發的分片產品),則可以使用TiDB DM工具進行數據傳輸。 有關DM的更多信息,請參見TiDB數據遷移概述 。
If you have any questions on any of the topics we covered today, you can join our community on Slack, and send us your feedback.
如果您對我們今天討論的任何主題有任何疑問,可以加入Slack上的社區 ,并將您的反饋發送給我們。
Originally published at www.pingcap.com on July 30, 2020
最初于 2020年7月30日 在 www.pingcap.com 上 發布
翻譯自: https://medium.com/swlh/heterogeneous-database-replication-to-tidb-c10478d11b29
tidb數據庫
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388926.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388926.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388926.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

機器學習實踐七----異常檢測和推薦系統
![CODE[VS] 1621 混合牛奶 USACO](http://pic.xiahunao.cn/CODE[VS] 1621 混合牛奶 USACO)
CODE[VS] 1621 混合牛奶 USACO

apply和call用法

剛認識女孩說不要浪費時間_不要浪費時間尋找學習數據科學的最佳方法

測試工具之badboy

hive 集成sentry

word模板生成word報表文檔
![isql 測試mysql連接_[libco] 協程庫學習,測試連接 mysql](http://pic.xiahunao.cn/isql 測試mysql連接_[libco] 協程庫學習,測試連接 mysql)
isql 測試mysql連接_[libco] 協程庫學習,測試連接 mysql

什么是數據倉庫,何時以及為什么要考慮一個

安裝好MongoDB,但服務中沒有MongoDB服務的解決辦法

DRF數據驗證+數據存儲

mysql變量 exec_MySQL slave_exec_mode 參數說明


機器學習kaggle競賽實戰-泰坦尼克號

上海大都會 H.A Simple Problem with Integers

探索性數據分析入門_入門指南:R中的探索性數據分析

用Javascript代碼實現瀏覽器菜單命令(以下代碼在 Windows XP下的瀏覽器中調試通過

mysql程序設計教程_MySQL教程_編程入門教程_牛客網

學習筆記整理之StringBuffer與StringBulider的線程安全與線程不安全
