python web應用
Living in today’s world, we are surrounded by different data all around us. The ability to collect and use this data in our projects is a must-have skill for every data scientist.
生活在當今世界中,我們周圍遍布著不同的數據。 在我們的項目中收集和使用這些數據的能力是每位數據科學家必不可少的技能。
There are so many tutorials online about how to use specific Python libraries to harvest online data. However, you can rarely find tutorials on choosing the best library for your particular application.
在線上有太多關于如何使用特定的Python庫來收集在線數據的教程。 但是,您很少會找到有關為特定應用程序選擇最佳庫的教程。
Python offers a variety of libraries that one can use to scrape the web, libraires such as Scrapy, Beautiful Soup, Requests, Urllib, and Selenium. I am quite sure that more libraries exist, and more will be released soon considering how popular Python is.
Python提供了多種可用于抓取網絡的庫,例如Scrapy,Beautiful Soup,Requests,Urllib和Selenium等庫。 我很確定存在更多的庫,并且考慮到Python的流行程度,很快就會發布更多的庫。
In this article, I will cover the 5 libraries I just mentioned, will give an overview of each of them, for example, code and what are the best applications and cases for each of them.
在本文中,我將介紹我剛剛提到的5個庫,并對它們進行概述,例如,代碼以及對它們而言最佳的應用程序和案例。
For the rest of this article, I will use this sandbox website containing books to explain specific aspects of each library.
對于本文的其余部分,我將使用這個沙箱網站包含的書來解釋每個庫的具體方面。
1.崎cra (1. Scrapy)
Scrapy is one of the most popular Python web scrapping libraries right now. It is an open-source framework. This means it is not even a library; it is rather a complete tool that you can use to scrape and crawl around the web systematically.
Scrapy是目前最流行的Python Web抓取庫之一。 這是一個開源框架。 這意味著它甚至不是圖書館。 它是一個完整的工具,可用于系統地在網絡上抓取和爬網。
Scrapy was initially designed to build web spiders that can crawl the web on their own. It can be used in monitoring and mining data, as well as automated and systematic testing.
Scrapy最初旨在構建可自動爬網的網絡蜘蛛。 它可以用于監視和挖掘數據以及自動和系統的測試。
It is also very CPU and memory effecient compared to other Python approaches to scrape the web. The downside to using Scrapy is that installing it and getting to work correctly on your device can be a bit of a hassle.
與其他刮取Web的Python方法相比,它在CPU和內存方面也非常有效。 使用Scrapy的缺點是安裝它并在您的設備上正常工作可能有點麻煩。
概述和安裝 (Overview and installation)
To get started with Scrapy, you need to make sure that you’re running Python 3 or higher. To install Scrapy, you can simply write the following command in the terminal.
要開始使用Scrapy,您需要確保運行的是Python 3或更高版本。 要安裝Scrapy,您只需在終端中編寫以下命令即可。
pip install scrapyOnce Scrapy is successfully installed, you can run the Scrapy shell, by typing:
成功安裝Scrapy之后,您可以通過鍵入以下命令運行Scrapy Shell:
scrapy shellWhen you run this command, you will see something like this:
運行此命令時,您將看到以下內容:
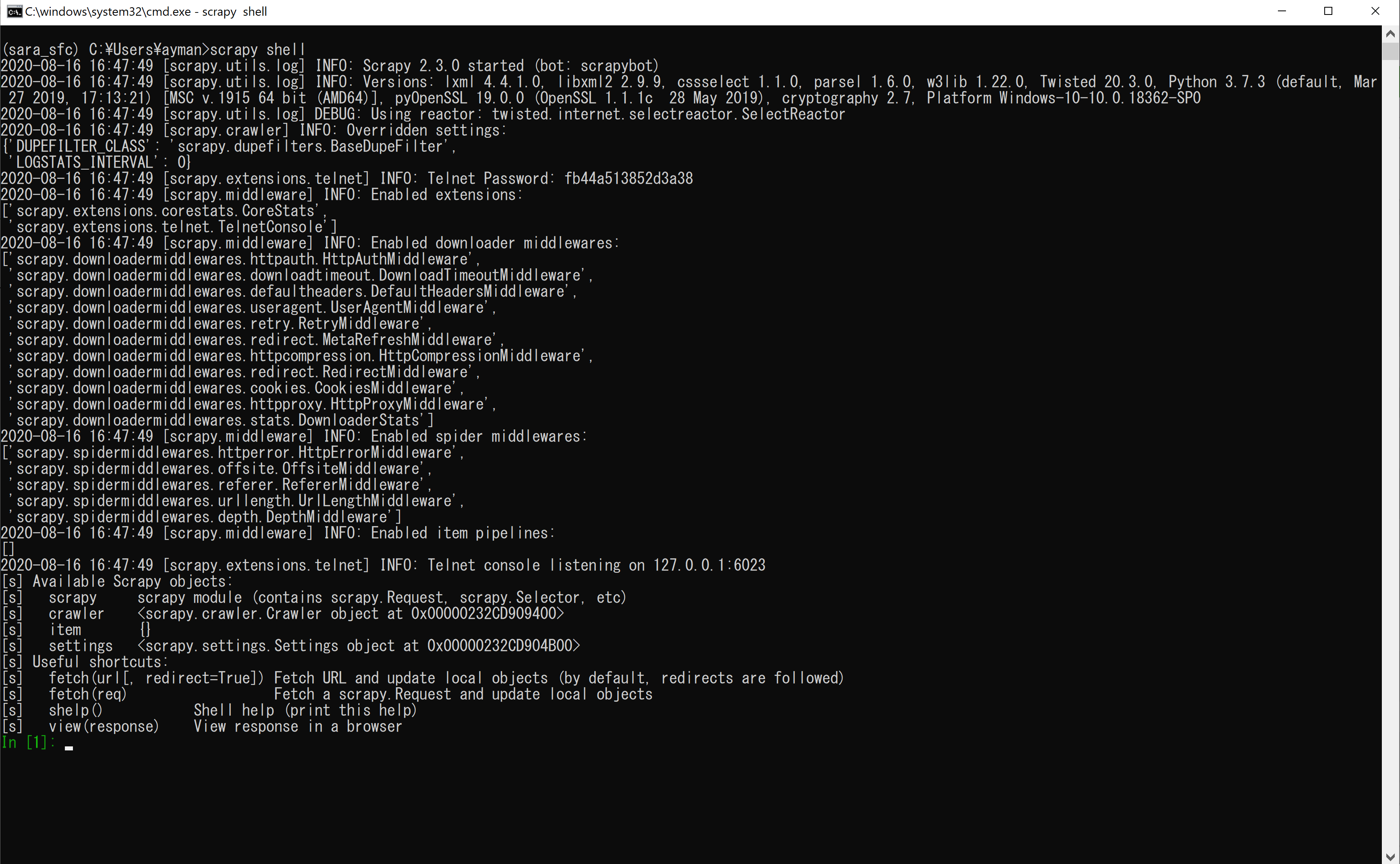
You can use the Scrapy shell to run simple commands, for example, you can fetch the HTML content of a website using the fetch function. So, let's say I want to fetch this book website; I can simply do that it in the shell.
您可以使用Scrapy shell來運行一些簡單的命令,例如,您可以獲取使用網站HTML內容fetch功能。 所以,讓我們說,我想取這本書的網站; 我可以在外殼中簡單地做到這一點。

fetch("http://books.toscrape.com/")Now, you can then use the view function to open up this HTML file in your default browser. Or you can just print out the HTML source code of the page.
現在,您可以使用view功能在默認瀏覽器中打開此HTML文件。 或者,您可以只打印頁面HTML源代碼。
view(response)
print(response.text)Of course, you won’t be scaring a website just to open it in your browser. You probably want some specific information from the HTML text. This is done using CSS Selectors.
當然,您不會只是在瀏覽器中打開網站而感到害怕。 您可能需要HTML文本中的一些特定信息。 這是使用CSS選擇器完成的。
You will need to inspect the structure of the webpage you want to fetch before you start so you can use the correct CSS selector.
在開始之前,您需要檢查要獲取的網頁的結構,以便可以使用正確CSS選擇器。
什么時候使用Scarpy? (When to use Scarpy?)
The best case to use Scrapy is when you want to do a big-scale web scraping or automate multiple tests. Scrapy is very well-structured, which allows for better flexibility and adaptability to specific applications. Moreover, the way Scrapy projects are organized makes it easier o maintain and extend.
最好使用Scrapy的情況是要進行大規模的Web抓取或自動化多個測試時。 Scrapy的結構非常好,可以為特定應用程序提供更好的靈活性和適應性。 此外,Scrapy項目的組織方式使維護和擴展變得更容易。
I would suggest that you avoid using Scrapy if you have a small project or you want to scrape one or just a few webpages. In this case, Scarpy will overcomplicate things and won’t add and benefits.
如果您的項目很小,或者只想抓取一個或幾個網頁,我建議您避免使用Scrapy。 在這種情況下,Scarpy將使事情變得復雜,并且不會增加收益。
2.要求 (2. Requests)
Requests is the most straightforward HTTP library you can use. Requests allow the user to sent requests to the HTTP server and GET response back in the form of HTML or JSON response. It also allows the user to send POST requests to the server to modify or add some content.
請求是您可以使用的最直接的HTTP庫。 請求允許用戶將請求發送到HTTP服務器,并以HTML或JSON響應的形式返回GET響應。 它還允許用戶向服務器發送POST請求,以修改或添加一些內容。
Requests show the real power that can be obtained with a well designed high-level abstract API.
請求顯示了使用精心設計的高級抽象API可以獲得的真正功能。
概述和安裝 (Overview and installation)
Requests is often included in Python’s built-in libraries. However, if for some reason you can’t import it right away, you can install it easily using pip.
請求通常包含在Python的內置庫中。 但是,如果由于某種原因無法立即導入,則可以使用pip輕松安裝。
pip install requestsYou can use Requests to fetch and clean well-organized API responses. For example, let’s say I want to look up a movie in the OMDB database. Requests allow me to send a movie name to the API, clean up the response, and print it in less than 10 lines of code — if we omit the comments 😄.
您可以使用請求來獲取和清理組織良好的API響應。 例如,假設我要在OMDB數據庫中查找電影。 請求允許我將影片名稱發送到API,清理響應,并在少于10行的代碼中將其打印-如果我們省略注釋😄。
何時使用請求? (When to use Requests?)
Requests is the ideal choice when you’re starting with web scraping, and you have an API tp contact with. It’s simple and doesn’t need much practice to master using. Requests also doesn’t require you to add query strings to your URLs manually. Finally, it has a very well written documentation and supports the entire restful API with all its methods (PUT, GET, DELETE, and POST).
當您開始抓取網頁并且與API tp聯系時, 請求是理想的選擇。 它很簡單,不需要太多練習就可以掌握。 請求也不需要您手動將查詢字符串添加到您的URL。 最后,它有一個寫得很好的文檔,并以其所有方法(PUT,GET,DELETE和POST)支持整個Restful API。
Avoid using Requests if the webpage you’re trying or desiring has JavaScrip content. Then the responses may not parse the correct information.
如果您嘗試或想要的網頁包含JavaScrip內容,請避免使用請求。 然后,響應可能無法解析正確的信息。
3. Urllib (3. Urllib)
Urllib is a Python library that allows the developer to open and parse information from HTTP or FTP protocols. Urllib offers some functionality to deal with and open URLs, namely:
Urllib是一個Python庫,允許開發人員打開和解析來自HTTP或FTP協議的信息。 Urllib提供了一些處理和打開URL的功能,即:
urllib.request: opens and reads URLs.
urllib.request:打開并讀取URL。
urllib.error: catches the exceptions raised by urllib.request.
urllib.error:捕獲urllib.request引發的異常。
urllib.parse: parses URLs.
urllib.parse:解析URL。
urllib.robotparser: parses robots.txt files.
urllib.robotparser:解析robots.txt文件。
概述和安裝 (Overview and installation)
The good news is, you don’t need to install Urllib since it is a part of the built-in Python library. However, in some rare cases, you may not find Urllib in your Python package. If that’s the case, simply install it using pip.
好消息是,您不需要安裝Urllib,因為它是內置Python庫的一部分。 但是,在極少數情況下,您可能在Python包中找不到Urllib。 如果是這種情況,只需使用pip安裝即可。
pip install urllibYou can use Urllib to explore and parse websites; however, it won’t offer you much functionality.
您可以使用Urllib瀏覽和解析網站。 但是,它不會為您提供太多功能。
何時使用Urllib? (When to use Urllib?)
Urllib is a little more complicated than Requests; however, if you want to have better control over your requests, then Urllib is the way to go.
Urllib比Requests要復雜一些; 但是 ,如果您想更好地控制自己的請求,則可以使用Urllib。
4.美麗的湯 (4. Beautiful Soup)
Beautiful Soup is a Python library that is used to extract information from XML and HTML files. Beautiful Soup is considered a parser library. Parsers help the programmer obtain data from an HTML file. If parsers didn’t exist, we would probably use Regex to match and get patterns from the text, which is not an effecient or maintainable approach.
Beautiful Soup是一個Python庫,用于從XML和HTML文件中提取信息。 Beautiful Soup被視為解析器庫。 解析器幫助程序員從HTML文件獲取數據。 如果不存在解析器,我們可能會使用Regex匹配并從文本中獲取模式,這不是一種有效或可維護的方法。
Luckily, we don’t need to do that, because we have parsers!
幸運的是,我們不需要這樣做,因為我們有解析器!
One of Beautiful Soup’s strengths is its ability to detect page encoding, and hence get more accurate information from the HTML text. Another advantage of Beautiful Soup is its simplicity and ease.
Beautiful Soup的優勢之一是它能夠檢測頁面編碼,從而從HTML文本中獲取更準確的信息。 美麗湯的另一個優點是簡單易用。
概述和安裝 (Overview and installation)
Installing Beautiful Soup is quite simple and straight forward. All you have to do is type the following in the terminal.
安裝Beautiful Soup非常簡單直接。 您所要做的就是在終端中鍵入以下內容。
pip install beautifulsoup4That’s it! You can get right to scraping.
而已! 您可以直接進行抓取。
Now, Beautiful Soup is a parser that we just mentioned, which means we’ll need to get the HTML first and then use Beautiful Soup to extract the information we need from it. We can use Urllib or Requests to get the HTML text from a webpage and then use Beautiful Soup to cleaning it up.
現在,Beautiful Soup是我們剛剛提到的解析器,這意味著我們需要首先獲取HTML,然后使用Beautiful Soup從中提取所需的信息。 我們可以使用Urllib或Requests從網頁中獲取HTML文本,然后使用Beautiful Soup對其進行清理。
Going back to the webpage from before, we can use Requests to fetch the webpage’s HTML source and then use Beautiful Soup to get all links inside the <a> in the page. And we can do that with a few lines of code.
回到以前的網頁,我們可以使用請求來獲取網頁HTML源,然后使用Beautiful Soup來獲取頁面<a>中的所有鏈接。 我們可以用幾行代碼來做到這一點。
何時使用美麗湯? (When to use Beautiful Soup?)
If you’re just starting with webs scarping or with Python, Beautiful Soup is the best choice to go. Moreover, if the documents you’ll be scraping are not structured, Beautiful Soup will be the perfect choice to use.
如果您只是從網上清理或Python開始,那么Beautiful Soup是最好的選擇。 此外,如果您要抓取的文檔沒有結構化,那么Beautiful Soup將是使用的理想選擇。
If you’re building a big project, Beautiful Soup will not be the wise option to take. Beautiful Soup projects are not flexible and are difficult to maintain as the project size increases.
如果您要建設一個大型項目,則“美麗湯”將不是明智的選擇。 Beautiful Soup項目不靈活,并且隨著項目規模的增加而難以維護。
5.Selenium (5. Selenium)
Selenium is an open-source web-based tool. Selenium is a web-driver, which means you can use it to open a webpage, click on a button, and get results. It is a potent tool that was mainly written in Java to automate tests.
Selenium是基于Web的開源工具。 Selenium是一個網絡驅動程序,這意味著您可以使用它來打開網頁,單擊按鈕并獲得結果。 這是一個強大的工具,主要是用Java編寫的用于自動化測試的工具。
Despite its strength, Selenium is a beginner-friendly tool that doesn’t require a steep learning curve. It also allows the code to mimic human behavior, which is a must in automated testing.
盡管具有優勢,Selenium還是一種適合初學者的工具,不需要陡峭的學習曲線。 它還允許代碼模仿人類行為,這在自動化測試中是必須的。
概述和安裝 (Overview and installation)
To install Selenium, you can simply use the pip command in the terminal.
要安裝Selenium,您只需在終端中使用pip命令。
pip install seleniumIf you want to harvest the full power of Selenium — which you probably will — you will need to install a Selenium WebDriver to drive the browser natively, as a real user, either locally or on remote devices.
如果您想充分利用Selenium的全部功能(可能會),則需要安裝Selenium WebDriver以本地用戶或本地設備在本地或遠程設備上以本機驅動瀏覽器。
You can use Selenium to automate logging in to Twitter — or Facebook or any site, really.
實際上,您可以使用Selenium來自動登錄Twitter或Facebook或任何站點。
何時使用Selenium? (When to use Selenium?)
If you’re new to the web scraping game, yet you need a powerful tool that is extendable and flexible, Selenium is the best choice. Also, it is an excellent choice if you want to scrape a few pages, yet the information you need is within JavaScript.
如果您不熟悉網絡抓取游戲,但是您需要一個可擴展且靈活的強大工具,那么Selenium是最佳選擇。 另外,如果要刮幾頁,這也是一個極好的選擇,但是所需的信息在JavaScript中。
Using the correct library for your project can save you a lot of time and effort, which could be critical for the success of the project.
為您的項目使用正確的庫可以節省大量時間和精力,這對于項目的成功至關重要。
As a data scientist, you will probably come across all these libraries and maybe more during your journey, which is, in my opinion, the only way to know the pros and cons of each of them. Doing so, you will develop a sixth sense to lead you through choosing and using the best library in future projects.
作為數據科學家,您可能會遇到所有這些庫,并且在您的旅途中可能會遇到更多的庫,我認為這是了解每個庫的優缺點的唯一方法。 這樣做,您將形成第六感,引導您選擇和使用未來項目中的最佳庫。
翻譯自: https://towardsdatascience.com/choose-the-best-python-web-scraping-library-for-your-application-91a68bc81c4f
python web應用
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388906.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388906.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388906.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

NDK-r14b + FFmpeg-release-3.4 linux下編譯FFmpeg

C# WebBrowser自動填表與提交

html中列表導航怎么和圖片對齊_HTML實戰篇:html仿百度首頁

C# 依賴注入那些事兒

asp.net core Serilog的使用

在FAANG面試中破解堆算法

android webView的緩存機制和資源預加載

mysql springboot 緩存_Spring Boot 整合 Redis 實現緩存操作

http壓力測試工具及使用說明

itchat 道歉_人類的“道歉”
)
使用Kubespray部署生產可用的Kubernetes集群(1.11.2)

android webView 與 JS交互方式

matlab軟件imag函數_「復變函數與積分變換」基本計算代碼

數據科學 python_為什么需要以數據科學家的身份學習Python的7大理由
![[luoguP4142]洞穴遇險](http://pic.xiahunao.cn/[luoguP4142]洞穴遇險)
[luoguP4142]洞穴遇險


django的contenttype表

視頻播放問題和提高性能方案

rabbitmq 不同的消費者消費同一個隊列_RabbitMQ 消費端限流、TTL、死信隊列
